Compare commits
175 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fcd520787d | ||
|
|
e2417e4e40 | ||
|
|
70a2cbf1c6 | ||
|
|
fa0c6af6aa | ||
|
|
4f1abd0c8d | ||
|
|
41e839aa36 | ||
|
|
2fd1593ad2 | ||
|
|
27b601c5aa | ||
|
|
5fc69134e3 | ||
|
|
9adc0698bb | ||
|
|
119c2ff464 | ||
|
|
f3a4201c7d | ||
|
|
8b6aa73df0 | ||
|
|
1d4dfb0883 | ||
|
|
eab7f126a6 | ||
|
|
fe7547d83e | ||
|
|
7d0df82861 | ||
|
|
7f0cd27591 | ||
|
|
e094c2ae14 | ||
|
|
a5d438257f | ||
|
|
d8cb8f1064 | ||
|
|
a8d8bb2d6f | ||
|
|
a76ea5917c | ||
|
|
b0b6198ec8 | ||
|
|
eda97f35d2 | ||
|
|
2b6507d35a | ||
|
|
f7c4d5aa0b | ||
|
|
74f07cffa6 | ||
|
|
79c8ff0af8 | ||
|
|
ac544eea4b | ||
|
|
231a32331b | ||
|
|
104e8ef050 | ||
|
|
296015faff | ||
|
|
9a9964c968 | ||
|
|
0d05d86e32 | ||
|
|
9680ca98f2 | ||
|
|
42b850ca52 | ||
|
|
3f5c22d863 | ||
|
|
535a92e871 | ||
|
|
3411a6a981 | ||
|
|
b5adee271c | ||
|
|
e2abcd1323 | ||
|
|
25fbe7ecb6 | ||
|
|
6befee79c2 | ||
|
|
f09c5a60f1 | ||
|
|
52e89ff509 | ||
|
|
35e20406ef | ||
|
|
c6e96ff1bb | ||
|
|
793ab524b0 | ||
|
|
5a479d0187 | ||
|
|
a23e4f1d2a | ||
|
|
bd35a3f61c | ||
|
|
197e987d5f | ||
|
|
7f29beb639 | ||
|
|
1140af8dc7 | ||
|
|
a2688c3910 | ||
|
|
75b27ab3f3 | ||
|
|
59d3f55fb2 | ||
|
|
f34739f334 | ||
|
|
90c71ec18f | ||
|
|
395234d7c8 | ||
|
|
e322ba0065 | ||
|
|
6db8b96f72 | ||
|
|
44d7e96e96 | ||
|
|
1662479c8d | ||
|
|
2e351fcf0d | ||
|
|
5d81876d07 | ||
|
|
c81e6989ec | ||
|
|
4d61a896c3 | ||
|
|
d148933ab3 | ||
|
|
04a56a3591 | ||
|
|
4a354e74d4 | ||
|
|
1e3e6427d5 | ||
|
|
38826108c8 | ||
|
|
4c4752f907 | ||
|
|
94dcd6c94d | ||
|
|
eabef3db30 | ||
|
|
6750f10ffa | ||
|
|
56cb888cbf | ||
|
|
b3e7fb3417 | ||
|
|
2c6e1baca2 | ||
|
|
c8358929d1 | ||
|
|
1dc7677dfb | ||
|
|
8e699a7543 | ||
|
|
cbbabdfac0 | ||
|
|
9d92de234c | ||
|
|
ba65975fb5 | ||
|
|
ef423b2078 | ||
|
|
f451b4e36c | ||
|
|
0856e13ee6 | ||
|
|
87b9fa8ca7 | ||
|
|
5b43d3d314 | ||
|
|
ac4972dd8d | ||
|
|
8a8f68af5d | ||
|
|
c669dc0c4b | ||
|
|
863a5466cc | ||
|
|
e2347c84e3 | ||
|
|
e0e673f565 | ||
|
|
30cbf2a741 | ||
|
|
f58de3801c | ||
|
|
7c6b88d4c1 | ||
|
|
0c0ebaecd5 | ||
|
|
1925f99118 | ||
|
|
6f2a22a1cc | ||
|
|
ee04082cd7 | ||
|
|
efd901ac3a | ||
|
|
e565789ae8 | ||
|
|
d3953004f6 | ||
|
|
df1d9e3011 | ||
|
|
631c55fa6e | ||
|
|
29cdd43288 | ||
|
|
9b79af9fcd | ||
|
|
2c9c1adb47 | ||
|
|
5dfb5808c4 | ||
|
|
bb0175aebf | ||
|
|
adaf4c99c0 | ||
|
|
bed6ed09d5 | ||
|
|
4ff67a85ce | ||
|
|
702f4fcd14 | ||
|
|
8a03ae153d | ||
|
|
434c6149ab | ||
|
|
97fc4a90ae | ||
|
|
217ef06930 | ||
|
|
71057946e6 | ||
|
|
a74ad52c72 | ||
|
|
12d26874f8 | ||
|
|
27de9ce151 | ||
|
|
9e7cd5a8c5 | ||
|
|
38cb487b64 | ||
|
|
05ca266c5e | ||
|
|
5cc26de645 | ||
|
|
2b9a195fa3 | ||
|
|
4454749eec | ||
|
|
b435a03fab | ||
|
|
7c166e2b40 | ||
|
|
f7a7963dcf | ||
|
|
9c77c0d69c | ||
|
|
e8a9555346 | ||
|
|
59751dd007 | ||
|
|
9c4d4d16b6 | ||
|
|
0e3d1b3e8f | ||
|
|
f119b78940 | ||
|
|
456d914c35 | ||
|
|
737507b0fe | ||
|
|
4bcf82d295 | ||
|
|
e9cd7afc8a | ||
|
|
0830abd51d | ||
|
|
5b296e01b3 | ||
|
|
3fd039afd1 | ||
|
|
5904348ba5 | ||
|
|
1a98e93723 | ||
|
|
c9685fbd13 | ||
|
|
dc347e273d | ||
|
|
8170916897 | ||
|
|
71cd4e0cb7 | ||
|
|
0109788ccc | ||
|
|
1649dea468 | ||
|
|
b8a7ea8534 | ||
|
|
afe4d59d5a | ||
|
|
0f2697df23 | ||
|
|
05664fa648 | ||
|
|
3b2564f34b | ||
|
|
dd0cf2d588 | ||
|
|
7c66f23c6a | ||
|
|
a9f034de1a | ||
|
|
6ad2dca57a | ||
|
|
e8353c110b | ||
|
|
dbf26ddf53 | ||
|
|
acc72d207f | ||
|
|
a784f83464 | ||
|
|
07d8355363 | ||
|
|
f7a439274e | ||
|
|
bd6d446cb8 | ||
|
|
385d0e0549 | ||
|
|
02236374d8 |
22
.circleci/config.yml
Normal file
@@ -0,0 +1,22 @@
|
||||
version: 2.1
|
||||
jobs:
|
||||
e2e-testing:
|
||||
machine: true
|
||||
steps:
|
||||
- checkout
|
||||
- run: test/e2e-kind.sh
|
||||
- run: test/e2e-istio.sh
|
||||
- run: test/e2e-build.sh
|
||||
- run: test/e2e-tests.sh
|
||||
|
||||
workflows:
|
||||
version: 2
|
||||
build-and-test:
|
||||
jobs:
|
||||
- e2e-testing:
|
||||
filters:
|
||||
branches:
|
||||
ignore:
|
||||
- gh-pages
|
||||
- /docs-.*/
|
||||
- /release-.*/
|
||||
@@ -6,3 +6,6 @@ coverage:
|
||||
threshold: 50
|
||||
base: auto
|
||||
patch: off
|
||||
|
||||
comment:
|
||||
require_changes: yes
|
||||
17
.github/main.workflow
vendored
Normal file
@@ -0,0 +1,17 @@
|
||||
workflow "Publish Helm charts" {
|
||||
on = "push"
|
||||
resolves = ["helm-push"]
|
||||
}
|
||||
|
||||
action "helm-lint" {
|
||||
uses = "stefanprodan/gh-actions/helm@master"
|
||||
args = ["lint charts/*"]
|
||||
}
|
||||
|
||||
action "helm-push" {
|
||||
needs = ["helm-lint"]
|
||||
uses = "stefanprodan/gh-actions/helm-gh-pages@master"
|
||||
args = ["charts/*","https://flagger.app"]
|
||||
secrets = ["GITHUB_TOKEN"]
|
||||
}
|
||||
|
||||
4
.gitignore
vendored
@@ -11,3 +11,7 @@
|
||||
# Output of the go coverage tool, specifically when used with LiteIDE
|
||||
*.out
|
||||
.DS_Store
|
||||
|
||||
bin/
|
||||
artifacts/gcloud/
|
||||
.idea
|
||||
20
.travis.yml
@@ -12,20 +12,26 @@ addons:
|
||||
packages:
|
||||
- docker-ce
|
||||
|
||||
#before_script:
|
||||
# - go get -u sigs.k8s.io/kind
|
||||
# - curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bash
|
||||
# - curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl && chmod +x kubectl && sudo mv kubectl /usr/local/bin/
|
||||
|
||||
script:
|
||||
- set -e
|
||||
- make test-fmt
|
||||
- make test-codegen
|
||||
- go test -race -coverprofile=coverage.txt -covermode=atomic ./pkg/controller/
|
||||
- make build
|
||||
- set -e
|
||||
- make test-fmt
|
||||
- make test-codegen
|
||||
- go test -race -coverprofile=coverage.txt -covermode=atomic $(go list ./pkg/...)
|
||||
- make build
|
||||
|
||||
after_success:
|
||||
- if [ -z "$DOCKER_USER" ]; then
|
||||
echo "PR build, skipping image push";
|
||||
else
|
||||
docker tag stefanprodan/flagger:latest quay.io/stefanprodan/flagger:${TRAVIS_COMMIT};
|
||||
BRANCH_COMMIT=${TRAVIS_BRANCH}-$(echo ${TRAVIS_COMMIT} | head -c7);
|
||||
docker tag stefanprodan/flagger:latest quay.io/stefanprodan/flagger:${BRANCH_COMMIT};
|
||||
echo $DOCKER_PASS | docker login -u=$DOCKER_USER --password-stdin quay.io;
|
||||
docker push quay.io/stefanprodan/flagger:${TRAVIS_COMMIT};
|
||||
docker push quay.io/stefanprodan/flagger:${BRANCH_COMMIT};
|
||||
fi
|
||||
- if [ -z "$TRAVIS_TAG" ]; then
|
||||
echo "Not a release, skipping image push";
|
||||
|
||||
180
CHANGELOG.md
Normal file
@@ -0,0 +1,180 @@
|
||||
# Changelog
|
||||
|
||||
All notable changes to this project are documented in this file.
|
||||
|
||||
## 0.8.0 (2019-03-06)
|
||||
|
||||
Adds support for CORS policy and HTTP request headers manipulation
|
||||
|
||||
#### Features
|
||||
|
||||
- CORS policy support [#83](https://github.com/stefanprodan/flagger/pull/83)
|
||||
- Allow headers to be appended to HTTP requests [#82](https://github.com/stefanprodan/flagger/pull/82)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Refactor the routing management
|
||||
[#72](https://github.com/stefanprodan/flagger/pull/72)
|
||||
[#80](https://github.com/stefanprodan/flagger/pull/80)
|
||||
- Fine-grained RBAC [#73](https://github.com/stefanprodan/flagger/pull/73)
|
||||
- Add option to limit Flagger to a single namespace [#78](https://github.com/stefanprodan/flagger/pull/78)
|
||||
|
||||
## 0.7.0 (2019-02-28)
|
||||
|
||||
Adds support for custom metric checks, HTTP timeouts and HTTP retries
|
||||
|
||||
#### Features
|
||||
|
||||
- Allow custom promql queries in the canary analysis spec [#60](https://github.com/stefanprodan/flagger/pull/60)
|
||||
- Add HTTP timeout and retries to canary service spec [#62](https://github.com/stefanprodan/flagger/pull/62)
|
||||
|
||||
## 0.6.0 (2019-02-25)
|
||||
|
||||
Allows for [HTTPMatchRequests](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#HTTPMatchRequest)
|
||||
and [HTTPRewrite](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#HTTPRewrite)
|
||||
to be customized in the service spec of the canary custom resource.
|
||||
|
||||
#### Features
|
||||
|
||||
- Add HTTP match conditions and URI rewrite to the canary service spec [#55](https://github.com/stefanprodan/flagger/pull/55)
|
||||
- Update virtual service when the canary service spec changes
|
||||
[#54](https://github.com/stefanprodan/flagger/pull/54)
|
||||
[#51](https://github.com/stefanprodan/flagger/pull/51)
|
||||
|
||||
#### Improvements
|
||||
|
||||
- Run e2e testing on [Kubernetes Kind](https://github.com/kubernetes-sigs/kind) for canary promotion
|
||||
[#53](https://github.com/stefanprodan/flagger/pull/53)
|
||||
|
||||
## 0.5.1 (2019-02-14)
|
||||
|
||||
Allows skipping the analysis phase to ship changes directly to production
|
||||
|
||||
#### Features
|
||||
|
||||
- Add option to skip the canary analysis [#46](https://github.com/stefanprodan/flagger/pull/46)
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Reject deployment if the pod label selector doesn't match `app: <DEPLOYMENT_NAME>` [#43](https://github.com/stefanprodan/flagger/pull/43)
|
||||
|
||||
## 0.5.0 (2019-01-30)
|
||||
|
||||
Track changes in ConfigMaps and Secrets [#37](https://github.com/stefanprodan/flagger/pull/37)
|
||||
|
||||
#### Features
|
||||
|
||||
- Promote configmaps and secrets changes from canary to primary
|
||||
- Detect changes in configmaps and/or secrets and (re)start canary analysis
|
||||
- Add configs checksum to Canary CRD status
|
||||
- Create primary configmaps and secrets at bootstrap
|
||||
- Scan canary volumes and containers for configmaps and secrets
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Copy deployment labels from canary to primary at bootstrap and promotion
|
||||
|
||||
## 0.4.1 (2019-01-24)
|
||||
|
||||
Load testing webhook [#35](https://github.com/stefanprodan/flagger/pull/35)
|
||||
|
||||
#### Features
|
||||
|
||||
- Add the load tester chart to Flagger Helm repository
|
||||
- Implement a load test runner based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
- Log warning when no values are found for Istio metric due to lack of traffic
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Run wekbooks before the metrics checks to avoid failures when using a load tester
|
||||
|
||||
## 0.4.0 (2019-01-18)
|
||||
|
||||
Restart canary analysis if revision changes [#31](https://github.com/stefanprodan/flagger/pull/31)
|
||||
|
||||
#### Breaking changes
|
||||
|
||||
- Drop support for Kubernetes 1.10
|
||||
|
||||
#### Features
|
||||
|
||||
- Detect changes during canary analysis and reset advancement
|
||||
- Add status and additional printer columns to CRD
|
||||
- Add canary name and namespace to controller structured logs
|
||||
|
||||
#### Fixes
|
||||
|
||||
- Allow canary name to be different to the target name
|
||||
- Check if multiple canaries have the same target and log error
|
||||
- Use deep copy when updating Kubernetes objects
|
||||
- Skip readiness checks if canary analysis has finished
|
||||
|
||||
## 0.3.0 (2019-01-11)
|
||||
|
||||
Configurable canary analysis duration [#20](https://github.com/stefanprodan/flagger/pull/20)
|
||||
|
||||
#### Breaking changes
|
||||
|
||||
- Helm chart: flag `controlLoopInterval` has been removed
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha3
|
||||
- Schedule canary analysis independently based on `canaryAnalysis.interval`
|
||||
- Add analysis interval to Canary CRD (defaults to one minute)
|
||||
- Make autoscaler (HPA) reference optional
|
||||
|
||||
## 0.2.0 (2019-01-04)
|
||||
|
||||
Webhooks [#18](https://github.com/stefanprodan/flagger/pull/18)
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha2
|
||||
- Implement canary external checks based on webhooks HTTP POST calls
|
||||
- Add webhooks to Canary CRD
|
||||
- Move docs to gitbook [docs.flagger.app](https://docs.flagger.app)
|
||||
|
||||
## 0.1.2 (2018-12-06)
|
||||
|
||||
Improve Slack notifications [#14](https://github.com/stefanprodan/flagger/pull/14)
|
||||
|
||||
#### Features
|
||||
|
||||
- Add canary analysis metadata to init and start Slack messages
|
||||
- Add rollback reason to failed canary Slack messages
|
||||
|
||||
## 0.1.1 (2018-11-28)
|
||||
|
||||
Canary progress deadline [#10](https://github.com/stefanprodan/flagger/pull/10)
|
||||
|
||||
#### Features
|
||||
|
||||
- Rollback canary based on the deployment progress deadline check
|
||||
- Add progress deadline to Canary CRD (defaults to 10 minutes)
|
||||
|
||||
## 0.1.0 (2018-11-25)
|
||||
|
||||
First stable release
|
||||
|
||||
#### Features
|
||||
|
||||
- CRD: canaries.flagger.app v1alpha1
|
||||
- Notifications: post canary events to Slack
|
||||
- Instrumentation: expose Prometheus metrics for canary status and traffic weight percentage
|
||||
- Autoscaling: add HPA reference to CRD and create primary HPA at bootstrap
|
||||
- Bootstrap: create primary deployment, ClusterIP services and Istio virtual service based on CRD spec
|
||||
|
||||
|
||||
## 0.0.1 (2018-10-07)
|
||||
|
||||
Initial semver release
|
||||
|
||||
#### Features
|
||||
|
||||
- Implement canary rollback based on failed checks threshold
|
||||
- Scale up the deployment when canary revision changes
|
||||
- Add OpenAPI v3 schema validation to Canary CRD
|
||||
- Use CRD status for canary state persistence
|
||||
- Add Helm charts for Flagger and Grafana
|
||||
- Add canary analysis Grafana dashboard
|
||||
44
Dockerfile.loadtester
Normal file
@@ -0,0 +1,44 @@
|
||||
FROM golang:1.11 AS hey-builder
|
||||
|
||||
RUN mkdir -p /go/src/github.com/rakyll/hey/
|
||||
|
||||
WORKDIR /go/src/github.com/rakyll/hey
|
||||
|
||||
ADD https://github.com/rakyll/hey/archive/v0.1.1.tar.gz .
|
||||
|
||||
RUN tar xzf v0.1.1.tar.gz --strip 1
|
||||
|
||||
RUN go get ./...
|
||||
|
||||
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 \
|
||||
go install -ldflags '-w -extldflags "-static"' \
|
||||
/go/src/github.com/rakyll/hey
|
||||
|
||||
FROM golang:1.11 AS builder
|
||||
|
||||
RUN mkdir -p /go/src/github.com/stefanprodan/flagger/
|
||||
|
||||
WORKDIR /go/src/github.com/stefanprodan/flagger
|
||||
|
||||
COPY . .
|
||||
|
||||
RUN go test -race ./pkg/loadtester/
|
||||
|
||||
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o loadtester ./cmd/loadtester/*
|
||||
|
||||
FROM alpine:3.8
|
||||
|
||||
RUN addgroup -S app \
|
||||
&& adduser -S -g app app \
|
||||
&& apk --no-cache add ca-certificates curl
|
||||
|
||||
WORKDIR /home/app
|
||||
|
||||
COPY --from=hey-builder /go/bin/hey /usr/local/bin/hey
|
||||
COPY --from=builder /go/src/github.com/stefanprodan/flagger/loadtester .
|
||||
|
||||
RUN chown -R app:app ./
|
||||
|
||||
USER app
|
||||
|
||||
ENTRYPOINT ["./loadtester"]
|
||||
152
Gopkg.lock
generated
@@ -2,12 +2,12 @@
|
||||
|
||||
|
||||
[[projects]]
|
||||
digest = "1:5c3894b2aa4d6bead0ceeea6831b305d62879c871780e7b76296ded1b004bc57"
|
||||
digest = "1:4d6f036ea3fe636bcb2e89850bcdc62a771354e157cd51b8b22a2de8562bf663"
|
||||
name = "cloud.google.com/go"
|
||||
packages = ["compute/metadata"]
|
||||
pruneopts = "NUT"
|
||||
revision = "97efc2c9ffd9fe8ef47f7f3203dc60bbca547374"
|
||||
version = "v0.28.0"
|
||||
revision = "c9474f2f8deb81759839474b6bd1726bbfe1c1c4"
|
||||
version = "v0.36.0"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
@@ -34,15 +34,15 @@
|
||||
version = "v1.0.0"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:8679b8a64f3613e9749c5640c3535c83399b8e69f67ce54d91dc73f6d77373af"
|
||||
digest = "1:a1b2a5e38f79688ee8250942d5fa960525fceb1024c855c7bc76fa77b0f3cca2"
|
||||
name = "github.com/gogo/protobuf"
|
||||
packages = [
|
||||
"proto",
|
||||
"sortkeys",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "636bf0302bc95575d69441b25a2603156ffdddf1"
|
||||
version = "v1.1.1"
|
||||
revision = "ba06b47c162d49f2af050fb4c75bcbc86a159d5c"
|
||||
version = "v1.2.1"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
@@ -55,14 +55,14 @@
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:3fb07f8e222402962fa190eb060608b34eddfb64562a18e2167df2de0ece85d8"
|
||||
digest = "1:b7cb6054d3dff43b38ad2e92492f220f57ae6087ee797dca298139776749ace8"
|
||||
name = "github.com/golang/groupcache"
|
||||
packages = ["lru"]
|
||||
pruneopts = "NUT"
|
||||
revision = "24b0969c4cb722950103eed87108c8d291a8df00"
|
||||
revision = "5b532d6fd5efaf7fa130d4e859a2fde0fc3a9e1b"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:63ccdfbd20f7ccd2399d0647a7d100b122f79c13bb83da9660b1598396fd9f62"
|
||||
digest = "1:2d0636a8c490d2272dd725db26f74a537111b99b9dbdda0d8b98febe63702aa4"
|
||||
name = "github.com/golang/protobuf"
|
||||
packages = [
|
||||
"proto",
|
||||
@@ -72,8 +72,8 @@
|
||||
"ptypes/timestamp",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "aa810b61a9c79d51363740d207bb46cf8e620ed5"
|
||||
version = "v1.2.0"
|
||||
revision = "c823c79ea1570fb5ff454033735a8e68575d1d0f"
|
||||
version = "v1.3.0"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
@@ -119,33 +119,33 @@
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:7fdf3223c7372d1ced0b98bf53457c5e89d89aecbad9a77ba9fcc6e01f9e5621"
|
||||
digest = "1:a86d65bc23eea505cd9139178e4d889733928fe165c7a008f41eaab039edf9df"
|
||||
name = "github.com/gregjones/httpcache"
|
||||
packages = [
|
||||
".",
|
||||
"diskcache",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "9cad4c3443a7200dd6400aef47183728de563a38"
|
||||
revision = "3befbb6ad0cc97d4c25d851e9528915809e1a22f"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:b42cde0e1f3c816dd57f57f7bbcf05ca40263ad96f168714c130c611fc0856a6"
|
||||
digest = "1:52094d0f8bdf831d1a2401e9b6fee5795fdc0b2a2d1f8bb1980834c289e79129"
|
||||
name = "github.com/hashicorp/golang-lru"
|
||||
packages = [
|
||||
".",
|
||||
"simplelru",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "20f1fb78b0740ba8c3cb143a61e86ba5c8669768"
|
||||
version = "v0.5.0"
|
||||
revision = "7087cb70de9f7a8bc0a10c375cb0d2280a8edf9c"
|
||||
version = "v0.5.1"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:9a52adf44086cead3b384e5d0dbf7a1c1cce65e67552ee3383a8561c42a18cd3"
|
||||
digest = "1:aaa38889f11896ee3644d77e17dc7764cc47f5f3d3b488268df2af2b52541c5f"
|
||||
name = "github.com/imdario/mergo"
|
||||
packages = ["."]
|
||||
pruneopts = "NUT"
|
||||
revision = "9f23e2d6bd2a77f959b2bf6acdbefd708a83a4a4"
|
||||
version = "v0.3.6"
|
||||
revision = "7c29201646fa3de8506f701213473dd407f19646"
|
||||
version = "v0.3.7"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
@@ -162,32 +162,6 @@
|
||||
pruneopts = "NUT"
|
||||
revision = "f2b4162afba35581b6d4a50d3b8f34e33c144682"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:03a74b0d86021c8269b52b7c908eb9bb3852ff590b363dad0a807cf58cec2f89"
|
||||
name = "github.com/knative/pkg"
|
||||
packages = [
|
||||
"apis",
|
||||
"apis/duck",
|
||||
"apis/duck/v1alpha1",
|
||||
"apis/istio",
|
||||
"apis/istio/authentication",
|
||||
"apis/istio/authentication/v1alpha1",
|
||||
"apis/istio/common/v1alpha1",
|
||||
"apis/istio/v1alpha3",
|
||||
"client/clientset/versioned",
|
||||
"client/clientset/versioned/fake",
|
||||
"client/clientset/versioned/scheme",
|
||||
"client/clientset/versioned/typed/authentication/v1alpha1",
|
||||
"client/clientset/versioned/typed/authentication/v1alpha1/fake",
|
||||
"client/clientset/versioned/typed/duck/v1alpha1",
|
||||
"client/clientset/versioned/typed/duck/v1alpha1/fake",
|
||||
"client/clientset/versioned/typed/istio/v1alpha3",
|
||||
"client/clientset/versioned/typed/istio/v1alpha3/fake",
|
||||
"signals",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "c15d7c8f2220a7578b33504df6edefa948c845ae"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:5985ef4caf91ece5d54817c11ea25f182697534f8ae6521eadcd628c142ac4b6"
|
||||
name = "github.com/matttproud/golang_protobuf_extensions"
|
||||
@@ -245,11 +219,10 @@
|
||||
name = "github.com/prometheus/client_model"
|
||||
packages = ["go"]
|
||||
pruneopts = "NUT"
|
||||
revision = "5c3871d89910bfb32f5fcab2aa4b9ec68e65a99f"
|
||||
revision = "fd36f4220a901265f90734c3183c5f0c91daa0b8"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:fad5a35eea6a1a33d6c8f949fbc146f24275ca809ece854248187683f52cc30b"
|
||||
digest = "1:4e776079b966091d3e6e12ed2aaf728bea5cd1175ef88bb654e03adbf5d4f5d3"
|
||||
name = "github.com/prometheus/common"
|
||||
packages = [
|
||||
"expfmt",
|
||||
@@ -257,28 +230,30 @@
|
||||
"model",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "c7de2306084e37d54b8be01f3541a8464345e9a5"
|
||||
revision = "cfeb6f9992ffa54aaa4f2170ade4067ee478b250"
|
||||
version = "v0.2.0"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:26a2f5e891cc4d2321f18a0caa84c8e788663c17bed6a487f3cbe2c4295292d0"
|
||||
digest = "1:0a2e604afa3cbf53a1ddade2f240ee8472eded98856dd8c7cfbfea392ddbbfc7"
|
||||
name = "github.com/prometheus/procfs"
|
||||
packages = [
|
||||
".",
|
||||
"internal/util",
|
||||
"iostats",
|
||||
"nfs",
|
||||
"xfs",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "418d78d0b9a7b7de3a6bbc8a23def624cc977bb2"
|
||||
revision = "bbced9601137e764853b2fad7ec3e2dc4c504e02"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:e3707aeaccd2adc89eba6c062fec72116fe1fc1ba71097da85b4d8ae1668a675"
|
||||
digest = "1:9d8420bbf131d1618bde6530af37c3799340d3762cc47210c1d9532a4c3a2779"
|
||||
name = "github.com/spf13/pflag"
|
||||
packages = ["."]
|
||||
pruneopts = "NUT"
|
||||
revision = "9a97c102cda95a86cec2345a6f09f55a939babf5"
|
||||
version = "v1.0.2"
|
||||
revision = "298182f68c66c05229eb03ac171abe6e309ee79a"
|
||||
version = "v1.0.3"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:22f696cee54865fb8e9ff91df7b633f6b8f22037a8015253c6b6a71ca82219c7"
|
||||
@@ -313,15 +288,15 @@
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:3f3a05ae0b95893d90b9b3b5afdb79a9b3d96e4e36e099d841ae602e4aca0da8"
|
||||
digest = "1:058e9504b9a79bfe86092974d05bb3298d2aa0c312d266d43148de289a5065d9"
|
||||
name = "golang.org/x/crypto"
|
||||
packages = ["ssh/terminal"]
|
||||
pruneopts = "NUT"
|
||||
revision = "0e37d006457bf46f9e6692014ba72ef82c33022c"
|
||||
revision = "8dd112bcdc25174059e45e07517d9fc663123347"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:1400b8e87c2c9bd486ea1a13155f59f8f02d385761206df05c0b7db007a53b2c"
|
||||
digest = "1:e3477b53a5c2fb71a7c9688e9b3d58be702807a5a88def8b9a327259d46e4979"
|
||||
name = "golang.org/x/net"
|
||||
packages = [
|
||||
"context",
|
||||
@@ -332,11 +307,11 @@
|
||||
"idna",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "26e67e76b6c3f6ce91f7c52def5af501b4e0f3a2"
|
||||
revision = "16b79f2e4e95ea23b2bf9903c9809ff7b013ce85"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:bc2b221d465bb28ce46e8d472ecdc424b9a9b541bd61d8c311c5f29c8dd75b1b"
|
||||
digest = "1:17ee74a4d9b6078611784b873cdbfe91892d2c73052c430724e66fcc015b6c7b"
|
||||
name = "golang.org/x/oauth2"
|
||||
packages = [
|
||||
".",
|
||||
@@ -346,18 +321,18 @@
|
||||
"jwt",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "d2e6202438beef2727060aa7cabdd924d92ebfd9"
|
||||
revision = "e64efc72b421e893cbf63f17ba2221e7d6d0b0f3"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:44261e94b6095310a2df925fd68632d399a00eb153b52566a7b3697f7c70638c"
|
||||
digest = "1:a0d91ab4d23badd4e64e115c6e6ba7dd56bd3cde5d287845822fb2599ac10236"
|
||||
name = "golang.org/x/sys"
|
||||
packages = [
|
||||
"unix",
|
||||
"windows",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "1561086e645b2809fb9f8a1e2a38160bf8d53bf4"
|
||||
revision = "30e92a19ae4a77dde818b8c3d41d51e4850cba12"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:e7071ed636b5422cc51c0e3a6cebc229d6c9fffc528814b519a980641422d619"
|
||||
@@ -384,26 +359,35 @@
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:c9e7a4b4d47c0ed205d257648b0e5b0440880cb728506e318f8ac7cd36270bc4"
|
||||
digest = "1:9fdc2b55e8e0fafe4b41884091e51e77344f7dc511c5acedcfd98200003bff90"
|
||||
name = "golang.org/x/time"
|
||||
packages = ["rate"]
|
||||
pruneopts = "NUT"
|
||||
revision = "fbb02b2291d28baffd63558aa44b4b56f178d650"
|
||||
revision = "85acf8d2951cb2a3bde7632f9ff273ef0379bcbd"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:45751dc3302c90ea55913674261b2d74286b05cdd8e3ae9606e02e4e77f4353f"
|
||||
digest = "1:e46d8e20161401a9cf8765dfa428494a3492a0b56fe114156b7da792bf41ba78"
|
||||
name = "golang.org/x/tools"
|
||||
packages = [
|
||||
"go/ast/astutil",
|
||||
"go/gcexportdata",
|
||||
"go/internal/cgo",
|
||||
"go/internal/gcimporter",
|
||||
"go/internal/packagesdriver",
|
||||
"go/packages",
|
||||
"go/types/typeutil",
|
||||
"imports",
|
||||
"internal/fastwalk",
|
||||
"internal/gopathwalk",
|
||||
"internal/module",
|
||||
"internal/semver",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "90fa682c2a6e6a37b3a1364ce2fe1d5e41af9d6d"
|
||||
revision = "f8c04913dfb7b2339a756441456bdbe0af6eb508"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:e2da54c7866453ac5831c61c7ec5d887f39328cac088c806553303bff4048e6f"
|
||||
digest = "1:d395d49d784dd3a11938a3e85091b6570664aa90ff2767a626565c6c130fa7e9"
|
||||
name = "google.golang.org/appengine"
|
||||
packages = [
|
||||
".",
|
||||
@@ -418,8 +402,8 @@
|
||||
"urlfetch",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "ae0ab99deb4dc413a2b4bd6c8bdd0eb67f1e4d06"
|
||||
version = "v1.2.0"
|
||||
revision = "e9657d882bb81064595ca3b56cbe2546bbabf7b1"
|
||||
version = "v1.4.0"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:2d1fbdc6777e5408cabeb02bf336305e724b925ff4546ded0fa8715a7267922a"
|
||||
@@ -430,12 +414,12 @@
|
||||
version = "v0.9.1"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:7c95b35057a0ff2e19f707173cc1a947fa43a6eb5c4d300d196ece0334046082"
|
||||
digest = "1:18108594151654e9e696b27b181b953f9a90b16bf14d253dd1b397b025a1487f"
|
||||
name = "gopkg.in/yaml.v2"
|
||||
packages = ["."]
|
||||
pruneopts = "NUT"
|
||||
revision = "5420a8b6744d3b0345ab293f6fcba19c978f1183"
|
||||
version = "v2.2.1"
|
||||
revision = "51d6538a90f86fe93ac480b35f37b2be17fef232"
|
||||
version = "v2.2.2"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:8960ef753a87391086a307122d23cd5007cee93c28189437e4f1b6ed72bffc50"
|
||||
@@ -476,10 +460,9 @@
|
||||
version = "kubernetes-1.11.0"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:4b0d523ee389c762d02febbcfa0734c4530ebe87abe925db18f05422adcb33e8"
|
||||
digest = "1:83b01e3d6f85c4e911de84febd69a2d3ece614c5a4a518fbc2b5d59000645980"
|
||||
name = "k8s.io/apimachinery"
|
||||
packages = [
|
||||
"pkg/api/equality",
|
||||
"pkg/api/errors",
|
||||
"pkg/api/meta",
|
||||
"pkg/api/resource",
|
||||
@@ -659,7 +642,7 @@
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:5249c83f0fb9e277b2d28c19eca814feac7ef05dc762e4deaf0a2e4b1a7c5df3"
|
||||
digest = "1:61024ed77a53ac618effed55043bf6a9afbdeb64136bd6a5b0c992d4c0363766"
|
||||
name = "k8s.io/gengo"
|
||||
packages = [
|
||||
"args",
|
||||
@@ -672,15 +655,23 @@
|
||||
"types",
|
||||
]
|
||||
pruneopts = "NUT"
|
||||
revision = "4242d8e6c5dba56827bb7bcf14ad11cda38f3991"
|
||||
revision = "0689ccc1d7d65d9dd1bedcc3b0b1ed7df91ba266"
|
||||
|
||||
[[projects]]
|
||||
digest = "1:c263611800c3a97991dbcf9d3bc4de390f6224aaa8ca0a7226a9d734f65a416a"
|
||||
name = "k8s.io/klog"
|
||||
packages = ["."]
|
||||
pruneopts = "NUT"
|
||||
revision = "71442cd4037d612096940ceb0f3fec3f7fff66e0"
|
||||
version = "v0.2.0"
|
||||
|
||||
[[projects]]
|
||||
branch = "master"
|
||||
digest = "1:a2c842a1e0aed96fd732b535514556323a6f5edfded3b63e5e0ab1bce188aa54"
|
||||
digest = "1:03a96603922fc1f6895ae083e1e16d943b55ef0656b56965351bd87e7d90485f"
|
||||
name = "k8s.io/kube-openapi"
|
||||
packages = ["pkg/util/proto"]
|
||||
pruneopts = "NUT"
|
||||
revision = "e3762e86a74c878ffed47484592986685639c2cd"
|
||||
revision = "b3a7cee44a305be0a69e1b9ac03018307287e1b0"
|
||||
|
||||
[solve-meta]
|
||||
analyzer-name = "dep"
|
||||
@@ -689,10 +680,7 @@
|
||||
"github.com/google/go-cmp/cmp",
|
||||
"github.com/google/go-cmp/cmp/cmpopts",
|
||||
"github.com/istio/glog",
|
||||
"github.com/knative/pkg/apis/istio/v1alpha3",
|
||||
"github.com/knative/pkg/client/clientset/versioned",
|
||||
"github.com/knative/pkg/client/clientset/versioned/fake",
|
||||
"github.com/knative/pkg/signals",
|
||||
"github.com/prometheus/client_golang/prometheus",
|
||||
"github.com/prometheus/client_golang/prometheus/promhttp",
|
||||
"go.uber.org/zap",
|
||||
"go.uber.org/zap/zapcore",
|
||||
|
||||
@@ -45,10 +45,6 @@ required = [
|
||||
name = "github.com/google/go-cmp"
|
||||
version = "v0.2.0"
|
||||
|
||||
[[constraint]]
|
||||
name = "github.com/knative/pkg"
|
||||
revision = "c15d7c8f2220a7578b33504df6edefa948c845ae"
|
||||
|
||||
[[override]]
|
||||
name = "github.com/golang/glog"
|
||||
source = "github.com/istio/glog"
|
||||
|
||||
11
Makefile
@@ -3,9 +3,11 @@ VERSION?=$(shell grep 'VERSION' pkg/version/version.go | awk '{ print $$4 }' | t
|
||||
VERSION_MINOR:=$(shell grep 'VERSION' pkg/version/version.go | awk '{ print $$4 }' | tr -d '"' | rev | cut -d'.' -f2- | rev)
|
||||
PATCH:=$(shell grep 'VERSION' pkg/version/version.go | awk '{ print $$4 }' | tr -d '"' | awk -F. '{print $$NF}')
|
||||
SOURCE_DIRS = cmd pkg/apis pkg/controller pkg/server pkg/logging pkg/version
|
||||
LT_VERSION?=$(shell grep 'VERSION' cmd/loadtester/main.go | awk '{ print $$4 }' | tr -d '"' | head -n1)
|
||||
|
||||
run:
|
||||
go run cmd/flagger/* -kubeconfig=$$HOME/.kube/config -log-level=info \
|
||||
-metrics-server=https://prometheus.iowa.weavedx.com \
|
||||
-metrics-server=https://prometheus.istio.weavedx.com \
|
||||
-slack-url=https://hooks.slack.com/services/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 \
|
||||
-slack-channel="devops-alerts"
|
||||
|
||||
@@ -29,7 +31,7 @@ test: test-fmt test-codegen
|
||||
go test ./...
|
||||
|
||||
helm-package:
|
||||
cd charts/ && helm package flagger/ && helm package grafana/
|
||||
cd charts/ && helm package ./*
|
||||
mv charts/*.tgz docs/
|
||||
helm repo index docs --url https://stefanprodan.github.io/flagger --merge ./docs/index.yaml
|
||||
|
||||
@@ -44,6 +46,7 @@ version-set:
|
||||
sed -i '' "s/flagger:$$current/flagger:$$next/g" artifacts/flagger/deployment.yaml && \
|
||||
sed -i '' "s/tag: $$current/tag: $$next/g" charts/flagger/values.yaml && \
|
||||
sed -i '' "s/appVersion: $$current/appVersion: $$next/g" charts/flagger/Chart.yaml && \
|
||||
sed -i '' "s/version: $$current/version: $$next/g" charts/flagger/Chart.yaml && \
|
||||
echo "Version $$next set in code, deployment and charts"
|
||||
|
||||
version-up:
|
||||
@@ -77,3 +80,7 @@ reset-test:
|
||||
kubectl delete -f ./artifacts/namespaces
|
||||
kubectl apply -f ./artifacts/namespaces
|
||||
kubectl apply -f ./artifacts/canaries
|
||||
|
||||
loadtester-push:
|
||||
docker build -t quay.io/stefanprodan/flagger-loadtester:$(LT_VERSION) . -f Dockerfile.loadtester
|
||||
docker push quay.io/stefanprodan/flagger-loadtester:$(LT_VERSION)
|
||||
424
README.md
@@ -8,9 +8,38 @@
|
||||
|
||||
Flagger is a Kubernetes operator that automates the promotion of canary deployments
|
||||
using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running integration tests,
|
||||
The canary analysis can be extended with webhooks for running acceptance tests,
|
||||
load tests or any other custom validation.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pods health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||
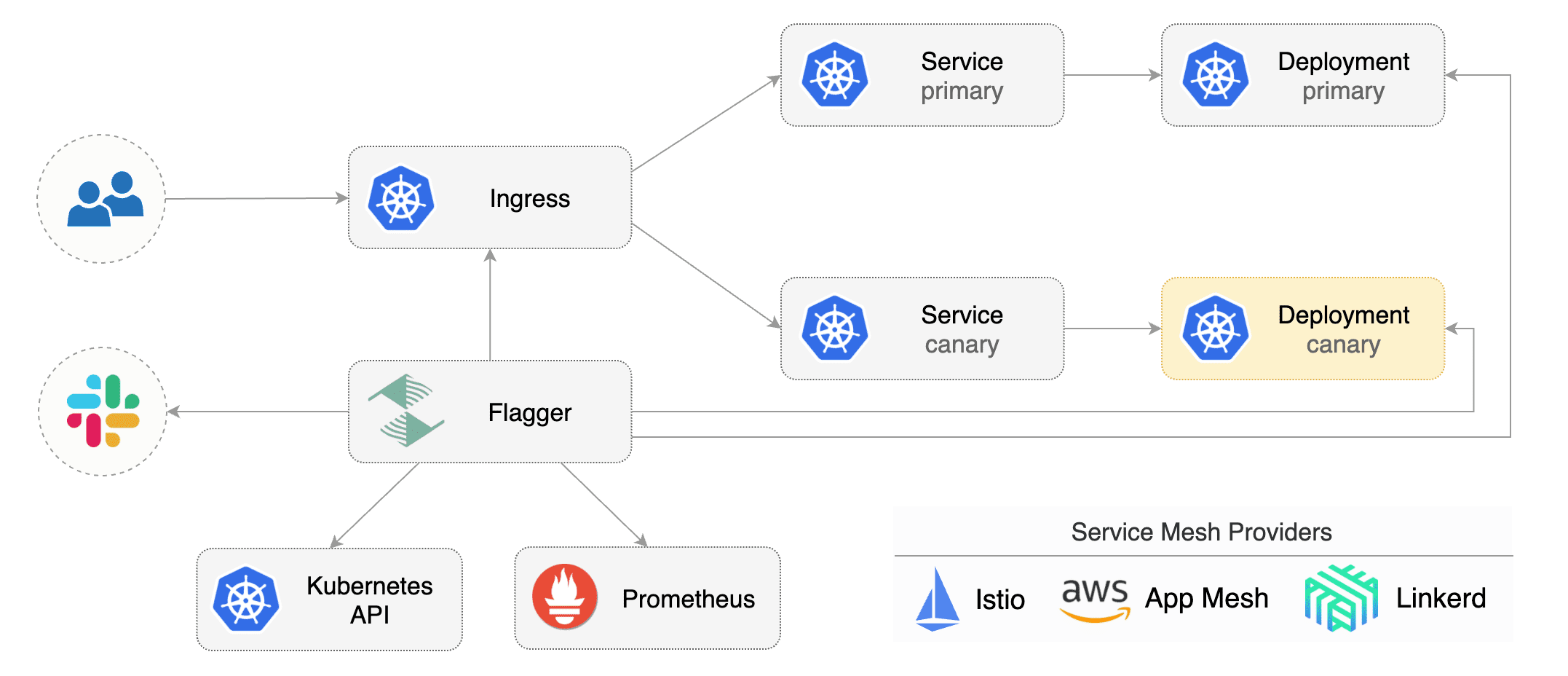
|
||||
|
||||
### Documentation
|
||||
|
||||
Flagger documentation can be found at [docs.flagger.app](https://docs.flagger.app)
|
||||
|
||||
* Install
|
||||
* [Flagger install on Kubernetes](https://docs.flagger.app/install/flagger-install-on-kubernetes)
|
||||
* [Flagger install on GKE](https://docs.flagger.app/install/flagger-install-on-google-cloud)
|
||||
* How it works
|
||||
* [Canary custom resource](https://docs.flagger.app/how-it-works#canary-custom-resource)
|
||||
* [Routing](https://docs.flagger.app/how-it-works#istio-routing)
|
||||
* [Canary deployment stages](https://docs.flagger.app/how-it-works#canary-deployment)
|
||||
* [Canary analysis](https://docs.flagger.app/how-it-works#canary-analysis)
|
||||
* [HTTP metrics](https://docs.flagger.app/how-it-works#http-metrics)
|
||||
* [Custom metrics](https://docs.flagger.app/how-it-works#custom-metrics)
|
||||
* [Webhooks](https://docs.flagger.app/how-it-works#webhooks)
|
||||
* [Load testing](https://docs.flagger.app/how-it-works#load-testing)
|
||||
* Usage
|
||||
* [Canary promotions and rollbacks](https://docs.flagger.app/usage/progressive-delivery)
|
||||
* [Monitoring](https://docs.flagger.app/usage/monitoring)
|
||||
* [Alerting](https://docs.flagger.app/usage/alerting)
|
||||
* Tutorials
|
||||
* [Canary deployments with Helm charts and Weave Flux](https://docs.flagger.app/tutorials/canary-helm-gitops)
|
||||
|
||||
### Install
|
||||
|
||||
Before installing Flagger make sure you have Istio setup up with Prometheus enabled.
|
||||
@@ -30,46 +59,14 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
Flagger is compatible with Kubernetes >1.11.0 and Istio >1.0.0.
|
||||
|
||||
### Usage
|
||||
### Canary CRD
|
||||
|
||||
Flagger takes a Kubernetes deployment and creates a series of objects
|
||||
(Kubernetes [deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/),
|
||||
ClusterIP [services](https://kubernetes.io/docs/concepts/services-networking/service/) and
|
||||
Istio [virtual services](https://istio.io/docs/reference/config/istio.networking.v1alpha3/#VirtualService))
|
||||
to drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Istio virtual services).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
|
||||

|
||||
|
||||
Gated canary promotion stages:
|
||||
|
||||
* scan for canary deployments
|
||||
* check Istio virtual service routes are mapped to primary and canary ClusterIP services
|
||||
* check primary and canary deployments status
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* increase canary traffic weight percentage from 0% to 5% (step weight)
|
||||
* check canary HTTP request success rate and latency
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* check if the number of failed checks reached the threshold
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* wait for the canary deployment to be updated (revision bump) and start over
|
||||
* increase canary traffic weight by 5% (step weight) till it reaches 50% (max weight)
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
* halt advancement while canary deployment is being scaled up/down by HPA
|
||||
* promote canary to primary
|
||||
* copy canary deployment spec template over primary
|
||||
* wait for primary rolling update to finish
|
||||
* halt advancement if pods are unhealthy
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment
|
||||
* mark rollout as finished
|
||||
* wait for the canary deployment to be updated (revision bump) and start over
|
||||
|
||||
You can change the canary analysis _max weight_ and the _step weight_ percentage in the Flagger's custom resource.
|
||||
Flagger keeps track of ConfigMaps and Secrets referenced by a Kubernetes Deployment and triggers a canary analysis if any of those objects change.
|
||||
When promoting a workload in production, both code (container images) and configuration (config maps and secrets) are being synchronised.
|
||||
|
||||
For a deployment named _podinfo_, a canary promotion can be defined using Flagger's custom resource:
|
||||
|
||||
@@ -102,6 +99,27 @@ spec:
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- podinfo.example.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# cross-origin resource sharing policy (optional)
|
||||
corsPolicy:
|
||||
allowOrigin:
|
||||
- example.com
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
@@ -115,6 +133,7 @@ spec:
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
metrics:
|
||||
# builtin Istio checks
|
||||
- name: istio_requests_total
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
@@ -125,312 +144,32 @@ spec:
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# custom check
|
||||
- name: "kafka lag"
|
||||
threshold: 100
|
||||
query: |
|
||||
avg_over_time(
|
||||
kafka_consumergroup_lag{
|
||||
consumergroup=~"podinfo-consumer-.*",
|
||||
topic="podinfo"
|
||||
}[1m]
|
||||
)
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: integration-tests
|
||||
url: http://podinfo.test:9898/echo
|
||||
timeout: 1m
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
test: "all"
|
||||
token: "16688eb5e9f289f1991c"
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
The canary analysis is using the following promql queries:
|
||||
|
||||
_HTTP requests success rate percentage_
|
||||
|
||||
```sql
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload",
|
||||
response_code!~"5.*"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
_HTTP requests milliseconds duration P99_
|
||||
|
||||
```sql
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
irate(
|
||||
istio_request_duration_seconds_bucket{
|
||||
reporter="destination",
|
||||
destination_workload=~"$workload",
|
||||
destination_workload_namespace=~"$namespace"
|
||||
}[$interval]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
The canary analysis can be extended with webhooks.
|
||||
Flagger will call the webhooks (HTTP POST) and determine from the response status code (HTTP 2xx) if the canary is failing or not.
|
||||
|
||||
Webhook payload:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "podinfo",
|
||||
"namespace": "test",
|
||||
"metadata": {
|
||||
"test": "all",
|
||||
"token": "16688eb5e9f289f1991c"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Automated canary analysis, promotions and rollbacks
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/deployment.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/hpa.yaml
|
||||
```
|
||||
|
||||
Create a canary promotion custom resource (replace the Istio gateway and the internet domain with your own):
|
||||
|
||||
```bash
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
virtualservice.networking.istio.io/podinfo
|
||||
```
|
||||
|
||||
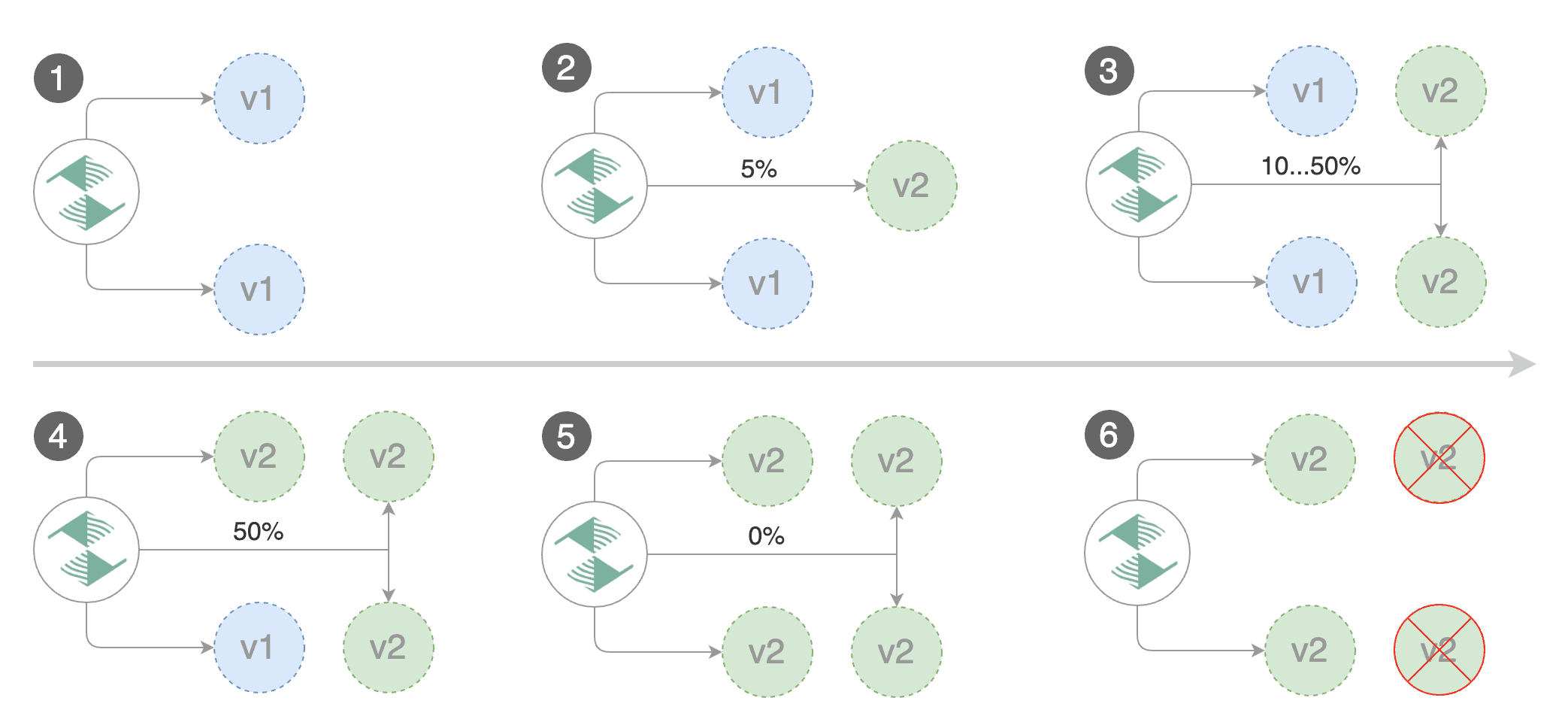
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.2.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new canary analysis:
|
||||
|
||||
```
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Last Transition Time: 2019-01-16T13:47:16Z
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 5 2019-01-16T14:05:07Z
|
||||
```
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Create a tester pod and exec into it:
|
||||
|
||||
```bash
|
||||
kubectl -n test run tester --image=quay.io/stefanprodan/podinfo:1.2.1 -- ./podinfo --port=9898
|
||||
kubectl -n test exec -it tester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Last Transition Time: 2019-01-16T13:47:16Z
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
### Monitoring
|
||||
|
||||
Flagger comes with a Grafana dashboard made for canary analysis.
|
||||
|
||||
Install Grafana with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
The dashboard shows the RED and USE metrics for the primary and canary workloads:
|
||||
|
||||
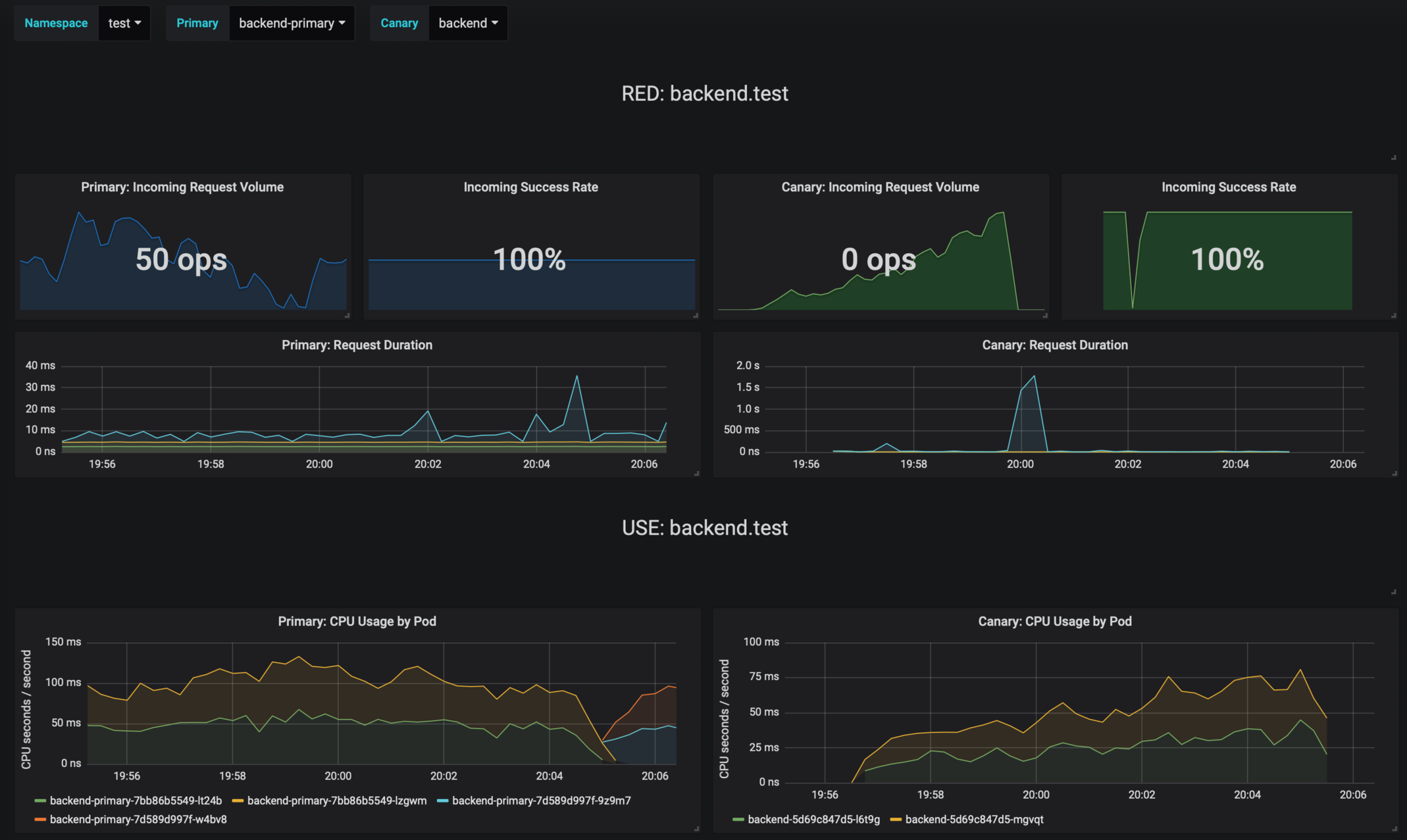
|
||||
|
||||
The canary errors and latency spikes have been recorded as Kubernetes events and logged by Flagger in json format:
|
||||
|
||||
```
|
||||
kubectl -n istio-system logs deployment/flagger --tail=100 | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Halt podinfo.test advancement success rate 98.69% < 99%
|
||||
Advance podinfo.test canary weight 40
|
||||
Halt podinfo.test advancement request duration 1.515s > 500ms
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Halt podinfo-primary.test advancement waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Scaling down podinfo.test
|
||||
Promotion completed! podinfo.test
|
||||
```
|
||||
|
||||
Flagger exposes Prometheus metrics that can be used to determine the canary analysis status and the destination weight values:
|
||||
|
||||
```bash
|
||||
# Canaries total gauge
|
||||
flagger_canary_total{namespace="test"} 1
|
||||
|
||||
# Canary promotion last known status gauge
|
||||
# 0 - running, 1 - successful, 2 - failed
|
||||
flagger_canary_status{name="podinfo" namespace="test"} 1
|
||||
|
||||
# Canary traffic weight gauge
|
||||
flagger_canary_weight{workload="podinfo-primary" namespace="test"} 95
|
||||
flagger_canary_weight{workload="podinfo" namespace="test"} 5
|
||||
|
||||
# Seconds spent performing canary analysis histogram
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="10"} 6
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="+Inf"} 6
|
||||
flagger_canary_duration_seconds_sum{name="podinfo",namespace="test"} 17.3561329
|
||||
flagger_canary_duration_seconds_count{name="podinfo",namespace="test"} 6
|
||||
```
|
||||
|
||||
### Alerting
|
||||
|
||||
Flagger can be configured to send Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Once configured with a Slack incoming webhook, Flagger will post messages when a canary deployment has been initialized,
|
||||
when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||

|
||||
|
||||
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis
|
||||
reached the maximum number of failed checks:
|
||||
|
||||
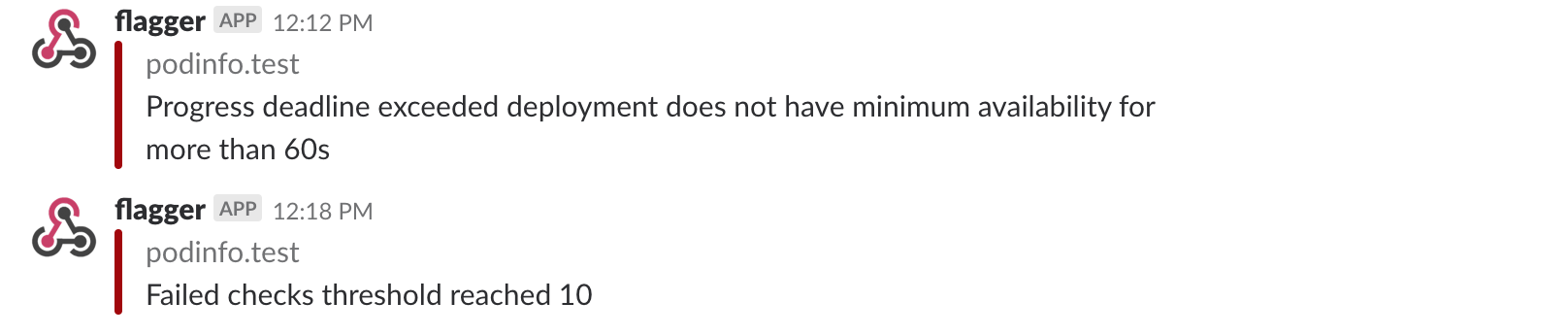
|
||||
|
||||
Besides Slack, you can use Alertmanager to trigger alerts when a canary deployment failed:
|
||||
|
||||
```yaml
|
||||
- alert: canary_rollback
|
||||
expr: flagger_canary_status > 1
|
||||
for: 1m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "Canary failed"
|
||||
description: "Workload {{ $labels.name }} namespace {{ $labels.namespace }}"
|
||||
```
|
||||
For more details on how the canary analysis and promotion works please [read the docs](https://docs.flagger.app/how-it-works).
|
||||
|
||||
### Roadmap
|
||||
|
||||
* Extend the validation mechanism to support other metrics than HTTP success rate and latency
|
||||
* Add A/B testing capabilities using fixed routing based on HTTP headers and cookies match conditions
|
||||
* Integrate with other service mesh technologies like AWS AppMesh and Linkerd v2
|
||||
* Add support for comparing the canary metrics to the primary ones and do the validation based on the derivation between the two
|
||||
* Extend the canary analysis and promotion to other types than Kubernetes deployments such as Flux Helm releases or OpenFaaS functions
|
||||
|
||||
### Contributing
|
||||
|
||||
@@ -442,3 +181,16 @@ When submitting bug reports please include as much details as possible:
|
||||
* which Kubernetes/Istio version
|
||||
* what configuration (canary, virtual service and workloads definitions)
|
||||
* what happened (Flagger, Istio Pilot and Proxy logs)
|
||||
|
||||
### Getting Help
|
||||
|
||||
If you have any questions about Flagger and progressive delivery:
|
||||
|
||||
* Read the Flagger [docs](https://docs.flagger.app).
|
||||
* Invite yourself to the [Weave community slack](https://slack.weave.works/)
|
||||
and join the [#flagger](https://weave-community.slack.com/messages/flagger/) channel.
|
||||
* Join the [Weave User Group](https://www.meetup.com/pro/Weave/) and get invited to online talks,
|
||||
hands-on training and meetups in your area.
|
||||
* File an [issue](https://github.com/stefanprodan/flagger/issues/new).
|
||||
|
||||
Your feedback is always welcome!
|
||||
|
||||
@@ -25,7 +25,23 @@ spec:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.iowa.weavedx.com
|
||||
- app.istio.weavedx.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
@@ -51,9 +67,8 @@ spec:
|
||||
interval: 30s
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: integration-tests
|
||||
url: https://httpbin.org/post
|
||||
timeout: 1m
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
test: "all"
|
||||
token: "16688eb5e9f289f1991c"
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
|
||||
@@ -25,7 +25,7 @@ spec:
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.3.0
|
||||
image: quay.io/stefanprodan/podinfo:1.4.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
|
||||
6
artifacts/cluster/namespaces/test.yaml
Normal file
@@ -0,0 +1,6 @@
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: test
|
||||
labels:
|
||||
istio-injection: enabled
|
||||
26
artifacts/cluster/releases/test/backend.yaml
Normal file
@@ -0,0 +1,26 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: backend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: regexp:^1.4.*
|
||||
spec:
|
||||
releaseName: backend
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
httpServer:
|
||||
timeout: 30s
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: false
|
||||
loadtest:
|
||||
enabled: true
|
||||
27
artifacts/cluster/releases/test/frontend.yaml
Normal file
@@ -0,0 +1,27 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: semver:~1.4
|
||||
spec:
|
||||
releaseName: frontend
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
backend: http://backend-podinfo:9898/echo
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: true
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
host: frontend.istio.example.com
|
||||
loadtest:
|
||||
enabled: true
|
||||
18
artifacts/cluster/releases/test/loadtester.yaml
Normal file
@@ -0,0 +1,18 @@
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: loadtester
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: glob:0.*
|
||||
spec:
|
||||
releaseName: flagger-loadtester
|
||||
chart:
|
||||
repository: https://flagger.app/
|
||||
name: loadtester
|
||||
version: 0.1.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger-loadtester
|
||||
tag: 0.1.0
|
||||
58
artifacts/configs/canary.yaml
Normal file
@@ -0,0 +1,58 @@
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.iowa.weavedx.com
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# Istio Prometheus checks
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
threshold: 99
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# external checks (optional)
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
16
artifacts/configs/configs.yaml
Normal file
@@ -0,0 +1,16 @@
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: podinfo-config-env
|
||||
namespace: test
|
||||
data:
|
||||
color: blue
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: podinfo-config-vol
|
||||
namespace: test
|
||||
data:
|
||||
output: console
|
||||
textmode: "true"
|
||||
89
artifacts/configs/deployment.yaml
Normal file
@@ -0,0 +1,89 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
labels:
|
||||
app: podinfo
|
||||
spec:
|
||||
minReadySeconds: 5
|
||||
revisionHistoryLimit: 5
|
||||
progressDeadlineSeconds: 60
|
||||
strategy:
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
type: RollingUpdate
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
prometheus.io/scrape: "true"
|
||||
labels:
|
||||
app: podinfo
|
||||
spec:
|
||||
containers:
|
||||
- name: podinfod
|
||||
image: quay.io/stefanprodan/podinfo:1.3.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- containerPort: 9898
|
||||
name: http
|
||||
protocol: TCP
|
||||
command:
|
||||
- ./podinfo
|
||||
- --port=9898
|
||||
- --level=info
|
||||
- --random-delay=false
|
||||
- --random-error=false
|
||||
env:
|
||||
- name: PODINFO_UI_COLOR
|
||||
valueFrom:
|
||||
configMapKeyRef:
|
||||
name: podinfo-config-env
|
||||
key: color
|
||||
- name: SECRET_USER
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: podinfo-secret-env
|
||||
key: user
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/healthz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:9898/readyz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2000m
|
||||
memory: 512Mi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 64Mi
|
||||
volumeMounts:
|
||||
- name: configs
|
||||
mountPath: /etc/podinfo/configs
|
||||
readOnly: true
|
||||
- name: secrets
|
||||
mountPath: /etc/podinfo/secrets
|
||||
readOnly: true
|
||||
volumes:
|
||||
- name: configs
|
||||
configMap:
|
||||
name: podinfo-config-vol
|
||||
- name: secrets
|
||||
secret:
|
||||
secretName: podinfo-secret-vol
|
||||
19
artifacts/configs/hpa.yaml
Normal file
@@ -0,0 +1,19 @@
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
minReplicas: 1
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
# scale up if usage is above
|
||||
# 99% of the requested CPU (100m)
|
||||
targetAverageUtilization: 99
|
||||
16
artifacts/configs/secrets.yaml
Normal file
@@ -0,0 +1,16 @@
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: podinfo-secret-env
|
||||
namespace: test
|
||||
data:
|
||||
password: cGFzc3dvcmQ=
|
||||
user: YWRtaW4=
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: podinfo-secret-vol
|
||||
namespace: test
|
||||
data:
|
||||
key: cGFzc3dvcmQ=
|
||||
@@ -13,11 +13,73 @@ metadata:
|
||||
labels:
|
||||
app: flagger
|
||||
rules:
|
||||
- apiGroups: ['*']
|
||||
resources: ['*']
|
||||
verbs: ['*']
|
||||
- nonResourceURLs: ['*']
|
||||
verbs: ['*']
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- configmaps
|
||||
- secrets
|
||||
- events
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- services
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- apps
|
||||
resources:
|
||||
- deployments
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- autoscaling
|
||||
resources:
|
||||
- horizontalpodautoscalers
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries/status
|
||||
verbs:
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- networking.istio.io
|
||||
resources:
|
||||
- virtualservices
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries
|
||||
verbs:
|
||||
- get
|
||||
- list
|
||||
- watch
|
||||
- nonResourceURLs:
|
||||
- /version
|
||||
verbs:
|
||||
- get
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
|
||||
@@ -73,6 +73,10 @@ spec:
|
||||
properties:
|
||||
port:
|
||||
type: number
|
||||
timeout:
|
||||
type: string
|
||||
skipAnalysis:
|
||||
type: boolean
|
||||
canaryAnalysis:
|
||||
properties:
|
||||
interval:
|
||||
@@ -89,7 +93,7 @@ spec:
|
||||
properties:
|
||||
items:
|
||||
type: object
|
||||
required: ['name', 'interval', 'threshold']
|
||||
required: ['name', 'threshold']
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
@@ -98,6 +102,8 @@ spec:
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
threshold:
|
||||
type: number
|
||||
query:
|
||||
type: string
|
||||
webhooks:
|
||||
type: array
|
||||
properties:
|
||||
|
||||
@@ -22,8 +22,8 @@ spec:
|
||||
serviceAccountName: flagger
|
||||
containers:
|
||||
- name: flagger
|
||||
image: quay.io/stefanprodan/flagger:0.4.0
|
||||
imagePullPolicy: Always
|
||||
image: quay.io/stefanprodan/flagger:0.8.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 8080
|
||||
|
||||
27
artifacts/gke/istio-gateway.yaml
Normal file
@@ -0,0 +1,27 @@
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
httpsRedirect: true
|
||||
- port:
|
||||
number: 443
|
||||
name: https
|
||||
protocol: HTTPS
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
mode: SIMPLE
|
||||
privateKey: /etc/istio/ingressgateway-certs/tls.key
|
||||
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
|
||||
443
artifacts/gke/istio-prometheus.yaml
Normal file
@@ -0,0 +1,443 @@
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRole
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- nodes
|
||||
- services
|
||||
- endpoints
|
||||
- pods
|
||||
- nodes/proxy
|
||||
verbs: ["get", "list", "watch"]
|
||||
- apiGroups: [""]
|
||||
resources:
|
||||
- configmaps
|
||||
verbs: ["get"]
|
||||
- nonResourceURLs: ["/metrics"]
|
||||
verbs: ["get"]
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
metadata:
|
||||
name: prometheus
|
||||
labels:
|
||||
app: prometheus
|
||||
roleRef:
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
kind: ClusterRole
|
||||
name: prometheus
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
data:
|
||||
prometheus.yml: |-
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
scrape_configs:
|
||||
|
||||
- job_name: 'istio-mesh'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-telemetry;prometheus
|
||||
|
||||
|
||||
# Scrape config for envoy stats
|
||||
- job_name: 'envoy-stats'
|
||||
metrics_path: /stats/prometheus
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_pod_container_port_name]
|
||||
action: keep
|
||||
regex: '.*-envoy-prom'
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:15090
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
|
||||
metric_relabel_configs:
|
||||
# Exclude some of the envoy metrics that have massive cardinality
|
||||
# This list may need to be pruned further moving forward, as informed
|
||||
# by performance and scalability testing.
|
||||
- source_labels: [ cluster_name ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ tcp_prefix ]
|
||||
regex: '(outbound|inbound|prometheus_stats).*'
|
||||
action: drop
|
||||
- source_labels: [ listener_address ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_listener_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ http_conn_manager_prefix ]
|
||||
regex: '(.+)'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tls.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_tcp_downstream.*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_http_(stats|admin).*'
|
||||
action: drop
|
||||
- source_labels: [ __name__ ]
|
||||
regex: 'envoy_cluster_(lb|retry|bind|internal|max|original).*'
|
||||
action: drop
|
||||
|
||||
|
||||
- job_name: 'istio-policy'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-policy;http-monitoring
|
||||
|
||||
- job_name: 'istio-telemetry'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-telemetry;http-monitoring
|
||||
|
||||
- job_name: 'pilot'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-pilot;http-monitoring
|
||||
|
||||
- job_name: 'galley'
|
||||
# Override the global default and scrape targets from this job every 5 seconds.
|
||||
scrape_interval: 5s
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- istio-system
|
||||
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: istio-galley;http-monitoring
|
||||
|
||||
# scrape config for API servers
|
||||
- job_name: 'kubernetes-apiservers'
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
namespaces:
|
||||
names:
|
||||
- default
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
|
||||
action: keep
|
||||
regex: kubernetes;https
|
||||
|
||||
# scrape config for nodes (kubelet)
|
||||
- job_name: 'kubernetes-nodes'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics
|
||||
|
||||
# Scrape config for Kubelet cAdvisor.
|
||||
#
|
||||
# This is required for Kubernetes 1.7.3 and later, where cAdvisor metrics
|
||||
# (those whose names begin with 'container_') have been removed from the
|
||||
# Kubelet metrics endpoint. This job scrapes the cAdvisor endpoint to
|
||||
# retrieve those metrics.
|
||||
#
|
||||
# In Kubernetes 1.7.0-1.7.2, these metrics are only exposed on the cAdvisor
|
||||
# HTTP endpoint; use "replacement: /api/v1/nodes/${1}:4194/proxy/metrics"
|
||||
# in that case (and ensure cAdvisor's HTTP server hasn't been disabled with
|
||||
# the --cadvisor-port=0 Kubelet flag).
|
||||
#
|
||||
# This job is not necessary and should be removed in Kubernetes 1.6 and
|
||||
# earlier versions, or it will cause the metrics to be scraped twice.
|
||||
- job_name: 'kubernetes-cadvisor'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
|
||||
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
|
||||
kubernetes_sd_configs:
|
||||
- role: node
|
||||
relabel_configs:
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_node_label_(.+)
|
||||
- target_label: __address__
|
||||
replacement: kubernetes.default.svc:443
|
||||
- source_labels: [__meta_kubernetes_node_name]
|
||||
regex: (.+)
|
||||
target_label: __metrics_path__
|
||||
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
|
||||
|
||||
# scrape config for service endpoints.
|
||||
- job_name: 'kubernetes-service-endpoints'
|
||||
kubernetes_sd_configs:
|
||||
- role: endpoints
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
|
||||
action: replace
|
||||
target_label: __scheme__
|
||||
regex: (https?)
|
||||
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
target_label: __address__
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_service_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: kubernetes_namespace
|
||||
- source_labels: [__meta_kubernetes_service_name]
|
||||
action: replace
|
||||
target_label: kubernetes_name
|
||||
|
||||
- job_name: 'kubernetes-pods'
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
relabel_configs: # If first two labels are present, pod should be scraped by the istio-secure job.
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_sidecar_istio_io_status]
|
||||
action: drop
|
||||
regex: (.+)
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_istio_mtls]
|
||||
action: drop
|
||||
regex: (true)
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
|
||||
- job_name: 'kubernetes-pods-istio-secure'
|
||||
scheme: https
|
||||
tls_config:
|
||||
ca_file: /etc/istio-certs/root-cert.pem
|
||||
cert_file: /etc/istio-certs/cert-chain.pem
|
||||
key_file: /etc/istio-certs/key.pem
|
||||
insecure_skip_verify: true # prometheus does not support secure naming.
|
||||
kubernetes_sd_configs:
|
||||
- role: pod
|
||||
relabel_configs:
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
|
||||
action: keep
|
||||
regex: true
|
||||
# sidecar status annotation is added by sidecar injector and
|
||||
# istio_workload_mtls_ability can be specifically placed on a pod to indicate its ability to receive mtls traffic.
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_sidecar_istio_io_status, __meta_kubernetes_pod_annotation_istio_mtls]
|
||||
action: keep
|
||||
regex: (([^;]+);([^;]*))|(([^;]*);(true))
|
||||
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
|
||||
action: replace
|
||||
target_label: __metrics_path__
|
||||
regex: (.+)
|
||||
- source_labels: [__address__] # Only keep address that is host:port
|
||||
action: keep # otherwise an extra target with ':443' is added for https scheme
|
||||
regex: ([^:]+):(\d+)
|
||||
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
|
||||
action: replace
|
||||
regex: ([^:]+)(?::\d+)?;(\d+)
|
||||
replacement: $1:$2
|
||||
target_label: __address__
|
||||
- action: labelmap
|
||||
regex: __meta_kubernetes_pod_label_(.+)
|
||||
- source_labels: [__meta_kubernetes_namespace]
|
||||
action: replace
|
||||
target_label: namespace
|
||||
- source_labels: [__meta_kubernetes_pod_name]
|
||||
action: replace
|
||||
target_label: pod_name
|
||||
---
|
||||
|
||||
# Source: istio/charts/prometheus/templates/service.yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
annotations:
|
||||
prometheus.io/scrape: 'true'
|
||||
labels:
|
||||
name: prometheus
|
||||
spec:
|
||||
selector:
|
||||
app: prometheus
|
||||
ports:
|
||||
- name: http-prometheus
|
||||
protocol: TCP
|
||||
port: 9090
|
||||
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: prometheus
|
||||
namespace: istio-system
|
||||
labels:
|
||||
app: prometheus
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: prometheus
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: prometheus
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "false"
|
||||
scheduler.alpha.kubernetes.io/critical-pod: ""
|
||||
spec:
|
||||
serviceAccountName: prometheus
|
||||
containers:
|
||||
- name: prometheus
|
||||
image: "docker.io/prom/prometheus:v2.7.1"
|
||||
imagePullPolicy: IfNotPresent
|
||||
args:
|
||||
- '--storage.tsdb.retention=6h'
|
||||
- '--config.file=/etc/prometheus/prometheus.yml'
|
||||
ports:
|
||||
- containerPort: 9090
|
||||
name: http
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
path: /-/healthy
|
||||
port: 9090
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
path: /-/ready
|
||||
port: 9090
|
||||
resources:
|
||||
requests:
|
||||
cpu: 10m
|
||||
|
||||
volumeMounts:
|
||||
- name: config-volume
|
||||
mountPath: /etc/prometheus
|
||||
- mountPath: /etc/istio-certs
|
||||
name: istio-certs
|
||||
volumes:
|
||||
- name: config-volume
|
||||
configMap:
|
||||
name: prometheus
|
||||
- name: istio-certs
|
||||
secret:
|
||||
defaultMode: 420
|
||||
optional: true
|
||||
secretName: istio.default
|
||||
60
artifacts/loadtester/deployment.yaml
Normal file
@@ -0,0 +1,60 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: flagger-loadtester
|
||||
labels:
|
||||
app: flagger-loadtester
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: flagger-loadtester
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: flagger-loadtester
|
||||
annotations:
|
||||
prometheus.io/scrape: "true"
|
||||
spec:
|
||||
containers:
|
||||
- name: loadtester
|
||||
image: quay.io/stefanprodan/flagger-loadtester:0.1.0
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 8080
|
||||
command:
|
||||
- ./loadtester
|
||||
- -port=8080
|
||||
- -log-level=info
|
||||
- -timeout=1h
|
||||
- -log-cmd-output=true
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
resources:
|
||||
limits:
|
||||
memory: "512Mi"
|
||||
cpu: "1000m"
|
||||
requests:
|
||||
memory: "32Mi"
|
||||
cpu: "10m"
|
||||
securityContext:
|
||||
readOnlyRootFilesystem: true
|
||||
runAsUser: 10001
|
||||
15
artifacts/loadtester/service.yaml
Normal file
@@ -0,0 +1,15 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: flagger-loadtester
|
||||
labels:
|
||||
app: flagger-loadtester
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
app: flagger-loadtester
|
||||
ports:
|
||||
- name: http
|
||||
port: 80
|
||||
protocol: TCP
|
||||
targetPort: http
|
||||
45
artifacts/routing/destination-rule.yaml
Normal file
@@ -0,0 +1,45 @@
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- podinfo.istio.weavedx.com
|
||||
- podinfo
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: podinfo
|
||||
subset: primary
|
||||
weight: 50
|
||||
- destination:
|
||||
host: podinfo
|
||||
subset: canary
|
||||
weight: 50
|
||||
---
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: DestinationRule
|
||||
metadata:
|
||||
name: podinfo-destination
|
||||
namespace: test
|
||||
spec:
|
||||
host: podinfo
|
||||
trafficPolicy:
|
||||
loadBalancer:
|
||||
consistentHash:
|
||||
httpCookie:
|
||||
name: istiouser
|
||||
ttl: 30s
|
||||
subsets:
|
||||
- name: primary
|
||||
labels:
|
||||
app: podinfo
|
||||
role: primary
|
||||
- name: canary
|
||||
labels:
|
||||
app: podinfo
|
||||
role: canary
|
||||
@@ -8,13 +8,17 @@ spec:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- podinfo.iowa.weavedx.com
|
||||
- app.istio.weavedx.com
|
||||
- podinfo
|
||||
http:
|
||||
- match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: ^(?!.*Chrome)(?=.*\bSafari\b).*$
|
||||
uri:
|
||||
prefix: "/version/"
|
||||
rewrite:
|
||||
uri: /api/info
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
@@ -26,7 +30,12 @@ spec:
|
||||
port:
|
||||
number: 9898
|
||||
weight: 100
|
||||
- route:
|
||||
- match:
|
||||
- uri:
|
||||
prefix: "/version/"
|
||||
rewrite:
|
||||
uri: /api/info
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
port:
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
apiVersion: v1
|
||||
name: flagger
|
||||
version: 0.4.0
|
||||
appVersion: 0.4.0
|
||||
version: 0.8.0
|
||||
appVersion: 0.8.0
|
||||
kubeVersion: ">=1.11.0-0"
|
||||
engine: gotpl
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of canary deployments using Istio routing for traffic shifting and Prometheus metrics for canary analysis.
|
||||
|
||||
@@ -74,6 +74,10 @@ spec:
|
||||
properties:
|
||||
port:
|
||||
type: number
|
||||
timeout:
|
||||
type: string
|
||||
skipAnalysis:
|
||||
type: boolean
|
||||
canaryAnalysis:
|
||||
properties:
|
||||
interval:
|
||||
@@ -90,7 +94,7 @@ spec:
|
||||
properties:
|
||||
items:
|
||||
type: object
|
||||
required: ['name', 'interval', 'threshold']
|
||||
required: ['name', 'threshold']
|
||||
properties:
|
||||
name:
|
||||
type: string
|
||||
@@ -99,6 +103,8 @@ spec:
|
||||
pattern: "^[0-9]+(m|s)"
|
||||
threshold:
|
||||
type: number
|
||||
query:
|
||||
type: string
|
||||
webhooks:
|
||||
type: array
|
||||
properties:
|
||||
|
||||
@@ -36,6 +36,9 @@ spec:
|
||||
- ./flagger
|
||||
- -log-level=info
|
||||
- -metrics-server={{ .Values.metricsServer }}
|
||||
{{- if .Values.namespace }}
|
||||
- -namespace={{ .Values.namespace }}
|
||||
{{- end }}
|
||||
{{- if .Values.slack.url }}
|
||||
- -slack-url={{ .Values.slack.url }}
|
||||
- -slack-user={{ .Values.slack.user }}
|
||||
|
||||
@@ -9,11 +9,73 @@ metadata:
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
rules:
|
||||
- apiGroups: ['*']
|
||||
resources: ['*']
|
||||
verbs: ['*']
|
||||
- nonResourceURLs: ['*']
|
||||
verbs: ['*']
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- configmaps
|
||||
- secrets
|
||||
- events
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- ""
|
||||
resources:
|
||||
- services
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- apps
|
||||
resources:
|
||||
- deployments
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- autoscaling
|
||||
resources:
|
||||
- horizontalpodautoscalers
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries/status
|
||||
verbs:
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- networking.istio.io
|
||||
resources:
|
||||
- virtualservices
|
||||
verbs:
|
||||
- create
|
||||
- get
|
||||
- patch
|
||||
- update
|
||||
- apiGroups:
|
||||
- flagger.app
|
||||
resources:
|
||||
- canaries
|
||||
verbs:
|
||||
- get
|
||||
- list
|
||||
- watch
|
||||
- nonResourceURLs:
|
||||
- /version
|
||||
verbs:
|
||||
- get
|
||||
---
|
||||
apiVersion: rbac.authorization.k8s.io/v1beta1
|
||||
kind: ClusterRoleBinding
|
||||
|
||||
@@ -2,11 +2,14 @@
|
||||
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger
|
||||
tag: 0.4.0
|
||||
tag: 0.8.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
metricsServer: "http://prometheus.istio-system.svc.cluster.local:9090"
|
||||
|
||||
# Namespace that flagger will watch for Canary objects
|
||||
namespace: ""
|
||||
|
||||
slack:
|
||||
user: flagger
|
||||
channel:
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
apiVersion: v1
|
||||
name: grafana
|
||||
version: 0.1.0
|
||||
appVersion: 5.4.2
|
||||
version: 1.0.0
|
||||
appVersion: 5.4.3
|
||||
description: Grafana dashboards for monitoring Flagger canary deployments
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
home: https://flagger.app
|
||||
|
||||
@@ -6,7 +6,7 @@ Grafana dashboards for monitoring progressive deployments powered by Istio, Prom
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* Kubernetes >= 1.9
|
||||
* Kubernetes >= 1.11
|
||||
* Istio >= 1.0
|
||||
* Prometheus >= 2.6
|
||||
|
||||
@@ -75,5 +75,5 @@ helm install flagger/grafana --name flagger-grafana -f values.yaml
|
||||
```
|
||||
|
||||
> **Tip**: You can use the default [values.yaml](values.yaml)
|
||||
```
|
||||
|
||||
|
||||
|
||||
@@ -2,7 +2,6 @@
|
||||
"annotations": {
|
||||
"list": [
|
||||
{
|
||||
"$$hashKey": "object:1587",
|
||||
"builtIn": 1,
|
||||
"datasource": "-- Grafana --",
|
||||
"enable": true,
|
||||
@@ -16,8 +15,8 @@
|
||||
"editable": true,
|
||||
"gnetId": null,
|
||||
"graphTooltip": 0,
|
||||
"id": null,
|
||||
"iteration": 1534587617141,
|
||||
"id": 1,
|
||||
"iteration": 1549736611069,
|
||||
"links": [],
|
||||
"panels": [
|
||||
{
|
||||
@@ -179,7 +178,6 @@
|
||||
"tableColumn": "",
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2857",
|
||||
"expr": "sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$primary\",response_code!~\"5.*\"}[30s])) / sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$primary\"}[30s]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -344,7 +342,6 @@
|
||||
"tableColumn": "",
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2810",
|
||||
"expr": "sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$canary\",response_code!~\"5.*\"}[30s])) / sum(irate(istio_requests_total{reporter=\"destination\",destination_workload_namespace=~\"$namespace\",destination_workload=~\"$canary\"}[30s]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -363,7 +360,7 @@
|
||||
"value": "null"
|
||||
}
|
||||
],
|
||||
"valueName": "avg"
|
||||
"valueName": "current"
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -432,6 +429,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Request Duration",
|
||||
"tooltip": {
|
||||
@@ -464,7 +462,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -533,6 +535,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Request Duration",
|
||||
"tooltip": {
|
||||
@@ -565,7 +568,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"content": "<div class=\"dashboard-header text-center\">\n<span>USE: $canary.$namespace</span>\n</div>",
|
||||
@@ -623,7 +630,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(rate(container_cpu_usage_seconds_total{cpu=\"total\",namespace=\"$namespace\",pod_name=~\"$primary.*\", container_name!~\"POD|istio-proxy\"}[1m])) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -634,6 +640,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: CPU Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -651,7 +658,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"format": "s",
|
||||
"label": "CPU seconds / second",
|
||||
"logBase": 1,
|
||||
@@ -660,7 +666,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -668,7 +673,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -711,7 +720,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(rate(container_cpu_usage_seconds_total{cpu=\"total\",namespace=\"$namespace\",pod_name=~\"$canary.*\", pod_name!~\"$primary.*\", container_name!~\"POD|istio-proxy\"}[1m])) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -722,6 +730,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: CPU Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -739,7 +748,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"format": "s",
|
||||
"label": "CPU seconds / second",
|
||||
"logBase": 1,
|
||||
@@ -748,7 +756,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -756,7 +763,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -799,7 +810,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(container_memory_working_set_bytes{namespace=\"$namespace\",pod_name=~\"$primary.*\", container_name!~\"POD|istio-proxy\"}) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -811,6 +821,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Memory Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -828,7 +839,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "bytes",
|
||||
"label": "",
|
||||
@@ -838,7 +848,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -846,7 +855,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -889,7 +902,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1685",
|
||||
"expr": "sum(container_memory_working_set_bytes{namespace=\"$namespace\",pod_name=~\"$canary.*\", pod_name!~\"$primary.*\", container_name!~\"POD|istio-proxy\"}) by (pod_name)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -901,6 +913,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Memory Usage by Pod",
|
||||
"tooltip": {
|
||||
@@ -918,7 +931,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "bytes",
|
||||
"label": "",
|
||||
@@ -928,7 +940,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -936,7 +947,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -975,12 +990,10 @@
|
||||
"renderer": "flot",
|
||||
"seriesOverrides": [
|
||||
{
|
||||
"$$hashKey": "object:3641",
|
||||
"alias": "received",
|
||||
"color": "#f9d9f9"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3649",
|
||||
"alias": "transmited",
|
||||
"color": "#f29191"
|
||||
}
|
||||
@@ -990,7 +1003,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2598",
|
||||
"expr": "sum(rate (container_network_receive_bytes_total{namespace=\"$namespace\",pod_name=~\"$primary.*\"}[1m])) ",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -998,7 +1010,6 @@
|
||||
"refId": "A"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3245",
|
||||
"expr": "-sum (rate (container_network_transmit_bytes_total{namespace=\"$namespace\",pod_name=~\"$primary.*\"}[1m]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1008,6 +1019,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Network I/O",
|
||||
"tooltip": {
|
||||
@@ -1025,7 +1037,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "Bps",
|
||||
"label": "",
|
||||
@@ -1035,7 +1046,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1043,7 +1053,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1082,12 +1096,10 @@
|
||||
"renderer": "flot",
|
||||
"seriesOverrides": [
|
||||
{
|
||||
"$$hashKey": "object:3641",
|
||||
"alias": "received",
|
||||
"color": "#f9d9f9"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3649",
|
||||
"alias": "transmited",
|
||||
"color": "#f29191"
|
||||
}
|
||||
@@ -1097,7 +1109,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:2598",
|
||||
"expr": "sum(rate (container_network_receive_bytes_total{namespace=\"$namespace\",pod_name=~\"$canary.*\",pod_name!~\"$primary.*\"}[1m])) ",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1105,7 +1116,6 @@
|
||||
"refId": "A"
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:3245",
|
||||
"expr": "-sum (rate (container_network_transmit_bytes_total{namespace=\"$namespace\",pod_name=~\"$canary.*\",pod_name!~\"$primary.*\"}[1m]))",
|
||||
"format": "time_series",
|
||||
"intervalFactor": 1,
|
||||
@@ -1115,6 +1125,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Network I/O",
|
||||
"tooltip": {
|
||||
@@ -1132,7 +1143,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1845",
|
||||
"decimals": null,
|
||||
"format": "Bps",
|
||||
"label": "",
|
||||
@@ -1142,7 +1152,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1846",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1150,7 +1159,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"content": "<div class=\"dashboard-header text-center\">\n<span>IN/OUTBOUND: $canary.$namespace</span>\n</div>",
|
||||
@@ -1205,7 +1218,6 @@
|
||||
"steppedLine": false,
|
||||
"targets": [
|
||||
{
|
||||
"$$hashKey": "object:1953",
|
||||
"expr": "round(sum(irate(istio_requests_total{connection_security_policy=\"mutual_tls\", destination_workload_namespace=~\"$namespace\", destination_workload=~\"$primary\", reporter=\"destination\"}[30s])) by (source_workload, source_workload_namespace, response_code), 0.001)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -1215,7 +1227,6 @@
|
||||
"step": 2
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:1954",
|
||||
"expr": "round(sum(irate(istio_requests_total{connection_security_policy!=\"mutual_tls\", destination_workload_namespace=~\"$namespace\", destination_workload=~\"$primary\", reporter=\"destination\"}[30s])) by (source_workload, source_workload_namespace, response_code), 0.001)",
|
||||
"format": "time_series",
|
||||
"hide": false,
|
||||
@@ -1227,6 +1238,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Incoming Requests by Source And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1246,7 +1258,6 @@
|
||||
},
|
||||
"yaxes": [
|
||||
{
|
||||
"$$hashKey": "object:1999",
|
||||
"format": "ops",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1255,7 +1266,6 @@
|
||||
"show": true
|
||||
},
|
||||
{
|
||||
"$$hashKey": "object:2000",
|
||||
"format": "short",
|
||||
"label": null,
|
||||
"logBase": 1,
|
||||
@@ -1263,7 +1273,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1323,6 +1337,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Incoming Requests by Source And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1357,7 +1372,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1416,6 +1435,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Primary: Outgoing Requests by Destination And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1450,7 +1470,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
},
|
||||
{
|
||||
"aliasColors": {},
|
||||
@@ -1509,6 +1533,7 @@
|
||||
],
|
||||
"thresholds": [],
|
||||
"timeFrom": null,
|
||||
"timeRegions": [],
|
||||
"timeShift": null,
|
||||
"title": "Canary: Outgoing Requests by Destination And Response Code",
|
||||
"tooltip": {
|
||||
@@ -1543,7 +1568,11 @@
|
||||
"min": null,
|
||||
"show": false
|
||||
}
|
||||
]
|
||||
],
|
||||
"yaxis": {
|
||||
"align": false,
|
||||
"alignLevel": null
|
||||
}
|
||||
}
|
||||
],
|
||||
"refresh": "10s",
|
||||
@@ -1555,10 +1584,12 @@
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "demo",
|
||||
"value": "demo"
|
||||
"selected": true,
|
||||
"text": "test",
|
||||
"value": "test"
|
||||
},
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Namespace",
|
||||
@@ -1568,6 +1599,7 @@
|
||||
"query": "query_result(sum(istio_requests_total) by (destination_workload_namespace) or sum(istio_tcp_sent_bytes_total) by (destination_workload_namespace))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*_namespace=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 0,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1578,10 +1610,12 @@
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "primary",
|
||||
"value": "primary"
|
||||
"selected": false,
|
||||
"text": "backend-primary",
|
||||
"value": "backend-primary"
|
||||
},
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Primary",
|
||||
@@ -1591,6 +1625,7 @@
|
||||
"query": "query_result(sum(istio_requests_total{destination_workload_namespace=~\"$namespace\"}) by (destination_service_name))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*destination_service_name=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 1,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1601,10 +1636,12 @@
|
||||
{
|
||||
"allValue": null,
|
||||
"current": {
|
||||
"text": "canary",
|
||||
"value": "canary"
|
||||
"selected": true,
|
||||
"text": "backend",
|
||||
"value": "backend"
|
||||
},
|
||||
"datasource": "prometheus",
|
||||
"definition": "",
|
||||
"hide": 0,
|
||||
"includeAll": false,
|
||||
"label": "Canary",
|
||||
@@ -1614,6 +1651,7 @@
|
||||
"query": "query_result(sum(istio_requests_total{destination_workload_namespace=~\"$namespace\"}) by (destination_service_name))",
|
||||
"refresh": 1,
|
||||
"regex": "/.*destination_service_name=\"([^\"]*).*/",
|
||||
"skipUrlSync": false,
|
||||
"sort": 1,
|
||||
"tagValuesQuery": "",
|
||||
"tags": [],
|
||||
@@ -1653,7 +1691,7 @@
|
||||
]
|
||||
},
|
||||
"timezone": "",
|
||||
"title": "Canary analysis",
|
||||
"title": "Flagger canary",
|
||||
"uid": "RdykD7tiz",
|
||||
"version": 2
|
||||
}
|
||||
"version": 3
|
||||
}
|
||||
@@ -38,12 +38,21 @@ spec:
|
||||
# path: /
|
||||
# port: http
|
||||
env:
|
||||
- name: GF_PATHS_PROVISIONING
|
||||
value: /etc/grafana/provisioning/
|
||||
{{- if .Values.password }}
|
||||
- name: GF_SECURITY_ADMIN_USER
|
||||
value: {{ .Values.user }}
|
||||
- name: GF_SECURITY_ADMIN_PASSWORD
|
||||
value: {{ .Values.password }}
|
||||
- name: GF_PATHS_PROVISIONING
|
||||
value: /etc/grafana/provisioning/
|
||||
{{- else }}
|
||||
- name: GF_AUTH_BASIC_ENABLED
|
||||
value: "false"
|
||||
- name: GF_AUTH_ANONYMOUS_ENABLED
|
||||
value: "true"
|
||||
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
|
||||
value: Admin
|
||||
{{- end }}
|
||||
volumeMounts:
|
||||
- name: grafana
|
||||
mountPath: /var/lib/grafana
|
||||
|
||||
@@ -6,7 +6,7 @@ replicaCount: 1
|
||||
|
||||
image:
|
||||
repository: grafana/grafana
|
||||
tag: 5.4.2
|
||||
tag: 5.4.3
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
service:
|
||||
@@ -28,7 +28,7 @@ tolerations: []
|
||||
affinity: {}
|
||||
|
||||
user: admin
|
||||
password: admin
|
||||
password:
|
||||
|
||||
# Istio Prometheus instance
|
||||
url: http://prometheus:9090
|
||||
|
||||
22
charts/loadtester/.helmignore
Normal file
@@ -0,0 +1,22 @@
|
||||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
.vscode/
|
||||
20
charts/loadtester/Chart.yaml
Normal file
@@ -0,0 +1,20 @@
|
||||
apiVersion: v1
|
||||
name: loadtester
|
||||
version: 0.1.0
|
||||
appVersion: 0.1.0
|
||||
kubeVersion: ">=1.11.0-0"
|
||||
engine: gotpl
|
||||
description: Flagger's load testing services based on rakyll/hey that generates traffic during canary analysis when configured as a webhook.
|
||||
home: https://docs.flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
maintainers:
|
||||
- name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
email: stefanprodan@users.noreply.github.com
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- gitops
|
||||
- load testing
|
||||
78
charts/loadtester/README.md
Normal file
@@ -0,0 +1,78 @@
|
||||
# Flagger load testing service
|
||||
|
||||
[Flagger's](https://github.com/stefanprodan/flagger) load testing service is based on
|
||||
[rakyll/hey](https://github.com/rakyll/hey)
|
||||
and can be used to generates traffic during canary analysis when configured as a webhook.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* Kubernetes >= 1.11
|
||||
* Istio >= 1.0
|
||||
|
||||
## Installing the Chart
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```console
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
To install the chart with the release name `flagger-loadtester`:
|
||||
|
||||
```console
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester
|
||||
```
|
||||
|
||||
The command deploys Grafana on the Kubernetes cluster in the default namespace.
|
||||
|
||||
> **Tip**: Note that the namespace where you deploy the load tester should have the Istio sidecar injection enabled
|
||||
|
||||
The [configuration](#configuration) section lists the parameters that can be configured during installation.
|
||||
|
||||
## Uninstalling the Chart
|
||||
|
||||
To uninstall/delete the `flagger-loadtester` deployment:
|
||||
|
||||
```console
|
||||
helm delete --purge flagger-loadtester
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
## Configuration
|
||||
|
||||
The following tables lists the configurable parameters of the load tester chart and their default values.
|
||||
|
||||
Parameter | Description | Default
|
||||
--- | --- | ---
|
||||
`image.repository` | Image repository | `quay.io/stefanprodan/flagger-loadtester`
|
||||
`image.pullPolicy` | Image pull policy | `IfNotPresent`
|
||||
`image.tag` | Image tag | `<VERSION>`
|
||||
`replicaCount` | desired number of pods | `1`
|
||||
`resources.requests.cpu` | CPU requests | `10m`
|
||||
`resources.requests.memory` | memory requests | `64Mi`
|
||||
`tolerations` | List of node taints to tolerate | `[]`
|
||||
`affinity` | node/pod affinities | `node`
|
||||
`nodeSelector` | node labels for pod assignment | `{}`
|
||||
`service.type` | type of service | `ClusterIP`
|
||||
`service.port` | ClusterIP port | `80`
|
||||
`cmd.logOutput` | Log the command output to stderr | `true`
|
||||
`cmd.timeout` | Command execution timeout | `1h`
|
||||
`logLevel` | Log level can be debug, info, warning, error or panic | `info`
|
||||
|
||||
Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example,
|
||||
|
||||
```console
|
||||
helm install flagger/loadtester --name flagger-loadtester \
|
||||
--set cmd.logOutput=false
|
||||
```
|
||||
|
||||
Alternatively, a YAML file that specifies the values for the above parameters can be provided while installing the chart. For example,
|
||||
|
||||
```console
|
||||
helm install flagger/loadtester --name flagger-loadtester -f values.yaml
|
||||
```
|
||||
|
||||
> **Tip**: You can use the default [values.yaml](values.yaml)
|
||||
|
||||
|
||||
1
charts/loadtester/templates/NOTES.txt
Normal file
@@ -0,0 +1 @@
|
||||
Flagger's load testing service is available at http://{{ include "loadtester.fullname" . }}.{{ .Release.Namespace }}/
|
||||
32
charts/loadtester/templates/_helpers.tpl
Normal file
@@ -0,0 +1,32 @@
|
||||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "loadtester.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "loadtester.fullname" -}}
|
||||
{{- if .Values.fullnameOverride -}}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- if contains $name .Release.Name -}}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "loadtester.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
66
charts/loadtester/templates/deployment.yaml
Normal file
@@ -0,0 +1,66 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: {{ include "loadtester.fullname" . }}
|
||||
labels:
|
||||
app.kubernetes.io/name: {{ include "loadtester.name" . }}
|
||||
helm.sh/chart: {{ include "loadtester.chart" . }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
spec:
|
||||
replicas: {{ .Values.replicaCount }}
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ include "loadtester.name" . }}
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ include "loadtester.name" . }}
|
||||
spec:
|
||||
containers:
|
||||
- name: {{ .Chart.Name }}
|
||||
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
|
||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 8080
|
||||
command:
|
||||
- ./loadtester
|
||||
- -port=8080
|
||||
- -log-level={{ .Values.logLevel }}
|
||||
- -timeout={{ .Values.cmd.timeout }}
|
||||
- -log-cmd-output={{ .Values.cmd.logOutput }}
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
resources:
|
||||
{{- toYaml .Values.resources | nindent 12 }}
|
||||
{{- with .Values.nodeSelector }}
|
||||
nodeSelector:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.affinity }}
|
||||
affinity:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.tolerations }}
|
||||
tolerations:
|
||||
{{- toYaml . | nindent 8 }}
|
||||
{{- end }}
|
||||
18
charts/loadtester/templates/service.yaml
Normal file
@@ -0,0 +1,18 @@
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: {{ include "loadtester.fullname" . }}
|
||||
labels:
|
||||
app.kubernetes.io/name: {{ include "loadtester.name" . }}
|
||||
helm.sh/chart: {{ include "loadtester.chart" . }}
|
||||
app.kubernetes.io/instance: {{ .Release.Name }}
|
||||
app.kubernetes.io/managed-by: {{ .Release.Service }}
|
||||
spec:
|
||||
type: {{ .Values.service.type }}
|
||||
ports:
|
||||
- port: {{ .Values.service.port }}
|
||||
targetPort: http
|
||||
protocol: TCP
|
||||
name: http
|
||||
selector:
|
||||
app: {{ include "loadtester.name" . }}
|
||||
29
charts/loadtester/values.yaml
Normal file
@@ -0,0 +1,29 @@
|
||||
replicaCount: 1
|
||||
|
||||
image:
|
||||
repository: quay.io/stefanprodan/flagger-loadtester
|
||||
tag: 0.1.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
logLevel: info
|
||||
cmd:
|
||||
logOutput: true
|
||||
timeout: 1h
|
||||
|
||||
nameOverride: ""
|
||||
fullnameOverride: ""
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 80
|
||||
|
||||
resources:
|
||||
requests:
|
||||
cpu: 10m
|
||||
memory: 64Mi
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
21
charts/podinfo/.helmignore
Normal file
@@ -0,0 +1,21 @@
|
||||
# Patterns to ignore when building packages.
|
||||
# This supports shell glob matching, relative path matching, and
|
||||
# negation (prefixed with !). Only one pattern per line.
|
||||
.DS_Store
|
||||
# Common VCS dirs
|
||||
.git/
|
||||
.gitignore
|
||||
.bzr/
|
||||
.bzrignore
|
||||
.hg/
|
||||
.hgignore
|
||||
.svn/
|
||||
# Common backup files
|
||||
*.swp
|
||||
*.bak
|
||||
*.tmp
|
||||
*~
|
||||
# Various IDEs
|
||||
.project
|
||||
.idea/
|
||||
*.tmproj
|
||||
12
charts/podinfo/Chart.yaml
Normal file
@@ -0,0 +1,12 @@
|
||||
apiVersion: v1
|
||||
version: 2.0.0
|
||||
appVersion: 1.4.0
|
||||
name: podinfo
|
||||
engine: gotpl
|
||||
description: Flagger canary deployment demo chart
|
||||
home: https://github.com/stefanprodan/flagger
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
79
charts/podinfo/README.md
Normal file
@@ -0,0 +1,79 @@
|
||||
# Podinfo
|
||||
|
||||
Podinfo is a tiny web application made with Go
|
||||
that showcases best practices of running canary deployments with Flagger and Istio.
|
||||
|
||||
## Installing the Chart
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```console
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
To install the chart with the release name `frontend`:
|
||||
|
||||
```console
|
||||
helm upgrade -i frontend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=frontend \
|
||||
--set backend=http://backend.test:9898/echo \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=true \
|
||||
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
||||
--set canary.istioIngress.host=frontend.istio.example.com
|
||||
```
|
||||
|
||||
To install the chart as `backend`:
|
||||
|
||||
```console
|
||||
helm upgrade -i backend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=backend \
|
||||
--set canary.enabled=true
|
||||
```
|
||||
|
||||
## Uninstalling the Chart
|
||||
|
||||
To uninstall/delete the `frontend` deployment:
|
||||
|
||||
```console
|
||||
$ helm delete --purge frontend
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
## Configuration
|
||||
|
||||
The following tables lists the configurable parameters of the podinfo chart and their default values.
|
||||
|
||||
Parameter | Description | Default
|
||||
--- | --- | ---
|
||||
`image.repository` | image repository | `quay.io/stefanprodan/podinfo`
|
||||
`image.tag` | image tag | `<VERSION>`
|
||||
`image.pullPolicy` | image pull policy | `IfNotPresent`
|
||||
`hpa.enabled` | enables HPA | `true`
|
||||
`hpa.cpu` | target CPU usage per pod | `80`
|
||||
`hpa.memory` | target memory usage per pod | `512Mi`
|
||||
`hpa.minReplicas` | maximum pod replicas | `2`
|
||||
`hpa.maxReplicas` | maximum pod replicas | `4`
|
||||
`resources.requests/cpu` | pod CPU request | `1m`
|
||||
`resources.requests/memory` | pod memory request | `16Mi`
|
||||
`backend` | backend URL | None
|
||||
`faults.delay` | random HTTP response delays between 0 and 5 seconds | `false`
|
||||
`faults.error` | 1/3 chances of a random HTTP response error | `false`
|
||||
|
||||
Specify each parameter using the `--set key=value[,key=value]` argument to `helm install`. For example,
|
||||
|
||||
```console
|
||||
$ helm install flagger/podinfo --name frontend \
|
||||
--set=image.tag=1.4.1,hpa.enabled=false
|
||||
```
|
||||
|
||||
Alternatively, a YAML file that specifies the values for the above parameters can be provided while installing the chart. For example,
|
||||
|
||||
```console
|
||||
$ helm install flagger/podinfo --name frontend -f values.yaml
|
||||
```
|
||||
|
||||
|
||||
1
charts/podinfo/templates/NOTES.txt
Normal file
@@ -0,0 +1 @@
|
||||
podinfo {{ .Release.Name }} deployed!
|
||||
43
charts/podinfo/templates/_helpers.tpl
Normal file
@@ -0,0 +1,43 @@
|
||||
{{/* vim: set filetype=mustache: */}}
|
||||
{{/*
|
||||
Expand the name of the chart.
|
||||
*/}}
|
||||
{{- define "podinfo.name" -}}
|
||||
{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create a default fully qualified app name.
|
||||
We truncate at 63 chars because some Kubernetes name fields are limited to this (by the DNS naming spec).
|
||||
If release name contains chart name it will be used as a full name.
|
||||
*/}}
|
||||
{{- define "podinfo.fullname" -}}
|
||||
{{- if .Values.fullnameOverride -}}
|
||||
{{- .Values.fullnameOverride | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- $name := default .Chart.Name .Values.nameOverride -}}
|
||||
{{- if contains $name .Release.Name -}}
|
||||
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- else -}}
|
||||
{{- printf "%s-%s" .Release.Name $name | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name and version as used by the chart label.
|
||||
*/}}
|
||||
{{- define "podinfo.chart" -}}
|
||||
{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}
|
||||
{{- end -}}
|
||||
|
||||
{{/*
|
||||
Create chart name suffix.
|
||||
*/}}
|
||||
{{- define "podinfo.suffix" -}}
|
||||
{{- if .Values.canary.enabled -}}
|
||||
{{- "-primary" -}}
|
||||
{{- else -}}
|
||||
{{- "" -}}
|
||||
{{- end -}}
|
||||
{{- end -}}
|
||||
54
charts/podinfo/templates/canary.yaml
Normal file
@@ -0,0 +1,54 @@
|
||||
{{- if .Values.canary.enabled }}
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
progressDeadlineSeconds: 60
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
service:
|
||||
port: {{ .Values.service.port }}
|
||||
{{- if .Values.canary.istioIngress.enabled }}
|
||||
gateways:
|
||||
- {{ .Values.canary.istioIngress.gateway }}
|
||||
hosts:
|
||||
- {{ .Values.canary.istioIngress.host }}
|
||||
{{- end }}
|
||||
canaryAnalysis:
|
||||
interval: {{ .Values.canary.analysis.interval }}
|
||||
threshold: {{ .Values.canary.analysis.threshold }}
|
||||
maxWeight: {{ .Values.canary.analysis.maxWeight }}
|
||||
stepWeight: {{ .Values.canary.analysis.stepWeight }}
|
||||
metrics:
|
||||
- name: istio_requests_total
|
||||
threshold: {{ .Values.canary.thresholds.successRate }}
|
||||
interval: 1m
|
||||
- name: istio_request_duration_seconds_bucket
|
||||
threshold: {{ .Values.canary.thresholds.latency }}
|
||||
interval: 1m
|
||||
{{- if .Values.canary.loadtest.enabled }}
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: {{ .Values.canary.loadtest.url }}
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 http://{{ template "podinfo.fullname" . }}.{{ .Release.Namespace }}:{{ .Values.service.port }}"
|
||||
- name: load-test-post
|
||||
url: {{ .Values.canary.loadtest.url }}
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 -m POST -d '{\"test\": true}' http://{{ template "podinfo.fullname" . }}.{{ .Release.Namespace }}:{{ .Values.service.port }}/echo"
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
15
charts/podinfo/templates/configmap.yaml
Normal file
@@ -0,0 +1,15 @@
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
data:
|
||||
config.yaml: |-
|
||||
# http settings
|
||||
http-client-timeout: 1m
|
||||
http-server-timeout: {{ .Values.httpServer.timeout }}
|
||||
http-server-shutdown-timeout: 5s
|
||||
93
charts/podinfo/templates/deployment.yaml
Normal file
@@ -0,0 +1,93 @@
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
annotations:
|
||||
prometheus.io/scrape: 'true'
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 30
|
||||
containers:
|
||||
- name: {{ .Chart.Name }}
|
||||
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
|
||||
imagePullPolicy: {{ .Values.image.pullPolicy }}
|
||||
command:
|
||||
- ./podinfo
|
||||
- --port={{ .Values.service.port }}
|
||||
- --level={{ .Values.logLevel }}
|
||||
- --random-delay={{ .Values.faults.delay }}
|
||||
- --random-error={{ .Values.faults.error }}
|
||||
- --config-path=/podinfo/config
|
||||
env:
|
||||
{{- if .Values.message }}
|
||||
- name: PODINFO_UI_MESSAGE
|
||||
value: {{ .Values.message }}
|
||||
{{- end }}
|
||||
{{- if .Values.backend }}
|
||||
- name: PODINFO_BACKEND_URL
|
||||
value: {{ .Values.backend }}
|
||||
{{- end }}
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: {{ .Values.service.port }}
|
||||
protocol: TCP
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:{{ .Values.service.port }}/healthz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- podcli
|
||||
- check
|
||||
- http
|
||||
- localhost:{{ .Values.service.port }}/readyz
|
||||
initialDelaySeconds: 5
|
||||
timeoutSeconds: 5
|
||||
volumeMounts:
|
||||
- name: data
|
||||
mountPath: /data
|
||||
- name: config
|
||||
mountPath: /podinfo/config
|
||||
readOnly: true
|
||||
resources:
|
||||
{{ toYaml .Values.resources | indent 12 }}
|
||||
{{- with .Values.nodeSelector }}
|
||||
nodeSelector:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.affinity }}
|
||||
affinity:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
{{- with .Values.tolerations }}
|
||||
tolerations:
|
||||
{{ toYaml . | indent 8 }}
|
||||
{{- end }}
|
||||
volumes:
|
||||
- name: data
|
||||
emptyDir: {}
|
||||
- name: config
|
||||
configMap:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
37
charts/podinfo/templates/hpa.yaml
Normal file
@@ -0,0 +1,37 @@
|
||||
{{- if .Values.hpa.enabled -}}
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1beta2
|
||||
kind: Deployment
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
minReplicas: {{ .Values.hpa.minReplicas }}
|
||||
maxReplicas: {{ .Values.hpa.maxReplicas }}
|
||||
metrics:
|
||||
{{- if .Values.hpa.cpu }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageUtilization: {{ .Values.hpa.cpu }}
|
||||
{{- end }}
|
||||
{{- if .Values.hpa.memory }}
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageValue: {{ .Values.hpa.memory }}
|
||||
{{- end }}
|
||||
{{- if .Values.hpa.requests }}
|
||||
- type: Pod
|
||||
pods:
|
||||
metricName: http_requests
|
||||
targetAverageValue: {{ .Values.hpa.requests }}
|
||||
{{- end }}
|
||||
{{- end }}
|
||||
20
charts/podinfo/templates/service.yaml
Normal file
@@ -0,0 +1,20 @@
|
||||
{{- if not .Values.canary.enabled }}
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}
|
||||
labels:
|
||||
app: {{ template "podinfo.name" . }}
|
||||
chart: {{ template "podinfo.chart" . }}
|
||||
release: {{ .Release.Name }}
|
||||
heritage: {{ .Release.Service }}
|
||||
spec:
|
||||
type: {{ .Values.service.type }}
|
||||
ports:
|
||||
- port: {{ .Values.service.port }}
|
||||
targetPort: http
|
||||
protocol: TCP
|
||||
name: http
|
||||
selector:
|
||||
app: {{ template "podinfo.fullname" . }}
|
||||
{{- end }}
|
||||
22
charts/podinfo/templates/tests/test-config.yaml
Executable file
@@ -0,0 +1,22 @@
|
||||
{{- $url := printf "%s%s.%s:%v" (include "podinfo.fullname" .) (include "podinfo.suffix" .) .Release.Namespace .Values.service.port -}}
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}-tests
|
||||
labels:
|
||||
heritage: {{ .Release.Service }}
|
||||
release: {{ .Release.Name }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
|
||||
app: {{ template "podinfo.name" . }}
|
||||
data:
|
||||
run.sh: |-
|
||||
@test "HTTP POST /echo" {
|
||||
run curl --retry 3 --connect-timeout 2 -sSX POST -d 'test' {{ $url }}/echo
|
||||
[ $output = "test" ]
|
||||
}
|
||||
@test "HTTP POST /store" {
|
||||
curl --retry 3 --connect-timeout 2 -sSX POST -d 'test' {{ $url }}/store
|
||||
}
|
||||
@test "HTTP GET /" {
|
||||
curl --retry 3 --connect-timeout 2 -sS {{ $url }} | grep hostname
|
||||
}
|
||||
43
charts/podinfo/templates/tests/test-pod.yaml
Executable file
@@ -0,0 +1,43 @@
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: {{ template "podinfo.fullname" . }}-tests-{{ randAlphaNum 5 | lower }}
|
||||
annotations:
|
||||
"helm.sh/hook": test-success
|
||||
sidecar.istio.io/inject: "false"
|
||||
labels:
|
||||
heritage: {{ .Release.Service }}
|
||||
release: {{ .Release.Name }}
|
||||
chart: {{ .Chart.Name }}-{{ .Chart.Version }}
|
||||
app: {{ template "podinfo.name" . }}
|
||||
spec:
|
||||
initContainers:
|
||||
- name: "test-framework"
|
||||
image: "dduportal/bats:0.4.0"
|
||||
command:
|
||||
- "bash"
|
||||
- "-c"
|
||||
- |
|
||||
set -ex
|
||||
# copy bats to tools dir
|
||||
cp -R /usr/local/libexec/ /tools/bats/
|
||||
volumeMounts:
|
||||
- mountPath: /tools
|
||||
name: tools
|
||||
containers:
|
||||
- name: {{ .Release.Name }}-ui-test
|
||||
image: dduportal/bats:0.4.0
|
||||
command: ["/tools/bats/bats", "-t", "/tests/run.sh"]
|
||||
volumeMounts:
|
||||
- mountPath: /tests
|
||||
name: tests
|
||||
readOnly: true
|
||||
- mountPath: /tools
|
||||
name: tools
|
||||
volumes:
|
||||
- name: tests
|
||||
configMap:
|
||||
name: {{ template "podinfo.fullname" . }}-tests
|
||||
- name: tools
|
||||
emptyDir: {}
|
||||
restartPolicy: Never
|
||||
73
charts/podinfo/values.yaml
Normal file
@@ -0,0 +1,73 @@
|
||||
# Default values for podinfo.
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
pullPolicy: IfNotPresent
|
||||
|
||||
service:
|
||||
type: ClusterIP
|
||||
port: 9898
|
||||
|
||||
hpa:
|
||||
enabled: true
|
||||
minReplicas: 2
|
||||
maxReplicas: 2
|
||||
cpu: 80
|
||||
memory: 512Mi
|
||||
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: false
|
||||
# Istio ingress gateway name
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
# external host name eg. podinfo.example.com
|
||||
host:
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 15s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
thresholds:
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
successRate: 99
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
latency: 500
|
||||
loadtest:
|
||||
enabled: false
|
||||
# load tester address
|
||||
url: http://flagger-loadtester.test/
|
||||
|
||||
resources:
|
||||
limits:
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 32Mi
|
||||
|
||||
nodeSelector: {}
|
||||
|
||||
tolerations: []
|
||||
|
||||
affinity: {}
|
||||
|
||||
nameOverride: ""
|
||||
fullnameOverride: ""
|
||||
|
||||
logLevel: info
|
||||
backend: #http://backend-podinfo:9898/echo
|
||||
message: #UI greetings
|
||||
|
||||
faults:
|
||||
delay: false
|
||||
error: false
|
||||
|
||||
httpServer:
|
||||
timeout: 30s
|
||||
@@ -2,23 +2,22 @@ package main
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"log"
|
||||
"time"
|
||||
|
||||
_ "github.com/istio/glog"
|
||||
istioclientset "github.com/knative/pkg/client/clientset/versioned"
|
||||
"github.com/knative/pkg/signals"
|
||||
clientset "github.com/stefanprodan/flagger/pkg/client/clientset/versioned"
|
||||
informers "github.com/stefanprodan/flagger/pkg/client/informers/externalversions"
|
||||
"github.com/stefanprodan/flagger/pkg/controller"
|
||||
"github.com/stefanprodan/flagger/pkg/logging"
|
||||
"github.com/stefanprodan/flagger/pkg/notifier"
|
||||
"github.com/stefanprodan/flagger/pkg/server"
|
||||
"github.com/stefanprodan/flagger/pkg/signals"
|
||||
"github.com/stefanprodan/flagger/pkg/version"
|
||||
"go.uber.org/zap"
|
||||
"k8s.io/client-go/kubernetes"
|
||||
_ "k8s.io/client-go/plugin/pkg/client/auth/gcp"
|
||||
"k8s.io/client-go/tools/cache"
|
||||
"k8s.io/client-go/tools/clientcmd"
|
||||
"log"
|
||||
"time"
|
||||
)
|
||||
|
||||
var (
|
||||
@@ -31,6 +30,10 @@ var (
|
||||
slackURL string
|
||||
slackUser string
|
||||
slackChannel string
|
||||
threadiness int
|
||||
zapReplaceGlobals bool
|
||||
zapEncoding string
|
||||
namespace string
|
||||
)
|
||||
|
||||
func init() {
|
||||
@@ -43,15 +46,23 @@ func init() {
|
||||
flag.StringVar(&slackURL, "slack-url", "", "Slack hook URL.")
|
||||
flag.StringVar(&slackUser, "slack-user", "flagger", "Slack user name.")
|
||||
flag.StringVar(&slackChannel, "slack-channel", "", "Slack channel.")
|
||||
flag.IntVar(&threadiness, "threadiness", 2, "Worker concurrency.")
|
||||
flag.BoolVar(&zapReplaceGlobals, "zap-replace-globals", false, "Whether to change the logging level of the global zap logger.")
|
||||
flag.StringVar(&zapEncoding, "zap-encoding", "json", "Zap logger encoding.")
|
||||
flag.StringVar(&namespace, "namespace", "", "Namespace that flagger would watch canary object")
|
||||
}
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
logger, err := logging.NewLogger(logLevel)
|
||||
logger, err := logging.NewLoggerWithEncoding(logLevel, zapEncoding)
|
||||
if err != nil {
|
||||
log.Fatalf("Error creating logger: %v", err)
|
||||
}
|
||||
if zapReplaceGlobals {
|
||||
zap.ReplaceGlobals(logger.Desugar())
|
||||
}
|
||||
|
||||
defer logger.Sync()
|
||||
|
||||
stopCh := signals.SetupSignalHandler()
|
||||
@@ -66,7 +77,7 @@ func main() {
|
||||
logger.Fatalf("Error building kubernetes clientset: %v", err)
|
||||
}
|
||||
|
||||
istioClient, err := istioclientset.NewForConfig(cfg)
|
||||
istioClient, err := clientset.NewForConfig(cfg)
|
||||
if err != nil {
|
||||
logger.Fatalf("Error building istio clientset: %v", err)
|
||||
}
|
||||
@@ -76,7 +87,14 @@ func main() {
|
||||
logger.Fatalf("Error building example clientset: %s", err.Error())
|
||||
}
|
||||
|
||||
flaggerInformerFactory := informers.NewSharedInformerFactory(flaggerClient, time.Second*30)
|
||||
if namespace == "" {
|
||||
logger.Infof("Flagger Canary's Watcher is on all namespace")
|
||||
} else {
|
||||
logger.Infof("Flagger Canary's Watcher is on namespace %s", namespace)
|
||||
}
|
||||
|
||||
flaggerInformerFactory := informers.NewSharedInformerFactoryWithOptions(flaggerClient, time.Second*30, informers.WithNamespace(namespace))
|
||||
|
||||
canaryInformer := flaggerInformerFactory.Flagger().V1alpha3().Canaries()
|
||||
|
||||
logger.Infof("Starting flagger version %s revision %s", version.VERSION, version.REVISION)
|
||||
@@ -132,7 +150,7 @@ func main() {
|
||||
|
||||
// start controller
|
||||
go func(ctrl *controller.Controller) {
|
||||
if err := ctrl.Run(2, stopCh); err != nil {
|
||||
if err := ctrl.Run(threadiness, stopCh); err != nil {
|
||||
logger.Fatalf("Error running controller: %v", err)
|
||||
}
|
||||
}(c)
|
||||
|
||||
53
cmd/loadtester/main.go
Normal file
@@ -0,0 +1,53 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"github.com/stefanprodan/flagger/pkg/loadtester"
|
||||
"github.com/stefanprodan/flagger/pkg/logging"
|
||||
"github.com/stefanprodan/flagger/pkg/signals"
|
||||
"go.uber.org/zap"
|
||||
"log"
|
||||
"time"
|
||||
)
|
||||
|
||||
var VERSION = "0.1.0"
|
||||
var (
|
||||
logLevel string
|
||||
port string
|
||||
timeout time.Duration
|
||||
logCmdOutput bool
|
||||
zapReplaceGlobals bool
|
||||
zapEncoding string
|
||||
)
|
||||
|
||||
func init() {
|
||||
flag.StringVar(&logLevel, "log-level", "debug", "Log level can be: debug, info, warning, error.")
|
||||
flag.StringVar(&port, "port", "9090", "Port to listen on.")
|
||||
flag.DurationVar(&timeout, "timeout", time.Hour, "Command exec timeout.")
|
||||
flag.BoolVar(&logCmdOutput, "log-cmd-output", true, "Log command output to stderr")
|
||||
flag.BoolVar(&zapReplaceGlobals, "zap-replace-globals", false, "Whether to change the logging level of the global zap logger.")
|
||||
flag.StringVar(&zapEncoding, "zap-encoding", "json", "Zap logger encoding.")
|
||||
}
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
logger, err := logging.NewLoggerWithEncoding(logLevel, zapEncoding)
|
||||
if err != nil {
|
||||
log.Fatalf("Error creating logger: %v", err)
|
||||
}
|
||||
if zapReplaceGlobals {
|
||||
zap.ReplaceGlobals(logger.Desugar())
|
||||
}
|
||||
|
||||
defer logger.Sync()
|
||||
|
||||
stopCh := signals.SetupSignalHandler()
|
||||
|
||||
taskRunner := loadtester.NewTaskRunner(logger, timeout, logCmdOutput)
|
||||
|
||||
go taskRunner.Start(100*time.Millisecond, stopCh)
|
||||
|
||||
logger.Infof("Starting load tester v%s API on port %s", VERSION, port)
|
||||
loadtester.ListenAndServe(port, time.Minute, logger, taskRunner, stopCh)
|
||||
}
|
||||
@@ -1 +0,0 @@
|
||||
flagger.app
|
||||
@@ -1,11 +0,0 @@
|
||||
# Flagger
|
||||
|
||||
Flagger is a Kubernetes operator that automates the promotion of canary deployments using Istio routing for traffic
|
||||
shifting and Prometheus metrics for canary analysis.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pods health. Based on the KPIs analysis
|
||||
a canary is promoted or aborted and the analysis result is published to Slack.
|
||||
|
||||
### For the install instructions and usage examples please see [docs.flagger.app](https://docs.flagger.app)
|
||||
|
||||
@@ -1,55 +0,0 @@
|
||||
title: Flagger - Istio Progressive Delivery Kubernetes Operator
|
||||
|
||||
remote_theme: errordeveloper/simple-project-homepage
|
||||
repository: stefanprodan/flagger
|
||||
by_weaveworks: true
|
||||
|
||||
url: "https://flagger.app"
|
||||
baseurl: "/"
|
||||
|
||||
twitter:
|
||||
username: "stefanprodan"
|
||||
author:
|
||||
twitter: "stefanprodan"
|
||||
|
||||
# Set default og:image
|
||||
defaults:
|
||||
- scope: {path: ""}
|
||||
values: {image: "diagrams/flagger-overview.png"}
|
||||
|
||||
# See: https://material.io/guidelines/style/color.html
|
||||
# Use color-name-value, like pink-200 or deep-purple-100
|
||||
brand_color: "amber-400"
|
||||
|
||||
# How article URLs are structured.
|
||||
# See: https://jekyllrb.com/docs/permalinks/
|
||||
permalink: posts/:title/
|
||||
|
||||
# "UA-NNNNNNNN-N"
|
||||
google_analytics: ""
|
||||
|
||||
# Language. For example, if you write in Japanese, use "ja"
|
||||
lang: "en"
|
||||
|
||||
# How many posts are visible on the home page without clicking "View More"
|
||||
num_posts_visible_initially: 5
|
||||
|
||||
# Date format: See http://strftime.net/
|
||||
date_format: "%b %-d, %Y"
|
||||
|
||||
plugins:
|
||||
- jekyll-feed
|
||||
- jekyll-readme-index
|
||||
- jekyll-seo-tag
|
||||
- jekyll-sitemap
|
||||
- jemoji
|
||||
# # required for local builds with starefossen/github-pages
|
||||
# - jekyll-github-metadata
|
||||
# - jekyll-mentions
|
||||
# - jekyll-redirect-from
|
||||
# - jekyll-remote-theme
|
||||
|
||||
exclude:
|
||||
- CNAME
|
||||
- gitbook
|
||||
|
||||
BIN
docs/diagrams/flagger-flux-gitops.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 130 KiB |
BIN
docs/diagrams/flagger-gke-istio.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 196 KiB |
BIN
docs/diagrams/flagger-load-testing.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 159 KiB |
BIN
docs/diagrams/istio-cert-manager-gke.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 205 KiB |
@@ -6,16 +6,16 @@ description: Flagger is an Istio progressive delivery Kubernetes operator
|
||||
|
||||
[Flagger](https://github.com/stefanprodan/flagger) is a **Kubernetes** operator that automates the promotion of canary
|
||||
deployments using **Istio** routing for traffic shifting and **Prometheus** metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running integration tests,
|
||||
load tests or any other custom validation.
|
||||
The canary analysis can be extended with webhooks for running
|
||||
system integration/acceptance tests, load tests, or any other custom validation.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pods health.
|
||||
Based on the **KPIs** analysis a canary is promoted or aborted and the analysis result is published to **Slack**.
|
||||
Based on analysis of the **KPIs** a canary is promoted or aborted, and the analysis result is published to **Slack**.
|
||||
|
||||

|
||||
|
||||
Flagger can be configured with Kubernetes custom resources \(canaries.flagger.app kind\) and is compatible with
|
||||
Flagger can be configured with Kubernetes custom resources and is compatible with
|
||||
any CI/CD solutions made for Kubernetes. Since Flagger is declarative and reacts to Kubernetes events,
|
||||
it can be used in **GitOps** pipelines together with Weave Flux or JenkinsX.
|
||||
|
||||
|
||||
@@ -5,9 +5,8 @@
|
||||
|
||||
## Install
|
||||
|
||||
* [Install Flagger](install/install-flagger.md)
|
||||
* [Install Grafana](install/install-grafana.md)
|
||||
* [Install Istio](install/install-istio.md)
|
||||
* [Flagger Install on Kubernetes](install/flagger-install-on-kubernetes.md)
|
||||
* [Flagger Install on Google Cloud](install/flagger-install-on-google-cloud.md)
|
||||
|
||||
## Usage
|
||||
|
||||
@@ -15,3 +14,7 @@
|
||||
* [Monitoring](usage/monitoring.md)
|
||||
* [Alerting](usage/alerting.md)
|
||||
|
||||
## Tutorials
|
||||
|
||||
* [Canaries with Helm charts and GitOps](tutorials/canary-helm-gitops.md)
|
||||
* [Zero downtime deployments](tutorials/zero-downtime-deployments.md)
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
# How it works
|
||||
|
||||
[Flagger](https://github.com/stefanprodan/flagger) takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\) and creates a series of objects \(Kubernetes deployments, ClusterIP services and Istio virtual services\) to drive the canary analysis and promotion.
|
||||
[Flagger](https://github.com/stefanprodan/flagger) takes a Kubernetes deployment and optionally
|
||||
a horizontal pod autoscaler \(HPA\) and creates a series of objects
|
||||
\(Kubernetes deployments, ClusterIP services and Istio virtual services\) to drive the canary analysis and promotion.
|
||||
|
||||
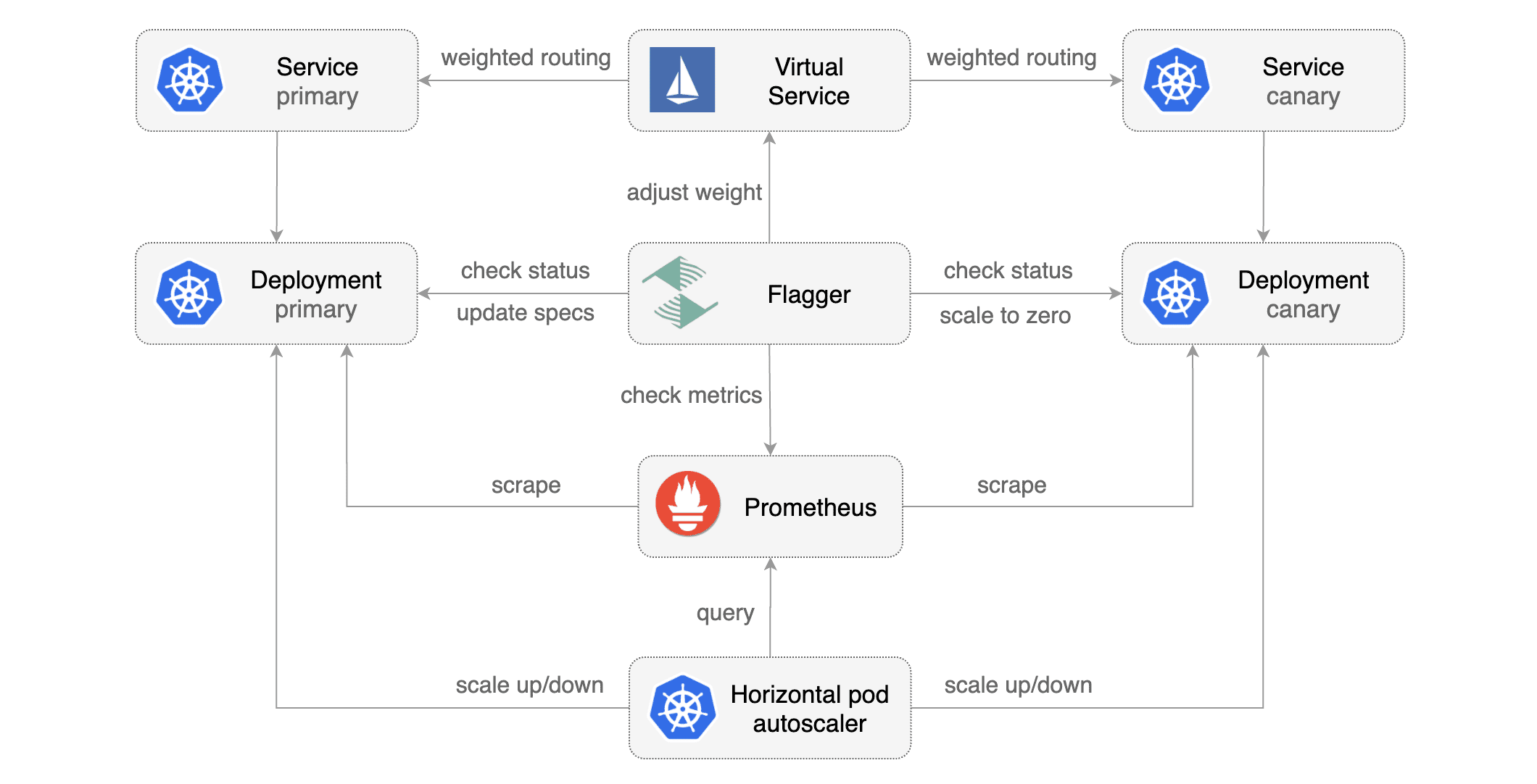
|
||||
|
||||
@@ -37,6 +39,9 @@ spec:
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- podinfo.example.com
|
||||
# promote the canary without analysing it (default false)
|
||||
skipAnalysis: false
|
||||
# define the canary analysis timing and KPIs
|
||||
canaryAnalysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
@@ -91,41 +96,195 @@ spec:
|
||||
The target deployment should expose a TCP port that will be used by Flagger to create the ClusterIP Service and
|
||||
the Istio Virtual Service. The container port from the target deployment should match the `service.port` value.
|
||||
|
||||
### Canary Deployment
|
||||
### Istio routing
|
||||
|
||||
Flagger creates an Istio Virtual Service based on the Canary service spec. The service configuration lets you expose
|
||||
an app inside or outside the mesh.
|
||||
You can also define HTTP match conditions, URI rewrite rules, CORS policies, timeout and retries.
|
||||
|
||||
The following spec exposes the `frontend` workload inside the mesh on `frontend.test.svc.cluster.local:9898`
|
||||
and outside the mesh on `frontend.example.com`. You'll have to specify an Istio ingress gateway for external hosts.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Envoy timeout and retry policy (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
# cross-origin resource sharing policy (optional)
|
||||
corsPolicy:
|
||||
allowOrigin:
|
||||
- example.com
|
||||
allowMethods:
|
||||
- GET
|
||||
allowCredentials: false
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
maxAge: 24h
|
||||
```
|
||||
|
||||
For the above spec Flagger will generate the following virtual service:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1alpha3
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: podinfo
|
||||
uid: 3a4a40dd-3875-11e9-8e1d-42010a9c0fd1
|
||||
spec:
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
- frontend
|
||||
http:
|
||||
- appendHeaders:
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: gateway-error,connect-failure,refused-stream
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
corsPolicy:
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
allowMethods:
|
||||
- GET
|
||||
allowOrigin:
|
||||
- example.com
|
||||
maxAge: 24h
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
rewrite:
|
||||
uri: /
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
port:
|
||||
number: 9898
|
||||
weight: 100
|
||||
- destination:
|
||||
host: podinfo-canary
|
||||
port:
|
||||
number: 9898
|
||||
weight: 0
|
||||
```
|
||||
|
||||
Flagger keeps in sync the virtual service with the canary service spec. Any direct modification to the virtual
|
||||
service spec will be overwritten.
|
||||
|
||||
To expose a workload inside the mesh on `http://backend.test.svc.cluster.local:9898`,
|
||||
the service spec can contain only the container port:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: backend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
```
|
||||
|
||||
Based on the above spec, Flagger will create several ClusterIP services like:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: backend-primary
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1alpha3
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: backend
|
||||
uid: 2ca1a9c7-2ef6-11e9-bd01-42010a9c0145
|
||||
spec:
|
||||
type: ClusterIP
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: 9898
|
||||
selector:
|
||||
app: backend-primary
|
||||
```
|
||||
|
||||
Flagger works for user facing apps exposed outside the cluster via an ingress gateway
|
||||
and for backend HTTP APIs that are accessible only from inside the mesh.
|
||||
|
||||
### Canary Stages
|
||||
|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* ConfigMaps mounted as volumes or mapped to environment variables
|
||||
* Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Gated canary promotion stages:
|
||||
|
||||
* scan for canary deployments
|
||||
* creates the primary deployment if needed
|
||||
* check Istio virtual service routes are mapped to primary and canary ClusterIP services
|
||||
* check primary and canary deployments status
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* increase canary traffic weight percentage from 0% to 5% \(step weight\)
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* increase canary traffic weight percentage from 0% to 5% (step weight)
|
||||
* call webhooks and check results
|
||||
* check canary HTTP request success rate and latency
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* check if the number of failed checks reached the threshold
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* wait for the canary deployment to be updated \(revision bump\) and start over
|
||||
* increase canary traffic weight by 5% \(step weight\) till it reaches 50% \(max weight\)
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
* halt advancement while canary deployment is being scaled up/down by HPA
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* wait for the canary deployment to be updated and start over
|
||||
* increase canary traffic weight by 5% (step weight) till it reaches 50% (max weight)
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
* halt advancement while canary deployment is being scaled up/down by HPA
|
||||
* promote canary to primary
|
||||
* copy canary deployment spec template over primary
|
||||
* copy ConfigMaps and Secrets from canary to primary
|
||||
* copy canary deployment spec template over primary
|
||||
* wait for primary rolling update to finish
|
||||
* halt advancement if pods are unhealthy
|
||||
* halt advancement if pods are unhealthy
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment
|
||||
* mark the canary deployment as finished
|
||||
* wait for the canary deployment to be updated \(revision bump\) and start over
|
||||
|
||||
You can change the canary analysis _max weight_ and the _step weight_ percentage in the Flagger's custom resource.
|
||||
* mark rollout as finished
|
||||
* wait for the canary deployment to be updated and start over
|
||||
|
||||
### Canary Analysis
|
||||
|
||||
@@ -145,6 +304,9 @@ Spec:
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 2
|
||||
# deploy straight to production without
|
||||
# the metrics and webhook checks
|
||||
skipAnalysis: false
|
||||
```
|
||||
|
||||
The above analysis, if it succeeds, will run for 25 minutes while validating the HTTP metrics and webhooks every minute.
|
||||
@@ -160,6 +322,11 @@ And the time it takes for a canary to be rollback when the metrics or webhook ch
|
||||
interval * threshold
|
||||
```
|
||||
|
||||
In emergency cases, you may want to skip the analysis phase and ship changes directly to production.
|
||||
At any time you can set the `spec.skipAnalysis: true`.
|
||||
When skip analysis is enabled, Flagger checks if the canary deployment is healthy and
|
||||
promotes it without analysing it. If an analysis is underway, Flagger cancels it and runs the promotion.
|
||||
|
||||
### HTTP Metrics
|
||||
|
||||
The canary analysis is using the following Prometheus queries:
|
||||
@@ -235,6 +402,49 @@ histogram_quantile(0.99,
|
||||
|
||||
> **Note** that the metric interval should be lower or equal to the control loop interval.
|
||||
|
||||
### Custom Metrics
|
||||
|
||||
The canary analysis can be extended with custom Prometheus queries.
|
||||
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
threshold: 1
|
||||
maxWeight: 50
|
||||
stepWeight: 5
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
threshold: 5
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="test",
|
||||
destination_workload="podinfo",
|
||||
response_code!="404"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="test",
|
||||
destination_workload="podinfo"
|
||||
}[1m]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking
|
||||
if the HTTP 404 req/sec percentage is below 5 percent of the total traffic.
|
||||
If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
When specifying a query, Flagger will run the promql query and convert the result to float64.
|
||||
Then it compares the query result value with the metric threshold value.
|
||||
|
||||
|
||||
### Webhooks
|
||||
|
||||
The canary analysis can be extended with webhooks.
|
||||
@@ -245,14 +455,14 @@ Spec:
|
||||
```yaml
|
||||
canaryAnalysis:
|
||||
webhooks:
|
||||
- name: integration-tests
|
||||
url: http://podinfo.test:9898/echo
|
||||
- name: integration-test
|
||||
url: http://int-runner.test:8080/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
test: "all"
|
||||
token: "16688eb5e9f289f1991c"
|
||||
- name: load-tests
|
||||
url: http://podinfo.test:9898/echo
|
||||
- name: db-test
|
||||
url: http://migration-check.db/query
|
||||
timeout: 30s
|
||||
metadata:
|
||||
key1: "val1"
|
||||
@@ -281,4 +491,78 @@ Response status codes:
|
||||
|
||||
On a non-2xx response Flagger will include the response body (if any) in the failed checks log and Kubernetes events.
|
||||
|
||||
### Load Testing
|
||||
|
||||
For workloads that are not receiving constant traffic Flagger can be configured with a webhook,
|
||||
that when called, will start a load test for the target workload.
|
||||
If the target workload doesn't receive any traffic during the canary analysis,
|
||||
Flagger metric checks will fail with "no values found for metric istio_requests_total".
|
||||
|
||||
Flagger comes with a load testing service based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
that generates traffic during analysis when configured as a webhook.
|
||||
|
||||
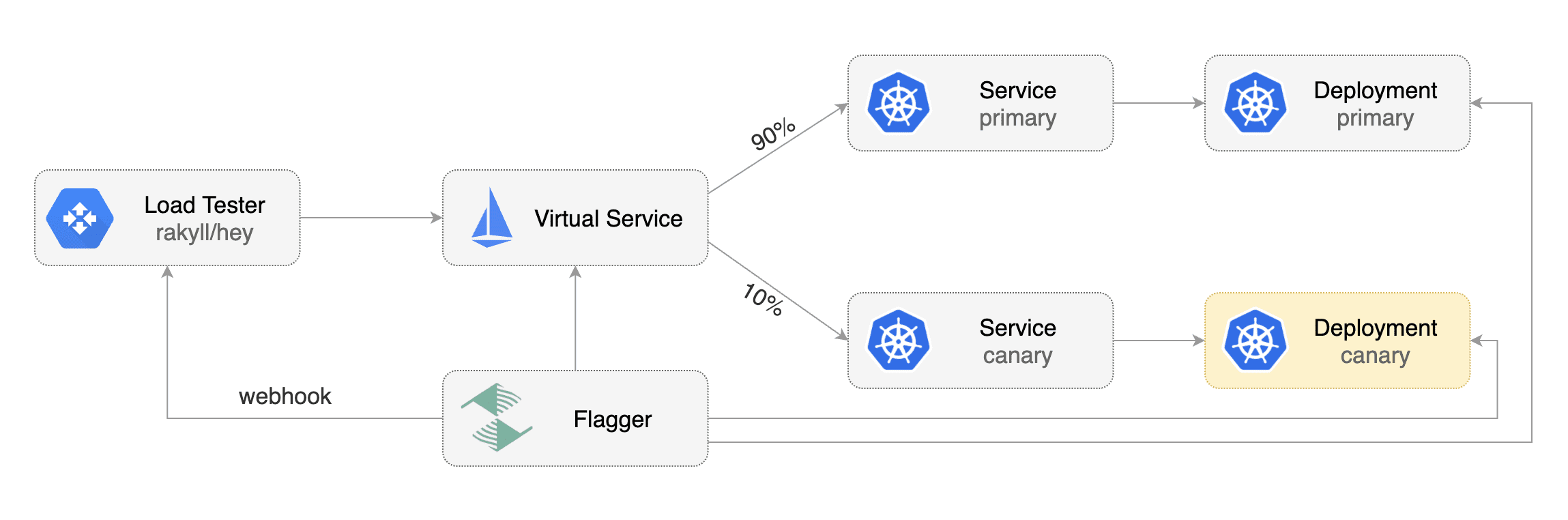
|
||||
|
||||
First you need to deploy the load test runner in a namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
```
|
||||
|
||||
Or by using Helm:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set cmd.logOutput=true \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
When deployed the load tester API will be available at `http://flagger-loadtester.test/`.
|
||||
|
||||
Now you can add webhooks to the canary analysis spec:
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
- name: load-test-post
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -m POST -d '{test: 2}' http://podinfo.test:9898/echo"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the webhooks and the load tester will run the `hey` commands
|
||||
in the background, if they are not already running. This will ensure that during the
|
||||
analysis, the `podinfo.test` virtual service will receive a steady steam of GET and POST requests.
|
||||
|
||||
If your workload is exposed outside the mesh with the Istio Gateway and TLS you can point `hey` to the
|
||||
public URL and use HTTP2.
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -h2 https://podinfo.example.com/"
|
||||
```
|
||||
|
||||
The load tester can run arbitrary commands as long as the binary is present in the container image.
|
||||
For example if you you want to replace `hey` with another CLI, you can create your own Docker image:
|
||||
|
||||
```dockerfile
|
||||
FROM quay.io/stefanprodan/flagger-loadtester:<VER>
|
||||
|
||||
RUN curl -Lo /usr/local/bin/my-cli https://github.com/user/repo/releases/download/ver/my-cli \
|
||||
&& chmod +x /usr/local/bin/my-cli
|
||||
```
|
||||
|
||||
@@ -1,16 +1,15 @@
|
||||
# Install Istio
|
||||
# Flagger install on Google Cloud
|
||||
|
||||
This guide walks you through setting up Istio with Jaeger, Prometheus, Grafana and
|
||||
Let’s Encrypt TLS for ingress gateway on Google Kubernetes Engine.
|
||||
This guide walks you through setting up Flagger and Istio on Google Kubernetes Engine.
|
||||
|
||||
|
||||
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You will be creating a cluster on Google’s Kubernetes Engine \(GKE\),
|
||||
if you don’t have an account you can sign up [here](https://cloud.google.com/free/) for free credits.
|
||||
|
||||
Login into GCP, create a project and enable billing for it.
|
||||
Login into Google Cloud, create a project and enable billing for it.
|
||||
|
||||
Install the [gcloud](https://cloud.google.com/sdk/) command line utility and configure your project with `gcloud init`.
|
||||
|
||||
@@ -23,8 +22,8 @@ gcloud config set project PROJECT_ID
|
||||
Set the default compute region and zone:
|
||||
|
||||
```text
|
||||
gcloud config set compute/region europe-west3
|
||||
gcloud config set compute/zone europe-west3-a
|
||||
gcloud config set compute/region us-central1
|
||||
gcloud config set compute/zone us-central1-a
|
||||
```
|
||||
|
||||
Enable the Kubernetes and Cloud DNS services for your project:
|
||||
@@ -34,46 +33,42 @@ gcloud services enable container.googleapis.com
|
||||
gcloud services enable dns.googleapis.com
|
||||
```
|
||||
|
||||
Install the `kubectl` command-line tool:
|
||||
Install the kubectl command-line tool:
|
||||
|
||||
```text
|
||||
gcloud components install kubectl
|
||||
```
|
||||
|
||||
Install the `helm` command-line tool:
|
||||
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
### GKE cluster setup
|
||||
|
||||
Create a cluster with three nodes using the latest Kubernetes version:
|
||||
Create a cluster with the Istio add-on:
|
||||
|
||||
```bash
|
||||
k8s_version=$(gcloud container get-server-config --format=json \
|
||||
| jq -r '.validNodeVersions[0]')
|
||||
K8S_VERSION=$(gcloud container get-server-config --format=json \
|
||||
| jq -r '.validMasterVersions[0]')
|
||||
|
||||
gcloud container clusters create istio \
|
||||
--cluster-version=${k8s_version} \
|
||||
--zone=europe-west3-a \
|
||||
--num-nodes=3 \
|
||||
gcloud beta container clusters create istio \
|
||||
--cluster-version=${K8S_VERSION} \
|
||||
--zone=us-central1-a \
|
||||
--num-nodes=2 \
|
||||
--machine-type=n1-highcpu-4 \
|
||||
--preemptible \
|
||||
--no-enable-cloud-logging \
|
||||
--no-enable-cloud-monitoring \
|
||||
--disk-size=30 \
|
||||
--enable-autorepair \
|
||||
--scopes=gke-default,compute-rw,storage-rw
|
||||
--addons=HorizontalPodAutoscaling,Istio \
|
||||
--istio-config=auth=MTLS_PERMISSIVE
|
||||
```
|
||||
|
||||
The above command will create a default node pool consisting of `n1-highcpu-4` \(vCPU: 4, RAM 3.60GB, DISK: 30GB\)
|
||||
The above command will create a default node pool consisting of two `n1-highcpu-4` \(vCPU: 4, RAM 3.60GB, DISK: 30GB\)
|
||||
preemptible VMs. Preemptible VMs are up to 80% cheaper than regular instances and are terminated and replaced
|
||||
after a maximum of 24 hours.
|
||||
|
||||
Set up credentials for `kubectl`:
|
||||
|
||||
```bash
|
||||
gcloud container clusters get-credentials istio -z=europe-west3-a
|
||||
gcloud container clusters get-credentials istio
|
||||
```
|
||||
|
||||
Create a cluster admin role binding:
|
||||
@@ -87,9 +82,11 @@ kubectl create clusterrolebinding "cluster-admin-$(whoami)" \
|
||||
Validate your setup with:
|
||||
|
||||
```bash
|
||||
kubectl get nodes -o wide
|
||||
kubectl -n istio-system get svc
|
||||
```
|
||||
|
||||
In a couple of seconds GCP should allocate an external IP to the `istio-ingressgateway` service.
|
||||
|
||||
### Cloud DNS setup
|
||||
|
||||
You will need an internet domain and access to the registrar to change the name servers to Google Cloud DNS.
|
||||
@@ -116,34 +113,30 @@ Wait for the name servers to change \(replace `example.com` with your domain\):
|
||||
watch dig +short NS example.com
|
||||
```
|
||||
|
||||
Create a static IP address named `istio-gateway-ip` in the same region as your GKE cluster:
|
||||
Create a static IP address named `istio-gateway` using the Istio ingress IP:
|
||||
|
||||
```bash
|
||||
gcloud compute addresses create istio-gateway-ip --region europe-west3
|
||||
export GATEWAY_IP=$(kubectl -n istio-system get svc/istio-ingressgateway -ojson \
|
||||
| jq -r .status.loadBalancer.ingress[0].ip)
|
||||
|
||||
gcloud compute addresses create istio-gateway --addresses ${GATEWAY_IP} --region us-central1
|
||||
```
|
||||
|
||||
Find the static IP address:
|
||||
|
||||
```bash
|
||||
gcloud compute addresses describe istio-gateway-ip --region europe-west3
|
||||
```
|
||||
|
||||
Create the following DNS records \(replace `example.com` with your domain and set your Istio Gateway IP\):
|
||||
Create the following DNS records \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
DOMAIN="example.com"
|
||||
GATEWAYIP="35.198.98.90"
|
||||
|
||||
gcloud dns record-sets transaction start --zone=istio
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="www.${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="www.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="*.${DOMAIN}" --ttl=300 --type=A ${GATEWAYIP}
|
||||
--name="*.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction execute --zone istio
|
||||
```
|
||||
@@ -154,31 +147,22 @@ Verify that the wildcard DNS is working \(replace `example.com` with your domain
|
||||
watch host test.example.com
|
||||
```
|
||||
|
||||
### Install Istio with Helm
|
||||
### Install Helm
|
||||
|
||||
Download the latest Istio release:
|
||||
Install the [Helm](https://docs.helm.sh/using_helm/#installing-helm) command-line tool:
|
||||
|
||||
```bash
|
||||
curl -L https://git.io/getLatestIstio | sh -
|
||||
```
|
||||
|
||||
Navigate to `istio-x.x.x` dir and copy the Istio CLI in your bin:
|
||||
|
||||
```bash
|
||||
cd istio-x.x.x/
|
||||
sudo cp ./bin/istioctl /usr/local/bin/istioctl
|
||||
```
|
||||
|
||||
Apply the Istio CRDs:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./install/kubernetes/helm/istio/templates/crds.yaml
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
Create a service account and a cluster role binding for Tiller:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./install/kubernetes/helm/helm-service-account.yaml
|
||||
kubectl -n kube-system create sa tiller
|
||||
|
||||
kubectl create clusterrolebinding tiller-cluster-rule \
|
||||
--clusterrole=cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
Deploy Tiller in the `kube-system` namespace:
|
||||
@@ -187,125 +171,51 @@ Deploy Tiller in the `kube-system` namespace:
|
||||
helm init --service-account tiller
|
||||
```
|
||||
|
||||
Find the GKE IP ranges:
|
||||
You should consider using SSL between Helm and Tiller, for more information on securing your Helm
|
||||
installation see [docs.helm.sh](https://docs.helm.sh/using_helm/#securing-your-helm-installation).
|
||||
|
||||
### Install cert-manager
|
||||
|
||||
Jetstack's [cert-manager](https://github.com/jetstack/cert-manager)
|
||||
is a Kubernetes operator that automatically creates and manages TLS certs issued by Let’s Encrypt.
|
||||
|
||||
You'll be using cert-manager to provision a wildcard certificate for the Istio ingress gateway.
|
||||
|
||||
Install cert-manager's CRDs:
|
||||
|
||||
```bash
|
||||
gcloud container clusters describe istio --zone=europe-west3-a \
|
||||
| grep -e clusterIpv4Cidr -e servicesIpv4Cidr
|
||||
CERT_REPO=https://raw.githubusercontent.com/jetstack/cert-manager
|
||||
|
||||
kubectl apply -f ${CERT_REPO}/release-0.6/deploy/manifests/00-crds.yaml
|
||||
```
|
||||
|
||||
You'll be using the IP ranges to allow unrestricted egress traffic for services running inside the service mesh.
|
||||
|
||||
Configure Istio with Prometheus, Jaeger, and cert-manager:
|
||||
|
||||
```yaml
|
||||
global:
|
||||
nodePort: false
|
||||
proxy:
|
||||
# replace with your GKE IP ranges
|
||||
includeIPRanges: "10.28.0.0/14,10.7.240.0/20"
|
||||
|
||||
sidecarInjectorWebhook:
|
||||
enabled: true
|
||||
enableNamespacesByDefault: false
|
||||
|
||||
gateways:
|
||||
enabled: true
|
||||
istio-ingressgateway:
|
||||
replicaCount: 2
|
||||
autoscaleMin: 2
|
||||
autoscaleMax: 3
|
||||
# replace with your Istio Gateway IP
|
||||
loadBalancerIP: "35.198.98.90"
|
||||
type: LoadBalancer
|
||||
|
||||
pilot:
|
||||
enabled: true
|
||||
replicaCount: 1
|
||||
autoscaleMin: 1
|
||||
autoscaleMax: 1
|
||||
resources:
|
||||
requests:
|
||||
cpu: 500m
|
||||
memory: 1024Mi
|
||||
|
||||
grafana:
|
||||
enabled: true
|
||||
security:
|
||||
enabled: true
|
||||
adminUser: admin
|
||||
# change the password
|
||||
adminPassword: admin
|
||||
|
||||
prometheus:
|
||||
enabled: true
|
||||
|
||||
servicegraph:
|
||||
enabled: true
|
||||
|
||||
tracing:
|
||||
enabled: true
|
||||
jaeger:
|
||||
tag: 1.7
|
||||
|
||||
certmanager:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
Save the above file as `my-istio.yaml` and install Istio with Helm:
|
||||
Create the cert-manager namespace and disable resource validation:
|
||||
|
||||
```bash
|
||||
helm upgrade --install istio ./install/kubernetes/helm/istio \
|
||||
--namespace=istio-system \
|
||||
-f ./my-istio.yaml
|
||||
kubectl create namespace cert-manager
|
||||
|
||||
kubectl label namespace cert-manager certmanager.k8s.io/disable-validation=true
|
||||
```
|
||||
|
||||
Verify that Istio workloads are running:
|
||||
Install cert-manager with Helm:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system get pods
|
||||
```bash
|
||||
helm repo update && helm upgrade -i cert-manager \
|
||||
--namespace cert-manager \
|
||||
--version v0.6.0 \
|
||||
stable/cert-manager
|
||||
```
|
||||
|
||||
### Configure Istio Gateway with LE TLS
|
||||
### Istio Gateway TLS setup
|
||||
|
||||
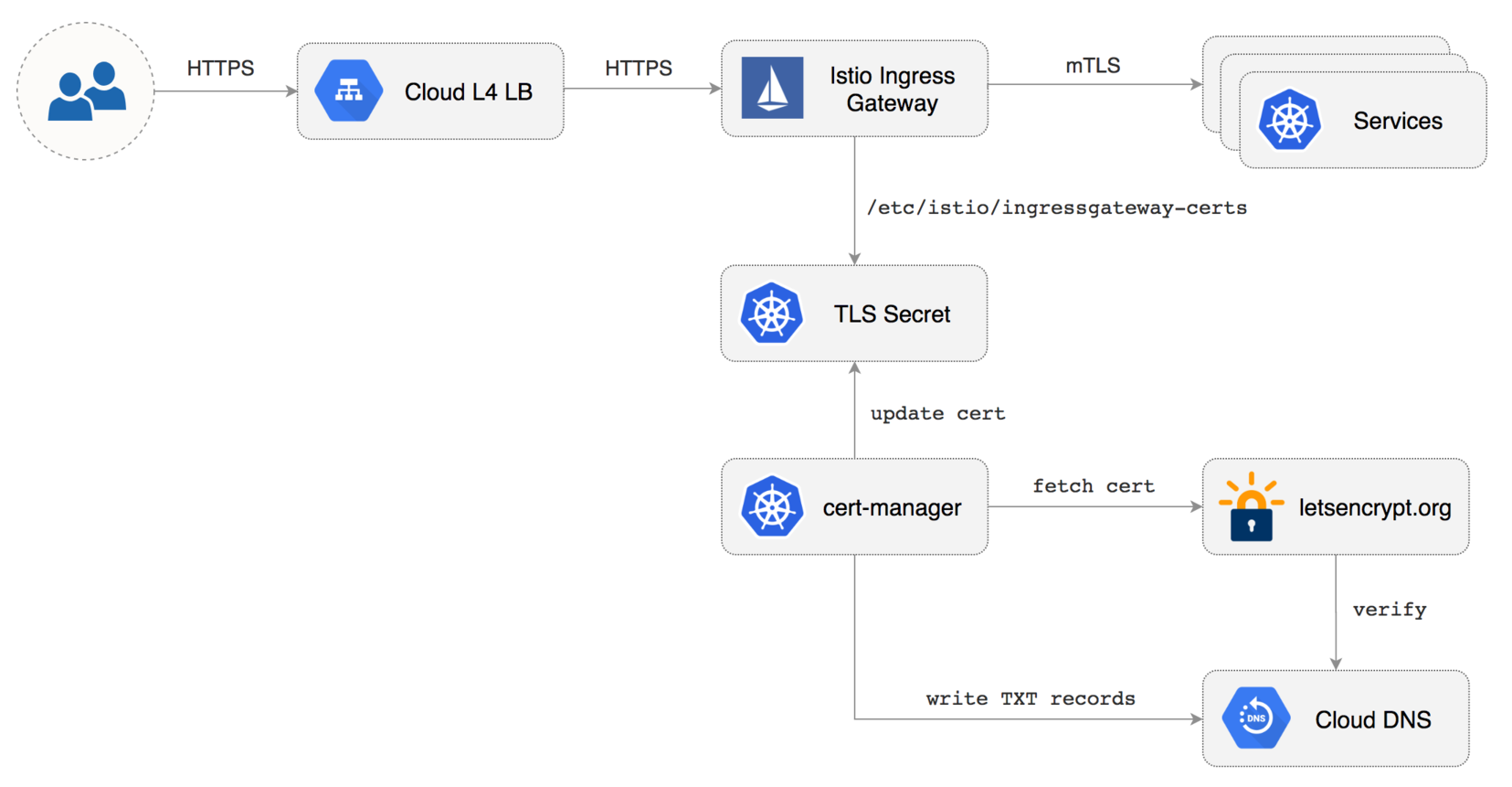
|
||||
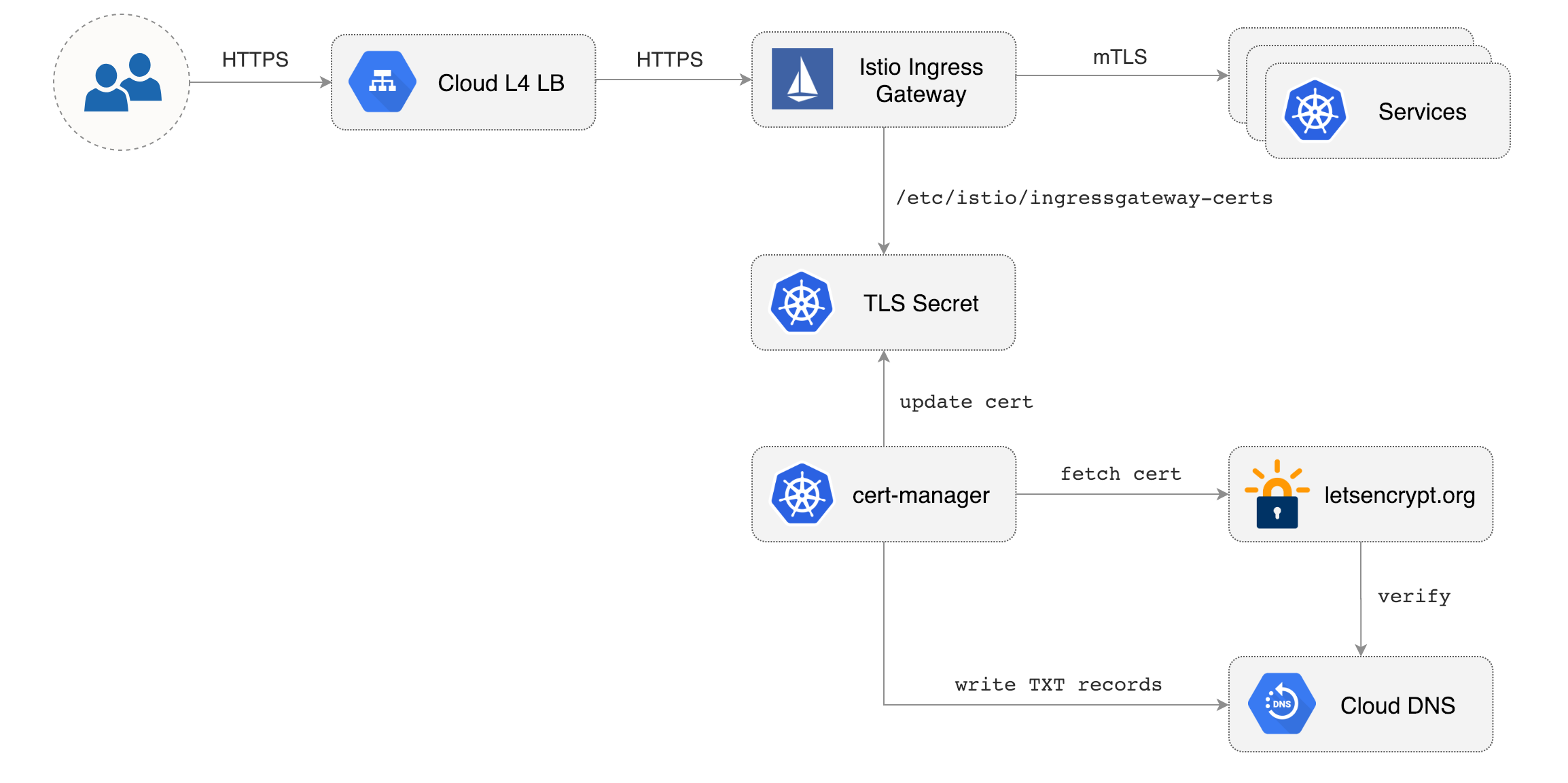
|
||||
|
||||
Create a Istio Gateway in istio-system namespace with HTTPS redirect:
|
||||
Create a generic Istio Gateway to expose services outside the mesh on HTTPS:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
httpsRedirect: true
|
||||
- port:
|
||||
number: 443
|
||||
name: https
|
||||
protocol: HTTPS
|
||||
hosts:
|
||||
- "*"
|
||||
tls:
|
||||
mode: SIMPLE
|
||||
privateKey: /etc/istio/ingressgateway-certs/tls.key
|
||||
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
|
||||
```
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
Save the above resource as istio-gateway.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./istio-gateway.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/gke/istio-gateway.yaml
|
||||
```
|
||||
|
||||
Create a service account with Cloud DNS admin role \(replace `my-gcp-project` with your project ID\):
|
||||
@@ -387,37 +297,76 @@ spec:
|
||||
- "example.com"
|
||||
```
|
||||
|
||||
Save the above resource as of-cert.yaml and then apply it:
|
||||
Save the above resource as istio-gateway-cert.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./of-cert.yaml
|
||||
kubectl apply -f ./istio-gateway-cert.yaml
|
||||
```
|
||||
|
||||
In a couple of seconds cert-manager should fetch a wildcard certificate from letsencrypt.org:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system logs deployment/certmanager -f
|
||||
kubectl -n istio-system describe certificate istio-gateway
|
||||
|
||||
Certificate issued successfully
|
||||
Certificate istio-system/istio-gateway scheduled for renewal in 1438 hours
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal CertIssued 1m52s cert-manager Certificate issued successfully
|
||||
```
|
||||
|
||||
Recreate Istio ingress gateway pods:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system delete pods -l istio=ingressgateway
|
||||
kubectl -n istio-system get pods -l istio=ingressgateway
|
||||
```
|
||||
|
||||
Note that Istio gateway doesn't reload the certificates from the TLS secret on cert-manager renewal.
|
||||
Since the GKE cluster is made out of preemptible VMs the gateway pods will be replaced once every 24h,
|
||||
if your not using preemptible nodes then you need to manually kill the gateway pods every two months
|
||||
if your not using preemptible nodes then you need to manually delete the gateway pods every two months
|
||||
before the certificate expires.
|
||||
|
||||
### Expose services outside the service mesh
|
||||
### Install Prometheus
|
||||
|
||||
In order to expose services via the Istio Gateway you have to create a Virtual Service attached to Istio Gateway.
|
||||
The GKE Istio add-on does not include a Prometheus instance that scrapes the Istio telemetry service.
|
||||
Because Flagger uses the Istio HTTP metrics to run the canary analysis you have to deploy the following
|
||||
Prometheus configuration that's similar to the one that comes with the official Istio Helm chart.
|
||||
|
||||
Create a virtual service in `istio-system` namespace for Grafana \(replace `example.com` with your domain\):
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/gke/istio-prometheus.yaml
|
||||
```
|
||||
|
||||
### Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the `istio-system` namespace with Slack notifications enabled:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Deploy Grafana in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=replace-me
|
||||
```
|
||||
|
||||
Expose Grafana through the public gateway by creating a virtual service \(replace `example.com` with your domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
@@ -433,8 +382,7 @@ spec:
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: grafana
|
||||
timeout: 30s
|
||||
host: flagger-grafana
|
||||
```
|
||||
|
||||
Save the above resource as grafana-virtual-service.yaml and then apply it:
|
||||
@@ -444,17 +392,3 @@ kubectl apply -f ./grafana-virtual-service.yaml
|
||||
```
|
||||
|
||||
Navigate to `http://grafana.example.com` in your browser and you should be redirected to the HTTPS version.
|
||||
|
||||
Check that HTTP2 is enabled:
|
||||
|
||||
```bash
|
||||
curl -I --http2 https://grafana.example.com
|
||||
|
||||
HTTP/2 200
|
||||
content-type: text/html; charset=UTF-8
|
||||
x-envoy-upstream-service-time: 3
|
||||
server: envoy
|
||||
```
|
||||
|
||||
|
||||
|
||||
143
docs/gitbook/install/flagger-install-on-kubernetes.md
Normal file
@@ -0,0 +1,143 @@
|
||||
# Flagger install on Kubernetes
|
||||
|
||||
This guide walks you through setting up Flagger on a Kubernetes cluster.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer with the following admission controllers enabled:
|
||||
|
||||
* MutatingAdmissionWebhook
|
||||
* ValidatingAdmissionWebhook
|
||||
|
||||
Flagger depends on [Istio](https://istio.io/docs/setup/kubernetes/quick-start/) **v1.0.3** or newer
|
||||
with traffic management, telemetry and Prometheus enabled.
|
||||
|
||||
A minimal Istio installation should contain the following services:
|
||||
|
||||
* istio-pilot
|
||||
* istio-ingressgateway
|
||||
* istio-sidecar-injector
|
||||
* istio-telemetry
|
||||
* prometheus
|
||||
|
||||
### Install Flagger
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
You can install Flagger in any namespace as long as it can talk to the Istio Prometheus service on port 9090.
|
||||
|
||||
Enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/flagger \
|
||||
--name flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
> $HOME/flagger.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger.yaml
|
||||
```
|
||||
|
||||
To uninstall the Flagger release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
> **Note** that on uninstall the Canary CRD will not be removed.
|
||||
Deleting the CRD will make Kubernetes remove all the objects owned by Flagger like Istio virtual services,
|
||||
Kubernetes deployments and ClusterIP services.
|
||||
|
||||
If you want to remove all the objects created by Flagger you have delete the Canary CRD with kubectl:
|
||||
|
||||
```text
|
||||
kubectl delete crd canaries.flagger.app
|
||||
```
|
||||
|
||||
### Install Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=change-me
|
||||
```
|
||||
|
||||
Or use helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/grafana \
|
||||
--name flagger-grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=change-me \
|
||||
> $HOME/flagger-grafana.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-grafana.yaml
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/flagger-grafana 3000:3000
|
||||
```
|
||||
|
||||
### Install Load Tester
|
||||
|
||||
Flagger comes with an optional load testing service that generates traffic
|
||||
during canary analysis when configured as a webhook.
|
||||
|
||||
Deploy the load test runner with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set cmd.logOutput=true \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
Deploy with kubectl:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
```
|
||||
|
||||
> **Note** that the load tester should be deployed in a namespace with Istio sidecar injection enabled.
|
||||
|
||||
@@ -1,75 +0,0 @@
|
||||
# Install Flagger
|
||||
|
||||
Before installing Flagger make sure you have [Istio](https://istio.io) running with Prometheus enabled.
|
||||
If you are new to Istio you can follow this GKE guide
|
||||
[Istio service mesh walk-through](https://docs.flagger.app/install/install-istio).
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Kubernetes >= 1.11
|
||||
* Istio >= 1.0
|
||||
* Prometheus >= 2.6
|
||||
|
||||
### Install with Helm and Tiller
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
Enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
### Install with kubectl
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/flagger \
|
||||
--name flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set controlLoopInterval=1m > $HOME/flagger.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger.yaml
|
||||
```
|
||||
|
||||
### Uninstall
|
||||
|
||||
To uninstall/delete the flagger release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
> **Note** that on uninstall the Canary CRD will not be removed.
|
||||
Deleting the CRD will make Kubernetes remove all the objects owned by Flagger like Istio virtual services,
|
||||
Kubernetes deployments and ClusterIP services.
|
||||
|
||||
|
||||
If you want to remove all the objects created by Flagger you have delete the Canary CRD with kubectl:
|
||||
|
||||
```text
|
||||
kubectl delete crd canaries.flagger.app
|
||||
```
|
||||
|
||||
@@ -1,48 +0,0 @@
|
||||
# Install Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
### Install with Helm and Tiller
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus:9090 \
|
||||
--set user=admin \
|
||||
--set password=admin
|
||||
```
|
||||
|
||||
### Install with kubectl
|
||||
|
||||
If you don't have Tiller you can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm template flagger/grafana \
|
||||
--name flagger-grafana \
|
||||
--namespace=istio-system \
|
||||
--set user=admin \
|
||||
--set password=admin > $HOME/flagger-grafana.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f $HOME/flagger-grafana.yaml
|
||||
```
|
||||
|
||||
### Uninstall
|
||||
|
||||
To uninstall/delete the Grafana release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete --purge flagger-grafana
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
353
docs/gitbook/tutorials/canary-helm-gitops.md
Normal file
@@ -0,0 +1,353 @@
|
||||
# Canary Deployments with Helm Charts and GitOps
|
||||
|
||||
This guide shows you how to package a web app into a Helm chart, trigger canary deployments on Helm upgrade
|
||||
and automate the chart release process with Weave Flux.
|
||||
|
||||
### Packaging
|
||||
|
||||
You'll be using the [podinfo](https://github.com/stefanprodan/k8s-podinfo) chart.
|
||||
This chart packages a web app made with Go, it's configuration, a horizontal pod autoscaler (HPA)
|
||||
and the canary configuration file.
|
||||
|
||||
```
|
||||
├── Chart.yaml
|
||||
├── README.md
|
||||
├── templates
|
||||
│ ├── NOTES.txt
|
||||
│ ├── _helpers.tpl
|
||||
│ ├── canary.yaml
|
||||
│ ├── configmap.yaml
|
||||
│ ├── deployment.yaml
|
||||
│ └── hpa.yaml
|
||||
└── values.yaml
|
||||
```
|
||||
|
||||
You can find the chart source [here](https://github.com/stefanprodan/flagger/tree/master/charts/podinfo).
|
||||
|
||||
### Install
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install podinfo with the release name `frontend` (replace `example.com` with your own domain):
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=frontend \
|
||||
--set backend=http://backend.test:9898/echo \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=true \
|
||||
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
||||
--set canary.istioIngress.host=frontend.istio.example.com
|
||||
```
|
||||
|
||||
Flagger takes a Kubernetes deployment and a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Istio virtual services).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
|
||||
```bash
|
||||
# generated by Helm
|
||||
configmap/frontend
|
||||
deployment.apps/frontend
|
||||
horizontalpodautoscaler.autoscaling/frontend
|
||||
canary.flagger.app/frontend
|
||||
|
||||
# generated by Flagger
|
||||
configmap/frontend-primary
|
||||
deployment.apps/frontend-primary
|
||||
horizontalpodautoscaler.autoscaling/frontend-primary
|
||||
service/frontend
|
||||
service/frontend-canary
|
||||
service/frontend-primary
|
||||
virtualservice.networking.istio.io/frontend
|
||||
```
|
||||
|
||||
When the `frontend-primary` deployment comes online,
|
||||
Flagger will route all traffic to the primary pods and scale to zero the `frontend` deployment.
|
||||
|
||||
Open your browser and navigate to the frontend URL:
|
||||
|
||||
|
||||
|
||||
Now let's install the `backend` release without exposing it outside the mesh:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=backend \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=false
|
||||
```
|
||||
|
||||
Check if Flagger has successfully deployed the canaries:
|
||||
|
||||
```
|
||||
kubectl -n test get canaries
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Initialized 0 2019-02-12T18:53:18Z
|
||||
frontend Initialized 0 2019-02-12T17:50:50Z
|
||||
```
|
||||
|
||||
Click on the ping button in the `frontend` UI to trigger a HTTP POST request
|
||||
that will reach the `backend` app:
|
||||
|
||||
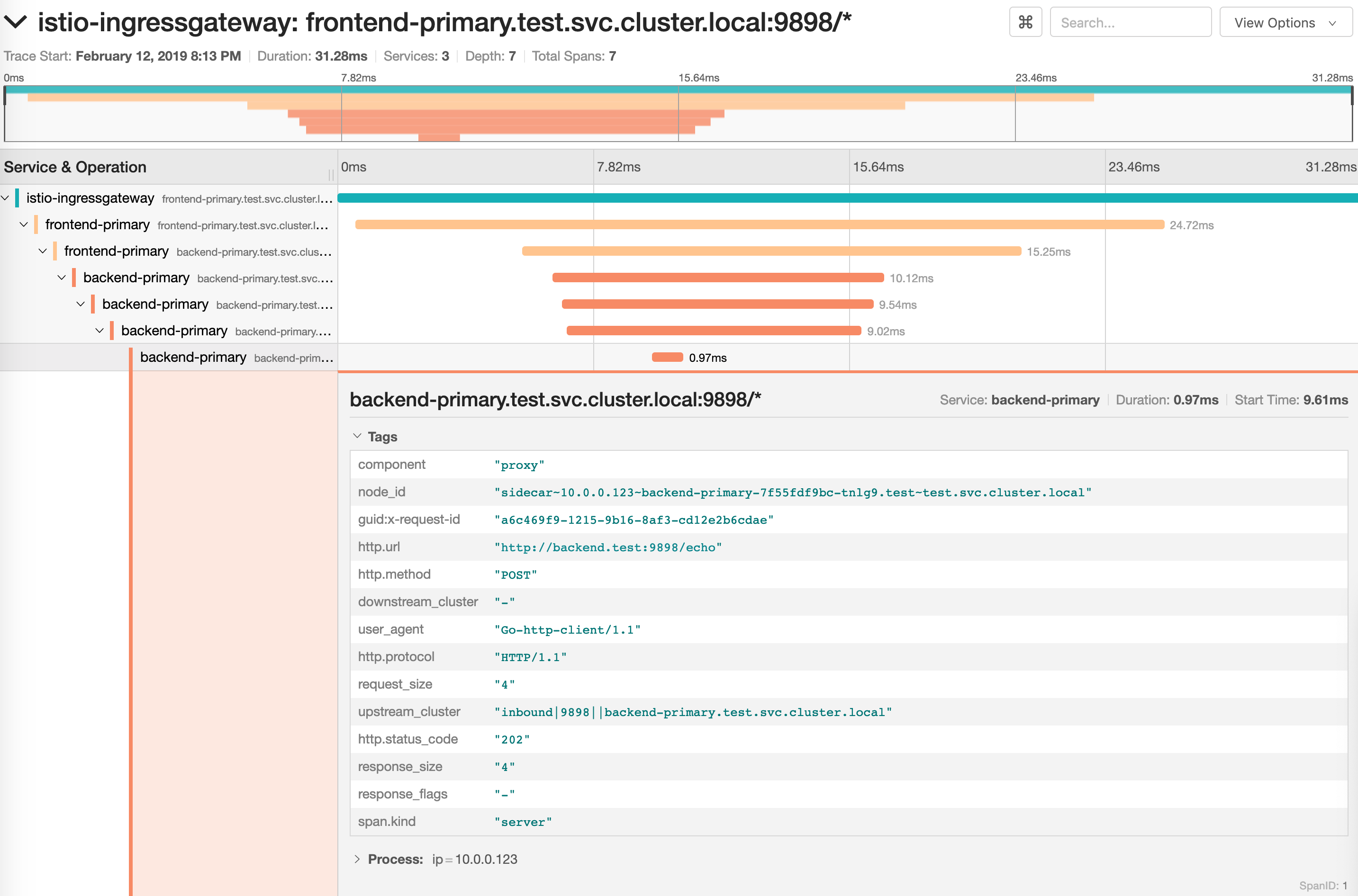
|
||||
|
||||
We'll use the `/echo` endpoint (same as the one the ping button calls)
|
||||
to generate load on both apps during a canary deployment.
|
||||
|
||||
### Upgrade
|
||||
|
||||
First let's install a load testing service that will generate traffic during analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Enable the load tester and deploy a new `frontend` version:
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set image.tag=1.4.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the canary analysis along with the load test:
|
||||
|
||||
```
|
||||
kubectl -n istio-system logs deployment/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Scaling up frontend.test
|
||||
Halt advancement frontend.test waiting for rollout to finish: 0 of 2 updated replicas are available
|
||||
Starting canary analysis for frontend.test
|
||||
Advance frontend.test canary weight 5
|
||||
Advance frontend.test canary weight 10
|
||||
Advance frontend.test canary weight 15
|
||||
Advance frontend.test canary weight 20
|
||||
Advance frontend.test canary weight 25
|
||||
Advance frontend.test canary weight 30
|
||||
Advance frontend.test canary weight 35
|
||||
Advance frontend.test canary weight 40
|
||||
Advance frontend.test canary weight 45
|
||||
Advance frontend.test canary weight 50
|
||||
Copying frontend.test template spec to frontend-primary.test
|
||||
Halt advancement frontend-primary.test waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Promotion completed! Scaling down frontend.test
|
||||
```
|
||||
|
||||
You can monitor the canary deployment with Grafana. Open the Flagger dashboard,
|
||||
select `test` from the namespace dropdown, `frontend-primary` from the primary dropdown and `frontend` from the
|
||||
canary dropdown.
|
||||
|
||||
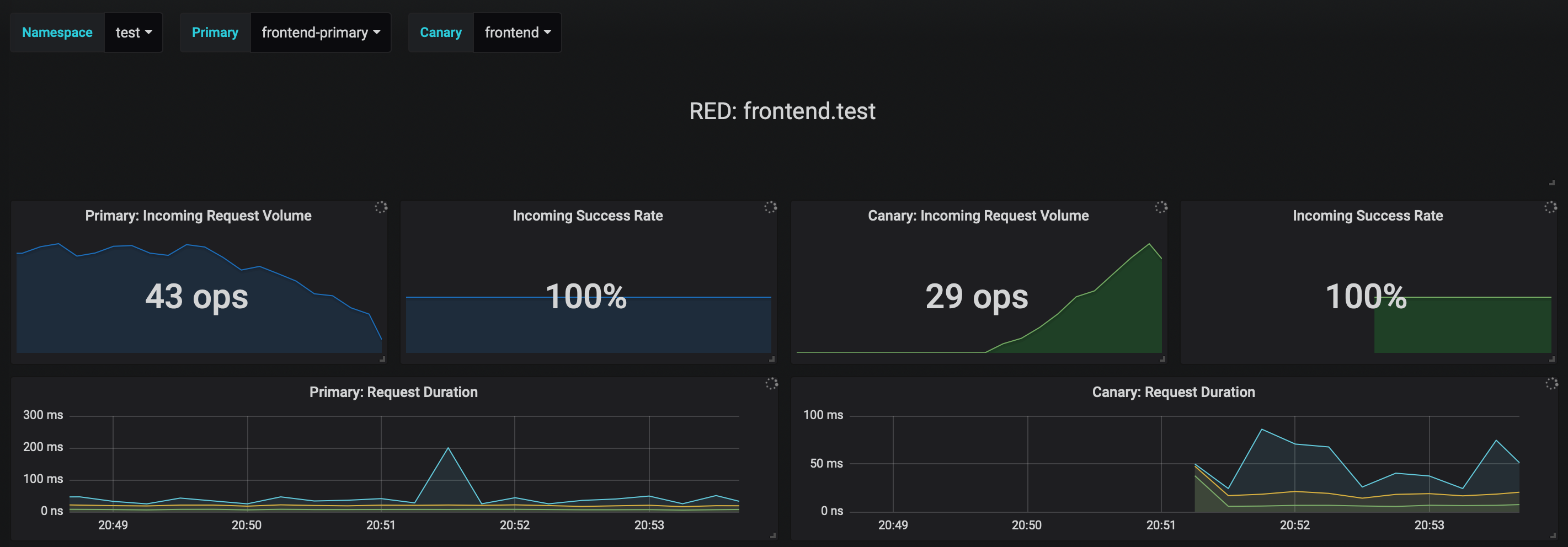
|
||||
|
||||
Now trigger a canary deployment for the `backend` app, but this time you'll change a value in the configmap:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set httpServer.timeout=25s
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/delay/1
|
||||
```
|
||||
|
||||
Flagger detects the config map change and starts a canary analysis. Flagger will pause the advancement
|
||||
when the HTTP success rate drops under 99% or when the average request duration in the last minute is over 500ms:
|
||||
|
||||
```
|
||||
kubectl -n test describe canary backend
|
||||
|
||||
Events:
|
||||
|
||||
ConfigMap backend has changed
|
||||
New revision detected! Scaling up backend.test
|
||||
Starting canary analysis for backend.test
|
||||
Advance backend.test canary weight 5
|
||||
Advance backend.test canary weight 10
|
||||
Advance backend.test canary weight 15
|
||||
Advance backend.test canary weight 20
|
||||
Advance backend.test canary weight 25
|
||||
Advance backend.test canary weight 30
|
||||
Advance backend.test canary weight 35
|
||||
Halt backend.test advancement success rate 62.50% < 99%
|
||||
Halt backend.test advancement success rate 88.24% < 99%
|
||||
Advance backend.test canary weight 40
|
||||
Advance backend.test canary weight 45
|
||||
Halt backend.test advancement request duration 2.415s > 500ms
|
||||
Halt backend.test advancement request duration 2.42s > 500ms
|
||||
Advance backend.test canary weight 50
|
||||
ConfigMap backend-primary synced
|
||||
Copying backend.test template spec to backend-primary.test
|
||||
Promotion completed! Scaling down backend.test
|
||||
```
|
||||
|
||||
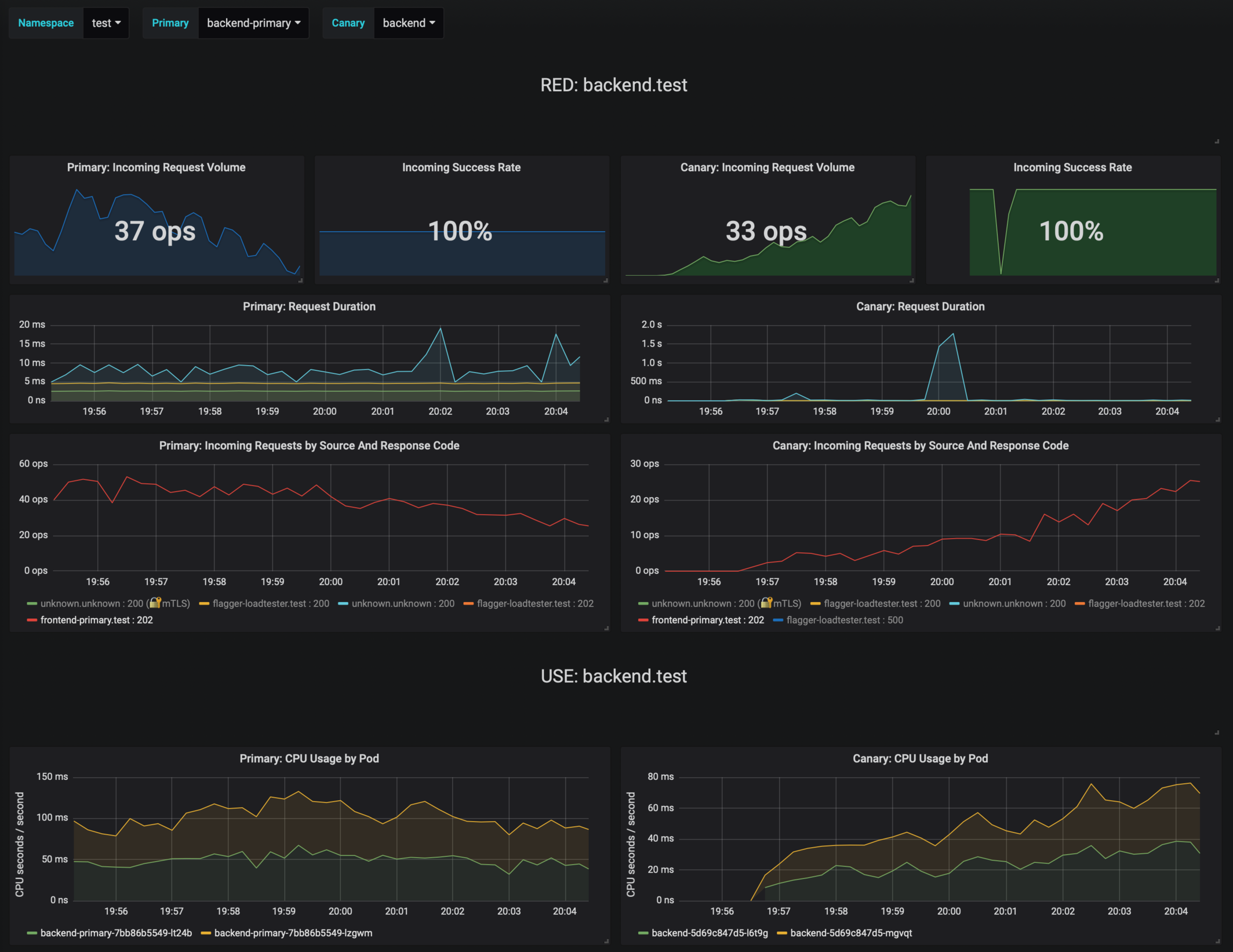
|
||||
|
||||
If the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```bash
|
||||
kubectl -n test get canary
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Succeeded 0 2019-02-12T19:33:11Z
|
||||
frontend Failed 0 2019-02-12T19:47:20Z
|
||||
```
|
||||
|
||||
If you've enabled the Slack notifications, you'll receive an alert with the reason why the `backend` promotion failed.
|
||||
|
||||
### GitOps automation
|
||||
|
||||
Instead of using Helm CLI from a CI tool to perform the install and upgrade,
|
||||
you could use a Git based approach. GitOps is a way to do Continuous Delivery,
|
||||
it works by using Git as a source of truth for declarative infrastructure and workloads.
|
||||
In the [GitOps model](https://www.weave.works/technologies/gitops/),
|
||||
any change to production must be committed in source control
|
||||
prior to being applied on the cluster. This way rollback and audit logs are provided by Git.
|
||||
|
||||
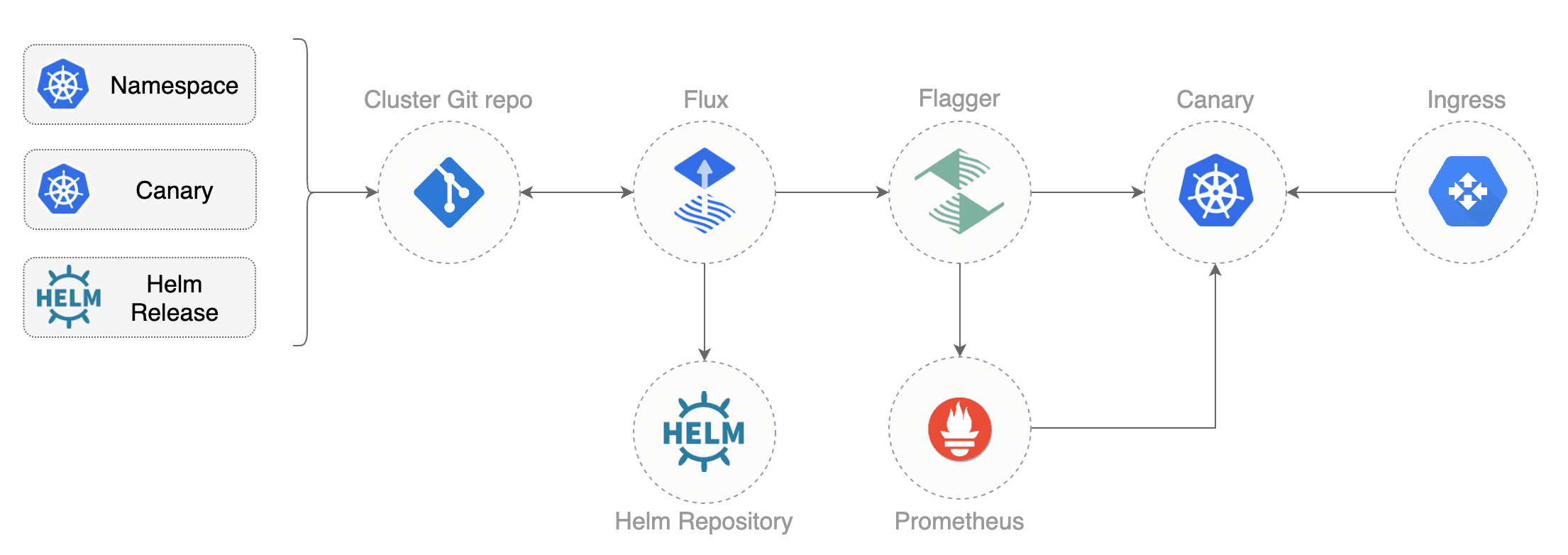
|
||||
|
||||
In order to apply the GitOps pipeline model to Flagger canary deployments you'll need
|
||||
a Git repository with your workloads definitions in YAML format,
|
||||
a container registry where your CI system pushes immutable images and
|
||||
an operator that synchronizes the Git repo with the cluster state.
|
||||
|
||||
Create a git repository with the following content:
|
||||
|
||||
```
|
||||
├── namespaces
|
||||
│ └── test.yaml
|
||||
└── releases
|
||||
└── test
|
||||
├── backend.yaml
|
||||
├── frontend.yaml
|
||||
└── loadtester.yaml
|
||||
```
|
||||
|
||||
You can find the git source [here](https://github.com/stefanprodan/flagger/tree/master/artifacts/cluster).
|
||||
|
||||
Define the `frontend` release using Flux `HelmRelease` custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
annotations:
|
||||
flux.weave.works/automated: "true"
|
||||
flux.weave.works/tag.chart-image: semver:~1.4
|
||||
spec:
|
||||
releaseName: frontend
|
||||
chart:
|
||||
repository: https://stefanprodan.github.io/flagger/
|
||||
name: podinfo
|
||||
version: 2.0.0
|
||||
values:
|
||||
image:
|
||||
repository: quay.io/stefanprodan/podinfo
|
||||
tag: 1.4.0
|
||||
backend: http://backend-podinfo:9898/echo
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: true
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
host: frontend.istio.example.com
|
||||
loadtest:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
In the `chart` section I've defined the release source by specifying the Helm repository (hosted on GitHub Pages), chart name and version.
|
||||
In the `values` section I've overwritten the defaults set in values.yaml.
|
||||
|
||||
With the `flux.weave.works` annotations I instruct Flux to automate this release.
|
||||
When an image tag in the sem ver range of `1.4.0 - 1.4.99` is pushed to Quay,
|
||||
Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
||||
|
||||
Install [Weave Flux](https://github.com/weaveworks/flux) and its Helm Operator by specifying your Git repo URL:
|
||||
|
||||
```bash
|
||||
helm repo add weaveworks https://weaveworks.github.io/flux
|
||||
|
||||
helm install --name flux \
|
||||
--set helmOperator.create=true \
|
||||
--set git.url=git@github.com:<USERNAME>/<REPOSITORY> \
|
||||
--namespace flux \
|
||||
weaveworks/flux
|
||||
```
|
||||
|
||||
At startup Flux generates a SSH key and logs the public key. Find the SSH public key with:
|
||||
|
||||
```bash
|
||||
kubectl -n flux logs deployment/flux | grep identity.pub | cut -d '"' -f2
|
||||
```
|
||||
|
||||
In order to sync your cluster state with Git you need to copy the public key and create a
|
||||
deploy key with write access on your GitHub repository.
|
||||
|
||||
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_,
|
||||
check _Allow write access_, paste the Flux public key and click _Add key_.
|
||||
|
||||
After a couple of seconds Flux will apply the Kubernetes resources from Git and Flagger will
|
||||
launch the `frontend` and `backend` apps.
|
||||
|
||||
A CI/CD pipeline for the `frontend` release could look like this:
|
||||
|
||||
* cut a release from the master branch of the podinfo code repo with the git tag `1.4.1`
|
||||
* CI builds the image and pushes the `podinfo:1.4.1` image to the container registry
|
||||
* Flux scans the registry and updates the Helm release `image.tag` to `1.4.1`
|
||||
* Flux commits and push the change to the cluster repo
|
||||
* Flux applies the updated Helm release on the cluster
|
||||
* Flux Helm Operator picks up the change and calls Tiller to upgrade the release
|
||||
* Flagger detects a revision change and scales up the `frontend` deployment
|
||||
* Flagger starts the load test and runs the canary analysis
|
||||
* Based on the analysis result the canary deployment is promoted to production or rolled back
|
||||
* Flagger sends a Slack notification with the canary result
|
||||
|
||||
If the canary fails, fix the bug, do another patch release eg `1.4.2` and the whole process will run again.
|
||||
|
||||
A canary deployment can fail due to any of the following reasons:
|
||||
|
||||
* the container image can't be downloaded
|
||||
* the deployment replica set is stuck for more then ten minutes (eg. due to a container crash loop)
|
||||
* the webooks (acceptance tests, load tests, etc) are returning a non 2xx response
|
||||
* the HTTP success rate (non 5xx responses) metric drops under the threshold
|
||||
* the HTTP average duration metric goes over the threshold
|
||||
* the Istio telemetry service is unable to collect traffic metrics
|
||||
* the metrics server (Prometheus) can't be reached
|
||||
|
||||
If you want to find out more about managing Helm releases with Flux here is an in-depth guide
|
||||
[github.com/stefanprodan/gitops-helm](https://github.com/stefanprodan/gitops-helm).
|
||||
206
docs/gitbook/tutorials/zero-downtime-deployments.md
Normal file
@@ -0,0 +1,206 @@
|
||||
# Zero downtime deployments
|
||||
|
||||
This is a list of things you should consider when dealing with a high traffic production environment if you want to
|
||||
minimise the impact of rolling updates and downscaling.
|
||||
|
||||
### Deployment strategy
|
||||
|
||||
Limit the number of unavailable pods during a rolling update:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
progressDeadlineSeconds: 120
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
```
|
||||
|
||||
The default progress deadline for a deployment is ten minutes.
|
||||
You should consider adjusting this value to make the deployment process fail faster.
|
||||
|
||||
### Liveness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if
|
||||
your app transitioned to a broken state from which it can't recover and needs to be restarted.
|
||||
|
||||
```yaml
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
```
|
||||
|
||||
If you've enabled mTLS, you'll have to use `exec` for liveness and readiness checks since
|
||||
kubelet is not part of the service mesh and doesn't have access to the TLS cert.
|
||||
|
||||
### Readiness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if
|
||||
your app is ready to receive traffic.
|
||||
|
||||
```yaml
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/readyz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
periodSeconds: 5
|
||||
```
|
||||
|
||||
If your app depends on external services, you should check if those services are available before allowing Kubernetes
|
||||
to route traffic to an app instance. Keep in mind that the Envoy sidecar can have a slower startup than your app.
|
||||
This means that on application start you should retry for at least a couple of seconds any external connection.
|
||||
|
||||
### Graceful shutdown
|
||||
|
||||
Before a pod gets terminated, Kubernetes sends a `SIGTERM` signal to every container and waits for period of
|
||||
time (30s by default) for all containers to exit gracefully. If your app doesn't handle the `SIGTERM` signal or if it
|
||||
doesn't exit within the grace period, Kubernetes will kill the container and any inflight requests that your app is
|
||||
processing will fail.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 60
|
||||
containers:
|
||||
- name: app
|
||||
lifecycle:
|
||||
preStop:
|
||||
exec:
|
||||
command:
|
||||
- sleep
|
||||
- "10"
|
||||
```
|
||||
|
||||
Your app container should have a `preStop` hook that delays the container shutdown.
|
||||
This will allow the service mesh to drain the traffic and remove this pod from all other Envoy sidecars before your app
|
||||
becomes unavailable.
|
||||
|
||||
### Delay Envoy shutdown
|
||||
|
||||
Even if your app reacts to `SIGTERM` and tries to complete the inflight requests before shutdown, that
|
||||
doesn't mean that the response will make it back to the caller. If the Envoy sidecar shuts down before your app, then
|
||||
the caller will receive a 503 error.
|
||||
|
||||
To mitigate this issue you can add a `preStop` hook to the Istio proxy and wait for the main app to exist before Envoy exists.
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
set -e
|
||||
if ! pidof envoy &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
if ! pidof pilot-agent &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do
|
||||
sleep 1;
|
||||
done
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
You'll have to build your own Envoy docker image with the above script and
|
||||
modify the Istio injection webhook with the `preStop` directive.
|
||||
|
||||
Thanks to Stono for his excellent [tips](https://github.com/istio/istio/issues/12183) on minimising 503s.
|
||||
|
||||
### Resource requests and limits
|
||||
|
||||
Setting CPU and memory requests/limits for all workloads is a mandatory step if you're running a production system.
|
||||
Without limits your nodes could run out of memory or become unresponsive due to CPU exhausting.
|
||||
Without CPU and memory requests,
|
||||
the Kubernetes scheduler will not be able to make decisions about which nodes to place pods on.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: app
|
||||
resources:
|
||||
limits:
|
||||
cpu: 1000m
|
||||
memory: 1Gi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 128Mi
|
||||
```
|
||||
|
||||
Note that without resource requests the horizontal pod autoscaler can't determine when to scale your app.
|
||||
|
||||
### Autoscaling
|
||||
|
||||
A production environment should be able to handle traffic bursts without impacting the quality of service.
|
||||
This can be achieved with Kubernetes autoscaling capabilities.
|
||||
Autoscaling in Kubernetes has two dimensions: the Cluster Autoscaler that deals with node scaling operations and
|
||||
the Horizontal Pod Autoscaler that automatically scales the number of pods in a deployment.
|
||||
|
||||
```yaml
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: app
|
||||
minReplicas: 2
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageValue: 900m
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageValue: 768Mi
|
||||
```
|
||||
|
||||
The above HPA ensures your app will be scaled up before the pods reach the CPU or memory limits.
|
||||
|
||||
### Ingress retries
|
||||
|
||||
To minimise the impact of downscaling operations you can make use of Envoy retry capabilities.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
hosts:
|
||||
- app.example.com
|
||||
appendHeaders:
|
||||
x-envoy-upstream-rq-timeout-ms: "15000"
|
||||
x-envoy-max-retries: "10"
|
||||
x-envoy-retry-on: "gateway-error,connect-failure,refused-stream"
|
||||
```
|
||||
|
||||
When the HPA scales down your app, your users could run into 503 errors.
|
||||
The above configuration will make Envoy retry the HTTP requests that failed due to gateway errors.
|
||||
@@ -17,7 +17,14 @@ kubectl apply -f ${REPO}/artifacts/canaries/deployment.yaml
|
||||
kubectl apply -f ${REPO}/artifacts/canaries/hpa.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace example.com with your own domain\):
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/deployment.yaml
|
||||
kubectl -n test apply -f ${REPO}/artifacts/loadtester/service.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace example.com with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha3
|
||||
@@ -70,6 +77,13 @@ spec:
|
||||
# milliseconds
|
||||
threshold: 500
|
||||
interval: 30s
|
||||
# generate traffic during analysis
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
@@ -99,7 +113,7 @@ Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.2.1
|
||||
podinfod=quay.io/stefanprodan/podinfo:1.4.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
@@ -132,6 +146,8 @@ Events:
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
@@ -167,7 +183,8 @@ Generate latency:
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
146
docs/index.yaml
@@ -1,146 +0,0 @@
|
||||
apiVersion: v1
|
||||
entries:
|
||||
flagger:
|
||||
- apiVersion: v1
|
||||
appVersion: 0.4.0
|
||||
created: 2019-01-18T12:49:18.099861+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: fe06de1c68c6cc414440ef681cde67ae02c771de9b1e4d2d264c38a7a9c37b3d
|
||||
engine: gotpl
|
||||
home: https://docs.flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- gitops
|
||||
kubeVersion: '>=1.11.0-0'
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
name: flagger
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.4.0.tgz
|
||||
version: 0.4.0
|
||||
- apiVersion: v1
|
||||
appVersion: 0.3.0
|
||||
created: 2019-01-18T12:49:18.099501+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: 8baa478cc802f4e6b7593934483359b8f70ec34413ca3b8de3a692e347a9bda4
|
||||
engine: gotpl
|
||||
home: https://docs.flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- gitops
|
||||
kubeVersion: '>=1.9.0-0'
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
name: flagger
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.3.0.tgz
|
||||
version: 0.3.0
|
||||
- apiVersion: v1
|
||||
appVersion: 0.2.0
|
||||
created: 2019-01-18T12:49:18.099162+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: 800b5fd1a0b2854ee8412b3170c36ecda3d382f209e18b475ee1d5e3c7fa2f83
|
||||
engine: gotpl
|
||||
home: https://flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- gitops
|
||||
kubeVersion: '>=1.9.0-0'
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
name: flagger
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.2.0.tgz
|
||||
version: 0.2.0
|
||||
- apiVersion: v1
|
||||
appVersion: 0.1.2
|
||||
created: 2019-01-18T12:49:18.098811+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: 0029ef8dd20ebead3d84638eaa4b44d60b3e2bd953b4b7a1169963ce93a4e87c
|
||||
engine: gotpl
|
||||
home: https://flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
keywords:
|
||||
- canary
|
||||
- istio
|
||||
- gitops
|
||||
kubeVersion: '>=1.9.0-0'
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
name: flagger
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.1.2.tgz
|
||||
version: 0.1.2
|
||||
- apiVersion: v1
|
||||
appVersion: 0.1.1
|
||||
created: 2019-01-18T12:49:18.098439+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: 2bb8f72fcf63a5ba5ecbaa2ab0d0446f438ec93fbf3a598cd7de45e64d8f9628
|
||||
home: https://github.com/stefanprodan/flagger
|
||||
name: flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.1.1.tgz
|
||||
version: 0.1.1
|
||||
- apiVersion: v1
|
||||
appVersion: 0.1.0
|
||||
created: 2019-01-18T12:49:18.098153+02:00
|
||||
description: Flagger is a Kubernetes operator that automates the promotion of
|
||||
canary deployments using Istio routing for traffic shifting and Prometheus metrics
|
||||
for canary analysis.
|
||||
digest: 03e05634149e13ddfddae6757266d65c271878a026c21c7d1429c16712bf3845
|
||||
home: https://github.com/stefanprodan/flagger
|
||||
name: flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/flagger-0.1.0.tgz
|
||||
version: 0.1.0
|
||||
grafana:
|
||||
- apiVersion: v1
|
||||
appVersion: 5.4.2
|
||||
created: 2019-01-18T12:49:18.100331+02:00
|
||||
description: Grafana dashboards for monitoring Flagger canary deployments
|
||||
digest: 97257d1742aca506f8703922d67863c459c1b43177870bc6050d453d19a683c0
|
||||
home: https://flagger.app
|
||||
icon: https://raw.githubusercontent.com/stefanprodan/flagger/master/docs/logo/flagger-icon.png
|
||||
maintainers:
|
||||
- email: stefanprodan@users.noreply.github.com
|
||||
name: stefanprodan
|
||||
url: https://github.com/stefanprodan
|
||||
name: grafana
|
||||
sources:
|
||||
- https://github.com/stefanprodan/flagger
|
||||
urls:
|
||||
- https://stefanprodan.github.io/flagger/grafana-0.1.0.tgz
|
||||
version: 0.1.0
|
||||
generated: 2019-01-18T12:49:18.097682+02:00
|
||||
BIN
docs/screens/demo-backend-dashboard.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 523 KiB |
BIN
docs/screens/demo-frontend-dashboard.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 349 KiB |
BIN
docs/screens/demo-frontend-jaeger.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 497 KiB |
BIN
docs/screens/demo-frontend.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 131 KiB |
BIN
docs/screens/flagger-grafana-dashboard.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 523 KiB |
{kind=link}
|
Before Width: | Height: | Size: 442 KiB After Width: | Height: | Size: 440 KiB |
@@ -23,6 +23,6 @@ CODEGEN_PKG=${CODEGEN_PKG:-$(cd ${SCRIPT_ROOT}; ls -d -1 ./vendor/k8s.io/code-ge
|
||||
|
||||
${CODEGEN_PKG}/generate-groups.sh "deepcopy,client,informer,lister" \
|
||||
github.com/stefanprodan/flagger/pkg/client github.com/stefanprodan/flagger/pkg/apis \
|
||||
flagger:v1alpha3 \
|
||||
"istio:v1alpha3 flagger:v1alpha3" \
|
||||
--go-header-file ${SCRIPT_ROOT}/hack/boilerplate.go.txt
|
||||
|
||||
|
||||
@@ -17,6 +17,7 @@ limitations under the License.
|
||||
package v1alpha3
|
||||
|
||||
import (
|
||||
istiov1alpha3 "github.com/stefanprodan/flagger/pkg/apis/istio/v1alpha3"
|
||||
hpav1 "k8s.io/api/autoscaling/v1"
|
||||
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
|
||||
"time"
|
||||
@@ -26,6 +27,7 @@ const (
|
||||
CanaryKind = "Canary"
|
||||
ProgressDeadlineSeconds = 600
|
||||
AnalysisInterval = 60 * time.Second
|
||||
MetricInterval = "1m"
|
||||
)
|
||||
|
||||
// +genclient
|
||||
@@ -58,6 +60,10 @@ type CanarySpec struct {
|
||||
// the maximum time in seconds for a canary deployment to make progress
|
||||
// before it is considered to be failed. Defaults to ten minutes.
|
||||
ProgressDeadlineSeconds *int32 `json:"progressDeadlineSeconds,omitempty"`
|
||||
|
||||
// promote the canary without analysing it
|
||||
// +optional
|
||||
SkipAnalysis bool `json:"skipAnalysis,omitempty"`
|
||||
}
|
||||
|
||||
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
|
||||
@@ -93,6 +99,8 @@ type CanaryStatus struct {
|
||||
FailedChecks int `json:"failedChecks"`
|
||||
CanaryWeight int `json:"canaryWeight"`
|
||||
// +optional
|
||||
TrackedConfigs *map[string]string `json:"trackedConfigs,omitempty"`
|
||||
// +optional
|
||||
LastAppliedSpec string `json:"lastAppliedSpec,omitempty"`
|
||||
// +optional
|
||||
LastTransitionTime metav1.Time `json:"lastTransitionTime,omitempty"`
|
||||
@@ -101,9 +109,15 @@ type CanaryStatus struct {
|
||||
// CanaryService is used to create ClusterIP services
|
||||
// and Istio Virtual Service
|
||||
type CanaryService struct {
|
||||
Port int32 `json:"port"`
|
||||
Gateways []string `json:"gateways"`
|
||||
Hosts []string `json:"hosts"`
|
||||
Port int32 `json:"port"`
|
||||
Gateways []string `json:"gateways"`
|
||||
Hosts []string `json:"hosts"`
|
||||
Match []istiov1alpha3.HTTPMatchRequest `json:"match,omitempty"`
|
||||
Rewrite *istiov1alpha3.HTTPRewrite `json:"rewrite,omitempty"`
|
||||
Timeout string `json:"timeout,omitempty"`
|
||||
Retries *istiov1alpha3.HTTPRetry `json:"retries,omitempty"`
|
||||
Headers *istiov1alpha3.Headers `json:"headers,omitempty"`
|
||||
CorsPolicy *istiov1alpha3.CorsPolicy `json:"corsPolicy,omitempty"`
|
||||
}
|
||||
|
||||
// CanaryAnalysis is used to describe how the analysis should be done
|
||||
@@ -118,9 +132,11 @@ type CanaryAnalysis struct {
|
||||
|
||||
// CanaryMetric holds the reference to Istio metrics used for canary analysis
|
||||
type CanaryMetric struct {
|
||||
Name string `json:"name"`
|
||||
Interval string `json:"interval"`
|
||||
Threshold int `json:"threshold"`
|
||||
Name string `json:"name"`
|
||||
Interval string `json:"interval,omitempty"`
|
||||
Threshold float64 `json:"threshold"`
|
||||
// +optional
|
||||
Query string `json:"query,omitempty"`
|
||||
}
|
||||
|
||||
// CanaryWebhook holds the reference to external checks used for canary analysis
|
||||
@@ -134,9 +150,9 @@ type CanaryWebhook struct {
|
||||
|
||||
// CanaryWebhookPayload holds the deployment info and metadata sent to webhooks
|
||||
type CanaryWebhookPayload struct {
|
||||
Name string `json:"name"`
|
||||
Namespace string `json:"namespace"`
|
||||
Metadata *map[string]string `json:"metadata,omitempty"`
|
||||
Name string `json:"name"`
|
||||
Namespace string `json:"namespace"`
|
||||
Metadata map[string]string `json:"metadata,omitempty"`
|
||||
}
|
||||
|
||||
// GetProgressDeadlineSeconds returns the progress deadline (default 600s)
|
||||
@@ -161,3 +177,8 @@ func (c *Canary) GetAnalysisInterval() time.Duration {
|
||||
|
||||
return interval
|
||||
}
|
||||
|
||||
// GetMetricInterval returns the metric interval default value (1m)
|
||||
func (c *Canary) GetMetricInterval() string {
|
||||
return MetricInterval
|
||||
}
|
||||
|
||||
@@ -21,6 +21,7 @@ limitations under the License.
|
||||
package v1alpha3
|
||||
|
||||
import (
|
||||
istiov1alpha3 "github.com/stefanprodan/flagger/pkg/apis/istio/v1alpha3"
|
||||
v1 "k8s.io/api/autoscaling/v1"
|
||||
runtime "k8s.io/apimachinery/pkg/runtime"
|
||||
)
|
||||
@@ -143,6 +144,33 @@ func (in *CanaryService) DeepCopyInto(out *CanaryService) {
|
||||
*out = make([]string, len(*in))
|
||||
copy(*out, *in)
|
||||
}
|
||||
if in.Match != nil {
|
||||
in, out := &in.Match, &out.Match
|
||||
*out = make([]istiov1alpha3.HTTPMatchRequest, len(*in))
|
||||
for i := range *in {
|
||||
(*in)[i].DeepCopyInto(&(*out)[i])
|
||||
}
|
||||
}
|
||||
if in.Rewrite != nil {
|
||||
in, out := &in.Rewrite, &out.Rewrite
|
||||
*out = new(istiov1alpha3.HTTPRewrite)
|
||||
**out = **in
|
||||
}
|
||||
if in.Retries != nil {
|
||||
in, out := &in.Retries, &out.Retries
|
||||
*out = new(istiov1alpha3.HTTPRetry)
|
||||
**out = **in
|
||||
}
|
||||
if in.Headers != nil {
|
||||
in, out := &in.Headers, &out.Headers
|
||||
*out = new(istiov1alpha3.Headers)
|
||||
(*in).DeepCopyInto(*out)
|
||||
}
|
||||
if in.CorsPolicy != nil {
|
||||
in, out := &in.CorsPolicy, &out.CorsPolicy
|
||||
*out = new(istiov1alpha3.CorsPolicy)
|
||||
(*in).DeepCopyInto(*out)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
@@ -188,6 +216,17 @@ func (in *CanarySpec) DeepCopy() *CanarySpec {
|
||||
// DeepCopyInto is an autogenerated deepcopy function, copying the receiver, writing into out. in must be non-nil.
|
||||
func (in *CanaryStatus) DeepCopyInto(out *CanaryStatus) {
|
||||
*out = *in
|
||||
if in.TrackedConfigs != nil {
|
||||
in, out := &in.TrackedConfigs, &out.TrackedConfigs
|
||||
*out = new(map[string]string)
|
||||
if **in != nil {
|
||||
in, out := *in, *out
|
||||
*out = make(map[string]string, len(*in))
|
||||
for key, val := range *in {
|
||||
(*out)[key] = val
|
||||
}
|
||||
}
|
||||
}
|
||||
in.LastTransitionTime.DeepCopyInto(&out.LastTransitionTime)
|
||||
return
|
||||
}
|
||||
@@ -234,13 +273,9 @@ func (in *CanaryWebhookPayload) DeepCopyInto(out *CanaryWebhookPayload) {
|
||||
*out = *in
|
||||
if in.Metadata != nil {
|
||||
in, out := &in.Metadata, &out.Metadata
|
||||
*out = new(map[string]string)
|
||||
if **in != nil {
|
||||
in, out := *in, *out
|
||||
*out = make(map[string]string, len(*in))
|
||||
for key, val := range *in {
|
||||
(*out)[key] = val
|
||||
}
|
||||
*out = make(map[string]string, len(*in))
|
||||
for key, val := range *in {
|
||||
(*out)[key] = val
|
||||
}
|
||||
}
|
||||
return
|
||||
|
||||
19
pkg/apis/istio/common/v1alpha1/string.go
Normal file
@@ -0,0 +1,19 @@
|
||||
package v1alpha1
|
||||
|
||||
// Describes how to match a given string in HTTP headers. Match is
|
||||
// case-sensitive.
|
||||
type StringMatch struct {
|
||||
// Specified exactly one of the fields below.
|
||||
|
||||
// exact string match
|
||||
Exact string `json:"exact,omitempty"`
|
||||
|
||||
// prefix-based match
|
||||
Prefix string `json:"prefix,omitempty"`
|
||||
|
||||
// suffix-based match.
|
||||
Suffix string `json:"suffix,omitempty"`
|
||||
|
||||
// ECMAscript style regex-based match
|
||||
Regex string `json:"regex,omitempty"`
|
||||
}
|
||||
5
pkg/apis/istio/register.go
Normal file
@@ -0,0 +1,5 @@
|
||||
package istio
|
||||
|
||||
const (
|
||||
GroupName = "networking.istio.io"
|
||||
)
|
||||