Compare commits
376 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
242d79e49d | ||
|
|
4f01ecde5a | ||
|
|
61141c7479 | ||
|
|
62429ff710 | ||
|
|
82a1f45cc1 | ||
|
|
1a95fc2a9c | ||
|
|
13816eeafa | ||
|
|
5279f73c17 | ||
|
|
d196bb2856 | ||
|
|
3f8f634a1b | ||
|
|
5ba27c898e | ||
|
|
57f1b63fa1 | ||
|
|
d69e203479 | ||
|
|
4d7fae39a8 | ||
|
|
2dc554c92a | ||
|
|
21c394ef7f | ||
|
|
2173bfc1a0 | ||
|
|
a19d016e14 | ||
|
|
8f1b5df9e2 | ||
|
|
2d6b8ecfdf | ||
|
|
8093612011 | ||
|
|
39dc761e32 | ||
|
|
0c68983c62 | ||
|
|
c7539f6e4b | ||
|
|
8cebc0acee | ||
|
|
f60c4d60cf | ||
|
|
662f9cba2e | ||
|
|
4a82e1e223 | ||
|
|
b60b912bf8 | ||
|
|
093348bc60 | ||
|
|
37ebbf14f9 | ||
|
|
156488c8d5 | ||
|
|
68d1f583cc | ||
|
|
3492b07d9a | ||
|
|
d0b582048f | ||
|
|
a82eb7b01f | ||
|
|
cd08afcbeb | ||
|
|
331942a4ed | ||
|
|
aa24d6ff7e | ||
|
|
58c2c19f1e | ||
|
|
2a91149211 | ||
|
|
868482c240 | ||
|
|
4e387fa943 | ||
|
|
15484363d6 | ||
|
|
50b7b74480 | ||
|
|
adb53c63dd | ||
|
|
bdc3a32e96 | ||
|
|
65f716182b | ||
|
|
6ef72e2550 | ||
|
|
60f51ad7d5 | ||
|
|
a09dc2cbd8 | ||
|
|
825d07aa54 | ||
|
|
f46882c778 | ||
|
|
663fa08cc1 | ||
|
|
19e625d38e | ||
|
|
edcff9cd15 | ||
|
|
e0fc5ecb39 | ||
|
|
4ac6629969 | ||
|
|
68d8dad7c8 | ||
|
|
4ab9ceafc1 | ||
|
|
352ed898d4 | ||
|
|
e091d6a50d | ||
|
|
c651ef00c9 | ||
|
|
4b17788a77 | ||
|
|
e5612bca50 | ||
|
|
d21fb1afe8 | ||
|
|
89d0a533e2 | ||
|
|
db673dddd9 | ||
|
|
88ad457e87 | ||
|
|
126b68559e | ||
|
|
2cd3fe47e6 | ||
|
|
15eb7cce55 | ||
|
|
13f923aabf | ||
|
|
0ffb112063 | ||
|
|
b4ea6af110 | ||
|
|
611c8f7374 | ||
|
|
1cc73f37e7 | ||
|
|
ca37fc0eb5 | ||
|
|
5380624da9 | ||
|
|
aaece0bd44 | ||
|
|
de7cc17f5d | ||
|
|
66efa39d27 | ||
|
|
ff7c0a105d | ||
|
|
7b29253df4 | ||
|
|
7ef63b341e | ||
|
|
e7bfaa4f1a | ||
|
|
3a9a408941 | ||
|
|
3e43963daa | ||
|
|
69a6e260f5 | ||
|
|
664e7ad555 | ||
|
|
ee4a009a06 | ||
|
|
36dfd4dd35 | ||
|
|
dbf36082b2 | ||
|
|
3a1018cff6 | ||
|
|
fc10745a1a | ||
|
|
347cfd06de | ||
|
|
ec759ce467 | ||
|
|
f211e0fe31 | ||
|
|
c91a128b65 | ||
|
|
6a080f3032 | ||
|
|
b2c12c1131 | ||
|
|
b945b37089 | ||
|
|
9a5529a0aa | ||
|
|
025785389d | ||
|
|
48d9a0dede | ||
|
|
fbdf38e990 | ||
|
|
ef5bf70386 | ||
|
|
274c1469b4 | ||
|
|
960d506360 | ||
|
|
79a6421178 | ||
|
|
8b5c004860 | ||
|
|
f54768772e | ||
|
|
b9075dc6f9 | ||
|
|
107596ad54 | ||
|
|
3c6a2b1508 | ||
|
|
f996cba354 | ||
|
|
bdd864fbdd | ||
|
|
ca074ef13f | ||
|
|
ddd3a8251e | ||
|
|
f5b862dc1b | ||
|
|
d45d475f61 | ||
|
|
d0f72ea3fa | ||
|
|
5ed5d1e5b6 | ||
|
|
311b14026e | ||
|
|
67cd722b54 | ||
|
|
7f6247eb7b | ||
|
|
f3fd515521 | ||
|
|
9db5dd0d7f | ||
|
|
d07925d79d | ||
|
|
662d0f31ff | ||
|
|
2c5ad0bf8f | ||
|
|
0ea76b986a | ||
|
|
3c4253c336 | ||
|
|
77ba28e91c | ||
|
|
6399e7586c | ||
|
|
1caa62adc8 | ||
|
|
8fa558f124 | ||
|
|
191228633b | ||
|
|
8a981f935a | ||
|
|
a8ea9adbcc | ||
|
|
685d94c44b | ||
|
|
153ed1b044 | ||
|
|
7788f3a1ba | ||
|
|
cd99225f9b | ||
|
|
33ba3b8d4a | ||
|
|
d222dd1069 | ||
|
|
39fd3d46ba | ||
|
|
419c1804b6 | ||
|
|
ae0351ddad | ||
|
|
941be15762 | ||
|
|
578ebcf6ed | ||
|
|
27ab4b08f9 | ||
|
|
428b2208ba | ||
|
|
438c553d60 | ||
|
|
90cb293182 | ||
|
|
1f9f93ebe4 | ||
|
|
f5b97fbb74 | ||
|
|
ce79244126 | ||
|
|
3af5d767d8 | ||
|
|
3ce3efd2f2 | ||
|
|
8108edea31 | ||
|
|
5d80087ab3 | ||
|
|
6593be584d | ||
|
|
a0f63f858f | ||
|
|
49914f3bd5 | ||
|
|
71988a8b98 | ||
|
|
d65be6ef58 | ||
|
|
38c40d02e7 | ||
|
|
9e071b9d60 | ||
|
|
b4ae060122 | ||
|
|
436656e81b | ||
|
|
d7e111b7d4 | ||
|
|
4b6126dd1a | ||
|
|
89faa70196 | ||
|
|
6ed9d4a1db | ||
|
|
9d0e38c2e1 | ||
|
|
8b758fd616 | ||
|
|
14369d8be3 | ||
|
|
7b4153113e | ||
|
|
7d340c5e61 | ||
|
|
337c94376d | ||
|
|
0ef1d0b2f1 | ||
|
|
5cf67bd4e0 | ||
|
|
f22be17852 | ||
|
|
48e79d5dd4 | ||
|
|
59f5a0654a | ||
|
|
6da2e11683 | ||
|
|
802c087a4b | ||
|
|
ed2048e9f3 | ||
|
|
437b1d30c0 | ||
|
|
ba1788cbc5 | ||
|
|
773094a20d | ||
|
|
5aa39106a0 | ||
|
|
a9167801ba | ||
|
|
62f4a6cb96 | ||
|
|
ea2b41e96e | ||
|
|
d28ce650e9 | ||
|
|
1bfcdba499 | ||
|
|
e48faa9144 | ||
|
|
33fbe99561 | ||
|
|
989925b484 | ||
|
|
7dd66559e7 | ||
|
|
2ef1c5608e | ||
|
|
b5932e8905 | ||
|
|
37999d3250 | ||
|
|
83985ae482 | ||
|
|
3adfcc837e | ||
|
|
c720fee3ab | ||
|
|
881387e522 | ||
|
|
d9f3378e29 | ||
|
|
ba87620225 | ||
|
|
1cd0c49872 | ||
|
|
12ac96deeb | ||
|
|
17e6f35785 | ||
|
|
bd115633a3 | ||
|
|
86ea172380 | ||
|
|
d87bbbbc1e | ||
|
|
6196f69f4d | ||
|
|
be31bcf22f | ||
|
|
cba2135c69 | ||
|
|
2e52573499 | ||
|
|
b2ce1ed1fb | ||
|
|
77a485af74 | ||
|
|
d8b847a973 | ||
|
|
e80a3d3232 | ||
|
|
780ba82385 | ||
|
|
6ba69dce0a | ||
|
|
3c7a561db8 | ||
|
|
49c942bea0 | ||
|
|
bf1ca293dc | ||
|
|
62b906d30b | ||
|
|
65bf048189 | ||
|
|
a498ed8200 | ||
|
|
9f12bbcd98 | ||
|
|
fcd520787d | ||
|
|
e2417e4e40 | ||
|
|
70a2cbf1c6 | ||
|
|
fa0c6af6aa | ||
|
|
4f1abd0c8d | ||
|
|
41e839aa36 | ||
|
|
2fd1593ad2 | ||
|
|
27b601c5aa | ||
|
|
5fc69134e3 | ||
|
|
9adc0698bb | ||
|
|
119c2ff464 | ||
|
|
f3a4201c7d | ||
|
|
8b6aa73df0 | ||
|
|
1d4dfb0883 | ||
|
|
eab7f126a6 | ||
|
|
fe7547d83e | ||
|
|
7d0df82861 | ||
|
|
7f0cd27591 | ||
|
|
e094c2ae14 | ||
|
|
a5d438257f | ||
|
|
d8cb8f1064 | ||
|
|
a8d8bb2d6f | ||
|
|
a76ea5917c | ||
|
|
b0b6198ec8 | ||
|
|
eda97f35d2 | ||
|
|
2b6507d35a | ||
|
|
f7c4d5aa0b | ||
|
|
74f07cffa6 | ||
|
|
79c8ff0af8 | ||
|
|
ac544eea4b | ||
|
|
231a32331b | ||
|
|
104e8ef050 | ||
|
|
296015faff | ||
|
|
9a9964c968 | ||
|
|
0d05d86e32 | ||
|
|
9680ca98f2 | ||
|
|
42b850ca52 | ||
|
|
3f5c22d863 | ||
|
|
535a92e871 | ||
|
|
3411a6a981 | ||
|
|
b5adee271c | ||
|
|
e2abcd1323 | ||
|
|
25fbe7ecb6 | ||
|
|
6befee79c2 | ||
|
|
f09c5a60f1 | ||
|
|
52e89ff509 | ||
|
|
35e20406ef | ||
|
|
c6e96ff1bb | ||
|
|
793ab524b0 | ||
|
|
5a479d0187 | ||
|
|
a23e4f1d2a | ||
|
|
bd35a3f61c | ||
|
|
197e987d5f | ||
|
|
7f29beb639 | ||
|
|
1140af8dc7 | ||
|
|
a2688c3910 | ||
|
|
75b27ab3f3 | ||
|
|
59d3f55fb2 | ||
|
|
f34739f334 | ||
|
|
90c71ec18f | ||
|
|
395234d7c8 | ||
|
|
e322ba0065 | ||
|
|
6db8b96f72 | ||
|
|
44d7e96e96 | ||
|
|
1662479c8d | ||
|
|
2e351fcf0d | ||
|
|
5d81876d07 | ||
|
|
c81e6989ec | ||
|
|
4d61a896c3 | ||
|
|
d148933ab3 | ||
|
|
04a56a3591 | ||
|
|
4a354e74d4 | ||
|
|
1e3e6427d5 | ||
|
|
38826108c8 | ||
|
|
4c4752f907 | ||
|
|
94dcd6c94d | ||
|
|
eabef3db30 | ||
|
|
6750f10ffa | ||
|
|
56cb888cbf | ||
|
|
b3e7fb3417 | ||
|
|
2c6e1baca2 | ||
|
|
c8358929d1 | ||
|
|
1dc7677dfb | ||
|
|
8e699a7543 | ||
|
|
cbbabdfac0 | ||
|
|
9d92de234c | ||
|
|
ba65975fb5 | ||
|
|
ef423b2078 | ||
|
|
f451b4e36c | ||
|
|
0856e13ee6 | ||
|
|
87b9fa8ca7 | ||
|
|
5b43d3d314 | ||
|
|
ac4972dd8d | ||
|
|
8a8f68af5d | ||
|
|
c669dc0c4b | ||
|
|
863a5466cc | ||
|
|
e2347c84e3 | ||
|
|
e0e673f565 | ||
|
|
30cbf2a741 | ||
|
|
f58de3801c | ||
|
|
7c6b88d4c1 | ||
|
|
0c0ebaecd5 | ||
|
|
1925f99118 | ||
|
|
6f2a22a1cc | ||
|
|
ee04082cd7 | ||
|
|
efd901ac3a | ||
|
|
e565789ae8 | ||
|
|
d3953004f6 | ||
|
|
df1d9e3011 | ||
|
|
631c55fa6e | ||
|
|
29cdd43288 | ||
|
|
9b79af9fcd | ||
|
|
2c9c1adb47 | ||
|
|
5dfb5808c4 | ||
|
|
bb0175aebf | ||
|
|
adaf4c99c0 | ||
|
|
bed6ed09d5 | ||
|
|
4ff67a85ce | ||
|
|
702f4fcd14 | ||
|
|
8a03ae153d | ||
|
|
434c6149ab | ||
|
|
97fc4a90ae | ||
|
|
217ef06930 | ||
|
|
71057946e6 | ||
|
|
a74ad52c72 | ||
|
|
12d26874f8 | ||
|
|
27de9ce151 | ||
|
|
9e7cd5a8c5 | ||
|
|
38cb487b64 | ||
|
|
05ca266c5e | ||
|
|
5cc26de645 | ||
|
|
2b9a195fa3 | ||
|
|
4454749eec | ||
|
|
b435a03fab | ||
|
|
7c166e2b40 | ||
|
|
f7a7963dcf | ||
|
|
9c77c0d69c | ||
|
|
e8a9555346 | ||
|
|
59751dd007 | ||
|
|
9c4d4d16b6 | ||
|
|
0e3d1b3e8f | ||
|
|
f119b78940 |
38
.circleci/config.yml
Normal file
@@ -0,0 +1,38 @@
|
||||
version: 2.1
|
||||
jobs:
|
||||
e2e-testing:
|
||||
machine: true
|
||||
steps:
|
||||
- checkout
|
||||
- run: test/e2e-kind.sh
|
||||
- run: test/e2e-istio.sh
|
||||
- run: test/e2e-build.sh
|
||||
- run: test/e2e-tests.sh
|
||||
|
||||
e2e-supergloo-testing:
|
||||
machine: true
|
||||
steps:
|
||||
- checkout
|
||||
- run: test/e2e-kind.sh
|
||||
- run: test/e2e-supergloo.sh
|
||||
- run: test/e2e-build.sh supergloo:test.supergloo-system
|
||||
- run: test/e2e-tests.sh canary
|
||||
|
||||
workflows:
|
||||
version: 2
|
||||
build-and-test:
|
||||
jobs:
|
||||
- e2e-testing:
|
||||
filters:
|
||||
branches:
|
||||
ignore:
|
||||
- /gh-pages.*/
|
||||
- /docs-.*/
|
||||
- /release-.*/
|
||||
- e2e-supergloo-testing:
|
||||
filters:
|
||||
branches:
|
||||
ignore:
|
||||
- /gh-pages.*/
|
||||
- /docs-.*/
|
||||
- /release-.*/
|
||||
@@ -6,3 +6,6 @@ coverage:
|
||||
threshold: 50
|
||||
base: auto
|
||||
patch: off
|
||||
|
||||
comment:
|
||||
require_changes: yes
|
||||
1
.github/CODEOWNERS
vendored
Normal file
@@ -0,0 +1 @@
|
||||
* @stefanprodan
|
||||
4
.gitignore
vendored
@@ -11,3 +11,7 @@
|
||||
# Output of the go coverage tool, specifically when used with LiteIDE
|
||||
*.out
|
||||
.DS_Store
|
||||
|
||||
bin/
|
||||
artifacts/gcloud/
|
||||
.idea
|
||||
@@ -1,7 +1,7 @@
|
||||
builds:
|
||||
- main: ./cmd/flagger
|
||||
binary: flagger
|
||||
ldflags: -s -w -X github.com/stefanprodan/flagger/pkg/version.REVISION={{.Commit}}
|
||||
ldflags: -s -w -X github.com/weaveworks/flagger/pkg/version.REVISION={{.Commit}}
|
||||
goos:
|
||||
- linux
|
||||
goarch:
|
||||
|
||||
28
.travis.yml
@@ -1,8 +1,13 @@
|
||||
sudo: required
|
||||
language: go
|
||||
|
||||
branches:
|
||||
except:
|
||||
- /gh-pages.*/
|
||||
- /docs-.*/
|
||||
|
||||
go:
|
||||
- 1.11.x
|
||||
- 1.12.x
|
||||
|
||||
services:
|
||||
- docker
|
||||
@@ -13,27 +18,26 @@ addons:
|
||||
- docker-ce
|
||||
|
||||
script:
|
||||
- set -e
|
||||
- make test-fmt
|
||||
- make test-codegen
|
||||
- go test -race -coverprofile=coverage.txt -covermode=atomic ./pkg/controller/
|
||||
- make build
|
||||
- make test-fmt
|
||||
- make test-codegen
|
||||
- go test -race -coverprofile=coverage.txt -covermode=atomic $(go list ./pkg/...)
|
||||
- make build
|
||||
|
||||
after_success:
|
||||
- if [ -z "$DOCKER_USER" ]; then
|
||||
echo "PR build, skipping image push";
|
||||
else
|
||||
BRANCH_COMMIT=${TRAVIS_BRANCH}-$(echo ${TRAVIS_COMMIT} | head -c7);
|
||||
docker tag stefanprodan/flagger:latest quay.io/stefanprodan/flagger:${BRANCH_COMMIT};
|
||||
echo $DOCKER_PASS | docker login -u=$DOCKER_USER --password-stdin quay.io;
|
||||
docker push quay.io/stefanprodan/flagger:${BRANCH_COMMIT};
|
||||
docker tag weaveworks/flagger:latest weaveworks/flagger:${BRANCH_COMMIT};
|
||||
echo $DOCKER_PASS | docker login -u=$DOCKER_USER --password-stdin;
|
||||
docker push weaveworks/flagger:${BRANCH_COMMIT};
|
||||
fi
|
||||
- if [ -z "$TRAVIS_TAG" ]; then
|
||||
echo "Not a release, skipping image push";
|
||||
else
|
||||
docker tag stefanprodan/flagger:latest quay.io/stefanprodan/flagger:${TRAVIS_TAG};
|
||||
echo $DOCKER_PASS | docker login -u=$DOCKER_USER --password-stdin quay.io;
|
||||
docker push quay.io/stefanprodan/flagger:$TRAVIS_TAG;
|
||||
docker tag weaveworks/flagger:latest weaveworks/flagger:${TRAVIS_TAG};
|
||||
echo $DOCKER_PASS | docker login -u=$DOCKER_USER --password-stdin;
|
||||
docker push weaveworks/flagger:$TRAVIS_TAG;
|
||||
fi
|
||||
- bash <(curl -s https://codecov.io/bash)
|
||||
- rm coverage.txt
|
||||
|
||||
245
CHANGELOG.md
Normal file
@@ -0,0 +1,245 @@
|
||||
# Changelog
|
||||
|
||||
All notable changes to this project are documented in this file.
|
||||
|
||||
## 0.12.0 (2019-04-29)
|
||||
|
||||
Adds support for [SuperGloo](https://docs.flagger.app/install/flagger-install-with-supergloo)
|
||||
|
||||
#### Features
|
||||
|
||||
- Supergloo support for canary deployment (weighted traffic) [#151](https://github.com/weaveworks/flagger/pull/151)
|
||||
|
||||
## 0.11.1 (2019-04-18)
|
||||
|
||||
Move Flagger and the load tester container images to Docker Hub
|
||||
|
||||
#### Features
|
||||
|
||||
- Add Bash Automated Testing System support to Flagger tester for running acceptance tests as pre-rollout hooks
|
||||
|
||||
## 0.11.0 (2019-04-17)
|
||||
|
||||
Adds pre/post rollout [webhooks](https://docs.flagger.app/how-it-works#webhooks)
|
||||
|
||||
#### Features
|
||||
|
||||
- Add `pre-rollout` and `post-rollout` webhook types [#147](https://github.com/weaveworks/flagger/pull/147)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Unify App Mesh and Istio builtin metric checks [#146](https://github.com/weaveworks/flagger/pull/146)
|
||||
- Make the pod selector label configurable [#148](https://github.com/weaveworks/flagger/pull/148)
|
||||
|
||||
#### Breaking changes
|
||||
|
||||
- Set default `mesh` Istio gateway only if no gateway is specified [#141](https://github.com/weaveworks/flagger/pull/141)
|
||||
|
||||
## 0.10.0 (2019-03-27)
|
||||
|
||||
Adds support for App Mesh
|
||||
|
||||
#### Features
|
||||
|
||||
- AWS App Mesh integration
|
||||
[#107](https://github.com/weaveworks/flagger/pull/107)
|
||||
[#123](https://github.com/weaveworks/flagger/pull/123)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Reconcile Kubernetes ClusterIP services [#122](https://github.com/weaveworks/flagger/pull/122)
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Preserve pod labels on canary promotion [#105](https://github.com/weaveworks/flagger/pull/105)
|
||||
- Fix canary status Prometheus metric [#121](https://github.com/weaveworks/flagger/pull/121)
|
||||
|
||||
## 0.9.0 (2019-03-11)
|
||||
|
||||
Allows A/B testing scenarios where instead of weighted routing, the traffic is split between the
|
||||
primary and canary based on HTTP headers or cookies.
|
||||
|
||||
#### Features
|
||||
|
||||
- A/B testing - canary with session affinity [#88](https://github.com/weaveworks/flagger/pull/88)
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Update the analysis interval when the custom resource changes [#91](https://github.com/weaveworks/flagger/pull/91)
|
||||
|
||||
## 0.8.0 (2019-03-06)
|
||||
|
||||
Adds support for CORS policy and HTTP request headers manipulation
|
||||
|
||||
#### Features
|
||||
|
||||
- CORS policy support [#83](https://github.com/weaveworks/flagger/pull/83)
|
||||
- Allow headers to be appended to HTTP requests [#82](https://github.com/weaveworks/flagger/pull/82)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Refactor the routing management
|
||||
[#72](https://github.com/weaveworks/flagger/pull/72)
|
||||
[#80](https://github.com/weaveworks/flagger/pull/80)
|
||||
- Fine-grained RBAC [#73](https://github.com/weaveworks/flagger/pull/73)
|
||||
- Add option to limit Flagger to a single namespace [#78](https://github.com/weaveworks/flagger/pull/78)
|
||||
|
||||
## 0.7.0 (2019-02-28)
|
||||
|
||||
Adds support for custom metric checks, HTTP timeouts and HTTP retries
|
||||
|
||||
#### Features
|
||||
|
||||
- Allow custom promql queries in the canary analysis spec [#60](https://github.com/weaveworks/flagger/pull/60)
|
||||
- Add HTTP timeout and retries to canary service spec [#62](https://github.com/weaveworks/flagger/pull/62)
|
||||
|
||||
## 0.6.0 (2019-02-25)
|
||||
|
||||
Allows for [HTTPMatchRequests](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#HTTPMatchRequest)
|
||||
and [HTTPRewrite](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#HTTPRewrite)
|
||||
to be customized in the service spec of the canary custom resource.
|
||||
|
||||
#### Features
|
||||
|
||||
- Add HTTP match conditions and URI rewrite to the canary service spec [#55](https://github.com/weaveworks/flagger/pull/55)
|
||||
- Update virtual service when the canary service spec changes
|
||||
[#54](https://github.com/weaveworks/flagger/pull/54)
|
||||
[#51](https://github.com/weaveworks/flagger/pull/51)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Run e2e testing on [Kubernetes Kind](https://github.com/kubernetes-sigs/kind) for canary promotion
|
||||
[#53](https://github.com/weaveworks/flagger/pull/53)
|
||||
|
||||
## 0.5.1 (2019-02-14)
|
||||
|
||||
Allows skipping the analysis phase to ship changes directly to production
|
||||
|
||||
#### Features
|
||||
|
||||
- Add option to skip the canary analysis [#46](https://github.com/weaveworks/flagger/pull/46)
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Reject deployment if the pod label selector doesn't match `app: <DEPLOYMENT_NAME>` [#43](https://github.com/weaveworks/flagger/pull/43)
|
||||
|
||||
## 0.5.0 (2019-01-30)
|
||||
|
||||
Track changes in ConfigMaps and Secrets [#37](https://github.com/weaveworks/flagger/pull/37)
|
||||
|
||||
#### Features
|
||||
|
||||
- Promote configmaps and secrets changes from canary to primary
|
||||
- Detect changes in configmaps and/or secrets and (re)start canary analysis
|
||||
- Add configs checksum to Canary CRD status
|
||||
- Create primary configmaps and secrets at bootstrap
|
||||
- Scan canary volumes and containers for configmaps and secrets
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Copy deployment labels from canary to primary at bootstrap and promotion
|
||||
|
||||
## 0.4.1 (2019-01-24)
|
||||
|
||||
Load testing webhook [#35](https://github.com/weaveworks/flagger/pull/35)
|
||||
|
||||
#### Features
|
||||
|
||||
- Add the load tester chart to Flagger Helm repository
|
||||
- Implement a load test runner based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
- Log warning when no values are found for Istio metric due to lack of traffic
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Run wekbooks before the metrics checks to avoid failures when using a load tester
|
||||
|
||||
## 0.4.0 (2019-01-18)
|
||||
|
||||
Restart canary analysis if revision changes [#31](https://github.com/weaveworks/flagger/pull/31)
|
||||
|
||||
#### Breaking changes
|
||||
|
||||
- Drop support for Kubernetes 1.10
|
||||
|
||||
#### Features
|
||||
|
||||
- Detect changes during canary analysis and reset advancement
|
||||
- Add status and additional printer columns to CRD
|
||||
- Add canary name and namespace to controller structured logs
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Allow canary name to be different to the target name
|
||||
- Check if multiple canaries have the same target and log error
|
||||
- Use deep copy when updating Kubernetes objects
|
||||
- Skip readiness checks if canary analysis has finished
|
||||
|
||||
## 0.3.0 (2019-01-11)
|
||||
|
||||
Configurable canary analysis duration [#20](https://github.com/weaveworks/flagger/pull/20)
|
||||
|
||||
#### Breaking changes
|
||||
|
||||
- Helm chart: flag `controlLoopInterval` has been removed
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha3
|
||||
- Schedule canary analysis independently based on `canaryAnalysis.interval`
|
||||
- Add analysis interval to Canary CRD (defaults to one minute)
|
||||
- Make autoscaler (HPA) reference optional
|
||||
|
||||
## 0.2.0 (2019-01-04)
|
||||
|
||||
Webhooks [#18](https://github.com/weaveworks/flagger/pull/18)
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha2
|
||||
- Implement canary external checks based on webhooks HTTP POST calls
|
||||
- Add webhooks to Canary CRD
|
||||
- Move docs to gitbook [docs.flagger.app](https://docs.flagger.app)
|
||||
|
||||
## 0.1.2 (2018-12-06)
|
||||
|
||||
Improve Slack notifications [#14](https://github.com/weaveworks/flagger/pull/14)
|
||||
|
||||
#### Features
|
||||
|
||||
- Add canary analysis metadata to init and start Slack messages
|
||||
- Add rollback reason to failed canary Slack messages
|
||||
|
||||
## 0.1.1 (2018-11-28)
|
||||
|
||||
Canary progress deadline [#10](https://github.com/weaveworks/flagger/pull/10)
|
||||
|
||||
#### Features
|
||||
|
||||
- Rollback canary based on the deployment progress deadline check
|
||||
- Add progress deadline to Canary CRD (defaults to 10 minutes)
|
||||
|
||||
## 0.1.0 (2018-11-25)
|
||||
|
||||
First stable release
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha1
|
||||
- Notifications: post canary events to Slack
|
||||
- Instrumentation: expose Prometheus metrics for canary status and traffic weight percentage
|
||||
- Autoscaling: add HPA reference to CRD and create primary HPA at bootstrap
|
||||
- Bootstrap: create primary deployment, ClusterIP services and Istio virtual service based on CRD spec
|
||||
|
||||
|
||||
## 0.0.1 (2018-10-07)
|
||||
|
||||
Initial semver release
|
||||
|
||||
#### Features
|
||||
|
||||
- Implement canary rollback based on failed checks threshold
|
||||
- Scale up the deployment when canary revision changes
|
||||
- Add OpenAPI v3 schema validation to Canary CRD
|
||||
- Use CRD status for canary state persistence
|
||||
- Add Helm charts for Flagger and Grafana
|
||||
- Add canary analysis Grafana dashboard
|
||||
12
Dockerfile
@@ -1,17 +1,17 @@
|
||||
FROM golang:1.11
|
||||
FROM golang:1.12
|
||||
|
||||
RUN mkdir -p /go/src/github.com/stefanprodan/flagger/
|
||||
RUN mkdir -p /go/src/github.com/weaveworks/flagger/
|
||||
|
||||
WORKDIR /go/src/github.com/stefanprodan/flagger
|
||||
WORKDIR /go/src/github.com/weaveworks/flagger
|
||||
|
||||
COPY . .
|
||||
|
||||
RUN GIT_COMMIT=$(git rev-list -1 HEAD) && \
|
||||
CGO_ENABLED=0 GOOS=linux go build -ldflags "-s -w \
|
||||
-X github.com/stefanprodan/flagger/pkg/version.REVISION=${GIT_COMMIT}" \
|
||||
-X github.com/weaveworks/flagger/pkg/version.REVISION=${GIT_COMMIT}" \
|
||||
-a -installsuffix cgo -o flagger ./cmd/flagger/*
|
||||
|
||||
FROM alpine:3.8
|
||||
FROM alpine:3.9
|
||||
|
||||
RUN addgroup -S flagger \
|
||||
&& adduser -S -g flagger flagger \
|
||||
@@ -19,7 +19,7 @@ RUN addgroup -S flagger \
|
||||
|
||||
WORKDIR /home/flagger
|
||||
|
||||
COPY --from=0 /go/src/github.com/stefanprodan/flagger/flagger .
|
||||
COPY --from=0 /go/src/github.com/weaveworks/flagger/flagger .
|
||||
|
||||
RUN chown -R flagger:flagger ./
|
||||
|
||||
|
||||
@@ -1,24 +1,8 @@
|
||||
FROM golang:1.11 AS hey-builder
|
||||
FROM golang:1.12 AS builder
|
||||
|
||||
RUN mkdir -p /go/src/github.com/rakyll/hey/
|
||||
RUN mkdir -p /go/src/github.com/weaveworks/flagger/
|
||||
|
||||
WORKDIR /go/src/github.com/rakyll/hey
|
||||
|
||||
ADD https://github.com/rakyll/hey/archive/v0.1.1.tar.gz .
|
||||
|
||||
RUN tar xzf v0.1.1.tar.gz --strip 1
|
||||
|
||||
RUN go get ./...
|
||||
|
||||
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 \
|
||||
go install -ldflags '-w -extldflags "-static"' \
|
||||
/go/src/github.com/rakyll/hey
|
||||
|
||||
FROM golang:1.11 AS builder
|
||||
|
||||
RUN mkdir -p /go/src/github.com/stefanprodan/flagger/
|
||||
|
||||
WORKDIR /go/src/github.com/stefanprodan/flagger
|
||||
WORKDIR /go/src/github.com/weaveworks/flagger
|
||||
|
||||
COPY . .
|
||||
|
||||
@@ -26,16 +10,18 @@ RUN go test -race ./pkg/loadtester/
|
||||
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o loadtester ./cmd/loadtester/*
|
||||
|
||||
FROM alpine:3.8
|
||||
FROM bats/bats:v1.1.0
|
||||
|
||||
RUN addgroup -S app \
|
||||
&& adduser -S -g app app \
|
||||
&& apk --no-cache add ca-certificates curl
|
||||
&& apk --no-cache add ca-certificates curl jq
|
||||
|
||||
WORKDIR /home/app
|
||||
|
||||
COPY --from=hey-builder /go/bin/hey /usr/local/bin/hey
|
||||
COPY --from=builder /go/src/github.com/stefanprodan/flagger/loadtester .
|
||||
RUN curl -sSLo hey "https://storage.googleapis.com/jblabs/dist/hey_linux_v0.1.2" && \
|
||||
chmod +x hey && mv hey /usr/local/bin/hey
|
||||
|
||||
COPY --from=builder /go/src/github.com/weaveworks/flagger/loadtester .
|
||||
|
||||
RUN chown -R app:app ./
|
||||
|
||||
|
||||
694
Gopkg.lock
generated
38
Gopkg.toml
@@ -11,31 +11,37 @@ required = [
|
||||
name = "go.uber.org/zap"
|
||||
version = "v1.9.1"
|
||||
|
||||
[[constraint]]
|
||||
name = "gopkg.in/h2non/gock.v1"
|
||||
version = "v1.0.14"
|
||||
|
||||
[[override]]
|
||||
name = "gopkg.in/yaml.v2"
|
||||
version = "v2.2.1"
|
||||
|
||||
[[override]]
|
||||
name = "k8s.io/api"
|
||||
version = "kubernetes-1.11.0"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[override]]
|
||||
name = "k8s.io/apimachinery"
|
||||
version = "kubernetes-1.11.0"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[override]]
|
||||
name = "k8s.io/code-generator"
|
||||
version = "kubernetes-1.11.0"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[override]]
|
||||
name = "k8s.io/client-go"
|
||||
version = "kubernetes-1.11.0"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[override]]
|
||||
name = "github.com/json-iterator/go"
|
||||
# This is the commit at which k8s depends on this in 1.11
|
||||
# It seems to be broken at HEAD.
|
||||
revision = "f2b4162afba35581b6d4a50d3b8f34e33c144682"
|
||||
name = "k8s.io/apiextensions-apiserver"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[override]]
|
||||
name = "k8s.io/apiserver"
|
||||
version = "kubernetes-1.13.1"
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/prometheus/client_golang"
|
||||
@@ -45,13 +51,9 @@ required = [
|
||||
name = "github.com/google/go-cmp"
|
||||
version = "v0.2.0"
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/knative/pkg"
|
||||
revision = "c15d7c8f2220a7578b33504df6edefa948c845ae"
|
||||
|
||||
[[override]]
|
||||
name = "github.com/golang/glog"
|
||||
source = "github.com/istio/glog"
|
||||
name = "k8s.io/klog"
|
||||
source = "github.com/stefanprodan/klog"
|
||||
|
||||
[prune]
|
||||
go-tests = true
|
||||
@@ -62,3 +64,11 @@ required = [
|
||||
name = "k8s.io/code-generator"
|
||||
unused-packages = false
|
||||
non-go = false
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/solo-io/supergloo"
|
||||
version = "v0.3.11"
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/solo-io/solo-kit"
|
||||
version = "v0.6.3"
|
||||
|
||||
5
MAINTAINERS
Normal file
@@ -0,0 +1,5 @@
|
||||
The maintainers are generally available in Slack at
|
||||
https://weave-community.slack.com/messages/flagger/ (obtain an invitation
|
||||
at https://slack.weave.works/).
|
||||
|
||||
Stefan Prodan, Weaveworks <stefan@weave.works> (Slack: @stefan Twitter: @stefanprodan)
|
||||
23
Makefile
@@ -4,19 +4,26 @@ VERSION_MINOR:=$(shell grep 'VERSION' pkg/version/version.go | awk '{ print $$4
|
||||
PATCH:=$(shell grep 'VERSION' pkg/version/version.go | awk '{ print $$4 }' | tr -d '"' | awk -F. '{print $$NF}')
|
||||
SOURCE_DIRS = cmd pkg/apis pkg/controller pkg/server pkg/logging pkg/version
|
||||
LT_VERSION?=$(shell grep 'VERSION' cmd/loadtester/main.go | awk '{ print $$4 }' | tr -d '"' | head -n1)
|
||||
TS=$(shell date +%Y-%m-%d_%H-%M-%S)
|
||||
|
||||
run:
|
||||
go run cmd/flagger/* -kubeconfig=$$HOME/.kube/config -log-level=info \
|
||||
-metrics-server=https://prometheus.iowa.weavedx.com \
|
||||
-metrics-server=https://prometheus.istio.weavedx.com \
|
||||
-slack-url=https://hooks.slack.com/services/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 \
|
||||
-slack-channel="devops-alerts"
|
||||
|
||||
run-appmesh:
|
||||
go run cmd/flagger/* -kubeconfig=$$HOME/.kube/config -log-level=info -mesh-provider=appmesh \
|
||||
-metrics-server=http://acfc235624ca911e9a94c02c4171f346-1585187926.us-west-2.elb.amazonaws.com:9090 \
|
||||
-slack-url=https://hooks.slack.com/services/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 \
|
||||
-slack-channel="devops-alerts"
|
||||
|
||||
build:
|
||||
docker build -t stefanprodan/flagger:$(TAG) . -f Dockerfile
|
||||
docker build -t weaveworks/flagger:$(TAG) . -f Dockerfile
|
||||
|
||||
push:
|
||||
docker tag stefanprodan/flagger:$(TAG) quay.io/stefanprodan/flagger:$(VERSION)
|
||||
docker push quay.io/stefanprodan/flagger:$(VERSION)
|
||||
docker tag weaveworks/flagger:$(TAG) weaveworks/flagger:$(VERSION)
|
||||
docker push weaveworks/flagger:$(VERSION)
|
||||
|
||||
fmt:
|
||||
gofmt -l -s -w $(SOURCE_DIRS)
|
||||
@@ -31,9 +38,9 @@ test: test-fmt test-codegen
|
||||
go test ./...
|
||||
|
||||
helm-package:
|
||||
cd charts/ && helm package flagger/ && helm package grafana/ && helm package loadtester/
|
||||
cd charts/ && helm package ./*
|
||||
mv charts/*.tgz docs/
|
||||
helm repo index docs --url https://stefanprodan.github.io/flagger --merge ./docs/index.yaml
|
||||
helm repo index docs --url https://weaveworks.github.io/flagger --merge ./docs/index.yaml
|
||||
|
||||
helm-up:
|
||||
helm upgrade --install flagger ./charts/flagger --namespace=istio-system --set crd.create=false
|
||||
@@ -82,5 +89,5 @@ reset-test:
|
||||
kubectl apply -f ./artifacts/canaries
|
||||
|
||||
loadtester-push:
|
||||
docker build -t quay.io/stefanprodan/flagger-loadtester:$(LT_VERSION) . -f Dockerfile.loadtester
|
||||
docker push quay.io/stefanprodan/flagger-loadtester:$(LT_VERSION)
|
||||
docker build -t weaveworks/flagger-loadtester:$(LT_VERSION) . -f Dockerfile.loadtester
|
||||
docker push weaveworks/flagger-loadtester:$(LT_VERSION)
|
||||
473
README.md
@@ -1,79 +1,58 @@
|
||||
# flagger
|
||||
|
||||
[](https://travis-ci.org/stefanprodan/flagger)
|
||||
[](https://goreportcard.com/report/github.com/stefanprodan/flagger)
|
||||
[](https://codecov.io/gh/stefanprodan/flagger)
|
||||
[](https://github.com/stefanprodan/flagger/blob/master/LICENSE)
|
||||
[](https://github.com/stefanprodan/flagger/releases)
|
||||
[](https://travis-ci.org/weaveworks/flagger)
|
||||
[](https://goreportcard.com/report/github.com/weaveworks/flagger)
|
||||
[](https://codecov.io/gh/weaveworks/flagger)
|
||||
[](https://github.com/weaveworks/flagger/blob/master/LICENSE)
|
||||
[](https://github.com/weaveworks/flagger/releases)
|
||||
|
||||
Flagger is a Kubernetes operator that automates the promotion of canary deployments
|
||||
using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running integration tests,
|
||||
using Istio or App Mesh routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running acceptance tests,
|
||||
load tests or any other custom validation.
|
||||
|
||||
### Install
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pods health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||
Before installing Flagger make sure you have Istio setup up with Prometheus enabled.
|
||||
If you are new to Istio you can follow my [Istio service mesh walk-through](https://github.com/stefanprodan/istio-gke).
|
||||
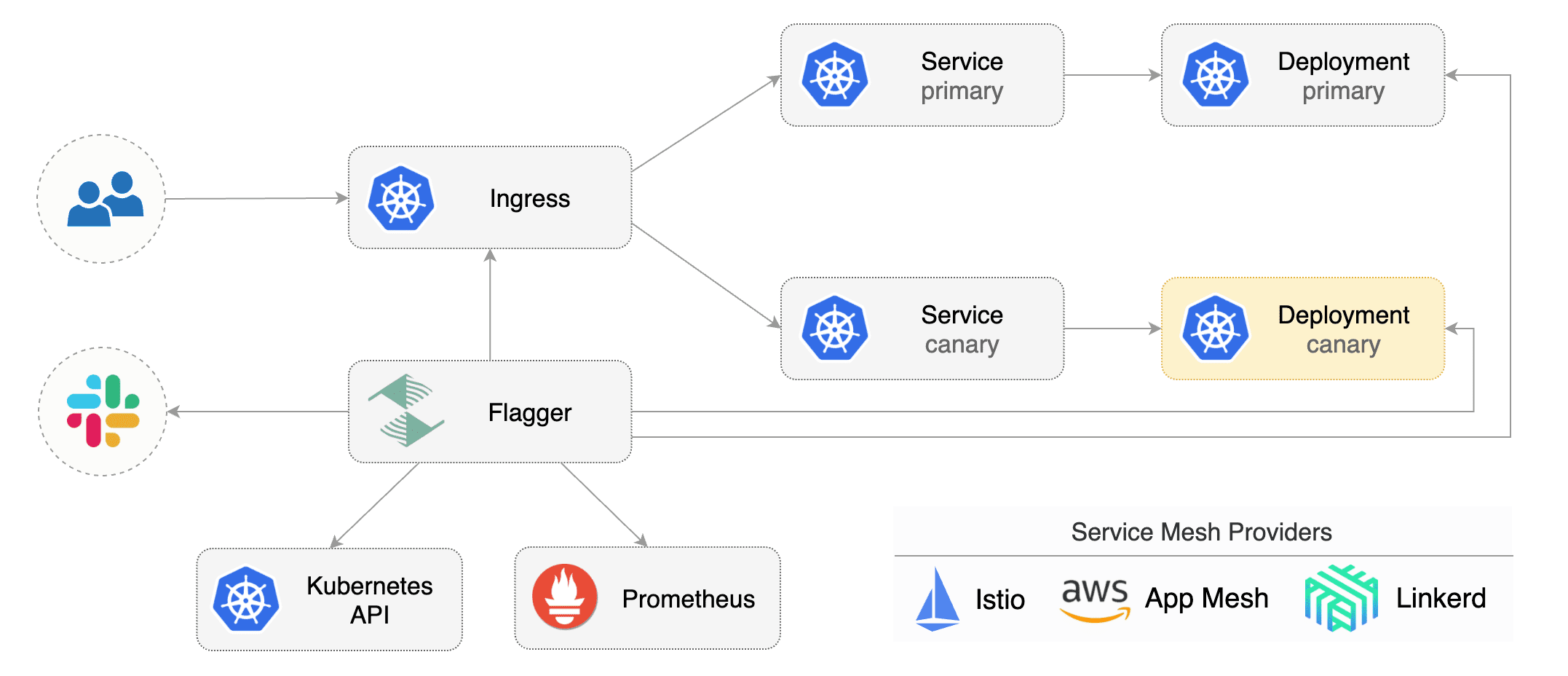
|
||||
|
||||
Deploy Flagger in the `istio-system` namespace using Helm:
|
||||
## Documentation
|
||||
|
||||
```bash
|
||||
# add the Helm repository
|
||||
helm repo add flagger https://flagger.app
|
||||
Flagger documentation can be found at [docs.flagger.app](https://docs.flagger.app)
|
||||
|
||||
# install or upgrade
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090
|
||||
```
|
||||
* Install
|
||||
* [Flagger install on Kubernetes](https://docs.flagger.app/install/flagger-install-on-kubernetes)
|
||||
* [Flagger install on GKE Istio](https://docs.flagger.app/install/flagger-install-on-google-cloud)
|
||||
* [Flagger install on EKS App Mesh](https://docs.flagger.app/install/flagger-install-on-eks-appmesh)
|
||||
* [Flagger install with SuperGloo](https://docs.flagger.app/install/flagger-install-with-supergloo)
|
||||
* How it works
|
||||
* [Canary custom resource](https://docs.flagger.app/how-it-works#canary-custom-resource)
|
||||
* [Routing](https://docs.flagger.app/how-it-works#istio-routing)
|
||||
* [Canary deployment stages](https://docs.flagger.app/how-it-works#canary-deployment)
|
||||
* [Canary analysis](https://docs.flagger.app/how-it-works#canary-analysis)
|
||||
* [HTTP metrics](https://docs.flagger.app/how-it-works#http-metrics)
|
||||
* [Custom metrics](https://docs.flagger.app/how-it-works#custom-metrics)
|
||||
* [Webhooks](https://docs.flagger.app/how-it-works#webhooks)
|
||||
* [Load testing](https://docs.flagger.app/how-it-works#load-testing)
|
||||
* Usage
|
||||
* [Istio canary deployments](https://docs.flagger.app/usage/progressive-delivery)
|
||||
* [Istio A/B testing](https://docs.flagger.app/usage/ab-testing)
|
||||
* [App Mesh canary deployments](https://docs.flagger.app/usage/appmesh-progressive-delivery)
|
||||
* [Monitoring](https://docs.flagger.app/usage/monitoring)
|
||||
* [Alerting](https://docs.flagger.app/usage/alerting)
|
||||
* Tutorials
|
||||
* [Canary deployments with Helm charts and Weave Flux](https://docs.flagger.app/tutorials/canary-helm-gitops)
|
||||
|
||||
Flagger is compatible with Kubernetes >1.11.0 and Istio >1.0.0.
|
||||
## Canary CRD
|
||||
|
||||
### Usage
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Istio or App Mesh virtual services).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
|
||||
Flagger takes a Kubernetes deployment and creates a series of objects
|
||||
(Kubernetes [deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/),
|
||||
ClusterIP [services](https://kubernetes.io/docs/concepts/services-networking/service/) and
|
||||
Istio [virtual services](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#VirtualService))
|
||||
to drive the canary analysis and promotion.
|
||||
|
||||
Flagger keeps track of ConfigMaps and Secrets referenced by a Kubernetes Deployment and triggers a canary analysis if any of those objects change.
|
||||
Flagger keeps track of ConfigMaps and Secrets referenced by a Kubernetes Deployment and triggers a canary analysis if any of those objects change.
|
||||
When promoting a workload in production, both code (container images) and configuration (config maps and secrets) are being synchronised.
|
||||
|
||||
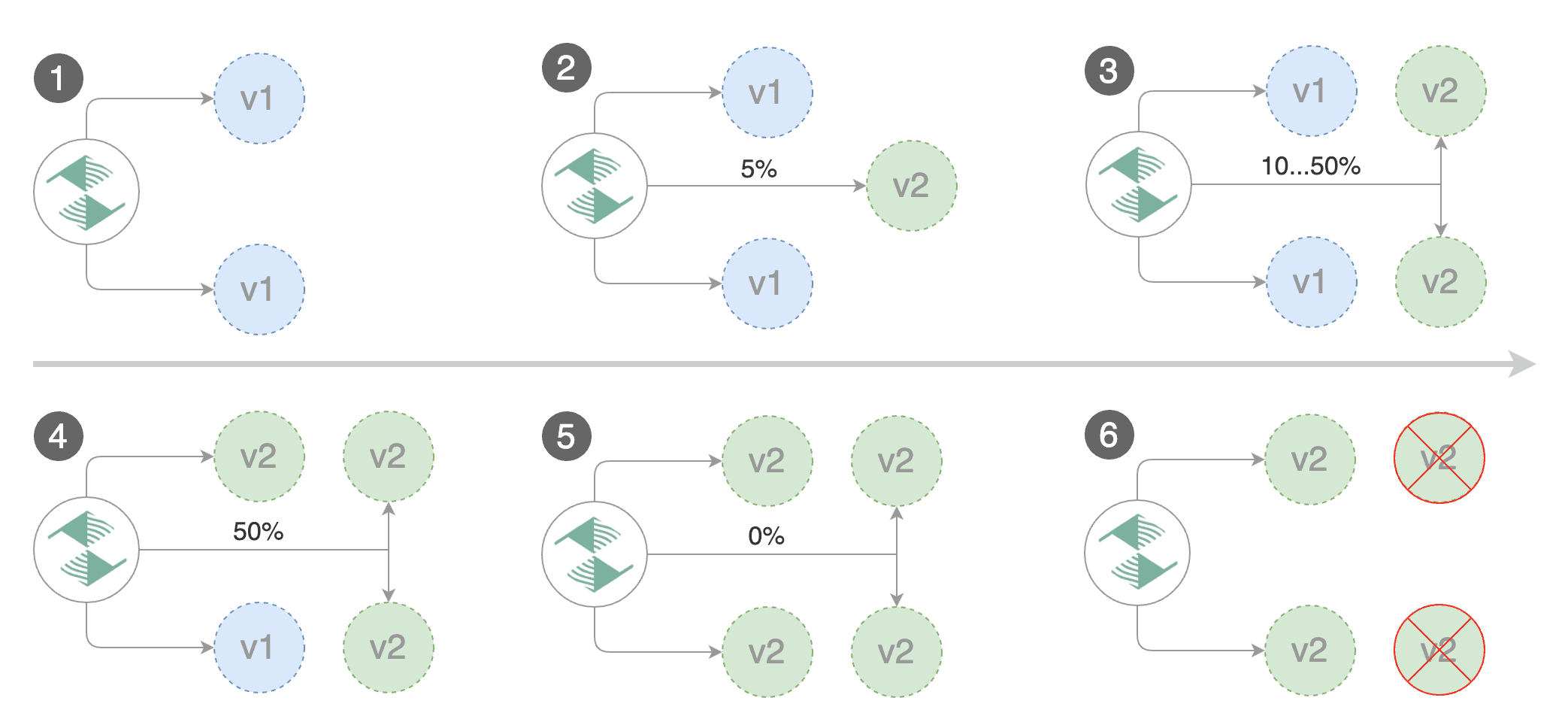
|
||||
|
||||
Gated canary promotion stages:
|
||||
|
||||
* scan for canary deployments
|
||||
* check Istio virtual service routes are mapped to primary and canary ClusterIP services
|
||||
* check primary and canary deployments status
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* increase canary traffic weight percentage from 0% to 5% (step weight)
|
||||
* call webhooks and check results
|
||||
* check canary HTTP request success rate and latency
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* check if the number of failed checks reached the threshold
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* wait for the canary deployment to be updated and start over
|
||||
* increase canary traffic weight by 5% (step weight) till it reaches 50% (max weight)
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
* halt advancement while canary deployment is being scaled up/down by HPA
|
||||
* promote canary to primary
|
||||
* copy ConfigMaps and Secrets from canary to primary
|
||||
* copy canary deployment spec template over primary
|
||||
* wait for primary rolling update to finish
|
||||
* halt advancement if pods are unhealthy
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment
|
||||
* mark rollout as finished
|
||||
* wait for the canary deployment to be updated and start over
|
||||
|
||||
For a deployment named _podinfo_, a canary promotion can be defined using Flagger's custom resource:
|
||||
|
||||
```yaml
|
||||
@@ -102,9 +81,31 @@ spec:
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- podinfo.example.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# cross-origin resource sharing policy (optional)
|
||||
corsPolicy:
|
||||
allowOrigin:
|
||||
- example.com
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
@@ -118,16 +119,27 @@ spec:
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
# builtin checks
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# custom check
|
||||
- name: "kafka lag"
|
||||
threshold: 100
|
||||
query: |
|
||||
avg_over_time(
|
||||
kafka_consumergroup_lag{
|
||||
consumergroup=~"podinfo-consumer-.*",
|
||||
topic="podinfo"
|
||||
}[1m]
|
||||
)
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: load-test
|
||||
@@ -137,322 +149,47 @@ spec:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
The canary analysis is using the following promql queries:
|
||||
|
||||
_HTTP requests success rate percentage_
|
||||
For more details on how the canary analysis and promotion works please [read the docs](https://docs.flagger.app/how-it-works).
|
||||
|
||||
```sql
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload",
|
||||
response_code!~"5.*"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
```
|
||||
## Features
|
||||
|
||||
_HTTP requests milliseconds duration P99_
|
||||
| Feature | Istio | App Mesh | SuperGloo |
|
||||
| -------------------------------------------- | ------------------ | ------------------ |------------------ |
|
||||
| Canary deployments (weighted traffic) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| A/B testing (headers and cookies filters) | :heavy_check_mark: | :heavy_minus_sign: | :heavy_minus_sign: |
|
||||
| Load testing | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Webhooks (custom acceptance tests) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Request success rate check (Envoy metric) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Request duration check (Envoy metric) | :heavy_check_mark: | :heavy_minus_sign: | :heavy_check_mark: |
|
||||
| Custom promql checks | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Ingress gateway (CORS, retries and timeouts) | :heavy_check_mark: | :heavy_minus_sign: | :heavy_check_mark: |
|
||||
|
||||
```sql
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
irate(
|
||||
istio_request_duration_seconds_bucket{
|
||||
reporter="destination",
|
||||
destination_workload=~"$workload",
|
||||
destination_workload_namespace=~"$namespace"
|
||||
}[$interval]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
## Roadmap
|
||||
|
||||
The canary analysis can be extended with webhooks.
|
||||
Flagger will call the webhooks (HTTP POST) and determine from the response status code (HTTP 2xx) if the canary is failing or not.
|
||||
|
||||
Webhook payload:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "podinfo",
|
||||
"namespace": "test",
|
||||
"metadata": {
|
||||
"test": "all",
|
||||
"token": "16688eb5e9f289f1991c"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Automated canary analysis, promotions and rollbacks
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/deployment.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/hpa.yaml
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
```
|
||||
|
||||
Create a canary promotion custom resource (replace the Istio gateway and the internet domain with your own):
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
virtualservice.networking.istio.io/podinfo
|
||||
```
|
||||
|
||||
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.4.0
|
||||
```
|
||||
|
||||
**Note** that Flagger tracks changes in the deployment `PodSpec` but also in `ConfigMaps` and `Secrets`
|
||||
that are referenced in the pod's volumes and containers environment variables.
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new canary analysis:
|
||||
|
||||
```
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Last Transition Time: 2019-01-16T13:47:16Z
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 5 2019-01-16T14:05:07Z
|
||||
```
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Create a tester pod and exec into it:
|
||||
|
||||
```bash
|
||||
kubectl -n test run tester --image=quay.io/stefanprodan/podinfo:1.2.1 -- ./podinfo --port=9898
|
||||
kubectl -n test exec -it tester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Last Transition Time: 2019-01-16T13:47:16Z
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
### Monitoring
|
||||
|
||||
Flagger comes with a Grafana dashboard made for canary analysis.
|
||||
|
||||
Install Grafana with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
The dashboard shows the RED and USE metrics for the primary and canary workloads:
|
||||
|
||||
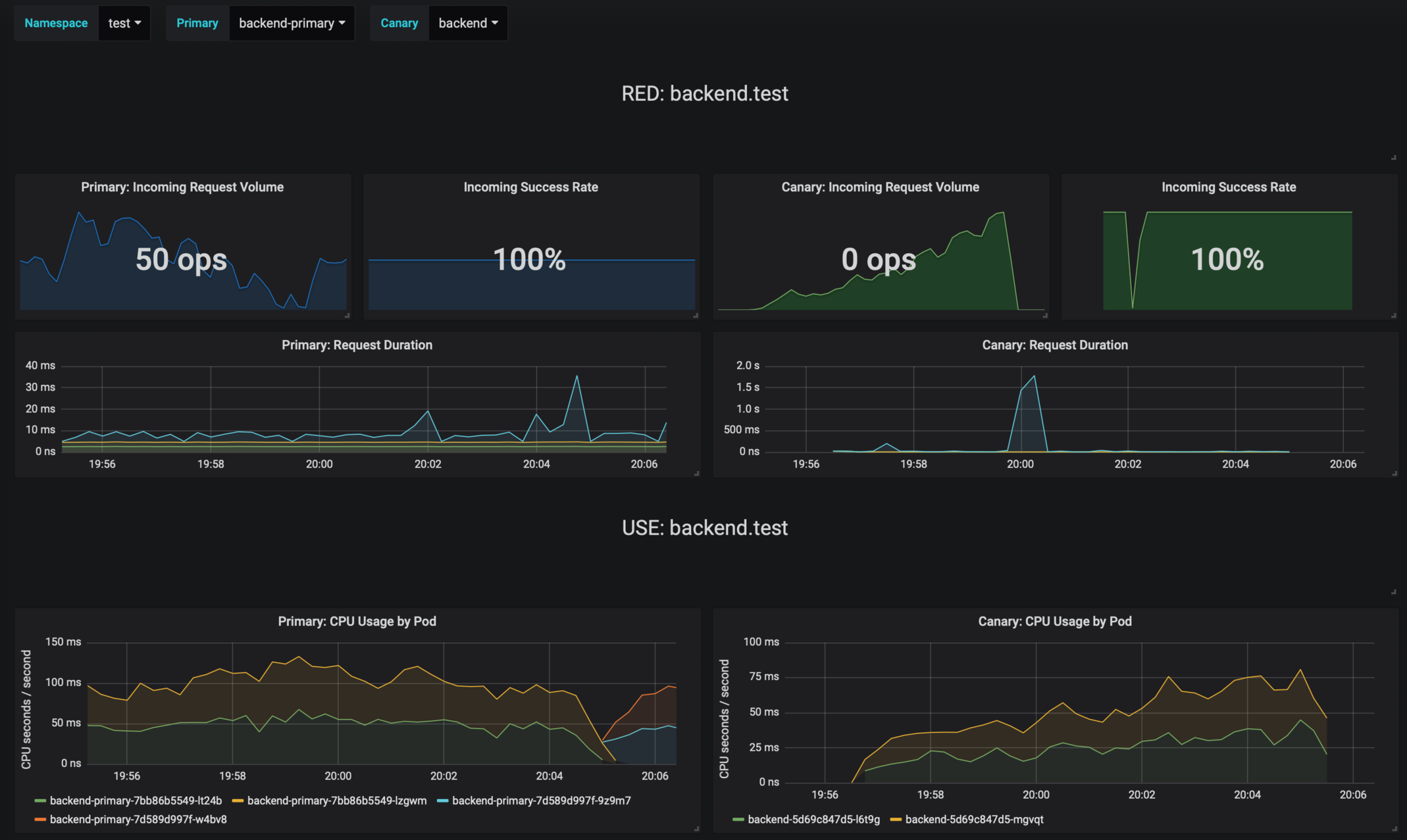
|
||||
|
||||
The canary errors and latency spikes have been recorded as Kubernetes events and logged by Flagger in json format:
|
||||
|
||||
```
|
||||
kubectl -n istio-system logs deployment/flagger --tail=100 | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Halt podinfo.test advancement success rate 98.69% < 99%
|
||||
Advance podinfo.test canary weight 40
|
||||
Halt podinfo.test advancement request duration 1.515s > 500ms
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Halt podinfo-primary.test advancement waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Scaling down podinfo.test
|
||||
Promotion completed! podinfo.test
|
||||
```
|
||||
|
||||
Flagger exposes Prometheus metrics that can be used to determine the canary analysis status and the destination weight values:
|
||||
|
||||
```bash
|
||||
# Canaries total gauge
|
||||
flagger_canary_total{namespace="test"} 1
|
||||
|
||||
# Canary promotion last known status gauge
|
||||
# 0 - running, 1 - successful, 2 - failed
|
||||
flagger_canary_status{name="podinfo" namespace="test"} 1
|
||||
|
||||
# Canary traffic weight gauge
|
||||
flagger_canary_weight{workload="podinfo-primary" namespace="test"} 95
|
||||
flagger_canary_weight{workload="podinfo" namespace="test"} 5
|
||||
|
||||
# Seconds spent performing canary analysis histogram
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="10"} 6
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="+Inf"} 6
|
||||
flagger_canary_duration_seconds_sum{name="podinfo",namespace="test"} 17.3561329
|
||||
flagger_canary_duration_seconds_count{name="podinfo",namespace="test"} 6
|
||||
```
|
||||
|
||||
### Alerting
|
||||
|
||||
Flagger can be configured to send Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Once configured with a Slack incoming webhook, Flagger will post messages when a canary deployment has been initialized,
|
||||
when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||

|
||||
|
||||
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis
|
||||
reached the maximum number of failed checks:
|
||||
|
||||
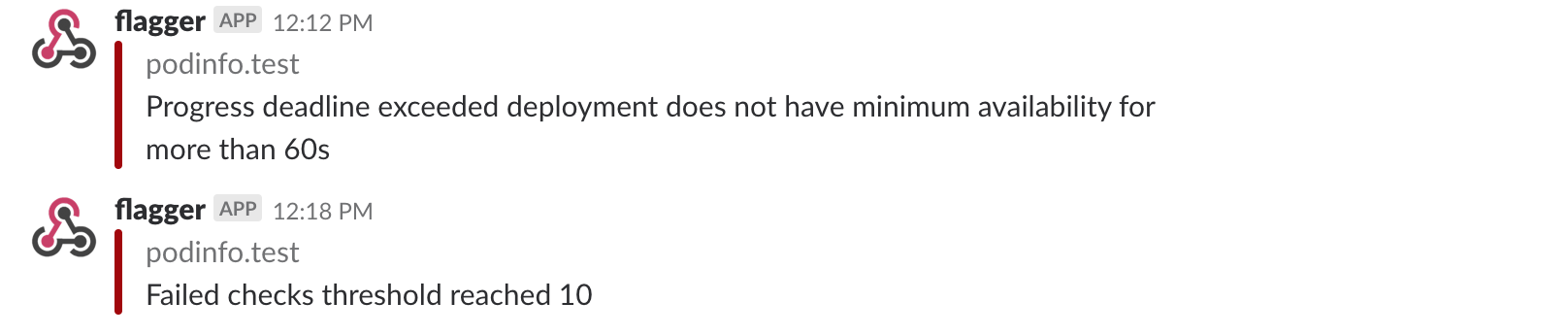
|
||||
|
||||
Besides Slack, you can use Alertmanager to trigger alerts when a canary deployment failed:
|
||||
|
||||
```yaml
|
||||
- alert: canary_rollback
|
||||
expr: flagger_canary_status > 1
|
||||
for: 1m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "Canary failed"
|
||||
description: "Workload {{ $labels.name }} namespace {{ $labels.namespace }}"
|
||||
```
|
||||
|
||||
### Roadmap
|
||||
|
||||
* Extend the validation mechanism to support other metrics than HTTP success rate and latency
|
||||
* Integrate with other service mesh technologies like Linkerd v2
|
||||
* Add support for comparing the canary metrics to the primary ones and do the validation based on the derivation between the two
|
||||
* Extend the canary analysis and promotion to other types than Kubernetes deployments such as Flux Helm releases or OpenFaaS functions
|
||||
|
||||
### Contributing
|
||||
## Contributing
|
||||
|
||||
Flagger is Apache 2.0 licensed and accepts contributions via GitHub pull requests.
|
||||
|
||||
When submitting bug reports please include as much details as possible:
|
||||
When submitting bug reports please include as much details as possible:
|
||||
|
||||
* which Flagger version
|
||||
* which Flagger CRD version
|
||||
* which Kubernetes/Istio version
|
||||
* what configuration (canary, virtual service and workloads definitions)
|
||||
* what happened (Flagger, Istio Pilot and Proxy logs)
|
||||
|
||||
## Getting Help
|
||||
|
||||
If you have any questions about Flagger and progressive delivery:
|
||||
|
||||
* Read the Flagger [docs](https://docs.flagger.app).
|
||||
* Invite yourself to the [Weave community slack](https://slack.weave.works/)
|
||||
and join the [#flagger](https://weave-community.slack.com/messages/flagger/) channel.
|
||||
* Join the [Weave User Group](https://www.meetup.com/pro/Weave/) and get invited to online talks,
|
||||
hands-on training and meetups in your area.
|
||||
* File an [issue](https://github.com/weaveworks/flagger/issues/new).
|
||||
|
||||
Your feedback is always welcome!
|
||||
|
||||
62
artifacts/ab-testing/canary.yaml
Normal file
@@ -0,0 +1,62 @@
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: abtest
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: abtest
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: abtest
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- abtest.istio.weavedx.com
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# canary match condition
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: "^(?!.*Chrome)(?=.*\bSafari\b).*$"
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(type=insider)(;.*)?$"
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: type=insider' http://podinfo.test:9898/"
|
||||
67
artifacts/ab-testing/deployment.yaml
Normal file
@@ -0,0 +1,67 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: abtest
|
||||
namespace: test
|
||||
labels:
|
||||
app: abtest
|
||||
spec:
|
||||
minReadySeconds: 5
|
||||
revisionHistoryLimit: 5
|
||||
progressDeadlineSeconds: 60
|
||||
strategy:
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
type: RollingUpdate
|
||||
selector:
|
||||
matchLabels:
|
||||
app: abtest
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
prometheus.io/scrape: "true"
|
||||
labels:
|
||||
app: abtest
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.4.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
name: http
|
||||
protocol: TCP
|
||||
command:
|
||||
- ./podinfo
|
||||
- --port=9898
|
||||
- --level=info
|
||||
- --random-delay=false
|
||||
- --random-error=false
|
||||
env:
|
||||
- name: PODINFO_UI_COLOR
|
||||
value: blue
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/healthz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/readyz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2000m
|
||||
memory: 512Mi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 64Mi
|
||||
19
artifacts/ab-testing/hpa.yaml
Normal file
@@ -0,0 +1,19 @@
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: abtest
|
||||
namespace: test
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: abtest
|
||||
minReplicas: 2
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
# scale up if usage is above
|
||||
# 99% of the requested CPU (100m)
|
||||
targetAverageUtilization: 99
|
||||
50
artifacts/appmesh/canary.yaml
Normal file
@@ -0,0 +1,50 @@
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# App Mesh reference
|
||||
meshName: global
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# App Mesh Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
65
artifacts/appmesh/deployment.yaml
Normal file
@@ -0,0 +1,65 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
labels:
|
||||
app: podinfo
|
||||
spec:
|
||||
minReadySeconds: 5
|
||||
revisionHistoryLimit: 5
|
||||
progressDeadlineSeconds: 60
|
||||
strategy:
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
type: RollingUpdate
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
prometheus.io/scrape: "true"
|
||||
labels:
|
||||
app: podinfo
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.4.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
name: http
|
||||
protocol: TCP
|
||||
command:
|
||||
- ./podinfo
|
||||
- --port=9898
|
||||
- --level=info
|
||||
env:
|
||||
- name: PODINFO_UI_COLOR
|
||||
value: blue
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/healthz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/readyz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2000m
|
||||
memory: 512Mi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 64Mi
|
||||
6
artifacts/appmesh/global-mesh.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
apiVersion: appmesh.k8s.aws/v1beta1
|
||||
kind: Mesh
|
||||
metadata:
|
||||
name: global
|
||||
spec:
|
||||
serviceDiscoveryType: dns
|
||||
19
artifacts/appmesh/hpa.yaml
Normal file
@@ -0,0 +1,19 @@
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
minReplicas: 2
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
# scale up if usage is above
|
||||
# 99% of the requested CPU (100m)
|
||||
targetAverageUtilization: 99
|
||||
177
artifacts/appmesh/ingress.yaml
Normal file
@@ -0,0 +1,177 @@
|
||||
---
|
||||
kind: ConfigMap
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: ingress-config
|
||||
namespace: test
|
||||
labels:
|
||||
app: ingress
|
||||
data:
|
||||
envoy.yaml: |
|
||||
static_resources:
|
||||
listeners:
|
||||
- address:
|
||||
socket_address:
|
||||
address: 0.0.0.0
|
||||
port_value: 80
|
||||
filter_chains:
|
||||
- filters:
|
||||
- name: envoy.http_connection_manager
|
||||
config:
|
||||
access_log:
|
||||
- name: envoy.file_access_log
|
||||
config:
|
||||
path: /dev/stdout
|
||||
codec_type: auto
|
||||
stat_prefix: ingress_http
|
||||
http_filters:
|
||||
- name: envoy.router
|
||||
config: {}
|
||||
route_config:
|
||||
name: local_route
|
||||
virtual_hosts:
|
||||
- name: local_service
|
||||
domains: ["*"]
|
||||
routes:
|
||||
- match:
|
||||
prefix: "/"
|
||||
route:
|
||||
cluster: podinfo
|
||||
host_rewrite: podinfo.test
|
||||
timeout: 15s
|
||||
retry_policy:
|
||||
retry_on: "gateway-error,connect-failure,refused-stream"
|
||||
num_retries: 10
|
||||
per_try_timeout: 5s
|
||||
clusters:
|
||||
- name: podinfo
|
||||
connect_timeout: 0.30s
|
||||
type: strict_dns
|
||||
lb_policy: round_robin
|
||||
http2_protocol_options: {}
|
||||
hosts:
|
||||
- socket_address:
|
||||
address: podinfo.test
|
||||
port_value: 9898
|
||||
admin:
|
||||
access_log_path: /dev/null
|
||||
address:
|
||||
socket_address:
|
||||
address: 0.0.0.0
|
||||
port_value: 9999
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: ingress
|
||||
namespace: test
|
||||
labels:
|
||||
app: ingress
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: ingress
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: ingress
|
||||
annotations:
|
||||
prometheus.io/path: "/stats/prometheus"
|
||||
prometheus.io/port: "9999"
|
||||
prometheus.io/scrape: "true"
|
||||
# dummy port to exclude ingress from mesh traffic
|
||||
# only egress should go over the mesh
|
||||
appmesh.k8s.aws/ports: "444"
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 30
|
||||
containers:
|
||||
- name: ingress
|
||||
image: "envoyproxy/envoy-alpine:d920944aed67425f91fc203774aebce9609e5d9a"
|
||||
securityContext:
|
||||
capabilities:
|
||||
drop:
|
||||
- ALL
|
||||
add:
|
||||
- NET_BIND_SERVICE
|
||||
command:
|
||||
- /usr/bin/dumb-init
|
||||
- --
|
||||
args:
|
||||
- /usr/local/bin/envoy
|
||||
- --base-id 30
|
||||
- --v2-config-only
|
||||
- -l
|
||||
- $loglevel
|
||||
- -c
|
||||
- /config/envoy.yaml
|
||||
ports:
|
||||
- name: admin
|
||||
containerPort: 9999
|
||||
protocol: TCP
|
||||
- name: http
|
||||
containerPort: 80
|
||||
protocol: TCP
|
||||
- name: https
|
||||
containerPort: 443
|
||||
protocol: TCP
|
||||
livenessProbe:
|
||||
initialDelaySeconds: 5
|
||||
tcpSocket:
|
||||
port: admin
|
||||
readinessProbe:
|
||||
initialDelaySeconds: 5
|
||||
tcpSocket:
|
||||
port: admin
|
||||
resources:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 64Mi
|
||||
volumeMounts:
|
||||
- name: config
|
||||
mountPath: /config
|
||||
volumes:
|
||||
- name: config
|
||||
configMap:
|
||||
name: ingress-config
|
||||
---
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: ingress
|
||||
namespace: test
|
||||
spec:
|
||||
selector:
|
||||
app: ingress
|
||||
ports:
|
||||
- protocol: TCP
|
||||
name: http
|
||||
port: 80
|
||||
targetPort: 80
|
||||
- protocol: TCP
|
||||
name: https
|
||||
port: 443
|
||||
targetPort: 443
|
||||
type: LoadBalancer
|
||||
---
|
||||
apiVersion: appmesh.k8s.aws/v1beta1
|
||||
kind: VirtualNode
|
||||
metadata:
|
||||
name: ingress
|
||||
namespace: test
|
||||
spec:
|
||||
meshName: global
|
||||
listeners:
|
||||
- portMapping:
|
||||
port: 80
|
||||
protocol: http
|
||||
serviceDiscovery:
|
||||
dns:
|
||||
hostName: ingress.test
|
||||
backends:
|
||||
- virtualService:
|
||||
virtualServiceName: podinfo.test
|
||||
@@ -23,9 +23,26 @@ spec:
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.iowa.weavedx.com
|
||||
- app.istio.weavedx.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
@@ -39,12 +56,12 @@ spec:
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
@@ -55,4 +72,6 @@ spec:
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
logCmdOutput: "true"
|
||||
|
||||
@@ -25,7 +25,7 @@ spec:
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.3.0
|
||||
image: quay.io/stefanprodan/podinfo:1.4.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
|
||||
6
artifacts/cluster/namespaces/test.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: test
|
||||
labels:
|
||||
istio-injection: enabled
|
||||
26
artifacts/cluster/releases/test/backend.yaml
Normal file
@@ -0,0 +1,26 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: backend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: regexp:^1.4.*
|
||||
spec:
|
||||
releaseName: backend
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
httpServer:
|
||||
timeout: 30s
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: false
|
||||
loadtest:
|
||||
enabled: true
|
||||
27
artifacts/cluster/releases/test/frontend.yaml
Normal file
@@ -0,0 +1,27 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: semver:~1.4
|
||||
spec:
|
||||
releaseName: frontend
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
backend: http://backend-podinfo:9898/echo
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: true
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
host: frontend.istio.example.com
|
||||
loadtest:
|
||||
enabled: true
|
||||
18
artifacts/cluster/releases/test/loadtester.yaml
Normal file
@@ -0,0 +1,18 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: loadtester
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: glob:0.*
|
||||
spec:
|
||||
releaseName: flagger-loadtester
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: loadtester
|
||||
version: 0.1.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger-loadtester
|
||||
tag: 0.1.0
|
||||
@@ -23,6 +23,7 @@ spec:
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.iowa.weavedx.com
|
||||
@@ -39,12 +40,12 @@ spec:
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
|
||||
264
artifacts/eks/appmesh-prometheus.yaml
Normal file
@@ -0,0 +1,264 @@
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRole
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- nodes
|
||||
- services
|
||||
- endpoints
|
||||
- pods
|
||||
- nodes/proxy
|
||||
verbs: ["get", "list", "watch"]
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- configmaps
|
||||
verbs: ["get"]
|
||||
- nonResourceURLs: ["/metrics"]
|
||||
verbs: ["get"]
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
roleRef:
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
kind: ClusterRole
|
||||
name: prometheus
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: prometheus
|
||||
namespace: appmesh-system
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: appmesh-system
|
||||
labels:
|
||||
app: prometheus
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: appmesh-system
|
||||
labels:
|
||||
app: prometheus
|
||||
data:
|
||||
prometheus.yml: |-
|
||||
global:
|
||||
scrape_interval: 5s
|
||||
scrape_configs:
|
||||
|
||||
# Scrape config for AppMesh Envoy sidecar
|
||||
- job_name: 'appmesh-envoy'
|
||||
metrics_path: /stats/prometheus
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_pod_container_name]
|
||||
action: keep
|
||||
regex: '^envoy$'
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: ${1}:9901
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: kubernetes_namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: kubernetes_pod_name
|
||||
|
||||
# Exclude high cardinality metrics
|
||||
metric_relabel_configs:
|
||||
- source_labels: [ cluster_name ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ tcp_prefix ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ listener_address ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_listener_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tls.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tcp_downstream.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_http_(stats|admin).*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_cluster_(lb|retry|bind|internal|max|original).*'
|
||||
action: drop
|
||||
|
||||
# Scrape config for API servers
|
||||
- job_name: 'kubernetes-apiservers'
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- default
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: kubernetes;https
|
||||
|
||||
# Scrape config for nodes
|
||||
- job_name: 'kubernetes-nodes'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics
|
||||
|
||||
# scrape config for cAdvisor
|
||||
- job_name: 'kubernetes-cadvisor'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
|
||||
|
||||
# scrape config for pods
|
||||
- job_name: kubernetes-pods
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
relabel_configs:
|
||||
- action: keep
|
||||
regex: true
|
||||
source_labels:
|
||||
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
|
||||
- source_labels: [ __address__ ]
|
||||
regex: '.*9901.*'
|
||||
action: drop
|
||||
- action: replace
|
||||
regex: (.+)
|
||||
source_labels:
|
||||
- __meta_kubernetes_pod_annotation_prometheus_io_path
|
||||
target_label: __metrics_path__
|
||||
- action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
source_labels:
|
||||
- __address__
|
||||
- __meta_kubernetes_pod_annotation_prometheus_io_port
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- action: replace
|
||||
source_labels:
|
||||
- __meta_kubernetes_namespace
|
||||
target_label: kubernetes_namespace
|
||||
- action: replace
|
||||
source_labels:
|
||||
- __meta_kubernetes_pod_name
|
||||
target_label: kubernetes_pod_name
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: appmesh-system
|
||||
labels:
|
||||
app: prometheus
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: prometheus
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: prometheus
|
||||
annotations:
|
||||
version: "appmesh-v1alpha1"
|
||||
spec:
|
||||
serviceAccountName: prometheus
|
||||
containers:
|
||||
- name: prometheus
|
||||
image: "docker.io/prom/prometheus:v2.7.1"
|
||||
imagePullPolicy: IfNotPresent
|
||||
args:
|
||||
- '--storage.tsdb.retention=6h'
|
||||
- '--config.file=/etc/prometheus/prometheus.yml'
|
||||
ports:
|
||||
- containerPort: 9090
|
||||
name: http
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /-/healthy
|
||||
port: 9090
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
path: /-/ready
|
||||
port: 9090
|
||||
resources:
|
||||
requests:
|
||||
cpu: 10m
|
||||
memory: 128Mi
|
||||
volumeMounts:
|
||||
- name: config-volume
|
||||
mountPath: /etc/prometheus
|
||||
volumes:
|
||||
- name: config-volume
|
||||
configMap:
|
||||
name: prometheus
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: appmesh-system
|
||||
labels:
|
||||
name: prometheus
|
||||
spec:
|
||||
selector:
|
||||
app: prometheus
|
||||
ports:
|
||||
- name: http
|
||||
protocol: TCP
|
||||
port: 9090
|
||||
@@ -13,11 +13,50 @@ metadata:
|
||||
labels:
|
||||
app: flagger
|
||||
rules:
|
||||
- apiGroups: ['*']
|
||||
resources: ['*']
|
||||
verbs: ['*']
|
||||
- nonResourceURLs: ['*']
|
||||
verbs: ['*']
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- events
|
||||
- configmaps
|
||||
- secrets
|
||||
- services
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- apps
|
||||
resources:
|
||||
- deployments
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- autoscaling
|
||||
resources:
|
||||
- horizontalpodautoscalers
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries
|
||||
- canaries/status
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- networking.istio.io
|
||||
resources:
|
||||
- virtualservices
|
||||
- virtualservices/status
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- appmesh.k8s.aws
|
||||
resources:
|
||||
- meshes
|
||||
- meshes/status
|
||||
- virtualnodes
|
||||
- virtualnodes/status
|
||||
- virtualservices
|
||||
- virtualservices/status
|
||||
verbs: ["*"]
|
||||
- nonResourceURLs:
|
||||
- /version
|
||||
verbs:
|
||||
- get
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
|
||||
@@ -2,6 +2,8 @@ apiVersion: apiextensions.k8s.io/v1beta1
|
||||
kind: CustomResourceDefinition
|
||||
metadata:
|
||||
name: canaries.flagger.app
|
||||
annotations:
|
||||
helm.sh/resource-policy: keep
|
||||
spec:
|
||||
group: flagger.app
|
||||
version: v1alpha3
|
||||
@@ -39,9 +41,9 @@ spec:
|
||||
properties:
|
||||
spec:
|
||||
required:
|
||||
- targetRef
|
||||
- service
|
||||
- canaryAnalysis
|
||||
- targetRef
|
||||
- service
|
||||
- canaryAnalysis
|
||||
properties:
|
||||
progressDeadlineSeconds:
|
||||
type: number
|
||||
@@ -73,11 +75,21 @@ spec:
|
||||
properties:
|
||||
port:
|
||||
type: number
|
||||
portName:
|
||||
type: string
|
||||
meshName:
|
||||
type: string
|
||||
timeout:
|
||||
type: string
|
||||
skipAnalysis:
|
||||
type: boolean
|
||||
canaryAnalysis:
|
||||
properties:
|
||||
interval:
|
||||
type: string
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
iterations:
|
||||
type: number
|
||||
threshold:
|
||||
type: number
|
||||
maxWeight:
|
||||
@@ -89,7 +101,7 @@ spec:
|
||||
properties:
|
||||
items:
|
||||
type: object
|
||||
required: ['name', 'interval', 'threshold']
|
||||
required: ['name', 'threshold']
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
@@ -98,6 +110,8 @@ spec:
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
threshold:
|
||||
type: number
|
||||
query:
|
||||
type: string
|
||||
webhooks:
|
||||
type: array
|
||||
properties:
|
||||
@@ -107,9 +121,36 @@ spec:
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
type:
|
||||
type: string
|
||||
enum:
|
||||
- ""
|
||||
- pre-rollout
|
||||
- rollout
|
||||
- post-rollout
|
||||
url:
|
||||
type: string
|
||||
format: url
|
||||
timeout:
|
||||
type: string
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
status:
|
||||
properties:
|
||||
phase:
|
||||
type: string
|
||||
enum:
|
||||
- ""
|
||||
- Initialized
|
||||
- Progressing
|
||||
- Succeeded
|
||||
- Failed
|
||||
canaryWeight:
|
||||
type: number
|
||||
failedChecks:
|
||||
type: number
|
||||
iterations:
|
||||
type: number
|
||||
lastAppliedSpec:
|
||||
type: string
|
||||
lastTransitionTime:
|
||||
type: string
|
||||
|
||||
@@ -22,8 +22,8 @@ spec:
|
||||
serviceAccountName: flagger
|
||||
containers:
|
||||
- name: flagger
|
||||
image: quay.io/stefanprodan/flagger:0.5.0
|
||||
imagePullPolicy: Always
|
||||
image: weaveworks/flagger:0.12.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 8080
|
||||
@@ -31,6 +31,7 @@ spec:
|
||||
- ./flagger
|
||||
- -log-level=info
|
||||
- -control-loop-interval=10s
|
||||
- -mesh-provider=$(MESH_PROVIDER)
|
||||
- -metrics-server=http://prometheus.istio-system.svc.cluster.local:9090
|
||||
livenessProbe:
|
||||
exec:
|
||||
|
||||
27
artifacts/gke/istio-gateway.yaml
Normal file
@@ -0,0 +1,27 @@
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
httpsRedirect: true
|
||||
- port:
|
||||
number: 443
|
||||
name: https
|
||||
protocol: HTTPS
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
mode: SIMPLE
|
||||
privateKey: /etc/istio/ingressgateway-certs/tls.key
|
||||
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
|
||||
443
artifacts/gke/istio-prometheus.yaml
Normal file
@@ -0,0 +1,443 @@
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRole
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- nodes
|
||||
- services
|
||||
- endpoints
|
||||
- pods
|
||||
- nodes/proxy
|
||||
verbs: ["get", "list", "watch"]
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- configmaps
|
||||
verbs: ["get"]
|
||||
- nonResourceURLs: ["/metrics"]
|
||||
verbs: ["get"]
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
roleRef:
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
kind: ClusterRole
|
||||
name: prometheus
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
data:
|
||||
prometheus.yml: |-
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
scrape_configs:
|
||||
|
||||
- job_name: 'istio-mesh'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-telemetry;prometheus
|
||||
|
||||
|
||||
# Scrape config for envoy stats
|
||||
- job_name: 'envoy-stats'
|
||||
metrics_path: /stats/prometheus
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_pod_container_port_name]
|
||||
action: keep
|
||||
regex: '.*-envoy-prom'
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:15090
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
|
||||
metric_relabel_configs:
|
||||
# Exclude some of the envoy metrics that have massive cardinality
|
||||
# This list may need to be pruned further moving forward, as informed
|
||||
# by performance and scalability testing.
|
||||
- source_labels: [ cluster_name ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ tcp_prefix ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ listener_address ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_listener_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tls.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tcp_downstream.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_http_(stats|admin).*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_cluster_(lb|retry|bind|internal|max|original).*'
|
||||
action: drop
|
||||
|
||||
|
||||
- job_name: 'istio-policy'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-policy;http-monitoring
|
||||
|
||||
- job_name: 'istio-telemetry'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-telemetry;http-monitoring
|
||||
|
||||
- job_name: 'pilot'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-pilot;http-monitoring
|
||||
|
||||
- job_name: 'galley'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-galley;http-monitoring
|
||||
|
||||
# scrape config for API servers
|
||||
- job_name: 'kubernetes-apiservers'
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- default
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: kubernetes;https
|
||||
|
||||
# scrape config for nodes (kubelet)
|
||||
- job_name: 'kubernetes-nodes'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics
|
||||
|
||||
# Scrape config for Kubelet cAdvisor.
|
||||
#
|
||||
# This is required for Kubernetes 1.7.3 and later, where cAdvisor metrics
|
||||
# (those whose names begin with 'container_') have been removed from the
|
||||
# Kubelet metrics endpoint. This job scrapes the cAdvisor endpoint to
|
||||
# retrieve those metrics.
|
||||
#
|
||||
# In Kubernetes 1.7.0-1.7.2, these metrics are only exposed on the cAdvisor
|
||||
# HTTP endpoint; use "replacement: /api/v1/nodes/${1}:4194/proxy/metrics"
|
||||
# in that case (and ensure cAdvisor's HTTP server hasn't been disabled with
|
||||
# the --cadvisor-port=0 Kubelet flag).
|
||||
#
|
||||
# This job is not necessary and should be removed in Kubernetes 1.6 and
|
||||
# earlier versions, or it will cause the metrics to be scraped twice.
|
||||
- job_name: 'kubernetes-cadvisor'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
|
||||
|
||||
# scrape config for service endpoints.
|
||||
- job_name: 'kubernetes-service-endpoints'
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
|
||||
action: replace
|
||||
target_label: __scheme__
|
||||
regex: (https?)
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
target_label: __address__
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_service_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: kubernetes_namespace
|
||||
- source_labels: [__meta_kubernetes_service_name]
|
||||
action: replace
|
||||
target_label: kubernetes_name
|
||||
|
||||
- job_name: 'kubernetes-pods'
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
relabel_configs: # If first two labels are present, pod should be scraped by the istio-secure job.
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_sidecar_istio_io_status]
|
||||
action: drop
|
||||
regex: (.+)
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_istio_mtls]
|
||||
action: drop
|
||||
regex: (true)
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
|
||||
- job_name: 'kubernetes-pods-istio-secure'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /etc/istio-certs/root-cert.pem
|
||||
cert_file: /etc/istio-certs/cert-chain.pem
|
||||
key_file: /etc/istio-certs/key.pem
|
||||
insecure_skip_verify: true # prometheus does not support secure naming.
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
# sidecar status annotation is added by sidecar injector and
|
||||
# istio_workload_mtls_ability can be specifically placed on a pod to indicate its ability to receive mtls traffic.
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_sidecar_istio_io_status, __meta_kubernetes_pod_annotation_istio_mtls]
|
||||
action: keep
|
||||
regex: (([^;]+);([^;]*))|(([^;]*);(true))
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__] # Only keep address that is host:port
|
||||
action: keep # otherwise an extra target with ':443' is added for https scheme
|
||||
regex: ([^:]+):(\d+)
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
---
|
||||
|
||||
# Source: istio/charts/prometheus/templates/service.yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
annotations:
|
||||
prometheus.io/scrape: 'true'
|
||||
labels:
|
||||
name: prometheus
|
||||
spec:
|
||||
selector:
|
||||
app: prometheus
|
||||
ports:
|
||||
- name: http-prometheus
|
||||
protocol: TCP
|
||||
port: 9090
|
||||
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: prometheus
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: prometheus
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "false"
|
||||
scheduler.alpha.kubernetes.io/critical-pod: ""
|
||||
spec:
|
||||
serviceAccountName: prometheus
|
||||
containers:
|
||||
- name: prometheus
|
||||
image: "docker.io/prom/prometheus:v2.7.1"
|
||||
imagePullPolicy: IfNotPresent
|
||||
args:
|
||||
- '--storage.tsdb.retention=6h'
|
||||
- '--config.file=/etc/prometheus/prometheus.yml'
|
||||
ports:
|
||||
- containerPort: 9090
|
||||
name: http
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /-/healthy
|
||||
port: 9090
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
path: /-/ready
|
||||
port: 9090
|
||||
resources:
|
||||
requests:
|
||||
cpu: 10m
|
||||
|
||||
volumeMounts:
|
||||
- name: config-volume
|
||||
mountPath: /etc/prometheus
|
||||
- mountPath: /etc/istio-certs
|
||||
name: istio-certs
|
||||
volumes:
|
||||
- name: config-volume
|
||||
configMap:
|
||||
name: prometheus
|
||||
- name: istio-certs
|
||||
secret:
|
||||
defaultMode: 420
|
||||
optional: true
|
||||
secretName: istio.default
|
||||
19
artifacts/loadtester/config.yaml
Normal file
@@ -0,0 +1,19 @@
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: flagger-loadtester-bats
|
||||
data:
|
||||
tests: |
|
||||
#!/usr/bin/env bats
|
||||
|
||||
@test "check message" {
|
||||
curl -sS http://${URL} | jq -r .message | {
|
||||
run cut -d $' ' -f1
|
||||
[ $output = "greetings" ]
|
||||
}
|
||||
}
|
||||
|
||||
@test "check headers" {
|
||||
curl -sS http://${URL}/headers | grep X-Request-Id
|
||||
}
|
||||
@@ -17,7 +17,7 @@ spec:
|
||||
spec:
|
||||
containers:
|
||||
- name: loadtester
|
||||
image: quay.io/stefanprodan/flagger-loadtester:0.1.0
|
||||
image: weaveworks/flagger-loadtester:0.3.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- name: http
|
||||
@@ -27,7 +27,6 @@ spec:
|
||||
- -port=8080
|
||||
- -log-level=info
|
||||
- -timeout=1h
|
||||
- -log-cmd-output=true
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
@@ -58,3 +57,11 @@ spec:
|
||||
securityContext:
|
||||
readOnlyRootFilesystem: true
|
||||
runAsUser: 10001
|
||||
# volumeMounts:
|
||||
# - name: tests
|
||||
# mountPath: /bats
|
||||
# readOnly: true
|
||||
# volumes:
|
||||
# - name: tests
|
||||
# configMap:
|
||||
# name: flagger-loadtester-bats
|
||||
@@ -4,3 +4,4 @@ metadata:
|
||||
name: test
|
||||
labels:
|
||||
istio-injection: enabled
|
||||
appmesh.k8s.aws/sidecarInjectorWebhook: enabled
|
||||
|
||||
45
artifacts/routing/destination-rule.yaml
Normal file
@@ -0,0 +1,45 @@
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- podinfo.istio.weavedx.com
|
||||
- podinfo
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: podinfo
|
||||
subset: primary
|
||||
weight: 50
|
||||
- destination:
|
||||
host: podinfo
|
||||
subset: canary
|
||||
weight: 50
|
||||
---
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: DestinationRule
|
||||
metadata:
|
||||
name: podinfo-destination
|
||||
namespace: test
|
||||
spec:
|
||||
host: podinfo
|
||||
trafficPolicy:
|
||||
loadBalancer:
|
||||
consistentHash:
|
||||
httpCookie:
|
||||
name: istiouser
|
||||
ttl: 30s
|
||||
subsets:
|
||||
- name: primary
|
||||
labels:
|
||||
app: podinfo
|
||||
role: primary
|
||||
- name: canary
|
||||
labels:
|
||||
app: podinfo
|
||||
role: canary
|
||||
@@ -8,13 +8,17 @@ spec:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- podinfo.iowa.weavedx.com
|
||||
- app.istio.weavedx.com
|
||||
- podinfo
|
||||
http:
|
||||
- match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: ^(?!.*Chrome)(?=.*\bSafari\b).*$
|
||||
uri:
|
||||
prefix: "/version/"
|
||||
rewrite:
|
||||
uri: /api/info
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
@@ -26,7 +30,12 @@ spec:
|
||||
port:
|
||||
number: 9898
|
||||
weight: 100
|
||||
- route:
|
||||
- match:
|
||||
- uri:
|
||||
prefix: "/version/"
|
||||
rewrite:
|
||||
uri: /api/info
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
port:
|
||||
|
||||
@@ -23,7 +23,7 @@ spec:
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.2.0
|
||||
image: quay.io/stefanprodan/podinfo:1.4.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
@@ -67,9 +67,3 @@ spec:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 16Mi
|
||||
volumeMounts:
|
||||
- mountPath: /data
|
||||
name: data
|
||||
volumes:
|
||||
- emptyDir: {}
|
||||
name: data
|
||||
|
||||
@@ -1,10 +1,8 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: podinfo
|
||||
name: podinfo-canary
|
||||
namespace: test
|
||||
labels:
|
||||
app: podinfo
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
|
||||
@@ -23,7 +23,7 @@ spec:
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.1.1
|
||||
image: quay.io/stefanprodan/podinfo:1.4.1
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
|
||||
14
artifacts/workloads/service.yaml
Normal file
@@ -0,0 +1,14 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
app: podinfo-primary
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: http
|
||||
@@ -1,14 +1,14 @@
|
||||
apiVersion: v1
|
||||
name: flagger
|
||||
version: 0.5.0
|
||||
appVersion: 0.5.0
|
||||
version: 0.12.0
|
||||
appVersion: 0.12.0
|
||||
kubeVersion: ">=1.11.0-0"
|
||||
engine: gotpl
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of canary deployments using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
home: https://docs.flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
icon: https://raw.githubusercontent.com/weaveworks/flagger/master/docs/logo/flagger-icon.png
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
- https://github.com/weaveworks/flagger
|
||||
maintainers:
|
||||
- name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
@@ -16,4 +16,5 @@ maintainers:
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- appmesh
|
||||
- gitops
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Flagger
|
||||
|
||||
[Flagger](https://github.com/stefanprodan/flagger) is a Kubernetes operator that automates the promotion of
|
||||
[Flagger](https://github.com/weaveworks/flagger) is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators
|
||||
like HTTP requests success rate, requests average duration and pods health.
|
||||
|
||||
@@ -3,6 +3,8 @@ apiVersion: apiextensions.k8s.io/v1beta1
|
||||
kind: CustomResourceDefinition
|
||||
metadata:
|
||||
name: canaries.flagger.app
|
||||
annotations:
|
||||
helm.sh/resource-policy: keep
|
||||
spec:
|
||||
group: flagger.app
|
||||
version: v1alpha3
|
||||
@@ -74,11 +76,21 @@ spec:
|
||||
properties:
|
||||
port:
|
||||
type: number
|
||||
portName:
|
||||
type: string
|
||||
meshName:
|
||||
type: string
|
||||
timeout:
|
||||
type: string
|
||||
skipAnalysis:
|
||||
type: boolean
|
||||
canaryAnalysis:
|
||||
properties:
|
||||
interval:
|
||||
type: string
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
iterations:
|
||||
type: number
|
||||
threshold:
|
||||
type: number
|
||||
maxWeight:
|
||||
@@ -90,7 +102,7 @@ spec:
|
||||
properties:
|
||||
items:
|
||||
type: object
|
||||
required: ['name', 'interval', 'threshold']
|
||||
required: ['name', 'threshold']
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
@@ -99,6 +111,8 @@ spec:
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
threshold:
|
||||
type: number
|
||||
query:
|
||||
type: string
|
||||
webhooks:
|
||||
type: array
|
||||
properties:
|
||||
@@ -108,10 +122,37 @@ spec:
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
type:
|
||||
type: string
|
||||
enum:
|
||||
- ""
|
||||
- pre-rollout
|
||||
- rollout
|
||||
- post-rollout
|
||||
url:
|
||||
type: string
|
||||
format: url
|
||||
timeout:
|
||||
type: string
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
status:
|
||||
properties:
|
||||
phase:
|
||||
type: string
|
||||
enum:
|
||||
- ""
|
||||
- Initialized
|
||||
- Progressing
|
||||
- Succeeded
|
||||
- Failed
|
||||
canaryWeight:
|
||||
type: number
|
||||
failedChecks:
|
||||
type: number
|
||||
iterations:
|
||||
type: number
|
||||
lastAppliedSpec:
|
||||
type: string
|
||||
lastTransitionTime:
|
||||
type: string
|
||||
{{- end }}
|
||||
|
||||
@@ -35,7 +35,13 @@ spec:
|
||||
command:
|
||||
- ./flagger
|
||||
- -log-level=info
|
||||
{{- if .Values.meshProvider }}
|
||||
- -mesh-provider={{ .Values.meshProvider }}
|
||||
{{- end }}
|
||||
- -metrics-server={{ .Values.metricsServer }}
|
||||
{{- if .Values.namespace }}
|
||||
- -namespace={{ .Values.namespace }}
|
||||
{{- end }}
|
||||
{{- if .Values.slack.url }}
|
||||
- -slack-url={{ .Values.slack.url }}
|
||||
- -slack-user={{ .Values.slack.user }}
|
||||
|
||||
@@ -9,11 +9,50 @@ metadata:
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
rules:
|
||||
- apiGroups: ['*']
|
||||
resources: ['*']
|
||||
verbs: ['*']
|
||||
- nonResourceURLs: ['*']
|
||||
verbs: ['*']
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- events
|
||||
- configmaps
|
||||
- secrets
|
||||
- services
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- apps
|
||||
resources:
|
||||
- deployments
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- autoscaling
|
||||
resources:
|
||||
- horizontalpodautoscalers
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries
|
||||
- canaries/status
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- networking.istio.io
|
||||
resources:
|
||||
- virtualservices
|
||||
- virtualservices/status
|
||||
verbs: ["*"]
|
||||
- apiGroups:
|
||||
- appmesh.k8s.aws
|
||||
resources:
|
||||
- meshes
|
||||
- meshes/status
|
||||
- virtualnodes
|
||||
- virtualnodes/status
|
||||
- virtualservices
|
||||
- virtualservices/status
|
||||
verbs: ["*"]
|
||||
- nonResourceURLs:
|
||||
- /version
|
||||
verbs:
|
||||
- get
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
|
||||
@@ -1,11 +1,17 @@
|
||||
# Default values for flagger.
|
||||
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger
|
||||
tag: 0.5.0
|
||||
repository: weaveworks/flagger
|
||||
tag: 0.12.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
metricsServer: "http://prometheus.istio-system.svc.cluster.local:9090"
|
||||
metricsServer: "http://prometheus:9090"
|
||||
|
||||
# accepted values are istio or appmesh (defaults to istio)
|
||||
meshProvider: ""
|
||||
|
||||
# single namespace restriction
|
||||
namespace: ""
|
||||
|
||||
slack:
|
||||
user: flagger
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
apiVersion: v1
|
||||
name: grafana
|
||||
version: 0.1.0
|
||||
appVersion: 5.4.2
|
||||
version: 1.1.0
|
||||
appVersion: 5.4.3
|
||||
description: Grafana dashboards for monitoring Flagger canary deployments
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
icon: https://raw.githubusercontent.com/weaveworks/flagger/master/docs/logo/flagger-icon.png
|
||||
home: https://flagger.app
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
- https://github.com/weaveworks/flagger
|
||||
maintainers:
|
||||
- name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
Grafana dashboards for monitoring progressive deployments powered by Istio, Prometheus and Flagger.
|
||||
|
||||

|
||||
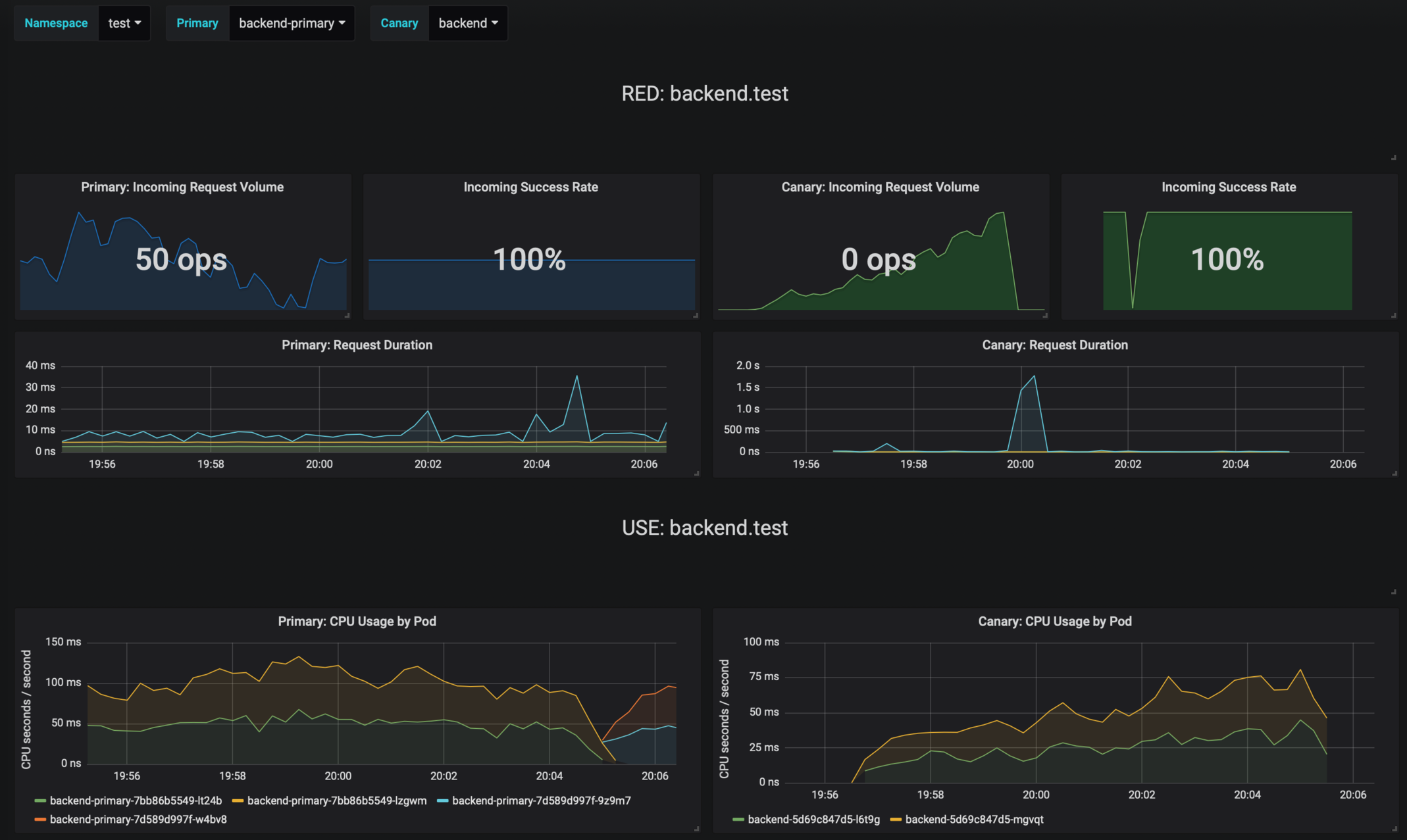
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
||||
1248
charts/grafana/dashboards/appmesh.json
Normal file
@@ -2,7 +2,6 @@
|
||||
"annotations": {
|
||||
"list": [
|
||||
{
|
||||
"$$hashKey": "object:1587",
|
||||
"builtIn": 1,
|
||||
"datasource": "-- Grafana --",
|
||||
"enable": true,
|
||||
@@ -16,8 +15,8 @@
|
||||
"editable": true,
|
||||
"gnetId": null,
|
||||
"graphTooltip": 0,
|
||||
"id": null,
|
||||
"iteration": 1534587617141,
|
||||
"id": 1,
|
||||
"iteration": 1549736611069,
|
||||
"links": [],
|
||||
"panels": [
|
||||
{
|
||||
@@ -179,7 +178,6 @@
|
||||
"tableColumn": "",
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2857",
|
||||
"expr": "sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$primary\",response_code!~\"5.*\"}[30s])) / sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$primary\"}[30s]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -344,7 +342,6 @@
|
||||
"tableColumn": "",
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2810",
|
||||
"expr": "sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$canary\",response_code!~\"5.*\"}[30s])) / sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$canary\"}[30s]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -363,7 +360,7 @@
|
||||
"value": "null"
|
||||
}
|
||||
],
|
||||
"valueName": "avg"
|
||||
"valueName": "current"
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -432,6 +429,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Request Duration",
|
||||
"tooltip": {
|
||||
@@ -464,7 +462,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -533,6 +535,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Request Duration",
|
||||
"tooltip": {
|
||||
@@ -565,7 +568,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"content": "<div class=\"dashboard-header text-center\">\n<span>USE: $canary.$namespace</span>\n</div>",
|
||||
@@ -623,7 +630,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(rate(container_cpu_usage_seconds_total{cpu=\"total\",namespace=\"$namespace\",pod_name=~\"$primary.*\", container_name!~\"POD|istio-proxy\"}[1m])) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -634,6 +640,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: CPU Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -651,7 +658,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"format": "s",
|
||||
"label": "CPU seconds / second",
|
||||
"logBase": 1,
|
||||
@@ -660,7 +666,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -668,7 +673,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -711,7 +720,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(rate(container_cpu_usage_seconds_total{cpu=\"total\",namespace=\"$namespace\",pod_name=~\"$canary.*\", pod_name!~\"$primary.*\", container_name!~\"POD|istio-proxy\"}[1m])) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -722,6 +730,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: CPU Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -739,7 +748,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"format": "s",
|
||||
"label": "CPU seconds / second",
|
||||
"logBase": 1,
|
||||
@@ -748,7 +756,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -756,7 +763,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -799,7 +810,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(container_memory_working_set_bytes{namespace=\"$namespace\",pod_name=~\"$primary.*\", container_name!~\"POD|istio-proxy\"}) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -811,6 +821,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Memory Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -828,7 +839,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "bytes",
|
||||
"label": "",
|
||||
@@ -838,7 +848,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -846,7 +855,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -889,7 +902,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(container_memory_working_set_bytes{namespace=\"$namespace\",pod_name=~\"$canary.*\", pod_name!~\"$primary.*\", container_name!~\"POD|istio-proxy\"}) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -901,6 +913,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Memory Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -918,7 +931,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "bytes",
|
||||
"label": "",
|
||||
@@ -928,7 +940,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -936,7 +947,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -975,12 +990,10 @@
|
||||
"renderer": "flot",
|
||||
"seriesOverrides": [
|
||||
{
|
||||
"$$hashKey": "object:3641",
|
||||
"alias": "received",
|
||||
"color": "#f9d9f9"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3649",
|
||||
"alias": "transmited",
|
||||
"color": "#f29191"
|
||||
}
|
||||
@@ -990,7 +1003,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2598",
|
||||
"expr": "sum(rate (container_network_receive_bytes_total{namespace=\"$namespace\",pod_name=~\"$primary.*\"}[1m])) ",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -998,7 +1010,6 @@
|
||||
"refId": "A"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3245",
|
||||
"expr": "-sum (rate (container_network_transmit_bytes_total{namespace=\"$namespace\",pod_name=~\"$primary.*\"}[1m]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1008,6 +1019,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Network I/O",
|
||||
"tooltip": {
|
||||
@@ -1025,7 +1037,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "Bps",
|
||||
"label": "",
|
||||
@@ -1035,7 +1046,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1043,7 +1053,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1082,12 +1096,10 @@
|
||||
"renderer": "flot",
|
||||
"seriesOverrides": [
|
||||
{
|
||||
"$$hashKey": "object:3641",
|
||||
"alias": "received",
|
||||
"color": "#f9d9f9"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3649",
|
||||
"alias": "transmited",
|
||||
"color": "#f29191"
|
||||
}
|
||||
@@ -1097,7 +1109,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2598",
|
||||
"expr": "sum(rate (container_network_receive_bytes_total{namespace=\"$namespace\",pod_name=~\"$canary.*\",pod_name!~\"$primary.*\"}[1m])) ",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1105,7 +1116,6 @@
|
||||
"refId": "A"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3245",
|
||||
"expr": "-sum (rate (container_network_transmit_bytes_total{namespace=\"$namespace\",pod_name=~\"$canary.*\",pod_name!~\"$primary.*\"}[1m]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1115,6 +1125,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Network I/O",
|
||||
"tooltip": {
|
||||
@@ -1132,7 +1143,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "Bps",
|
||||
"label": "",
|
||||
@@ -1142,7 +1152,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1150,7 +1159,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"content": "<div class=\"dashboard-header text-center\">\n<span>IN/OUTBOUND: $canary.$namespace</span>\n</div>",
|
||||
@@ -1205,7 +1218,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1953",
|
||||
"expr": "round(sum(irate(istio_requests_total{connection_security_policy=\"mutual_tls\", destination_workload_namespace=~\"$namespace\", destination_workload=~\"$primary\", reporter=\"destination\"}[30s])) by (source_workload, source_workload_namespace, response_code), 0.001)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -1215,7 +1227,6 @@
|
||||
"step": 2
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1954",
|
||||
"expr": "round(sum(irate(istio_requests_total{connection_security_policy!=\"mutual_tls\", destination_workload_namespace=~\"$namespace\", destination_workload=~\"$primary\", reporter=\"destination\"}[30s])) by (source_workload, source_workload_namespace, response_code), 0.001)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -1227,6 +1238,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Incoming Requests by Source And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1246,7 +1258,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1999",
|
||||
"format": "ops",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1255,7 +1266,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:2000",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1263,7 +1273,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1323,6 +1337,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Incoming Requests by Source And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1357,7 +1372,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1416,6 +1435,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Outgoing Requests by Destination And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1450,7 +1470,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1509,6 +1533,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Outgoing Requests by Destination And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1543,7 +1568,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
}
|
||||
],
|
||||
"refresh": "10s",
|
||||
@@ -1554,11 +1583,9 @@
|
||||
"list": [
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "demo",
|
||||
"value": "demo"
|
||||
},
|
||||
"current": null,
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Namespace",
|
||||
@@ -1568,6 +1595,7 @@
|
||||
"query": "query_result(sum(istio_requests_total) by (destination_workload_namespace) or sum(istio_tcp_sent_bytes_total) by (destination_workload_namespace))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*_namespace=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 0,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1577,11 +1605,9 @@
|
||||
},
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "primary",
|
||||
"value": "primary"
|
||||
},
|
||||
"current": null,
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Primary",
|
||||
@@ -1591,6 +1617,7 @@
|
||||
"query": "query_result(sum(istio_requests_total{destination_workload_namespace=~\"$namespace\"}) by (destination_service_name))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*destination_service_name=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 1,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1600,11 +1627,9 @@
|
||||
},
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "canary",
|
||||
"value": "canary"
|
||||
},
|
||||
"current": null,
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Canary",
|
||||
@@ -1614,6 +1639,7 @@
|
||||
"query": "query_result(sum(istio_requests_total{destination_workload_namespace=~\"$namespace\"}) by (destination_service_name))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*destination_service_name=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 1,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1653,7 +1679,7 @@
|
||||
]
|
||||
},
|
||||
"timezone": "",
|
||||
"title": "Canary analysis",
|
||||
"uid": "RdykD7tiz",
|
||||
"version": 2
|
||||
}
|
||||
"title": "Istio Canary",
|
||||
"uid": "flagger-istio",
|
||||
"version": 3
|
||||
}
|
||||
@@ -1,15 +1,7 @@
|
||||
1. Get the application URL by running these commands:
|
||||
{{- if contains "NodePort" .Values.service.type }}
|
||||
export NODE_PORT=$(kubectl get --namespace {{ .Release.Namespace }} -o jsonpath="{.spec.ports[0].nodePort}" services {{ template "grafana.fullname" . }})
|
||||
export NODE_IP=$(kubectl get nodes --namespace {{ .Release.Namespace }} -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
echo http://$NODE_IP:$NODE_PORT
|
||||
{{- else if contains "LoadBalancer" .Values.service.type }}
|
||||
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
|
||||
You can watch the status of by running 'kubectl get svc -w {{ template "grafana.fullname" . }}'
|
||||
export SERVICE_IP=$(kubectl get svc --namespace {{ .Release.Namespace }} {{ template "grafana.fullname" . }} -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
|
||||
echo http://$SERVICE_IP:{{ .Values.service.port }}
|
||||
{{- else if contains "ClusterIP" .Values.service.type }}
|
||||
export POD_NAME=$(kubectl get pods --namespace {{ .Release.Namespace }} -l "app={{ template "grafana.name" . }},release={{ .Release.Name }}" -o jsonpath="{.items[0].metadata.name}")
|
||||
echo "Visit http://127.0.0.1:8080 to use your application"
|
||||
kubectl port-forward $POD_NAME 8080:80
|
||||
{{- end }}
|
||||
1. Run the port forward command:
|
||||
|
||||
kubectl -n {{ .Release.Namespace }} port-forward svc/{{ .Release.Name }} 3000:80
|
||||
|
||||
2. Navigate to:
|
||||
|
||||
http://localhost:3000
|
||||
@@ -38,12 +38,21 @@ spec:
|
||||
# path: /
|
||||
# port: http
|
||||
env:
|
||||
- name: GF_PATHS_PROVISIONING
|
||||
value: /etc/grafana/provisioning/
|
||||
{{- if .Values.password }}
|
||||
- name: GF_SECURITY_ADMIN_USER
|
||||
value: {{ .Values.user }}
|
||||
- name: GF_SECURITY_ADMIN_PASSWORD
|
||||
value: {{ .Values.password }}
|
||||
- name: GF_PATHS_PROVISIONING
|
||||
value: /etc/grafana/provisioning/
|
||||
{{- else }}
|
||||
- name: GF_AUTH_BASIC_ENABLED
|
||||
value: "false"
|
||||
- name: GF_AUTH_ANONYMOUS_ENABLED
|
||||
value: "true"
|
||||
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
|
||||
value: Admin
|
||||
{{- end }}
|
||||
volumeMounts:
|
||||
- name: grafana
|
||||
mountPath: /var/lib/grafana
|
||||
|
||||
@@ -6,7 +6,7 @@ replicaCount: 1
|
||||
|
||||
image:
|
||||
repository: grafana/grafana
|
||||
tag: 5.4.2
|
||||
tag: 5.4.3
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
service:
|
||||
@@ -28,7 +28,7 @@ tolerations: []
|
||||
affinity: {}
|
||||
|
||||
user: admin
|
||||
password: admin
|
||||
password:
|
||||
|
||||
# Istio Prometheus instance
|
||||
url: http://prometheus:9090
|
||||
|
||||
@@ -1,14 +1,14 @@
|
||||
apiVersion: v1
|
||||
name: loadtester
|
||||
version: 0.1.0
|
||||
appVersion: 0.1.0
|
||||
version: 0.4.0
|
||||
appVersion: 0.3.0
|
||||
kubeVersion: ">=1.11.0-0"
|
||||
engine: gotpl
|
||||
description: Flagger's load testing services based on rakyll/hey that generates traffic during canary analysis when configured as a webhook.
|
||||
home: https://docs.flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
icon: https://raw.githubusercontent.com/weaveworks/flagger/master/docs/logo/flagger-icon.png
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
- https://github.com/weaveworks/flagger
|
||||
maintainers:
|
||||
- name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
@@ -16,5 +16,6 @@ maintainers:
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- appmesh
|
||||
- gitops
|
||||
- load testing
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Flagger load testing service
|
||||
|
||||
[Flagger's](https://github.com/stefanprodan/flagger) load testing service is based on
|
||||
[Flagger's](https://github.com/weaveworks/flagger) load testing service is based on
|
||||
[rakyll/hey](https://github.com/rakyll/hey)
|
||||
and can be used to generates traffic during canary analysis when configured as a webhook.
|
||||
|
||||
@@ -56,15 +56,15 @@ Parameter | Description | Default
|
||||
`nodeSelector` | node labels for pod assignment | `{}`
|
||||
`service.type` | type of service | `ClusterIP`
|
||||
`service.port` | ClusterIP port | `80`
|
||||
`cmd.logOutput` | Log the command output to stderr | `true`
|
||||
`cmd.timeout` | Command execution timeout | `1h`
|
||||
`logLevel` | Log level can be debug, info, warning, error or panic | `info`
|
||||
`meshName` | AWS App Mesh name | `none`
|
||||
`backends` | AWS App Mesh virtual services | `none`
|
||||
|
||||
Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example,
|
||||
|
||||
```console
|
||||
helm install flagger/loadtester --name flagger-loadtester \
|
||||
--set cmd.logOutput=false
|
||||
helm install flagger/loadtester --name flagger-loadtester
|
||||
```
|
||||
|
||||
Alternatively, a YAML file that specifies the values for the above parameters can be provided while installing the chart. For example,
|
||||
|
||||
@@ -16,6 +16,8 @@ spec:
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ include "loadtester.name" . }}
|
||||
annotations:
|
||||
appmesh.k8s.aws/ports: "444"
|
||||
spec:
|
||||
containers:
|
||||
- name: {{ .Chart.Name }}
|
||||
@@ -29,7 +31,6 @@ spec:
|
||||
- -port=8080
|
||||
- -log-level={{ .Values.logLevel }}
|
||||
- -timeout={{ .Values.cmd.timeout }}
|
||||
- -log-cmd-output={{ .Values.cmd.logOutput }}
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
|
||||
27
charts/loadtester/templates/virtual-node.yaml
Normal file
@@ -0,0 +1,27 @@
|
||||
{{- if .Values.meshName }}
|
||||
apiVersion: appmesh.k8s.aws/v1beta1
|
||||
kind: VirtualNode
|
||||
metadata:
|
||||
name: {{ include "loadtester.fullname" . }}
|
||||
labels:
|
||||
app.kubernetes.io/name: {{ include "loadtester.name" . }}
|
||||
helm.sh/chart: {{ include "loadtester.chart" . }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
spec:
|
||||
meshName: {{ .Values.meshName }}
|
||||
listeners:
|
||||
- portMapping:
|
||||
port: 444
|
||||
protocol: http
|
||||
serviceDiscovery:
|
||||
dns:
|
||||
hostName: {{ include "loadtester.fullname" . }}.{{ .Release.Namespace }}
|
||||
{{- if .Values.backends }}
|
||||
backends:
|
||||
{{- range .Values.backends }}
|
||||
- virtualService:
|
||||
virtualServiceName: {{ . }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
@@ -1,13 +1,12 @@
|
||||
replicaCount: 1
|
||||
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger-loadtester
|
||||
tag: 0.1.0
|
||||
repository: weaveworks/flagger-loadtester
|
||||
tag: 0.3.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
logLevel: info
|
||||
cmd:
|
||||
logOutput: true
|
||||
timeout: 1h
|
||||
|
||||
nameOverride: ""
|
||||
@@ -27,3 +26,9 @@ nodeSelector: {}
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
|
||||
# App Mesh virtual node settings
|
||||
meshName: ""
|
||||
#backends:
|
||||
# - app1.namespace
|
||||
# - app2.namespace
|
||||
|
||||
21
charts/podinfo/.helmignore
Normal file
@@ -0,0 +1,21 @@
|
||||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
12
charts/podinfo/Chart.yaml
Normal file
@@ -0,0 +1,12 @@
|
||||
apiVersion: v1
|
||||
version: 2.0.1
|
||||
appVersion: 1.4.0
|
||||
name: podinfo
|
||||
engine: gotpl
|
||||
description: Flagger canary deployment demo chart
|
||||
home: https://github.com/weaveworks/flagger
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
sources:
|
||||
- https://github.com/weaveworks/flagger
|
||||
79
charts/podinfo/README.md
Normal file
@@ -0,0 +1,79 @@
|
||||
# Podinfo
|
||||
|
||||
Podinfo is a tiny web application made with Go
|
||||
that showcases best practices of running canary deployments with Flagger and Istio.
|
||||
|
||||
## Installing the Chart
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```console
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
To install the chart with the release name `frontend`:
|
||||
|
||||
```console
|
||||
helm upgrade -i frontend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=frontend \
|
||||
--set backend=http://backend.test:9898/echo \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=true \
|
||||
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
||||
--set canary.istioIngress.host=frontend.istio.example.com
|
||||
```
|
||||
|
||||
To install the chart as `backend`:
|
||||
|
||||
```console
|
||||
helm upgrade -i backend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=backend \
|
||||
--set canary.enabled=true
|
||||
```
|
||||
|
||||
## Uninstalling the Chart
|
||||
|
||||
To uninstall/delete the `frontend` deployment:
|
||||
|
||||
```console
|
||||
$ helm delete --purge frontend
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
## Configuration
|
||||
|
||||
The following tables lists the configurable parameters of the podinfo chart and their default values.
|
||||
|
||||
Parameter | Description | Default
|
||||
--- | --- | ---
|
||||
`image.repository` | image repository | `quay.io/stefanprodan/podinfo`
|
||||
`image.tag` | image tag | `<VERSION>`
|
||||
`image.pullPolicy` | image pull policy | `IfNotPresent`
|
||||
`hpa.enabled` | enables HPA | `true`
|
||||
`hpa.cpu` | target CPU usage per pod | `80`
|
||||
`hpa.memory` | target memory usage per pod | `512Mi`
|
||||
`hpa.minReplicas` | maximum pod replicas | `2`
|
||||
`hpa.maxReplicas` | maximum pod replicas | `4`
|
||||
`resources.requests/cpu` | pod CPU request | `1m`
|
||||
`resources.requests/memory` | pod memory request | `16Mi`
|
||||
`backend` | backend URL | None
|
||||
`faults.delay` | random HTTP response delays between 0 and 5 seconds | `false`
|
||||
`faults.error` | 1/3 chances of a random HTTP response error | `false`
|
||||
|
||||
Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example,
|
||||
|
||||
```console
|
||||
$ helm install flagger/podinfo --name frontend \
|
||||
--set=image.tag=1.4.1,hpa.enabled=false
|
||||
```
|
||||
|
||||
Alternatively, a YAML file that specifies the values for the above parameters can be provided while installing the chart. For example,
|
||||
|
||||
```console
|
||||
$ helm install flagger/podinfo --name frontend -f values.yaml
|
||||
```
|
||||
|
||||
|
||||
1
charts/podinfo/templates/NOTES.txt
Normal file
@@ -0,0 +1 @@
|
||||
podinfo {{ .Release.Name }} deployed!
|
||||
43
charts/podinfo/templates/_helpers.tpl
Normal file
@@ -0,0 +1,43 @@
|
||||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "podinfo.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "podinfo.fullname" -}}
|
||||
{{- if .Values.fullnameOverride -}}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- if contains $name .Release.Name -}}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "podinfo.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name suffix.
|
||||
*/}}
|
||||
{{- define "podinfo.suffix" -}}
|
||||
{{- if .Values.canary.enabled -}}
|
||||
{{- "-primary" -}}
|
||||
{{- else -}}
|
||||
{{- "" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
54
charts/podinfo/templates/canary.yaml
Normal file
@@ -0,0 +1,54 @@
|
||||
{{- if .Values.canary.enabled }}
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
progressDeadlineSeconds: 60
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
service:
|
||||
port: {{ .Values.service.port }}
|
||||
{{- if .Values.canary.istioIngress.enabled }}
|
||||
gateways:
|
||||
- {{ .Values.canary.istioIngress.gateway }}
|
||||
hosts:
|
||||
- {{ .Values.canary.istioIngress.host }}
|
||||
{{- end }}
|
||||
canaryAnalysis:
|
||||
interval: {{ .Values.canary.analysis.interval }}
|
||||
threshold: {{ .Values.canary.analysis.threshold }}
|
||||
maxWeight: {{ .Values.canary.analysis.maxWeight }}
|
||||
stepWeight: {{ .Values.canary.analysis.stepWeight }}
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
threshold: {{ .Values.canary.thresholds.successRate }}
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
threshold: {{ .Values.canary.thresholds.latency }}
|
||||
interval: 1m
|
||||
{{- if .Values.canary.loadtest.enabled }}
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: {{ .Values.canary.loadtest.url }}
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 http://{{ template "podinfo.fullname" . }}.{{ .Release.Namespace }}:{{ .Values.service.port }}"
|
||||
- name: load-test-post
|
||||
url: {{ .Values.canary.loadtest.url }}
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 -m POST -d '{\"test\": true}' http://{{ template "podinfo.fullname" . }}.{{ .Release.Namespace }}:{{ .Values.service.port }}/echo"
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
15
charts/podinfo/templates/configmap.yaml
Normal file
@@ -0,0 +1,15 @@
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
data:
|
||||
config.yaml: |-
|
||||
# http settings
|
||||
http-client-timeout: 1m
|
||||
http-server-timeout: {{ .Values.httpServer.timeout }}
|
||||
http-server-shutdown-timeout: 5s
|
||||
93
charts/podinfo/templates/deployment.yaml
Normal file
@@ -0,0 +1,93 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
annotations:
|
||||
prometheus.io/scrape: 'true'
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 30
|
||||
containers:
|
||||
- name: {{ .Chart.Name }}
|
||||
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
|
||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
||||
command:
|
||||
- ./podinfo
|
||||
- --port={{ .Values.service.port }}
|
||||
- --level={{ .Values.logLevel }}
|
||||
- --random-delay={{ .Values.faults.delay }}
|
||||
- --random-error={{ .Values.faults.error }}
|
||||
- --config-path=/podinfo/config
|
||||
env:
|
||||
{{- if .Values.message }}
|
||||
- name: PODINFO_UI_MESSAGE
|
||||
value: {{ .Values.message }}
|
||||
{{- end }}
|
||||
{{- if .Values.backend }}
|
||||
- name: PODINFO_BACKEND_URL
|
||||
value: {{ .Values.backend }}
|
||||
{{- end }}
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: {{ .Values.service.port }}
|
||||
protocol: TCP
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:{{ .Values.service.port }}/healthz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:{{ .Values.service.port }}/readyz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
volumeMounts:
|
||||
- name: data
|
||||
mountPath: /data
|
||||
- name: config
|
||||
mountPath: /podinfo/config
|
||||
readOnly: true
|
||||
resources:
|
||||
{{ toYaml .Values.resources | indent 12 }}
|
||||
{{- with .Values.nodeSelector }}
|
||||
nodeSelector:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.affinity }}
|
||||
affinity:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.tolerations }}
|
||||
tolerations:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
volumes:
|
||||
- name: data
|
||||
emptyDir: {}
|
||||
- name: config
|
||||
configMap:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
37
charts/podinfo/templates/hpa.yaml
Normal file
@@ -0,0 +1,37 @@
|
||||
{{- if .Values.hpa.enabled -}}
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1beta2
|
||||
kind: Deployment
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
minReplicas: {{ .Values.hpa.minReplicas }}
|
||||
maxReplicas: {{ .Values.hpa.maxReplicas }}
|
||||
metrics:
|
||||
{{- if .Values.hpa.cpu }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageUtilization: {{ .Values.hpa.cpu }}
|
||||
{{- end }}
|
||||
{{- if .Values.hpa.memory }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageValue: {{ .Values.hpa.memory }}
|
||||
{{- end }}
|
||||
{{- if .Values.hpa.requests }}
|
||||
- type: Pod
|
||||
pods:
|
||||
metricName: http_requests
|
||||
targetAverageValue: {{ .Values.hpa.requests }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
20
charts/podinfo/templates/service.yaml
Normal file
@@ -0,0 +1,20 @@
|
||||
{{- if not .Values.canary.enabled }}
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
type: {{ .Values.service.type }}
|
||||
ports:
|
||||
- port: {{ .Values.service.port }}
|
||||
targetPort: http
|
||||
protocol: TCP
|
||||
name: http
|
||||
selector:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
{{- end }}
|
||||
22
charts/podinfo/templates/tests/test-config.yaml
Executable file
@@ -0,0 +1,22 @@
|
||||
{{- $url := printf "%s%s.%s:%v" (include "podinfo.fullname" .) (include "podinfo.suffix" .) .Release.Namespace .Values.service.port -}}
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}-tests
|
||||
labels:
|
||||
heritage: {{ .Release.Service }}
|
||||
release: {{ .Release.Name }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
|
||||
app: {{ template "podinfo.name" . }}
|
||||
data:
|
||||
run.sh: |-
|
||||
@test "HTTP POST /echo" {
|
||||
run curl --retry 3 --connect-timeout 2 -sSX POST -d 'test' {{ $url }}/echo
|
||||
[ $output = "test" ]
|
||||
}
|
||||
@test "HTTP POST /store" {
|
||||
curl --retry 3 --connect-timeout 2 -sSX POST -d 'test' {{ $url }}/store
|
||||
}
|
||||
@test "HTTP GET /" {
|
||||
curl --retry 3 --connect-timeout 2 -sS {{ $url }} | grep hostname
|
||||
}
|
||||
43
charts/podinfo/templates/tests/test-pod.yaml
Executable file
@@ -0,0 +1,43 @@
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}-tests-{{ randAlphaNum 5 | lower }}
|
||||
annotations:
|
||||
"helm.sh/hook": test-success
|
||||
sidecar.istio.io/inject: "false"
|
||||
labels:
|
||||
heritage: {{ .Release.Service }}
|
||||
release: {{ .Release.Name }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
|
||||
app: {{ template "podinfo.name" . }}
|
||||
spec:
|
||||
initContainers:
|
||||
- name: "test-framework"
|
||||
image: "dduportal/bats:0.4.0"
|
||||
command:
|
||||
- "bash"
|
||||
- "-c"
|
||||
- |
|
||||
set -ex
|
||||
# copy bats to tools dir
|
||||
cp -R /usr/local/libexec/ /tools/bats/
|
||||
volumeMounts:
|
||||
- mountPath: /tools
|
||||
name: tools
|
||||
containers:
|
||||
- name: {{ .Release.Name }}-ui-test
|
||||
image: dduportal/bats:0.4.0
|
||||
command: ["/tools/bats/bats", "-t", "/tests/run.sh"]
|
||||
volumeMounts:
|
||||
- mountPath: /tests
|
||||
name: tests
|
||||
readOnly: true
|
||||
- mountPath: /tools
|
||||
name: tools
|
||||
volumes:
|
||||
- name: tests
|
||||
configMap:
|
||||
name: {{ template "podinfo.fullname" . }}-tests
|
||||
- name: tools
|
||||
emptyDir: {}
|
||||
restartPolicy: Never
|
||||
73
charts/podinfo/values.yaml
Normal file
@@ -0,0 +1,73 @@
|
||||
# Default values for podinfo.
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 9898
|
||||
|
||||
hpa:
|
||||
enabled: true
|
||||
minReplicas: 2
|
||||
maxReplicas: 2
|
||||
cpu: 80
|
||||
memory: 512Mi
|
||||
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: false
|
||||
# Istio ingress gateway name
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
# external host name eg. podinfo.example.com
|
||||
host:
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 15s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
thresholds:
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
successRate: 99
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
latency: 500
|
||||
loadtest:
|
||||
enabled: false
|
||||
# load tester address
|
||||
url: http://flagger-loadtester.test/
|
||||
|
||||
resources:
|
||||
limits:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 32Mi
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
|
||||
nameOverride: ""
|
||||
fullnameOverride: ""
|
||||
|
||||
logLevel: info
|
||||
backend: #http://backend-podinfo:9898/echo
|
||||
message: #UI greetings
|
||||
|
||||
faults:
|
||||
delay: false
|
||||
error: false
|
||||
|
||||
httpServer:
|
||||
timeout: 30s
|
||||
@@ -3,18 +3,21 @@ package main
|
||||
import (
|
||||
"flag"
|
||||
"log"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
_ "github.com/istio/glog"
|
||||
istioclientset "github.com/knative/pkg/client/clientset/versioned"
|
||||
"github.com/knative/pkg/signals"
|
||||
clientset "github.com/stefanprodan/flagger/pkg/client/clientset/versioned"
|
||||
informers "github.com/stefanprodan/flagger/pkg/client/informers/externalversions"
|
||||
"github.com/stefanprodan/flagger/pkg/controller"
|
||||
"github.com/stefanprodan/flagger/pkg/logging"
|
||||
"github.com/stefanprodan/flagger/pkg/notifier"
|
||||
"github.com/stefanprodan/flagger/pkg/server"
|
||||
"github.com/stefanprodan/flagger/pkg/version"
|
||||
_ "github.com/stefanprodan/klog"
|
||||
clientset "github.com/weaveworks/flagger/pkg/client/clientset/versioned"
|
||||
informers "github.com/weaveworks/flagger/pkg/client/informers/externalversions"
|
||||
"github.com/weaveworks/flagger/pkg/controller"
|
||||
"github.com/weaveworks/flagger/pkg/logger"
|
||||
"github.com/weaveworks/flagger/pkg/metrics"
|
||||
"github.com/weaveworks/flagger/pkg/notifier"
|
||||
"github.com/weaveworks/flagger/pkg/router"
|
||||
"github.com/weaveworks/flagger/pkg/server"
|
||||
"github.com/weaveworks/flagger/pkg/signals"
|
||||
"github.com/weaveworks/flagger/pkg/version"
|
||||
"go.uber.org/zap"
|
||||
"k8s.io/client-go/kubernetes"
|
||||
_ "k8s.io/client-go/plugin/pkg/client/auth/gcp"
|
||||
"k8s.io/client-go/tools/cache"
|
||||
@@ -31,6 +34,12 @@ var (
|
||||
slackURL string
|
||||
slackUser string
|
||||
slackChannel string
|
||||
threadiness int
|
||||
zapReplaceGlobals bool
|
||||
zapEncoding string
|
||||
namespace string
|
||||
meshProvider string
|
||||
selectorLabels string
|
||||
)
|
||||
|
||||
func init() {
|
||||
@@ -43,15 +52,25 @@ func init() {
|
||||
flag.StringVar(&slackURL, "slack-url", "", "Slack hook URL.")
|
||||
flag.StringVar(&slackUser, "slack-user", "flagger", "Slack user name.")
|
||||
flag.StringVar(&slackChannel, "slack-channel", "", "Slack channel.")
|
||||
flag.IntVar(&threadiness, "threadiness", 2, "Worker concurrency.")
|
||||
flag.BoolVar(&zapReplaceGlobals, "zap-replace-globals", false, "Whether to change the logging level of the global zap logger.")
|
||||
flag.StringVar(&zapEncoding, "zap-encoding", "json", "Zap logger encoding.")
|
||||
flag.StringVar(&namespace, "namespace", "", "Namespace that flagger would watch canary object")
|
||||
flag.StringVar(&meshProvider, "mesh-provider", "istio", "Service mesh provider, can be istio or appmesh")
|
||||
flag.StringVar(&selectorLabels, "selector-labels", "app,name,app.kubernetes.io/name", "List of pod labels that Flagger uses to create pod selectors")
|
||||
}
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
logger, err := logging.NewLogger(logLevel)
|
||||
logger, err := logger.NewLoggerWithEncoding(logLevel, zapEncoding)
|
||||
if err != nil {
|
||||
log.Fatalf("Error creating logger: %v", err)
|
||||
}
|
||||
if zapReplaceGlobals {
|
||||
zap.ReplaceGlobals(logger.Desugar())
|
||||
}
|
||||
|
||||
defer logger.Sync()
|
||||
|
||||
stopCh := signals.SetupSignalHandler()
|
||||
@@ -66,7 +85,7 @@ func main() {
|
||||
logger.Fatalf("Error building kubernetes clientset: %v", err)
|
||||
}
|
||||
|
||||
istioClient, err := istioclientset.NewForConfig(cfg)
|
||||
meshClient, err := clientset.NewForConfig(cfg)
|
||||
if err != nil {
|
||||
logger.Fatalf("Error building istio clientset: %v", err)
|
||||
}
|
||||
@@ -76,7 +95,8 @@ func main() {
|
||||
logger.Fatalf("Error building example clientset: %s", err.Error())
|
||||
}
|
||||
|
||||
flaggerInformerFactory := informers.NewSharedInformerFactory(flaggerClient, time.Second*30)
|
||||
flaggerInformerFactory := informers.NewSharedInformerFactoryWithOptions(flaggerClient, time.Second*30, informers.WithNamespace(namespace))
|
||||
|
||||
canaryInformer := flaggerInformerFactory.Flagger().V1alpha3().Canaries()
|
||||
|
||||
logger.Infof("Starting flagger version %s revision %s", version.VERSION, version.REVISION)
|
||||
@@ -86,9 +106,17 @@ func main() {
|
||||
logger.Fatalf("Error calling Kubernetes API: %v", err)
|
||||
}
|
||||
|
||||
logger.Infof("Connected to Kubernetes API %s", ver)
|
||||
labels := strings.Split(selectorLabels, ",")
|
||||
if len(labels) < 1 {
|
||||
logger.Fatalf("At least one selector label is required")
|
||||
}
|
||||
|
||||
ok, err := controller.CheckMetricsServer(metricsServer)
|
||||
logger.Infof("Connected to Kubernetes API %s", ver)
|
||||
if namespace != "" {
|
||||
logger.Infof("Watching namespace %s", namespace)
|
||||
}
|
||||
|
||||
ok, err := metrics.CheckMetricsServer(metricsServer)
|
||||
if ok {
|
||||
logger.Infof("Connected to metrics server %s", metricsServer)
|
||||
} else {
|
||||
@@ -108,15 +136,21 @@ func main() {
|
||||
// start HTTP server
|
||||
go server.ListenAndServe(port, 3*time.Second, logger, stopCh)
|
||||
|
||||
routerFactory := router.NewFactory(cfg, kubeClient, flaggerClient, logger, meshClient)
|
||||
|
||||
c := controller.NewController(
|
||||
kubeClient,
|
||||
istioClient,
|
||||
meshClient,
|
||||
flaggerClient,
|
||||
canaryInformer,
|
||||
controlLoopInterval,
|
||||
metricsServer,
|
||||
logger,
|
||||
slack,
|
||||
routerFactory,
|
||||
meshProvider,
|
||||
version.VERSION,
|
||||
labels,
|
||||
)
|
||||
|
||||
flaggerInformerFactory.Start(stopCh)
|
||||
@@ -132,7 +166,7 @@ func main() {
|
||||
|
||||
// start controller
|
||||
go func(ctrl *controller.Controller) {
|
||||
if err := ctrl.Run(2, stopCh); err != nil {
|
||||
if err := ctrl.Run(threadiness, stopCh); err != nil {
|
||||
logger.Fatalf("Error running controller: %v", err)
|
||||
}
|
||||
}(c)
|
||||
|
||||
@@ -2,40 +2,47 @@ package main
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"github.com/knative/pkg/signals"
|
||||
"github.com/stefanprodan/flagger/pkg/loadtester"
|
||||
"github.com/stefanprodan/flagger/pkg/logging"
|
||||
"github.com/weaveworks/flagger/pkg/loadtester"
|
||||
"github.com/weaveworks/flagger/pkg/logger"
|
||||
"github.com/weaveworks/flagger/pkg/signals"
|
||||
"go.uber.org/zap"
|
||||
"log"
|
||||
"time"
|
||||
)
|
||||
|
||||
var VERSION = "0.1.0"
|
||||
var VERSION = "0.3.0"
|
||||
var (
|
||||
logLevel string
|
||||
port string
|
||||
timeout time.Duration
|
||||
logCmdOutput bool
|
||||
logLevel string
|
||||
port string
|
||||
timeout time.Duration
|
||||
zapReplaceGlobals bool
|
||||
zapEncoding string
|
||||
)
|
||||
|
||||
func init() {
|
||||
flag.StringVar(&logLevel, "log-level", "debug", "Log level can be: debug, info, warning, error.")
|
||||
flag.StringVar(&port, "port", "9090", "Port to listen on.")
|
||||
flag.DurationVar(&timeout, "timeout", time.Hour, "Command exec timeout.")
|
||||
flag.BoolVar(&logCmdOutput, "log-cmd-output", true, "Log command output to stderr")
|
||||
flag.DurationVar(&timeout, "timeout", time.Hour, "Load test exec timeout.")
|
||||
flag.BoolVar(&zapReplaceGlobals, "zap-replace-globals", false, "Whether to change the logging level of the global zap logger.")
|
||||
flag.StringVar(&zapEncoding, "zap-encoding", "json", "Zap logger encoding.")
|
||||
}
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
logger, err := logging.NewLogger(logLevel)
|
||||
logger, err := logger.NewLoggerWithEncoding(logLevel, zapEncoding)
|
||||
if err != nil {
|
||||
log.Fatalf("Error creating logger: %v", err)
|
||||
}
|
||||
if zapReplaceGlobals {
|
||||
zap.ReplaceGlobals(logger.Desugar())
|
||||
}
|
||||
|
||||
defer logger.Sync()
|
||||
|
||||
stopCh := signals.SetupSignalHandler()
|
||||
|
||||
taskRunner := loadtester.NewTaskRunner(logger, timeout, logCmdOutput)
|
||||
taskRunner := loadtester.NewTaskRunner(logger, timeout)
|
||||
|
||||
go taskRunner.Start(100*time.Millisecond, stopCh)
|
||||
|
||||
|
||||
BIN
docs/diagrams/flagger-abtest-steps.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 158 KiB |
{kind=link}
|
Before Width: | Height: | Size: 207 KiB After Width: | Height: | Size: 46 KiB |
BIN
docs/diagrams/flagger-flux-gitops.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 130 KiB |
BIN
docs/diagrams/flagger-gitops-aws.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
docs/diagrams/flagger-gke-istio.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 196 KiB |
{kind=link}
|
Before Width: | Height: | Size: 183 KiB After Width: | Height: | Size: 46 KiB |
BIN
docs/diagrams/istio-cert-manager-gke.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 205 KiB |
@@ -1,21 +1,21 @@
|
||||
---
|
||||
description: Flagger is an Istio progressive delivery Kubernetes operator
|
||||
description: Flagger is a progressive delivery Kubernetes operator
|
||||
---
|
||||
|
||||
# Introduction
|
||||
|
||||
[Flagger](https://github.com/stefanprodan/flagger) is a **Kubernetes** operator that automates the promotion of canary
|
||||
deployments using **Istio** routing for traffic shifting and **Prometheus** metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running integration tests,
|
||||
load tests or any other custom validation.
|
||||
[Flagger](https://github.com/weaveworks/flagger) is a **Kubernetes** operator that automates the promotion of canary
|
||||
deployments using **Istio** or **App Mesh** routing for traffic shifting and **Prometheus** metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running
|
||||
system integration/acceptance tests, load tests, or any other custom validation.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pods health.
|
||||
Based on the **KPIs** analysis a canary is promoted or aborted and the analysis result is published to **Slack**.
|
||||
Based on analysis of the **KPIs** a canary is promoted or aborted, and the analysis result is published to **Slack**.
|
||||
|
||||

|
||||

|
||||
|
||||
Flagger can be configured with Kubernetes custom resources \(canaries.flagger.app kind\) and is compatible with
|
||||
Flagger can be configured with Kubernetes custom resources and is compatible with
|
||||
any CI/CD solutions made for Kubernetes. Since Flagger is declarative and reacts to Kubernetes events,
|
||||
it can be used in **GitOps** pipelines together with Weave Flux or JenkinsX.
|
||||
|
||||
|
||||
@@ -5,13 +5,20 @@
|
||||
|
||||
## Install
|
||||
|
||||
* [Install Flagger](install/install-flagger.md)
|
||||
* [Install Grafana](install/install-grafana.md)
|
||||
* [Install Istio](install/install-istio.md)
|
||||
* [Flagger Install on Kubernetes](install/flagger-install-on-kubernetes.md)
|
||||
* [Flagger Install on GKE Istio](install/flagger-install-on-google-cloud.md)
|
||||
* [Flagger Install on EKS App Mesh](install/flagger-install-on-eks-appmesh.md)
|
||||
* [Flagger Install with SuperGloo](install/flagger-install-with-supergloo.md)
|
||||
|
||||
## Usage
|
||||
|
||||
* [Canary Deployments](usage/progressive-delivery.md)
|
||||
* [Istio Canary Deployments](usage/progressive-delivery.md)
|
||||
* [Istio A/B Testing](usage/ab-testing.md)
|
||||
* [App Mesh Canary Deployments](usage/appmesh-progressive-delivery.md)
|
||||
* [Monitoring](usage/monitoring.md)
|
||||
* [Alerting](usage/alerting.md)
|
||||
|
||||
## Tutorials
|
||||
|
||||
* [Canaries with Helm charts and GitOps](tutorials/canary-helm-gitops.md)
|
||||
* [Zero downtime deployments](tutorials/zero-downtime-deployments.md)
|
||||
|
||||
21
docs/gitbook/faq.md
Normal file
@@ -0,0 +1,21 @@
|
||||
# Frequently asked questions
|
||||
|
||||
**Can Flagger be part of my integration tests?**
|
||||
> Yes, Flagger supports webhooks to do integration testing.
|
||||
|
||||
**What if I only want to target beta testers?**
|
||||
> That's a feature in Flagger, not in App Mesh. It's on the App Mesh roadmap.
|
||||
|
||||
**When do I use A/B testing when Canary?**
|
||||
> One advantage of using A/B testing is that each version remains separated and routes aren't mixed.
|
||||
>
|
||||
> Using a Canary deployment can lead to behaviour like this one observed by a
|
||||
> user:
|
||||
>
|
||||
> [..] during a canary deployment of our nodejs app, the version that is being served <50% traffic reports mime type mismatch errors in the browser (js as "text/html")
|
||||
> When the deployment Passes/ Fails (doesn't really matter) the version that stays alive works as expected. If anyone has any tips or direction I would greatly appreciate it. Even if its as simple as I'm looking in the wrong place. Thanks in advance!
|
||||
>
|
||||
> The issue was that we were not maintaining session affinity while serving files for our frontend. Which resulted in any redirects or refreshes occasionally returning a mismatched app.*.js file (generated from vue)
|
||||
>
|
||||
> Read up on [A/B testing](https://docs.flagger.app/usage/ab-testing).
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
# How it works
|
||||
|
||||
[Flagger](https://github.com/stefanprodan/flagger) takes a Kubernetes deployment and optionally
|
||||
[Flagger](https://github.com/weaveworks/flagger) takes a Kubernetes deployment and optionally
|
||||
a horizontal pod autoscaler \(HPA\) and creates a series of objects
|
||||
\(Kubernetes deployments, ClusterIP services and Istio virtual services\) to drive the canary analysis and promotion.
|
||||
\(Kubernetes deployments, ClusterIP services and Istio or App Mesh virtual services\) to drive the canary analysis and promotion.
|
||||
|
||||
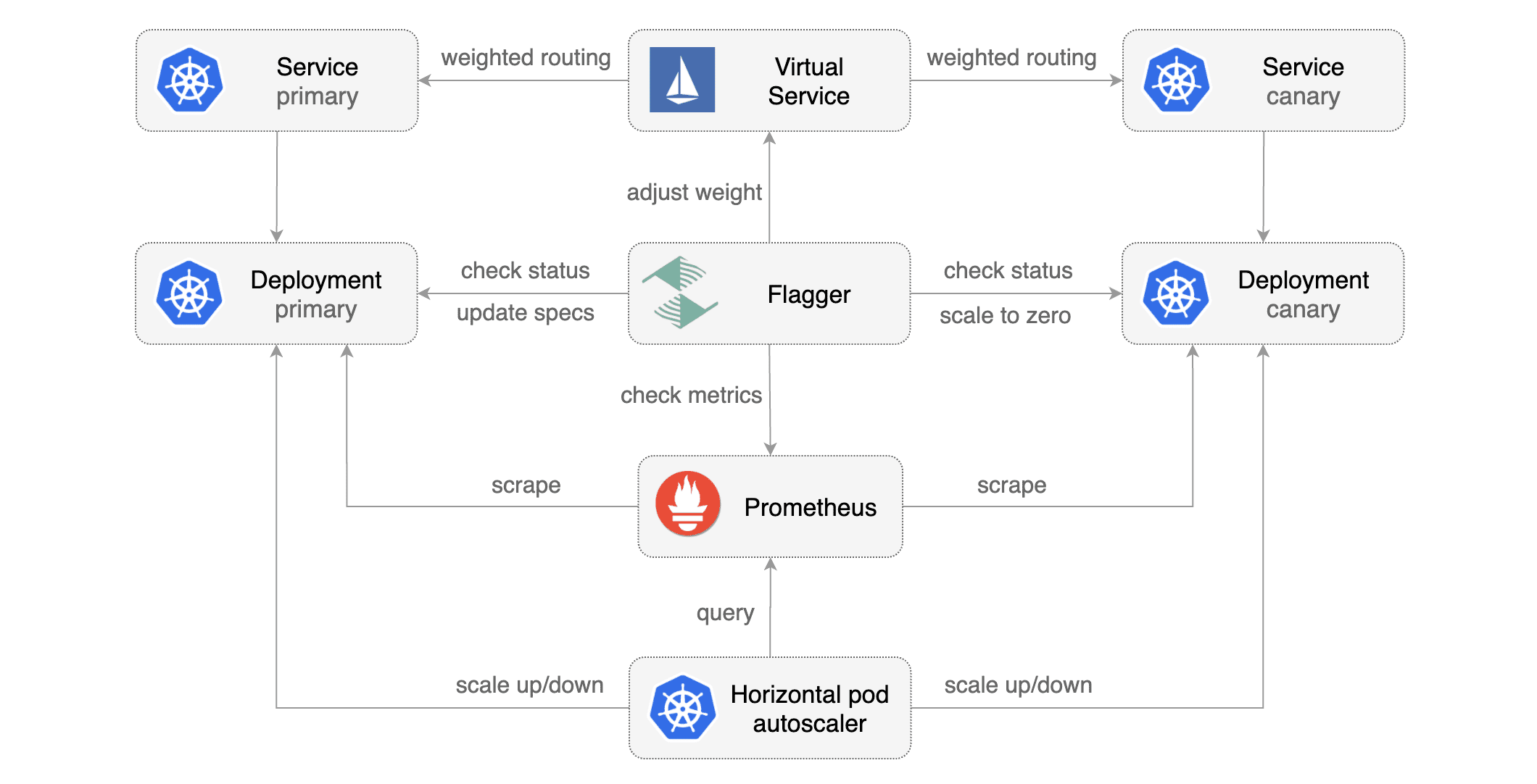
|
||||

|
||||
|
||||
### Canary Custom Resource
|
||||
|
||||
@@ -33,12 +33,18 @@ spec:
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# service port name (optional, will default to "http")
|
||||
portName: http-podinfo
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- podinfo.example.com
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
@@ -50,14 +56,14 @@ spec:
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
# Prometheus checks
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
@@ -90,12 +96,167 @@ spec:
|
||||
app: podinfo
|
||||
```
|
||||
|
||||
Besides `app` Flagger supports `name` and `app.kubernetes.io/name` selectors. If you use a different
|
||||
convention you can specify your label with the `-selector-labels` flag.
|
||||
|
||||
The target deployment should expose a TCP port that will be used by Flagger to create the ClusterIP Service and
|
||||
the Istio Virtual Service. The container port from the target deployment should match the `service.port` value.
|
||||
|
||||
### Canary Deployment
|
||||
### Istio routing
|
||||
|
||||

|
||||
Flagger creates an Istio Virtual Service based on the Canary service spec. The service configuration lets you expose
|
||||
an app inside or outside the mesh.
|
||||
You can also define HTTP match conditions, URI rewrite rules, CORS policies, timeout and retries.
|
||||
|
||||
The following spec exposes the `frontend` workload inside the mesh on `frontend.test.svc.cluster.local:9898`
|
||||
and outside the mesh on `frontend.example.com`. You'll have to specify an Istio ingress gateway for external hosts.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# service port name (optional, will default to "http")
|
||||
portName: http-frontend
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# cross-origin resource sharing policy (optional)
|
||||
corsPolicy:
|
||||
allowOrigin:
|
||||
- example.com
|
||||
allowMethods:
|
||||
- GET
|
||||
allowCredentials: false
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
maxAge: 24h
|
||||
```
|
||||
|
||||
For the above spec Flagger will generate the following virtual service:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1alpha3
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: podinfo
|
||||
uid: 3a4a40dd-3875-11e9-8e1d-42010a9c0fd1
|
||||
spec:
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
- frontend
|
||||
http:
|
||||
- appendHeaders:
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: gateway-error,connect-failure,refused-stream
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
corsPolicy:
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
allowMethods:
|
||||
- GET
|
||||
allowOrigin:
|
||||
- example.com
|
||||
maxAge: 24h
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
rewrite:
|
||||
uri: /
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
port:
|
||||
number: 9898
|
||||
weight: 100
|
||||
- destination:
|
||||
host: podinfo-canary
|
||||
port:
|
||||
number: 9898
|
||||
weight: 0
|
||||
```
|
||||
|
||||
Flagger keeps in sync the virtual service with the canary service spec. Any direct modification to the virtual
|
||||
service spec will be overwritten.
|
||||
|
||||
To expose a workload inside the mesh on `http://backend.test.svc.cluster.local:9898`,
|
||||
the service spec can contain only the container port:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: backend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
```
|
||||
|
||||
Based on the above spec, Flagger will create several ClusterIP services like:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: backend-primary
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1alpha3
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: backend
|
||||
uid: 2ca1a9c7-2ef6-11e9-bd01-42010a9c0145
|
||||
spec:
|
||||
type: ClusterIP
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: 9898
|
||||
selector:
|
||||
app: backend-primary
|
||||
```
|
||||
|
||||
Flagger works for user facing apps exposed outside the cluster via an ingress gateway
|
||||
and for backend HTTP APIs that are accessible only from inside the mesh.
|
||||
|
||||
### Canary Stages
|
||||
|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
@@ -110,16 +271,22 @@ Gated canary promotion stages:
|
||||
* check primary and canary deployments status
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* call pre-rollout webhooks are check results
|
||||
* halt advancement if any hook returned a non HTTP 2xx result
|
||||
* increment the failed checks counter
|
||||
* increase canary traffic weight percentage from 0% to 5% (step weight)
|
||||
* call webhooks and check results
|
||||
* call rollout webhooks and check results
|
||||
* check canary HTTP request success rate and latency
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* check if the number of failed checks reached the threshold
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* call post-rollout webhooks
|
||||
* post the analysis result to Slack
|
||||
* wait for the canary deployment to be updated and start over
|
||||
* increase canary traffic weight by 5% (step weight) till it reaches 50% (max weight)
|
||||
* halt advancement if any webhook call fails
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
@@ -132,6 +299,8 @@ Gated canary promotion stages:
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment
|
||||
* mark rollout as finished
|
||||
* call post-rollout webhooks
|
||||
* post the analysis result to Slack
|
||||
* wait for the canary deployment to be updated and start over
|
||||
|
||||
### Canary Analysis
|
||||
@@ -152,6 +321,9 @@ Spec:
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 2
|
||||
# deploy straight to production without
|
||||
# the metrics and webhook checks
|
||||
skipAnalysis: false
|
||||
```
|
||||
|
||||
The above analysis, if it succeeds, will run for 25 minutes while validating the HTTP metrics and webhooks every minute.
|
||||
@@ -167,6 +339,54 @@ And the time it takes for a canary to be rollback when the metrics or webhook ch
|
||||
interval * threshold
|
||||
```
|
||||
|
||||
In emergency cases, you may want to skip the analysis phase and ship changes directly to production.
|
||||
At any time you can set the `spec.skipAnalysis: true`.
|
||||
When skip analysis is enabled, Flagger checks if the canary deployment is healthy and
|
||||
promotes it without analysing it. If an analysis is underway, Flagger cancels it and runs the promotion.
|
||||
|
||||
### A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
You can enable A/B testing by specifying the HTTP match conditions and the number of iterations:
|
||||
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
# canary match condition
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: "^(?!.*Chrome).*Safari.*"
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(user=test)(;.*)?$"
|
||||
```
|
||||
|
||||
If Flagger finds a HTTP match condition, it will ignore the `maxWeight` and `stepWeight` settings.
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting the Safari users and those that have a test cookie.
|
||||
You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
|
||||
|
||||
```
|
||||
interval * iterations
|
||||
```
|
||||
|
||||
And the time it takes for a canary to be rollback when the metrics or webhook checks are failing:
|
||||
|
||||
```
|
||||
interval * threshold
|
||||
```
|
||||
|
||||
Make sure that the analysis threshold is lower than the number of iterations.
|
||||
|
||||
### HTTP Metrics
|
||||
|
||||
The canary analysis is using the following Prometheus queries:
|
||||
@@ -178,14 +398,14 @@ Spec:
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
Query:
|
||||
Istio query:
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
@@ -210,6 +430,29 @@ sum(
|
||||
)
|
||||
```
|
||||
|
||||
App Mesh query:
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="$namespace",
|
||||
kubernetes_pod_name=~"$workload",
|
||||
response_code!~"5.*"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="$namespace",
|
||||
kubernetes_pod_name=~"$workload"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
**HTTP requests milliseconds duration P99**
|
||||
|
||||
Spec:
|
||||
@@ -217,14 +460,14 @@ Spec:
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
metrics:
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
Query:
|
||||
Istio query:
|
||||
|
||||
```javascript
|
||||
histogram_quantile(0.99,
|
||||
@@ -240,40 +483,145 @@ histogram_quantile(0.99,
|
||||
)
|
||||
```
|
||||
|
||||
App Mesh query:
|
||||
|
||||
```javascript
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
irate(
|
||||
envoy_cluster_upstream_rq_time_bucket{
|
||||
kubernetes_pod_name=~"$workload",
|
||||
kubernetes_namespace=~"$namespace"
|
||||
}[$interval]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
> **Note** that the metric interval should be lower or equal to the control loop interval.
|
||||
|
||||
### Custom Metrics
|
||||
|
||||
The canary analysis can be extended with custom Prometheus queries.
|
||||
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
threshold: 1
|
||||
maxWeight: 50
|
||||
stepWeight: 5
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
threshold: 5
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="test",
|
||||
destination_workload="podinfo",
|
||||
response_code!="404"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="test",
|
||||
destination_workload="podinfo"
|
||||
}[1m]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking
|
||||
if the HTTP 404 req/sec percentage is below 5 percent of the total traffic.
|
||||
If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
threshold: 1
|
||||
maxWeight: 50
|
||||
stepWeight: 5
|
||||
metrics:
|
||||
- name: "rpc error rate"
|
||||
threshold: 5
|
||||
query: |
|
||||
100 - (sum
|
||||
rate(
|
||||
grpc_server_handled_total{
|
||||
grpc_service="my.TestService",
|
||||
grpc_code!="OK"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
grpc_server_started_total{
|
||||
grpc_service="my.TestService"
|
||||
}[1m]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the percentage of
|
||||
non-OK GRPC req/sec is below 5 percent of the total requests. If the non-OK
|
||||
rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
When specifying a query, Flagger will run the promql query and convert the result to float64.
|
||||
Then it compares the query result value with the metric threshold value.
|
||||
|
||||
### Webhooks
|
||||
|
||||
The canary analysis can be extended with webhooks.
|
||||
Flagger will call each webhook URL and determine from the response status code (HTTP 2xx) if the canary is failing or not.
|
||||
The canary analysis can be extended with webhooks. Flagger will call each webhook URL and
|
||||
determine from the response status code (HTTP 2xx) if the canary is failing or not.
|
||||
|
||||
There are three types of hooks:
|
||||
* Pre-rollout hooks are executed before routing traffic to canary.
|
||||
The canary advancement is paused if a pre-rollout hook fails and if the number of failures reach the
|
||||
threshold the canary will be rollback.
|
||||
* Rollout hooks are executed during the analysis on each iteration before the metric checks.
|
||||
If a rollout hook call fails the canary advancement is paused and eventfully rolled back.
|
||||
* Post-rollout hooks are executed after the canary has been promoted or rolled back.
|
||||
If a post rollout hook fails the error is logged.
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
webhooks:
|
||||
- name: integration-tests
|
||||
url: http://podinfo.test:9898/echo
|
||||
timeout: 30s
|
||||
metadata:
|
||||
test: "all"
|
||||
token: "16688eb5e9f289f1991c"
|
||||
- name: load-tests
|
||||
url: http://podinfo.test:9898/echo
|
||||
- name: "smoke test"
|
||||
type: pre-rollout
|
||||
url: http://migration-check.db/query
|
||||
timeout: 30s
|
||||
metadata:
|
||||
key1: "val1"
|
||||
key2: "val2"
|
||||
- name: "load test"
|
||||
type: rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 15s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 http://podinfo-canary.test:9898/"
|
||||
- name: "notify"
|
||||
type: post-rollout
|
||||
url: http://telegram.bot:8080/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
some: "message"
|
||||
```
|
||||
|
||||
> **Note** that the sum of all webhooks timeouts should be lower than the control loop interval.
|
||||
> **Note** that the sum of all rollout webhooks timeouts should be lower than the analysis interval.
|
||||
|
||||
Webhook payload (HTTP POST):
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "podinfo",
|
||||
"namespace": "test",
|
||||
"namespace": "test",
|
||||
"phase": "Progressing",
|
||||
"metadata": {
|
||||
"test": "all",
|
||||
"token": "16688eb5e9f289f1991c"
|
||||
@@ -298,12 +646,12 @@ Flagger metric checks will fail with "no values found for metric istio_requests_
|
||||
Flagger comes with a load testing service based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
that generates traffic during analysis when configured as a webhook.
|
||||
|
||||
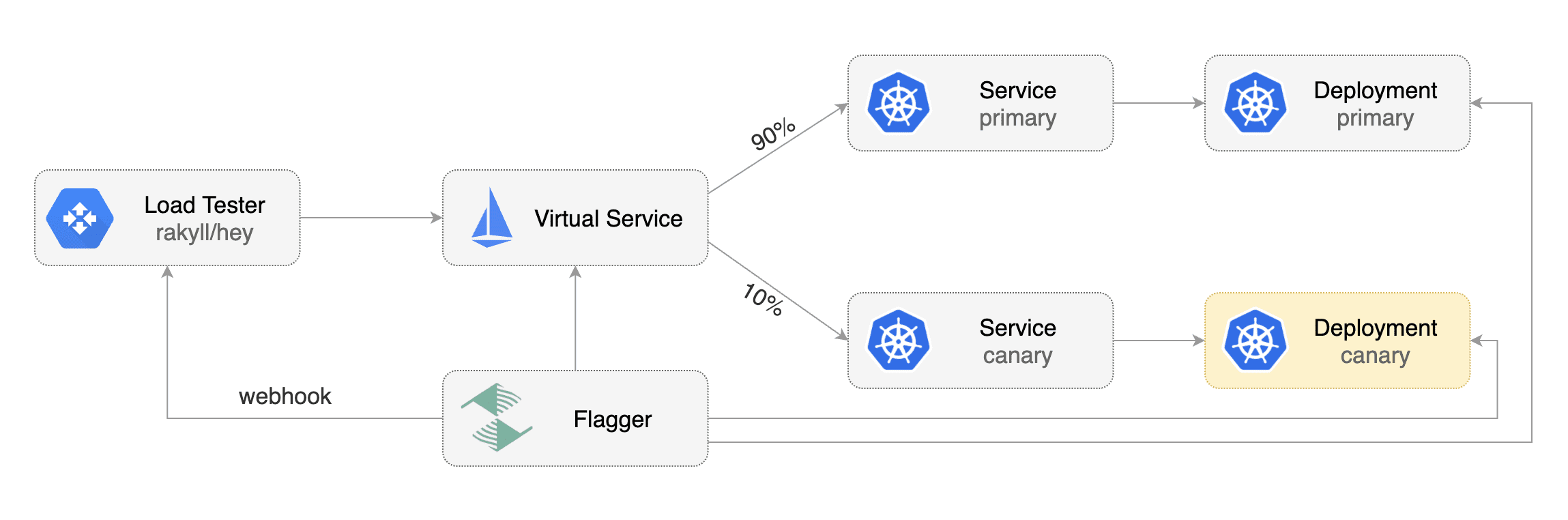
|
||||
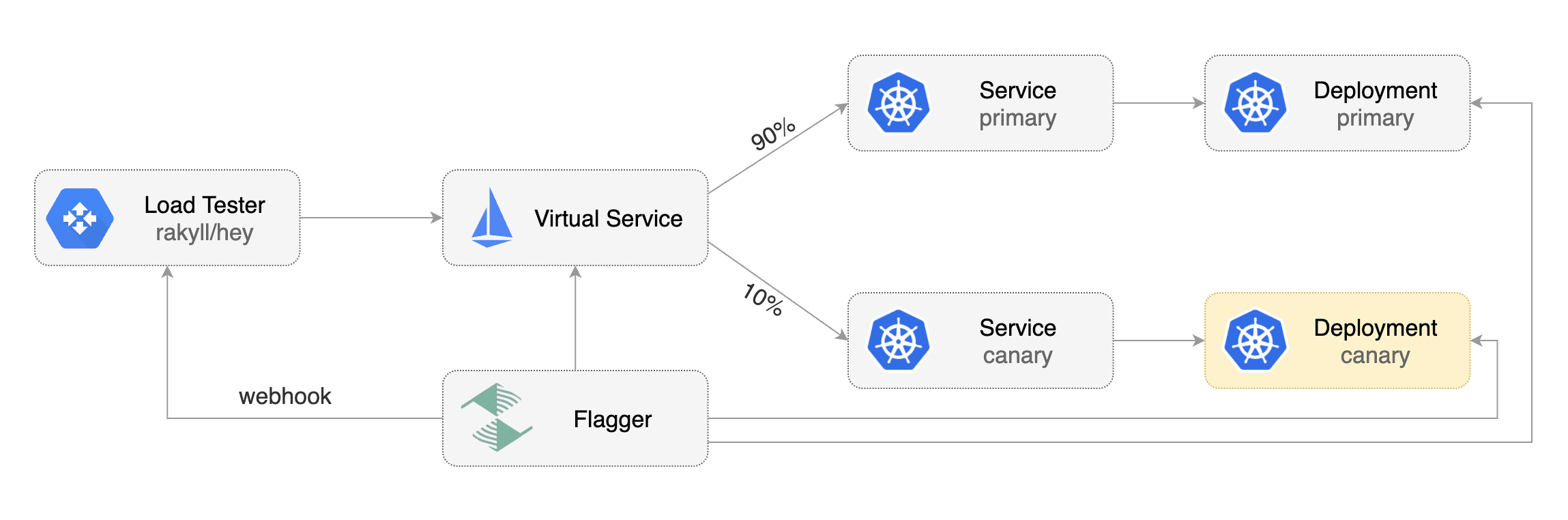
|
||||
|
||||
First you need to deploy the load test runner in a namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
@@ -315,8 +663,7 @@ Or by using Helm:
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namepace=test \
|
||||
--set cmd.logOutput=true \
|
||||
--namespace=test \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
@@ -330,11 +677,13 @@ webhooks:
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
- name: load-test-post
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 -m POST -d '{test: 2}' http://podinfo.test:9898/echo"
|
||||
```
|
||||
|
||||
@@ -351,6 +700,7 @@ webhooks:
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 -h2 https://podinfo.example.com/"
|
||||
```
|
||||
|
||||
@@ -363,3 +713,32 @@ FROM quay.io/stefanprodan/flagger-loadtester:<VER>
|
||||
RUN curl -Lo /usr/local/bin/my-cli https://github.com/user/repo/releases/download/ver/my-cli \
|
||||
&& chmod +x /usr/local/bin/my-cli
|
||||
```
|
||||
|
||||
### Load Testing Delegation
|
||||
|
||||
The load tester can also forward testing tasks to external tools, by now [nGrinder](https://github.com/naver/ngrinder)
|
||||
is supported.
|
||||
|
||||
To use this feature, add a load test task of type 'ngrinder' to the canary analysis spec:
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-post
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
# type of this load test task, cmd or ngrinder
|
||||
type: ngrinder
|
||||
# base url of your nGrinder controller server
|
||||
server: http://ngrinder-server:port
|
||||
# id of the test to clone from, the test must have been defined.
|
||||
clone: 100
|
||||
# user name and base64 encoded password to authenticate against the nGrinder server
|
||||
username: admin
|
||||
passwd: YWRtaW4=
|
||||
# the interval between between nGrinder test status polling, default to 1s
|
||||
pollInterval: 5s
|
||||
```
|
||||
When the canary analysis starts, the load tester will initiate a [clone_and_start request](https://github.com/naver/ngrinder/wiki/REST-API-PerfTest)
|
||||
to the nGrinder server and start a new performance test. the load tester will periodically poll the nGrinder server
|
||||
for the status of the test, and prevent duplicate requests from being sent in subsequent analysis loops.
|
||||
|
||||
188
docs/gitbook/install/flagger-install-on-eks-appmesh.md
Normal file
@@ -0,0 +1,188 @@
|
||||
# Flagger install on AWS
|
||||
|
||||
This guide walks you through setting up Flagger and AWS App Mesh on EKS.
|
||||
|
||||
### App Mesh
|
||||
|
||||
The App Mesh integration with EKS is made out of the following components:
|
||||
|
||||
* Kubernetes custom resources
|
||||
* `mesh.appmesh.k8s.aws` defines a logical boundary for network traffic between the services
|
||||
* `virtualnode.appmesh.k8s.aws` defines a logical pointer to a Kubernetes workload
|
||||
* `virtualservice.appmesh.k8s.aws` defines the routing rules for a workload inside the mesh
|
||||
* CRD controller - keeps the custom resources in sync with the App Mesh control plane
|
||||
* Admission controller - injects the Envoy sidecar and assigns Kubernetes pods to App Mesh virtual nodes
|
||||
* Metrics server - Prometheus instance that collects and stores Envoy's metrics
|
||||
|
||||
Prerequisites:
|
||||
|
||||
* jq
|
||||
* homebrew
|
||||
* openssl
|
||||
* kubectl
|
||||
* AWS CLI (default region us-west-2)
|
||||
|
||||
### Create a Kubernetes cluster
|
||||
|
||||
In order to create an EKS cluster you can use [eksctl](https://eksctl.io).
|
||||
Eksctl is an open source command-line utility made by Weaveworks in collaboration with Amazon,
|
||||
it’s a Kubernetes-native tool written in Go.
|
||||
|
||||
On MacOS you can install eksctl with Homebrew:
|
||||
|
||||
```bash
|
||||
brew tap weaveworks/tap
|
||||
brew install weaveworks/tap/eksctl
|
||||
```
|
||||
|
||||
Create an EKS cluster:
|
||||
|
||||
```bash
|
||||
eksctl create cluster --name=appmesh \
|
||||
--region=us-west-2 \
|
||||
--appmesh-access
|
||||
```
|
||||
|
||||
The above command will create a two nodes cluster with App Mesh
|
||||
[IAM policy](https://docs.aws.amazon.com/app-mesh/latest/userguide/MESH_IAM_user_policies.html)
|
||||
attached to the EKS node instance role.
|
||||
|
||||
Verify the install with:
|
||||
|
||||
```bash
|
||||
kubectl get nodes
|
||||
```
|
||||
|
||||
### Install Helm
|
||||
|
||||
Install the [Helm](https://docs.helm.sh/using_helm/#installing-helm) command-line tool:
|
||||
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
Create a service account and a cluster role binding for Tiller:
|
||||
|
||||
```bash
|
||||
kubectl -n kube-system create sa tiller
|
||||
|
||||
kubectl create clusterrolebinding tiller-cluster-rule \
|
||||
--clusterrole=cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
Deploy Tiller in the `kube-system` namespace:
|
||||
|
||||
```bash
|
||||
helm init --service-account tiller
|
||||
```
|
||||
|
||||
You should consider using SSL between Helm and Tiller, for more information on securing your Helm
|
||||
installation see [docs.helm.sh](https://docs.helm.sh/using_helm/#securing-your-helm-installation).
|
||||
|
||||
### Enable horizontal pod auto-scaling
|
||||
|
||||
Install the Horizontal Pod Autoscaler (HPA) metrics provider:
|
||||
|
||||
```bash
|
||||
helm upgrade -i metrics-server stable/metrics-server \
|
||||
--namespace kube-system
|
||||
```
|
||||
|
||||
After a minute, the metrics API should report CPU and memory usage for pods.
|
||||
You can very the metrics API with:
|
||||
|
||||
```bash
|
||||
kubectl -n kube-system top pods
|
||||
```
|
||||
|
||||
### Install the App Mesh components
|
||||
|
||||
Run the App Mesh installer:
|
||||
|
||||
```bash
|
||||
curl -fsSL https://git.io/get-app-mesh-eks.sh | bash -
|
||||
```
|
||||
|
||||
The installer does the following:
|
||||
|
||||
* creates the `appmesh-system` namespace
|
||||
* generates a certificate signed by Kubernetes CA
|
||||
* registers the App Mesh mutating webhook
|
||||
* deploys the App Mesh webhook in `appmesh-system` namespace
|
||||
* deploys the App Mesh CRDs
|
||||
* deploys the App Mesh controller in `appmesh-system` namespace
|
||||
* creates a mesh called `global`
|
||||
|
||||
Verify that the global mesh is active:
|
||||
|
||||
```bash
|
||||
kubectl describe mesh
|
||||
|
||||
Status:
|
||||
Mesh Condition:
|
||||
Status: True
|
||||
Type: MeshActive
|
||||
```
|
||||
|
||||
### Install Prometheus
|
||||
|
||||
In order to collect the App Mesh metrics that Flagger needs to run the canary analysis,
|
||||
you'll need to setup a Prometheus instance to scrape the Envoy sidecars.
|
||||
|
||||
Deploy Prometheus in the `appmesh-system` namespace:
|
||||
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/eks/appmesh-prometheus.yaml
|
||||
```
|
||||
|
||||
### Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**appmesh-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=appmesh-system \
|
||||
--set meshProvider=appmesh \
|
||||
--set metricsServer=http://prometheus.appmesh-system:9090
|
||||
```
|
||||
|
||||
You can install Flagger in any namespace as long as it can talk to the Istio Prometheus service on port 9090.
|
||||
|
||||
You can enable **Slack** notifications with:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=appmesh-system \
|
||||
--set meshProvider=appmesh \
|
||||
--set metricsServer=http://prometheus.appmesh:9090 \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
Deploy Grafana in the _**appmesh-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=appmesh-system \
|
||||
--set url=http://prometheus.appmesh-system:9090
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n appmesh-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
Now that you have Flagger running you can try the
|
||||
[App Mesh canary deployments tutorial](https://docs.flagger.app/usage/appmesh-progressive-delivery).
|
||||
@@ -1,16 +1,15 @@
|
||||
# Install Istio
|
||||
# Flagger install on Google Cloud
|
||||
|
||||
This guide walks you through setting up Istio with Jaeger, Prometheus, Grafana and
|
||||
Let’s Encrypt TLS for ingress gateway on Google Kubernetes Engine.
|
||||
This guide walks you through setting up Flagger and Istio on Google Kubernetes Engine.
|
||||
|
||||
|
||||
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You will be creating a cluster on Google’s Kubernetes Engine \(GKE\),
|
||||
if you don’t have an account you can sign up [here](https://cloud.google.com/free/) for free credits.
|
||||
|
||||
Login into GCP, create a project and enable billing for it.
|
||||
Login into Google Cloud, create a project and enable billing for it.
|
||||
|
||||
Install the [gcloud](https://cloud.google.com/sdk/) command line utility and configure your project with `gcloud init`.
|
||||
|
||||
@@ -23,8 +22,8 @@ gcloud config set project PROJECT_ID
|
||||
Set the default compute region and zone:
|
||||
|
||||
```text
|
||||
gcloud config set compute/region europe-west3
|
||||
gcloud config set compute/zone europe-west3-a
|
||||
gcloud config set compute/region us-central1
|
||||
gcloud config set compute/zone us-central1-a
|
||||
```
|
||||
|
||||
Enable the Kubernetes and Cloud DNS services for your project:
|
||||
@@ -34,46 +33,42 @@ gcloud services enable container.googleapis.com
|
||||
gcloud services enable dns.googleapis.com
|
||||
```
|
||||
|
||||
Install the `kubectl` command-line tool:
|
||||
Install the kubectl command-line tool:
|
||||
|
||||
```text
|
||||
gcloud components install kubectl
|
||||
```
|
||||
|
||||
Install the `helm` command-line tool:
|
||||
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
### GKE cluster setup
|
||||
|
||||
Create a cluster with three nodes using the latest Kubernetes version:
|
||||
Create a cluster with the Istio add-on:
|
||||
|
||||
```bash
|
||||
k8s_version=$(gcloud container get-server-config --format=json \
|
||||
| jq -r '.validNodeVersions[0]')
|
||||
K8S_VERSION=$(gcloud container get-server-config --format=json \
|
||||
| jq -r '.validMasterVersions[0]')
|
||||
|
||||
gcloud container clusters create istio \
|
||||
--cluster-version=${k8s_version} \
|
||||
--zone=europe-west3-a \
|
||||
--num-nodes=3 \
|
||||
gcloud beta container clusters create istio \
|
||||
--cluster-version=${K8S_VERSION} \
|
||||
--zone=us-central1-a \
|
||||
--num-nodes=2 \
|
||||
--machine-type=n1-highcpu-4 \
|
||||
--preemptible \
|
||||
--no-enable-cloud-logging \
|
||||
--no-enable-cloud-monitoring \
|
||||
--disk-size=30 \
|
||||
--enable-autorepair \
|
||||
--scopes=gke-default,compute-rw,storage-rw
|
||||
--addons=HorizontalPodAutoscaling,Istio \
|
||||
--istio-config=auth=MTLS_PERMISSIVE
|
||||
```
|
||||
|
||||
The above command will create a default node pool consisting of `n1-highcpu-4` \(vCPU: 4, RAM 3.60GB, DISK: 30GB\)
|
||||
The above command will create a default node pool consisting of two `n1-highcpu-4` \(vCPU: 4, RAM 3.60GB, DISK: 30GB\)
|
||||
preemptible VMs. Preemptible VMs are up to 80% cheaper than regular instances and are terminated and replaced
|
||||
after a maximum of 24 hours.
|
||||
|
||||
Set up credentials for `kubectl`:
|
||||
|
||||
```bash
|
||||
gcloud container clusters get-credentials istio -z=europe-west3-a
|
||||
gcloud container clusters get-credentials istio
|
||||
```
|
||||
|
||||
Create a cluster admin role binding:
|
||||
@@ -87,9 +82,11 @@ kubectl create clusterrolebinding "cluster-admin-$(whoami)" \
|
||||
Validate your setup with:
|
||||
|
||||
```bash
|
||||
kubectl get nodes -o wide
|
||||
kubectl -n istio-system get svc
|
||||
```
|
||||
|
||||
In a couple of seconds GCP should allocate an external IP to the `istio-ingressgateway` service.
|
||||
|
||||
### Cloud DNS setup
|
||||
|
||||
You will need an internet domain and access to the registrar to change the name servers to Google Cloud DNS.
|
||||
@@ -116,34 +113,30 @@ Wait for the name servers to change \(replace `example.com` with your domain\):
|
||||
watch dig +short NS example.com
|
||||
```
|
||||
|
||||
Create a static IP address named `istio-gateway-ip` in the same region as your GKE cluster:
|
||||
Create a static IP address named `istio-gateway` using the Istio ingress IP:
|
||||
|
||||
```bash
|
||||
gcloud compute addresses create istio-gateway-ip --region europe-west3
|
||||
export GATEWAY_IP=$(kubectl -n istio-system get svc/istio-ingressgateway -ojson \
|
||||
| jq -r .status.loadBalancer.ingress[0].ip)
|
||||
|
||||
gcloud compute addresses create istio-gateway --addresses ${GATEWAY_IP} --region us-central1
|
||||
```
|
||||
|
||||
Find the static IP address:
|
||||
|
||||
```bash
|
||||
gcloud compute addresses describe istio-gateway-ip --region europe-west3
|
||||
```
|
||||
|
||||
Create the following DNS records \(replace `example.com` with your domain and set your Istio Gateway IP\):
|
||||
Create the following DNS records \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
DOMAIN="example.com"
|
||||
GATEWAYIP="35.198.98.90"
|
||||
|
||||
gcloud dns record-sets transaction start --zone=istio
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="www.${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="www.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="*.${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="*.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction execute --zone istio
|
||||
```
|
||||
@@ -154,31 +147,22 @@ Verify that the wildcard DNS is working \(replace `example.com` with your domain
|
||||
watch host test.example.com
|
||||
```
|
||||
|
||||
### Install Istio with Helm
|
||||
### Install Helm
|
||||
|
||||
Download the latest Istio release:
|
||||
Install the [Helm](https://docs.helm.sh/using_helm/#installing-helm) command-line tool:
|
||||
|
||||
```bash
|
||||
curl -L https://git.io/getLatestIstio | sh -
|
||||
```
|
||||
|
||||
Navigate to `istio-x.x.x` dir and copy the Istio CLI in your bin:
|
||||
|
||||
```bash
|
||||
cd istio-x.x.x/
|
||||
sudo cp ./bin/istioctl /usr/local/bin/istioctl
|
||||
```
|
||||
|
||||
Apply the Istio CRDs:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./install/kubernetes/helm/istio/templates/crds.yaml
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
Create a service account and a cluster role binding for Tiller:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./install/kubernetes/helm/helm-service-account.yaml
|
||||
kubectl -n kube-system create sa tiller
|
||||
|
||||
kubectl create clusterrolebinding tiller-cluster-rule \
|
||||
--clusterrole=cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
Deploy Tiller in the `kube-system` namespace:
|
||||
@@ -187,125 +171,53 @@ Deploy Tiller in the `kube-system` namespace:
|
||||
helm init --service-account tiller
|
||||
```
|
||||
|
||||
Find the GKE IP ranges:
|
||||
You should consider using SSL between Helm and Tiller, for more information on securing your Helm
|
||||
installation see [docs.helm.sh](https://docs.helm.sh/using_helm/#securing-your-helm-installation).
|
||||
|
||||
### Install cert-manager
|
||||
|
||||
Jetstack's [cert-manager](https://github.com/jetstack/cert-manager)
|
||||
is a Kubernetes operator that automatically creates and manages TLS certs issued by Let’s Encrypt.
|
||||
|
||||
You'll be using cert-manager to provision a wildcard certificate for the Istio ingress gateway.
|
||||
|
||||
Install cert-manager's CRDs:
|
||||
|
||||
```bash
|
||||
gcloud container clusters describe istio --zone=europe-west3-a \
|
||||
| grep -e clusterIpv4Cidr -e servicesIpv4Cidr
|
||||
CERT_REPO=https://raw.githubusercontent.com/jetstack/cert-manager
|
||||
|
||||
kubectl apply -f ${CERT_REPO}/release-0.7/deploy/manifests/00-crds.yaml
|
||||
```
|
||||
|
||||
You'll be using the IP ranges to allow unrestricted egress traffic for services running inside the service mesh.
|
||||
|
||||
Configure Istio with Prometheus, Jaeger, and cert-manager:
|
||||
|
||||
```yaml
|
||||
global:
|
||||
nodePort: false
|
||||
proxy:
|
||||
# replace with your GKE IP ranges
|
||||
includeIPRanges: "10.28.0.0/14,10.7.240.0/20"
|
||||
|
||||
sidecarInjectorWebhook:
|
||||
enabled: true
|
||||
enableNamespacesByDefault: false
|
||||
|
||||
gateways:
|
||||
enabled: true
|
||||
istio-ingressgateway:
|
||||
replicaCount: 2
|
||||
autoscaleMin: 2
|
||||
autoscaleMax: 3
|
||||
# replace with your Istio Gateway IP
|
||||
loadBalancerIP: "35.198.98.90"
|
||||
type: LoadBalancer
|
||||
|
||||
pilot:
|
||||
enabled: true
|
||||
replicaCount: 1
|
||||
autoscaleMin: 1
|
||||
autoscaleMax: 1
|
||||
resources:
|
||||
requests:
|
||||
cpu: 500m
|
||||
memory: 1024Mi
|
||||
|
||||
grafana:
|
||||
enabled: true
|
||||
security:
|
||||
enabled: true
|
||||
adminUser: admin
|
||||
# change the password
|
||||
adminPassword: admin
|
||||
|
||||
prometheus:
|
||||
enabled: true
|
||||
|
||||
servicegraph:
|
||||
enabled: true
|
||||
|
||||
tracing:
|
||||
enabled: true
|
||||
jaeger:
|
||||
tag: 1.7
|
||||
|
||||
certmanager:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
Save the above file as `my-istio.yaml` and install Istio with Helm:
|
||||
Create the cert-manager namespace and disable resource validation:
|
||||
|
||||
```bash
|
||||
helm upgrade --install istio ./install/kubernetes/helm/istio \
|
||||
--namespace=istio-system \
|
||||
-f ./my-istio.yaml
|
||||
kubectl create namespace cert-manager
|
||||
|
||||
kubectl label namespace cert-manager certmanager.k8s.io/disable-validation=true
|
||||
```
|
||||
|
||||
Verify that Istio workloads are running:
|
||||
Install cert-manager with Helm:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system get pods
|
||||
```bash
|
||||
helm repo add jetstack https://charts.jetstack.io && \
|
||||
helm repo update && \
|
||||
helm upgrade -i cert-manager \
|
||||
--namespace cert-manager \
|
||||
--version v0.7.0 \
|
||||
jetstack/cert-manager
|
||||
```
|
||||
|
||||
### Configure Istio Gateway with LE TLS
|
||||
### Istio Gateway TLS setup
|
||||
|
||||
|
||||
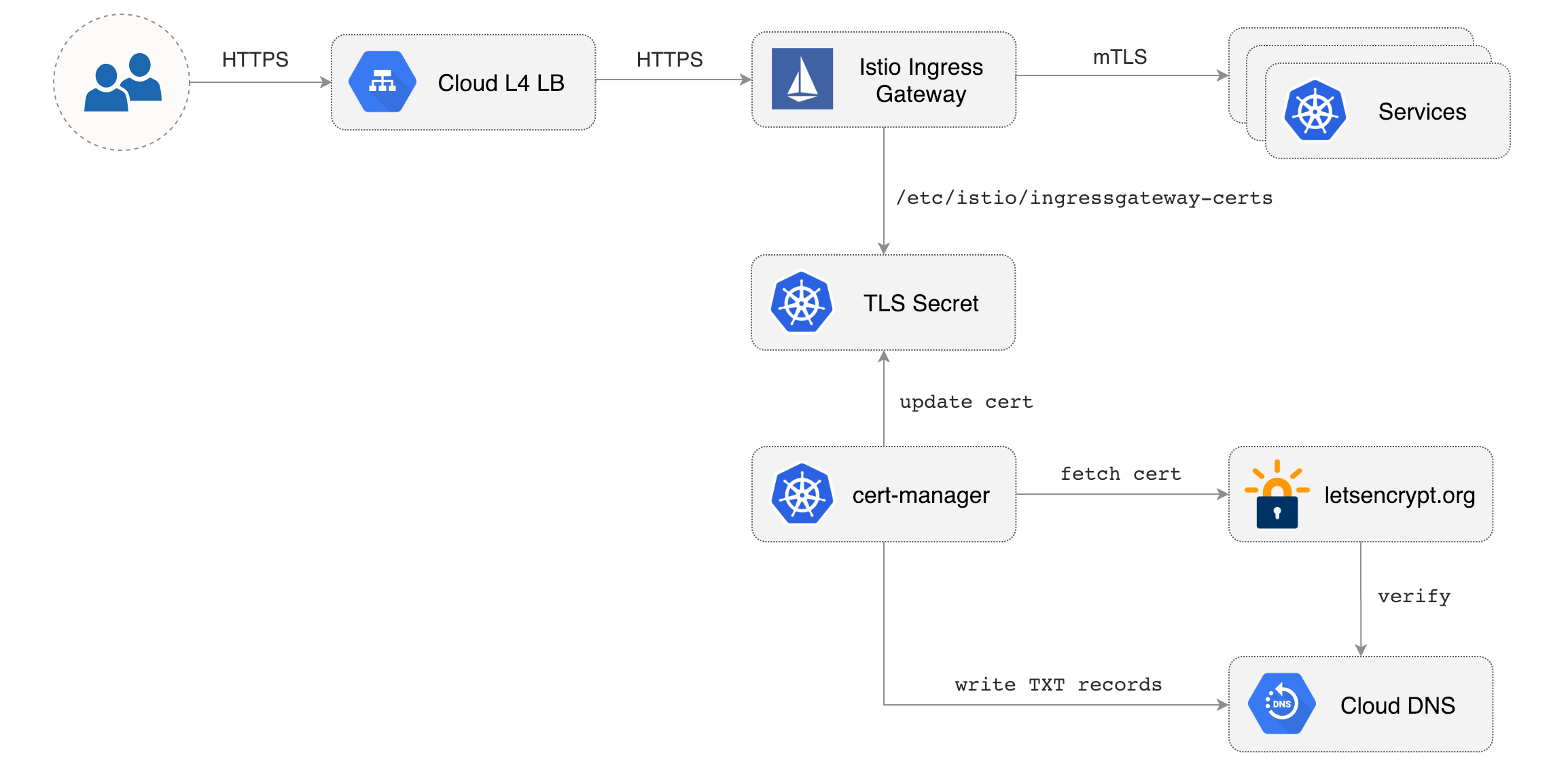
|
||||
|
||||
Create a Istio Gateway in istio-system namespace with HTTPS redirect:
|
||||
Create a generic Istio Gateway to expose services outside the mesh on HTTPS:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
httpsRedirect: true
|
||||
- port:
|
||||
number: 443
|
||||
name: https
|
||||
protocol: HTTPS
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
mode: SIMPLE
|
||||
privateKey: /etc/istio/ingressgateway-certs/tls.key
|
||||
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
|
||||
```
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
Save the above resource as istio-gateway.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./istio-gateway.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/gke/istio-gateway.yaml
|
||||
```
|
||||
|
||||
Create a service account with Cloud DNS admin role \(replace `my-gcp-project` with your project ID\):
|
||||
@@ -374,7 +286,7 @@ metadata:
|
||||
name: istio-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
secretname: istio-ingressgateway-certs
|
||||
secretName: istio-ingressgateway-certs
|
||||
issuerRef:
|
||||
name: letsencrypt-prod
|
||||
commonName: "*.example.com"
|
||||
@@ -387,37 +299,76 @@ spec:
|
||||
- "example.com"
|
||||
```
|
||||
|
||||
Save the above resource as of-cert.yaml and then apply it:
|
||||
Save the above resource as istio-gateway-cert.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./of-cert.yaml
|
||||
kubectl apply -f ./istio-gateway-cert.yaml
|
||||
```
|
||||
|
||||
In a couple of seconds cert-manager should fetch a wildcard certificate from letsencrypt.org:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system logs deployment/certmanager -f
|
||||
kubectl -n istio-system describe certificate istio-gateway
|
||||
|
||||
Certificate issued successfully
|
||||
Certificate istio-system/istio-gateway scheduled for renewal in 1438 hours
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal CertIssued 1m52s cert-manager Certificate issued successfully
|
||||
```
|
||||
|
||||
Recreate Istio ingress gateway pods:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system delete pods -l istio=ingressgateway
|
||||
kubectl -n istio-system get pods -l istio=ingressgateway
|
||||
```
|
||||
|
||||
Note that Istio gateway doesn't reload the certificates from the TLS secret on cert-manager renewal.
|
||||
Since the GKE cluster is made out of preemptible VMs the gateway pods will be replaced once every 24h,
|
||||
if your not using preemptible nodes then you need to manually kill the gateway pods every two months
|
||||
if your not using preemptible nodes then you need to manually delete the gateway pods every two months
|
||||
before the certificate expires.
|
||||
|
||||
### Expose services outside the service mesh
|
||||
### Install Prometheus
|
||||
|
||||
In order to expose services via the Istio Gateway you have to create a Virtual Service attached to Istio Gateway.
|
||||
The GKE Istio add-on does not include a Prometheus instance that scrapes the Istio telemetry service.
|
||||
Because Flagger uses the Istio HTTP metrics to run the canary analysis you have to deploy the following
|
||||
Prometheus configuration that's similar to the one that comes with the official Istio Helm chart.
|
||||
|
||||
Create a virtual service in `istio-system` namespace for Grafana \(replace `example.com` with your domain\):
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/gke/istio-prometheus.yaml
|
||||
```
|
||||
|
||||
### Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the `istio-system` namespace with Slack notifications enabled:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Deploy Grafana in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=replace-me
|
||||
```
|
||||
|
||||
Expose Grafana through the public gateway by creating a virtual service \(replace `example.com` with your domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
@@ -433,8 +384,7 @@ spec:
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: grafana
|
||||
timeout: 30s
|
||||
host: flagger-grafana
|
||||
```
|
||||
|
||||
Save the above resource as grafana-virtual-service.yaml and then apply it:
|
||||
@@ -444,17 +394,3 @@ kubectl apply -f ./grafana-virtual-service.yaml
|
||||
```
|
||||
|
||||
Navigate to `http://grafana.example.com` in your browser and you should be redirected to the HTTPS version.
|
||||
|
||||
Check that HTTP2 is enabled:
|
||||
|
||||
```bash
|
||||
curl -I --http2 https://grafana.example.com
|
||||
|
||||
HTTP/2 200
|
||||
content-type: text/html; charset=UTF-8
|
||||
x-envoy-upstream-service-time: 3
|
||||
server: envoy
|
||||
```
|
||||
|
||||
|
||||
|
||||
145
docs/gitbook/install/flagger-install-on-kubernetes.md
Normal file
@@ -0,0 +1,145 @@
|
||||
# Flagger install on Kubernetes
|
||||
|
||||
This guide walks you through setting up Flagger on a Kubernetes cluster.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer with the following admission controllers enabled:
|
||||
|
||||
* MutatingAdmissionWebhook
|
||||
* ValidatingAdmissionWebhook
|
||||
|
||||
Flagger depends on [Istio](https://istio.io/docs/setup/kubernetes/quick-start/) **v1.0.3** or newer
|
||||
with traffic management, telemetry and Prometheus enabled.
|
||||
|
||||
A minimal Istio installation should contain the following services:
|
||||
|
||||
* istio-pilot
|
||||
* istio-ingressgateway
|
||||
* istio-sidecar-injector
|
||||
* istio-telemetry
|
||||
* prometheus
|
||||
|
||||
### Install Flagger
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
You can install Flagger in any namespace as long as it can talk to the Istio Prometheus service on port 9090.
|
||||
|
||||
Enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm fetch --untar --untardir . flagger/flagger &&
|
||||
helm template flagger \
|
||||
--name flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
> $HOME/flagger.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger.yaml
|
||||
```
|
||||
|
||||
To uninstall the Flagger release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
> **Note** that on uninstall the Canary CRD will not be removed.
|
||||
Deleting the CRD will make Kubernetes remove all the objects owned by Flagger like Istio virtual services,
|
||||
Kubernetes deployments and ClusterIP services.
|
||||
|
||||
If you want to remove all the objects created by Flagger you have delete the Canary CRD with kubectl:
|
||||
|
||||
```text
|
||||
kubectl delete crd canaries.flagger.app
|
||||
```
|
||||
|
||||
### Install Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=change-me
|
||||
```
|
||||
|
||||
Or use helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm fetch --untar --untardir . flagger/grafana &&
|
||||
helm template grafana \
|
||||
--name flagger-grafana \
|
||||
--namespace=istio-system \
|
||||
> $HOME/flagger-grafana.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-grafana.yaml
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
### Install Load Tester
|
||||
|
||||
Flagger comes with an optional load testing service that generates traffic
|
||||
during canary analysis when configured as a webhook.
|
||||
|
||||
Deploy the load test runner with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
Deploy with kubectl:
|
||||
|
||||
```bash
|
||||
helm fetch --untar --untardir . flagger/loadtester &&
|
||||
helm template loadtester \
|
||||
--name flagger-loadtester \
|
||||
--namespace=test
|
||||
> $HOME/flagger-loadtester.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-loadtester.yaml
|
||||
```
|
||||
|
||||
> **Note** that the load tester should be deployed in a namespace with Istio sidecar injection enabled.
|
||||
|
||||
135
docs/gitbook/install/flagger-install-with-supergloo.md
Normal file
@@ -0,0 +1,135 @@
|
||||
# Flagger install on Kubernetes with SuperGloo
|
||||
|
||||
This guide walks you through setting up Flagger on a Kubernetes cluster using [SuperGloo](https://github.com/solo-io/supergloo).
|
||||
|
||||
SuperGloo by [Solo.io](https://solo.io) is an opinionated abstraction layer that will simplify the installation, management, and operation of your service mesh.
|
||||
It supports running multiple ingress with multiple mesh (Istio, App Mesh, Consul Connect and Linkerd 2) in the same cluster.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer with the following admission controllers enabled:
|
||||
|
||||
* MutatingAdmissionWebhook
|
||||
* ValidatingAdmissionWebhook
|
||||
|
||||
### Install Istio with SuperGloo
|
||||
|
||||
Download SuperGloo CLI and add it to your path:
|
||||
|
||||
```bash
|
||||
curl -sL https://run.solo.io/supergloo/install | sh
|
||||
export PATH=$HOME/.supergloo/bin:$PATH
|
||||
```
|
||||
|
||||
Deploy the SuperGloo controller in the `supergloo-system` namespace:
|
||||
|
||||
```bash
|
||||
supergloo init
|
||||
```
|
||||
|
||||
Create the `istio-system` namespace and install Istio with traffic management, telemetry and Prometheus enabled:
|
||||
|
||||
```bash
|
||||
ISTIO_VER="1.0.6"
|
||||
|
||||
kubectl create ns istio-system
|
||||
|
||||
supergloo install istio --name istio \
|
||||
--namespace=supergloo-system \
|
||||
--auto-inject=true \
|
||||
--installation-namespace=istio-system \
|
||||
--mtls=false \
|
||||
--prometheus=true \
|
||||
--version ${ISTIO_VER}
|
||||
```
|
||||
|
||||
Create a cluster role binding so that Flagger can manipulate SuperGloo custom resources:
|
||||
|
||||
```bash
|
||||
kubectl create clusterrolebinding flagger-supergloo \
|
||||
--clusterrole=mesh-discovery \
|
||||
--serviceaccount=istio-system:flagger
|
||||
```
|
||||
|
||||
Wait for the Istio control plane to become available:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system rollout status deployment/istio-sidecar-injector
|
||||
kubectl -n istio-system rollout status deployment/prometheus
|
||||
```
|
||||
|
||||
### Install Flagger
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace and set the service mesh provider to SuperGloo:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set meshProvider=supergloo:istio.supergloo-system
|
||||
```
|
||||
|
||||
When using SuperGloo the mesh provider format is `supergloo:<MESH-NAME>.<SUPERGLOO-NAMESPACE>`.
|
||||
|
||||
Optionally you can enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
### Install Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
### Install Load Tester
|
||||
|
||||
Flagger comes with an optional load testing service that generates traffic
|
||||
during canary analysis when configured as a webhook.
|
||||
|
||||
Deploy the load test runner with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
Deploy with kubectl:
|
||||
|
||||
```bash
|
||||
helm fetch --untar --untardir . flagger/loadtester &&
|
||||
helm template loadtester \
|
||||
--name flagger-loadtester \
|
||||
--namespace=test
|
||||
> $HOME/flagger-loadtester.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-loadtester.yaml
|
||||
```
|
||||
|
||||
> **Note** that the load tester should be deployed in a namespace with Istio sidecar injection enabled.
|
||||
@@ -1,75 +0,0 @@
|
||||
# Install Flagger
|
||||
|
||||
Before installing Flagger make sure you have [Istio](https://istio.io) running with Prometheus enabled.
|
||||
If you are new to Istio you can follow this GKE guide
|
||||
[Istio service mesh walk-through](https://docs.flagger.app/install/install-istio).
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Kubernetes >= 1.11
|
||||
* Istio >= 1.0
|
||||
* Prometheus >= 2.6
|
||||
|
||||
### Install with Helm and Tiller
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
Enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
### Install with kubectl
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/flagger \
|
||||
--name flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set controlLoopInterval=1m > $HOME/flagger.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger.yaml
|
||||
```
|
||||
|
||||
### Uninstall
|
||||
|
||||
To uninstall/delete the flagger release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
> **Note** that on uninstall the Canary CRD will not be removed.
|
||||
Deleting the CRD will make Kubernetes remove all the objects owned by Flagger like Istio virtual services,
|
||||
Kubernetes deployments and ClusterIP services.
|
||||
|
||||
|
||||
If you want to remove all the objects created by Flagger you have delete the Canary CRD with kubectl:
|
||||
|
||||
```text
|
||||
kubectl delete crd canaries.flagger.app
|
||||
```
|
||||
|
||||
@@ -1,48 +0,0 @@
|
||||
# Install Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
### Install with Helm and Tiller
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus:9090 \
|
||||
--set user=admin \
|
||||
--set password=admin
|
||||
```
|
||||
|
||||
### Install with kubectl
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/grafana \
|
||||
--name flagger-grafana \
|
||||
--namespace=istio-system \
|
||||
--set user=admin \
|
||||
--set password=admin > $HOME/flagger-grafana.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-grafana.yaml
|
||||
```
|
||||
|
||||
### Uninstall
|
||||
|
||||
To uninstall/delete the Grafana release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger-grafana
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
353
docs/gitbook/tutorials/canary-helm-gitops.md
Normal file
@@ -0,0 +1,353 @@
|
||||
# Canary Deployments with Helm Charts and GitOps
|
||||
|
||||
This guide shows you how to package a web app into a Helm chart, trigger canary deployments on Helm upgrade
|
||||
and automate the chart release process with Weave Flux.
|
||||
|
||||
### Packaging
|
||||
|
||||
You'll be using the [podinfo](https://github.com/stefanprodan/k8s-podinfo) chart.
|
||||
This chart packages a web app made with Go, it's configuration, a horizontal pod autoscaler (HPA)
|
||||
and the canary configuration file.
|
||||
|
||||
```
|
||||
├── Chart.yaml
|
||||
├── README.md
|
||||
├── templates
|
||||
│ ├── NOTES.txt
|
||||
│ ├── _helpers.tpl
|
||||
│ ├── canary.yaml
|
||||
│ ├── configmap.yaml
|
||||
│ ├── deployment.yaml
|
||||
│ └── hpa.yaml
|
||||
└── values.yaml
|
||||
```
|
||||
|
||||
You can find the chart source [here](https://github.com/stefanprodan/flagger/tree/master/charts/podinfo).
|
||||
|
||||
### Install
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install podinfo with the release name `frontend` (replace `example.com` with your own domain):
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=frontend \
|
||||
--set backend=http://backend.test:9898/echo \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=true \
|
||||
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
||||
--set canary.istioIngress.host=frontend.istio.example.com
|
||||
```
|
||||
|
||||
Flagger takes a Kubernetes deployment and a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Istio virtual services).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
|
||||
```bash
|
||||
# generated by Helm
|
||||
configmap/frontend
|
||||
deployment.apps/frontend
|
||||
horizontalpodautoscaler.autoscaling/frontend
|
||||
canary.flagger.app/frontend
|
||||
|
||||
# generated by Flagger
|
||||
configmap/frontend-primary
|
||||
deployment.apps/frontend-primary
|
||||
horizontalpodautoscaler.autoscaling/frontend-primary
|
||||
service/frontend
|
||||
service/frontend-canary
|
||||
service/frontend-primary
|
||||
virtualservice.networking.istio.io/frontend
|
||||
```
|
||||
|
||||
When the `frontend-primary` deployment comes online,
|
||||
Flagger will route all traffic to the primary pods and scale to zero the `frontend` deployment.
|
||||
|
||||
Open your browser and navigate to the frontend URL:
|
||||
|
||||

|
||||
|
||||
Now let's install the `backend` release without exposing it outside the mesh:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=backend \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=false
|
||||
```
|
||||
|
||||
Check if Flagger has successfully deployed the canaries:
|
||||
|
||||
```
|
||||
kubectl -n test get canaries
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Initialized 0 2019-02-12T18:53:18Z
|
||||
frontend Initialized 0 2019-02-12T17:50:50Z
|
||||
```
|
||||
|
||||
Click on the ping button in the `frontend` UI to trigger a HTTP POST request
|
||||
that will reach the `backend` app:
|
||||
|
||||

|
||||
|
||||
We'll use the `/echo` endpoint (same as the one the ping button calls)
|
||||
to generate load on both apps during a canary deployment.
|
||||
|
||||
### Upgrade
|
||||
|
||||
First let's install a load testing service that will generate traffic during analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Enable the load tester and deploy a new `frontend` version:
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set image.tag=1.4.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the canary analysis along with the load test:
|
||||
|
||||
```
|
||||
kubectl -n istio-system logs deployment/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Scaling up frontend.test
|
||||
Halt advancement frontend.test waiting for rollout to finish: 0 of 2 updated replicas are available
|
||||
Starting canary analysis for frontend.test
|
||||
Advance frontend.test canary weight 5
|
||||
Advance frontend.test canary weight 10
|
||||
Advance frontend.test canary weight 15
|
||||
Advance frontend.test canary weight 20
|
||||
Advance frontend.test canary weight 25
|
||||
Advance frontend.test canary weight 30
|
||||
Advance frontend.test canary weight 35
|
||||
Advance frontend.test canary weight 40
|
||||
Advance frontend.test canary weight 45
|
||||
Advance frontend.test canary weight 50
|
||||
Copying frontend.test template spec to frontend-primary.test
|
||||
Halt advancement frontend-primary.test waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Promotion completed! Scaling down frontend.test
|
||||
```
|
||||
|
||||
You can monitor the canary deployment with Grafana. Open the Flagger dashboard,
|
||||
select `test` from the namespace dropdown, `frontend-primary` from the primary dropdown and `frontend` from the
|
||||
canary dropdown.
|
||||
|
||||
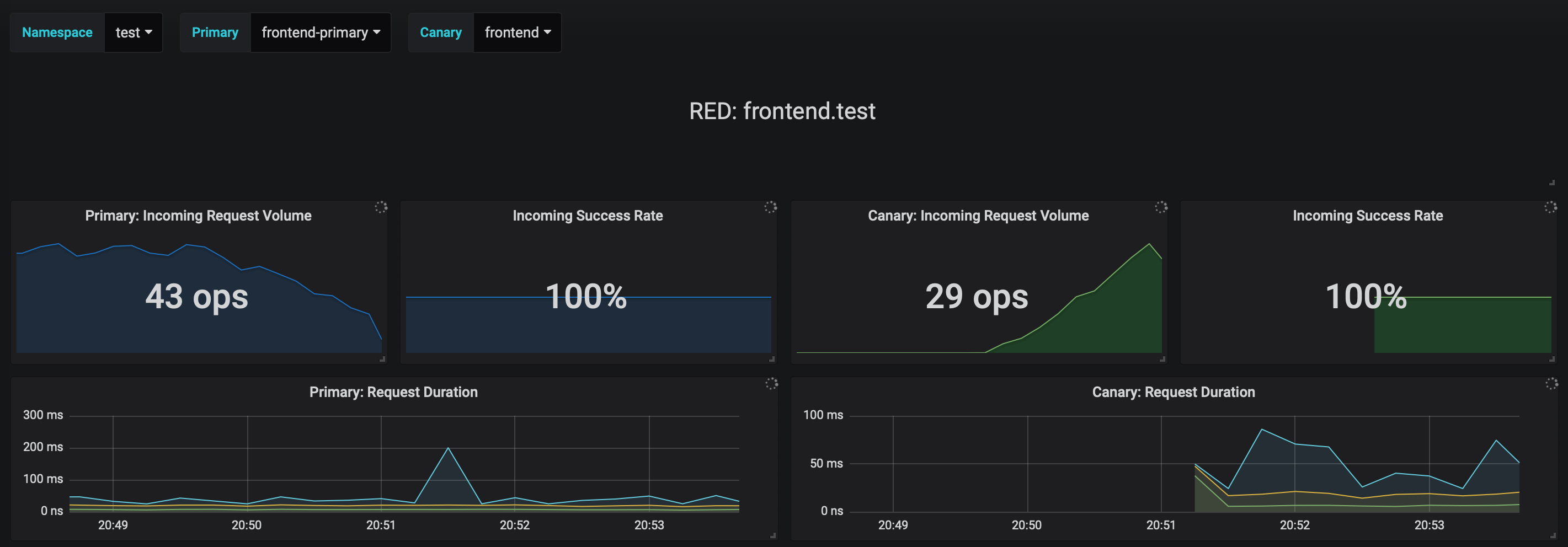
|
||||
|
||||
Now trigger a canary deployment for the `backend` app, but this time you'll change a value in the configmap:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set httpServer.timeout=25s
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/delay/1
|
||||
```
|
||||
|
||||
Flagger detects the config map change and starts a canary analysis. Flagger will pause the advancement
|
||||
when the HTTP success rate drops under 99% or when the average request duration in the last minute is over 500ms:
|
||||
|
||||
```
|
||||
kubectl -n test describe canary backend
|
||||
|
||||
Events:
|
||||
|
||||
ConfigMap backend has changed
|
||||
New revision detected! Scaling up backend.test
|
||||
Starting canary analysis for backend.test
|
||||
Advance backend.test canary weight 5
|
||||
Advance backend.test canary weight 10
|
||||
Advance backend.test canary weight 15
|
||||
Advance backend.test canary weight 20
|
||||
Advance backend.test canary weight 25
|
||||
Advance backend.test canary weight 30
|
||||
Advance backend.test canary weight 35
|
||||
Halt backend.test advancement success rate 62.50% < 99%
|
||||
Halt backend.test advancement success rate 88.24% < 99%
|
||||
Advance backend.test canary weight 40
|
||||
Advance backend.test canary weight 45
|
||||
Halt backend.test advancement request duration 2.415s > 500ms
|
||||
Halt backend.test advancement request duration 2.42s > 500ms
|
||||
Advance backend.test canary weight 50
|
||||
ConfigMap backend-primary synced
|
||||
Copying backend.test template spec to backend-primary.test
|
||||
Promotion completed! Scaling down backend.test
|
||||
```
|
||||
|
||||
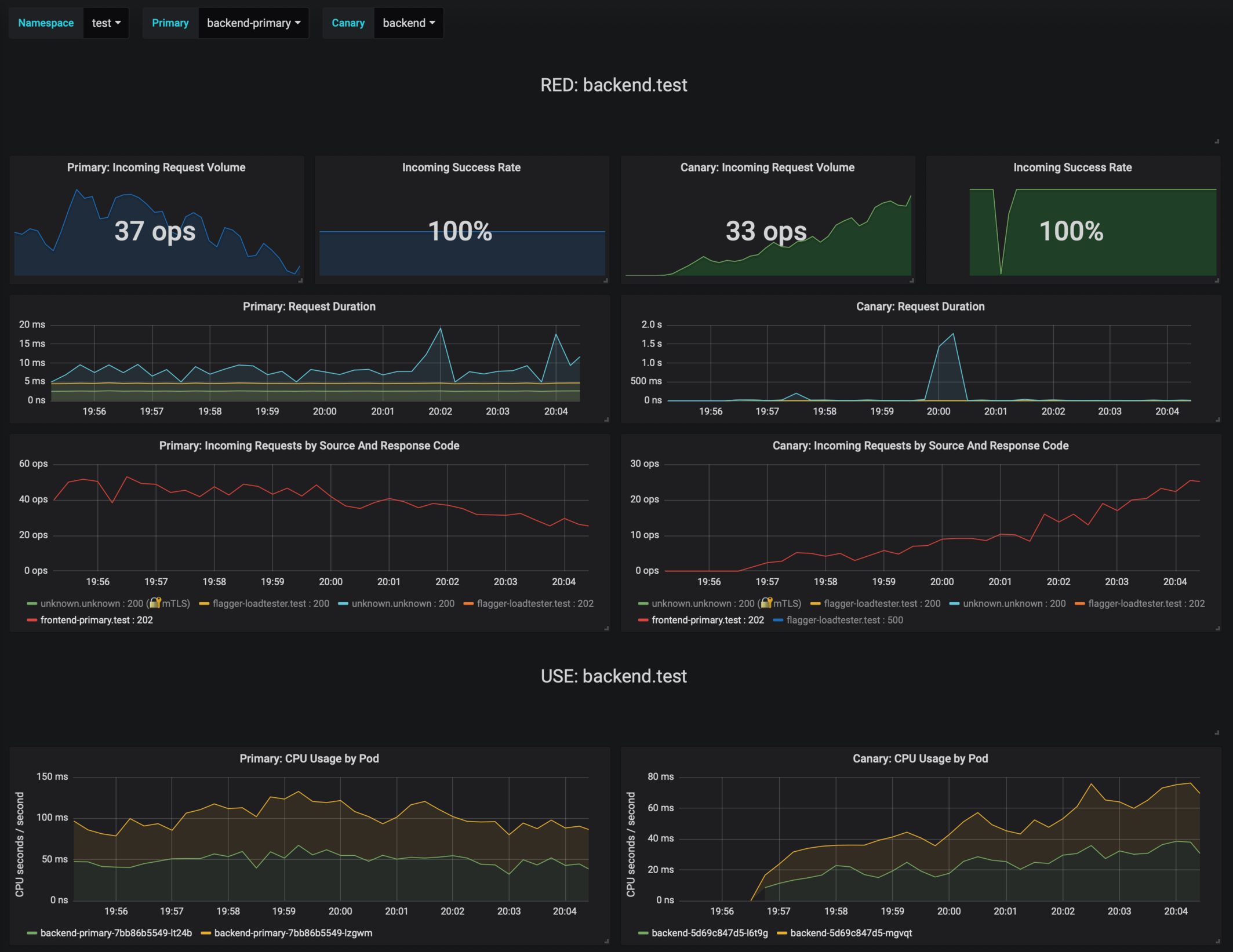
|
||||
|
||||
If the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```bash
|
||||
kubectl -n test get canary
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Succeeded 0 2019-02-12T19:33:11Z
|
||||
frontend Failed 0 2019-02-12T19:47:20Z
|
||||
```
|
||||
|
||||
If you've enabled the Slack notifications, you'll receive an alert with the reason why the `backend` promotion failed.
|
||||
|
||||
### GitOps automation
|
||||
|
||||
Instead of using Helm CLI from a CI tool to perform the install and upgrade,
|
||||
you could use a Git based approach. GitOps is a way to do Continuous Delivery,
|
||||
it works by using Git as a source of truth for declarative infrastructure and workloads.
|
||||
In the [GitOps model](https://www.weave.works/technologies/gitops/),
|
||||
any change to production must be committed in source control
|
||||
prior to being applied on the cluster. This way rollback and audit logs are provided by Git.
|
||||
|
||||
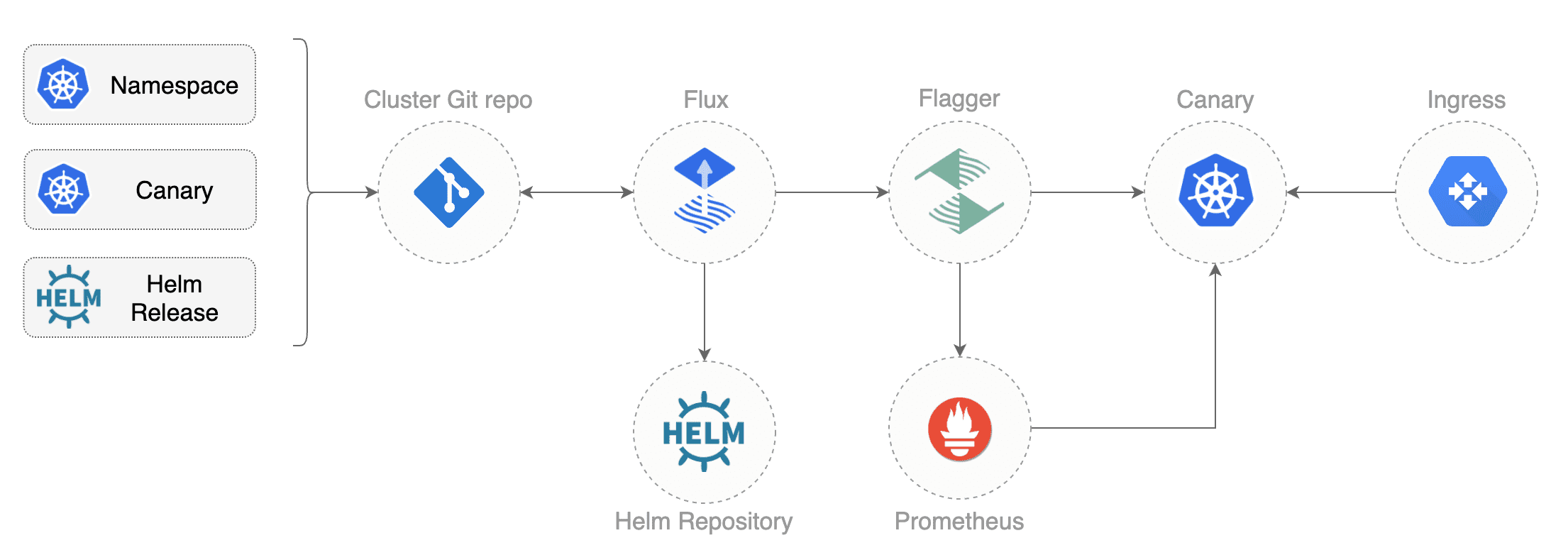
|
||||
|
||||
In order to apply the GitOps pipeline model to Flagger canary deployments you'll need
|
||||
a Git repository with your workloads definitions in YAML format,
|
||||
a container registry where your CI system pushes immutable images and
|
||||
an operator that synchronizes the Git repo with the cluster state.
|
||||
|
||||
Create a git repository with the following content:
|
||||
|
||||
```
|
||||
├── namespaces
|
||||
│ └── test.yaml
|
||||
└── releases
|
||||
└── test
|
||||
├── backend.yaml
|
||||
├── frontend.yaml
|
||||
└── loadtester.yaml
|
||||
```
|
||||
|
||||
You can find the git source [here](https://github.com/stefanprodan/flagger/tree/master/artifacts/cluster).
|
||||
|
||||
Define the `frontend` release using Flux `HelmRelease` custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: semver:~1.4
|
||||
spec:
|
||||
releaseName: frontend
|
||||
chart:
|
||||
repository: https://stefanprodan.github.io/flagger/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
backend: http://backend-podinfo:9898/echo
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: true
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
host: frontend.istio.example.com
|
||||
loadtest:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
In the `chart` section I've defined the release source by specifying the Helm repository (hosted on GitHub Pages), chart name and version.
|
||||
In the `values` section I've overwritten the defaults set in values.yaml.
|
||||
|
||||
With the `flux.weave.works` annotations I instruct Flux to automate this release.
|
||||
When an image tag in the sem ver range of `1.4.0 - 1.4.99` is pushed to Quay,
|
||||
Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
||||
|
||||
Install [Weave Flux](https://github.com/weaveworks/flux) and its Helm Operator by specifying your Git repo URL:
|
||||
|
||||
```bash
|
||||
helm repo add weaveworks https://weaveworks.github.io/flux
|
||||
|
||||
helm install --name flux \
|
||||
--set helmOperator.create=true \
|
||||
--set git.url=git@github.com:<USERNAME>/<REPOSITORY> \
|
||||
--namespace flux \
|
||||
weaveworks/flux
|
||||
```
|
||||
|
||||
At startup Flux generates a SSH key and logs the public key. Find the SSH public key with:
|
||||
|
||||
```bash
|
||||
kubectl -n flux logs deployment/flux | grep identity.pub | cut -d '"' -f2
|
||||
```
|
||||
|
||||
In order to sync your cluster state with Git you need to copy the public key and create a
|
||||
deploy key with write access on your GitHub repository.
|
||||
|
||||
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_,
|
||||
check _Allow write access_, paste the Flux public key and click _Add key_.
|
||||
|
||||
After a couple of seconds Flux will apply the Kubernetes resources from Git and Flagger will
|
||||
launch the `frontend` and `backend` apps.
|
||||
|
||||
A CI/CD pipeline for the `frontend` release could look like this:
|
||||
|
||||
* cut a release from the master branch of the podinfo code repo with the git tag `1.4.1`
|
||||
* CI builds the image and pushes the `podinfo:1.4.1` image to the container registry
|
||||
* Flux scans the registry and updates the Helm release `image.tag` to `1.4.1`
|
||||
* Flux commits and push the change to the cluster repo
|
||||
* Flux applies the updated Helm release on the cluster
|
||||
* Flux Helm Operator picks up the change and calls Tiller to upgrade the release
|
||||
* Flagger detects a revision change and scales up the `frontend` deployment
|
||||
* Flagger starts the load test and runs the canary analysis
|
||||
* Based on the analysis result the canary deployment is promoted to production or rolled back
|
||||
* Flagger sends a Slack notification with the canary result
|
||||
|
||||
If the canary fails, fix the bug, do another patch release eg `1.4.2` and the whole process will run again.
|
||||
|
||||
A canary deployment can fail due to any of the following reasons:
|
||||
|
||||
* the container image can't be downloaded
|
||||
* the deployment replica set is stuck for more then ten minutes (eg. due to a container crash loop)
|
||||
* the webooks (acceptance tests, load tests, etc) are returning a non 2xx response
|
||||
* the HTTP success rate (non 5xx responses) metric drops under the threshold
|
||||
* the HTTP average duration metric goes over the threshold
|
||||
* the Istio telemetry service is unable to collect traffic metrics
|
||||
* the metrics server (Prometheus) can't be reached
|
||||
|
||||
If you want to find out more about managing Helm releases with Flux here is an in-depth guide
|
||||
[github.com/stefanprodan/gitops-helm](https://github.com/stefanprodan/gitops-helm).
|
||||
206
docs/gitbook/tutorials/zero-downtime-deployments.md
Normal file
@@ -0,0 +1,206 @@
|
||||
# Zero downtime deployments
|
||||
|
||||
This is a list of things you should consider when dealing with a high traffic production environment if you want to
|
||||
minimise the impact of rolling updates and downscaling.
|
||||
|
||||
### Deployment strategy
|
||||
|
||||
Limit the number of unavailable pods during a rolling update:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
progressDeadlineSeconds: 120
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
```
|
||||
|
||||
The default progress deadline for a deployment is ten minutes.
|
||||
You should consider adjusting this value to make the deployment process fail faster.
|
||||
|
||||
### Liveness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if
|
||||
your app transitioned to a broken state from which it can't recover and needs to be restarted.
|
||||
|
||||
```yaml
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
```
|
||||
|
||||
If you've enabled mTLS, you'll have to use `exec` for liveness and readiness checks since
|
||||
kubelet is not part of the service mesh and doesn't have access to the TLS cert.
|
||||
|
||||
### Readiness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if
|
||||
your app is ready to receive traffic.
|
||||
|
||||
```yaml
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/readyz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
periodSeconds: 5
|
||||
```
|
||||
|
||||
If your app depends on external services, you should check if those services are available before allowing Kubernetes
|
||||
to route traffic to an app instance. Keep in mind that the Envoy sidecar can have a slower startup than your app.
|
||||
This means that on application start you should retry for at least a couple of seconds any external connection.
|
||||
|
||||
### Graceful shutdown
|
||||
|
||||
Before a pod gets terminated, Kubernetes sends a `SIGTERM` signal to every container and waits for period of
|
||||
time (30s by default) for all containers to exit gracefully. If your app doesn't handle the `SIGTERM` signal or if it
|
||||
doesn't exit within the grace period, Kubernetes will kill the container and any inflight requests that your app is
|
||||
processing will fail.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 60
|
||||
containers:
|
||||
- name: app
|
||||
lifecycle:
|
||||
preStop:
|
||||
exec:
|
||||
command:
|
||||
- sleep
|
||||
- "10"
|
||||
```
|
||||
|
||||
Your app container should have a `preStop` hook that delays the container shutdown.
|
||||
This will allow the service mesh to drain the traffic and remove this pod from all other Envoy sidecars before your app
|
||||
becomes unavailable.
|
||||
|
||||
### Delay Envoy shutdown
|
||||
|
||||
Even if your app reacts to `SIGTERM` and tries to complete the inflight requests before shutdown, that
|
||||
doesn't mean that the response will make it back to the caller. If the Envoy sidecar shuts down before your app, then
|
||||
the caller will receive a 503 error.
|
||||
|
||||
To mitigate this issue you can add a `preStop` hook to the Istio proxy and wait for the main app to exist before Envoy exists.
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
set -e
|
||||
if ! pidof envoy &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
if ! pidof pilot-agent &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do
|
||||
sleep 1;
|
||||
done
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
You'll have to build your own Envoy docker image with the above script and
|
||||
modify the Istio injection webhook with the `preStop` directive.
|
||||
|
||||
Thanks to Stono for his excellent [tips](https://github.com/istio/istio/issues/12183) on minimising 503s.
|
||||
|
||||
### Resource requests and limits
|
||||
|
||||
Setting CPU and memory requests/limits for all workloads is a mandatory step if you're running a production system.
|
||||
Without limits your nodes could run out of memory or become unresponsive due to CPU exhausting.
|
||||
Without CPU and memory requests,
|
||||
the Kubernetes scheduler will not be able to make decisions about which nodes to place pods on.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: app
|
||||
resources:
|
||||
limits:
|
||||
cpu: 1000m
|
||||
memory: 1Gi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 128Mi
|
||||
```
|
||||
|
||||
Note that without resource requests the horizontal pod autoscaler can't determine when to scale your app.
|
||||
|
||||
### Autoscaling
|
||||
|
||||
A production environment should be able to handle traffic bursts without impacting the quality of service.
|
||||
This can be achieved with Kubernetes autoscaling capabilities.
|
||||
Autoscaling in Kubernetes has two dimensions: the Cluster Autoscaler that deals with node scaling operations and
|
||||
the Horizontal Pod Autoscaler that automatically scales the number of pods in a deployment.
|
||||
|
||||
```yaml
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: app
|
||||
minReplicas: 2
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageValue: 900m
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageValue: 768Mi
|
||||
```
|
||||
|
||||
The above HPA ensures your app will be scaled up before the pods reach the CPU or memory limits.
|
||||
|
||||
### Ingress retries
|
||||
|
||||
To minimise the impact of downscaling operations you can make use of Envoy retry capabilities.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
hosts:
|
||||
- app.example.com
|
||||
appendHeaders:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
```
|
||||
|
||||
When the HPA scales down your app, your users could run into 503 errors.
|
||||
The above configuration will make Envoy retry the HTTP requests that failed due to gateway errors.
|
||||
214
docs/gitbook/usage/ab-testing.md
Normal file
@@ -0,0 +1,214 @@
|
||||
# Istio A/B Testing
|
||||
|
||||
This guide shows you how to automate A/B testing with Istio and Flagger.
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
|
||||
|
||||
### Bootstrap
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/ab-testing/deployment.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/ab-testing/hpa.yaml
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace example.com with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: abtest
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: abtest
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: abtest
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.example.com
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
# canary match condition
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: "^(?!.*Chrome).*Safari.*"
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(type=insider)(;.*)?$"
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# generate traffic during analysis
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: type=insider' http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting Safari users and those that have an insider cookie.
|
||||
|
||||
Save the above resource as podinfo-abtest.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-abtest.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/abtest
|
||||
horizontalpodautoscaler.autoscaling/abtest
|
||||
canary.flagger.app/abtest
|
||||
|
||||
# generated
|
||||
deployment.apps/abtest-primary
|
||||
horizontalpodautoscaler.autoscaling/abtest-primary
|
||||
service/abtest
|
||||
service/abtest-canary
|
||||
service/abtest-primary
|
||||
virtualservice.networking.istio.io/abtest
|
||||
```
|
||||
|
||||
### Automated canary promotion
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/abtest \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.4.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/abtest
|
||||
|
||||
Status:
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected abtest.test
|
||||
Normal Synced 3m flagger Scaling up abtest.test
|
||||
Warning Synced 3m flagger Waiting for abtest.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 3/10
|
||||
Normal Synced 2m flagger Advance abtest.test canary iteration 4/10
|
||||
Normal Synced 2m flagger Advance abtest.test canary iteration 5/10
|
||||
Normal Synced 1m flagger Advance abtest.test canary iteration 6/10
|
||||
Normal Synced 1m flagger Advance abtest.test canary iteration 7/10
|
||||
Normal Synced 55s flagger Advance abtest.test canary iteration 8/10
|
||||
Normal Synced 45s flagger Advance abtest.test canary iteration 9/10
|
||||
Normal Synced 35s flagger Advance abtest.test canary iteration 10/10
|
||||
Normal Synced 25s flagger Copying abtest.test template spec to abtest-primary.test
|
||||
Warning Synced 15s flagger Waiting for abtest-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down abtest.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test abtest Progressing 100 2019-03-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-03-15T16:15:07Z
|
||||
prod backend Failed 0 2019-03-14T17:05:07Z
|
||||
```
|
||||
|
||||
### Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test Flagger's rollback.
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl -b 'type=insider' http://app.example.com/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl -b 'type=insider' http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/abtest
|
||||
|
||||
Status:
|
||||
Failed Checks: 2
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for abtest.test
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance abtest.test canary iteration 3/10
|
||||
Normal Synced 3m flagger Halt abtest.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt abtest.test advancement success rate 61.39% < 99%
|
||||
Warning Synced 2m flagger Rolling back abtest.test failed checks threshold reached 2
|
||||
Warning Synced 1m flagger Canary failed! Scaling down abtest.test
|
||||
```
|
||||
@@ -15,12 +15,12 @@ helm upgrade -i flagger flagger/flagger \
|
||||
Once configured with a Slack incoming **webhook**, Flagger will post messages when a canary deployment
|
||||
has been initialised, when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||

|
||||

|
||||
|
||||
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis reached the
|
||||
maximum number of failed checks:
|
||||
|
||||

|
||||

|
||||
|
||||
### Prometheus Alert Manager
|
||||
|
||||
|
||||
286
docs/gitbook/usage/appmesh-progressive-delivery.md
Normal file
@@ -0,0 +1,286 @@
|
||||
# App Mesh Canary Deployments
|
||||
|
||||
This guide shows you how to use App Mesh and Flagger to automate canary deployments.
|
||||
You'll need an EKS cluster configured with App Mesh, you can find the install guide
|
||||
[here](https://docs.flagger.app/install/flagger-install-on-eks-appmesh).
|
||||
|
||||
### Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services, App Mesh virtual nodes and services).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
The only App Mesh object you need to create by yourself is the mesh resource.
|
||||
|
||||
Create a mesh called `global`:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/appmesh/global-mesh.yaml
|
||||
```
|
||||
|
||||
Create a test namespace with App Mesh sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/appmesh/deployment.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/appmesh/hpa.yaml
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set meshName=global.appmesh-system \
|
||||
--set "backends[0]=podinfo.test"
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# App Mesh reference
|
||||
meshName: global.appmesh-system
|
||||
# App Mesh egress (optional)
|
||||
backends:
|
||||
- backend.test
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# App Mesh Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated Kubernetes objects
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
|
||||
# generated App Mesh objects
|
||||
virtualnode.appmesh.k8s.aws/podinfo
|
||||
virtualnode.appmesh.k8s.aws/podinfo-canary
|
||||
virtualnode.appmesh.k8s.aws/podinfo-primary
|
||||
virtualservice.appmesh.k8s.aws/podinfo.test
|
||||
```
|
||||
|
||||
The App Mesh specific settings are:
|
||||
|
||||
```yaml
|
||||
service:
|
||||
port: 9898
|
||||
meshName: global.appmesh-system
|
||||
backends:
|
||||
- backend1.test
|
||||
- backend2.test
|
||||
```
|
||||
|
||||
App Mesh blocks all egress traffic by default. If your application needs to call another service, you have to create an
|
||||
App Mesh virtual service for it and add the virtual service name to the backend list.
|
||||
|
||||
### Setup App Mesh ingress (optional)
|
||||
|
||||
In order to expose the podinfo app outside the mesh you'll be using an Envoy ingress and an AWS classic load balancer.
|
||||
The ingress binds to an internet domain and forwards the calls into the mesh through the App Mesh sidecar.
|
||||
If podinfo becomes unavailable due to a HPA downscaling or a node restart,
|
||||
the ingress will retry the calls for a short period of time.
|
||||
|
||||
Deploy the ingress and the AWS ELB service:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/appmesh/ingress.yaml
|
||||
```
|
||||
|
||||
Find the ingress public address:
|
||||
|
||||
```bash
|
||||
kubectl -n test describe svc/ingress | grep Ingress
|
||||
|
||||
LoadBalancer Ingress: yyy-xx.us-west-2.elb.amazonaws.com
|
||||
```
|
||||
|
||||
Wait for the ELB to become active:
|
||||
|
||||
```bash
|
||||
watch curl -sS ${INGRESS_URL}
|
||||
```
|
||||
|
||||
Open your browser and navigate to the ingress address to access podinfo UI.
|
||||
|
||||
### Automated canary promotion
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.4.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
During the analysis the canary’s progress can be monitored with Grafana. The App Mesh dashboard URL is
|
||||
http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo
|
||||
|
||||

|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-03-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-03-15T16:15:07Z
|
||||
prod backend Failed 0 2019-03-14T17:05:07Z
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||
|
||||
### Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger a canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.4.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
hey -z 1m -c 5 -q 5 http://podinfo.test:9898/status/500
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||
@@ -6,15 +6,13 @@ Flagger comes with a Grafana dashboard made for canary analysis. Install Grafana
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus:9090 \
|
||||
--set user=admin \
|
||||
--set password=admin
|
||||
--namespace=istio-system \ # or appmesh-system
|
||||
--set url=http://prometheus:9090
|
||||
```
|
||||
|
||||
The dashboard shows the RED and USE metrics for the primary and canary workloads:
|
||||
|
||||

|
||||

|
||||
|
||||
### Logging
|
||||
|
||||
@@ -48,6 +46,9 @@ Flagger exposes Prometheus metrics that can be used to determine the canary anal
|
||||
the destination weight values:
|
||||
|
||||
```bash
|
||||
# Flagger version and mesh provider gauge
|
||||
flagger_info{version="0.10.0", mesh_provider="istio"} 1
|
||||
|
||||
# Canaries total gauge
|
||||
flagger_canary_total{namespace="test"} 1
|
||||
|
||||
|
||||