mirror of
https://github.com/jpetazzo/container.training.git
synced 2026-03-01 00:40:19 +00:00
Compare commits
63 Commits
2025-01-en
...
2025-10-ar
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
964a325fcd | ||
|
|
b9bf015c50 | ||
|
|
21b8ac6085 | ||
|
|
38562fe788 | ||
|
|
6ab0aa11ae | ||
|
|
62237556b1 | ||
|
|
f7da1ae656 | ||
|
|
adbd10506a | ||
|
|
487968dee5 | ||
|
|
093f31c25f | ||
|
|
eaec3e6148 | ||
|
|
84a1124461 | ||
|
|
dd747ac726 | ||
|
|
4a8725fde4 | ||
|
|
55f9b2e21d | ||
|
|
4f84fab763 | ||
|
|
b88218a9a1 | ||
|
|
01e46bfa37 | ||
|
|
86efafeb85 | ||
|
|
4d17cab888 | ||
|
|
c7a2b7a12d | ||
|
|
305dbe24ed | ||
|
|
6cffc0e2e7 | ||
|
|
2b8298c0c2 | ||
|
|
26e1309218 | ||
|
|
38714b4e2b | ||
|
|
2b0fae3c94 | ||
|
|
0fd5499233 | ||
|
|
0e4d7df9fc | ||
|
|
9175a5c42a | ||
|
|
d090aec9f6 | ||
|
|
08c702423f | ||
|
|
5d5aad347b | ||
|
|
2390783cfd | ||
|
|
10fbfa135a | ||
|
|
64376c5ec2 | ||
|
|
b536318b03 | ||
|
|
2a8bbfb719 | ||
|
|
a3c2c92984 | ||
|
|
1062c519b8 | ||
|
|
bc0ac34f5b | ||
|
|
4896a91bd4 | ||
|
|
303dc93ac8 | ||
|
|
785d704726 | ||
|
|
cd346ecace | ||
|
|
4de3c303a6 | ||
|
|
121713a6c7 | ||
|
|
4431cfe68a | ||
|
|
dcf218dbe2 | ||
|
|
43ff815d9f | ||
|
|
92e61ef83b | ||
|
|
45770cc584 | ||
|
|
58700396f9 | ||
|
|
8783da014c | ||
|
|
f780100217 | ||
|
|
555cd058bb | ||
|
|
a05d1f9d4f | ||
|
|
84365d03c6 | ||
|
|
164bc01388 | ||
|
|
c07116bd29 | ||
|
|
c4057f9c35 | ||
|
|
f57bd9a072 | ||
|
|
fca6396540 |
26
.devcontainer/devcontainer.json
Normal file
26
.devcontainer/devcontainer.json
Normal file
@@ -0,0 +1,26 @@
|
||||
{
|
||||
"name": "container.training environment to get started with Docker and/or Kubernetes",
|
||||
"image": "ghcr.io/jpetazzo/shpod",
|
||||
"features": {
|
||||
//"ghcr.io/devcontainers/features/common-utils:2": {}
|
||||
},
|
||||
|
||||
// Use 'forwardPorts' to make a list of ports inside the container available locally.
|
||||
"forwardPorts": [],
|
||||
|
||||
//"postCreateCommand": "... install extra packages...",
|
||||
"postStartCommand": "dind.sh",
|
||||
|
||||
// This lets us use "docker-outside-docker".
|
||||
// Unfortunately, minikube, kind, etc. don't work very well that way;
|
||||
// so for now, we'll likely use "docker-in-docker" instead (with a
|
||||
// privilege dcontainer). But we're still exposing that socket in case
|
||||
// someone wants to do something interesting with it.
|
||||
"mounts": ["source=/var/run/docker.sock,target=/var/run/docker-host.sock,type=bind"],
|
||||
|
||||
// This is for docker-in-docker.
|
||||
"privileged": true,
|
||||
|
||||
// Uncomment to connect as root instead. More info: https://aka.ms/dev-containers-non-root.
|
||||
"remoteUser": "k8s"
|
||||
}
|
||||
@@ -1,7 +1,7 @@
|
||||
FROM ruby:alpine
|
||||
RUN apk add --update build-base curl
|
||||
RUN gem install sinatra --version '~> 3'
|
||||
RUN gem install thin
|
||||
RUN gem install thin --version '~> 1'
|
||||
ADD hasher.rb /
|
||||
CMD ["ruby", "hasher.rb"]
|
||||
EXPOSE 80
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
FROM node:4-slim
|
||||
RUN npm install express
|
||||
RUN npm install express@4
|
||||
RUN npm install redis@3
|
||||
COPY files/ /files/
|
||||
COPY webui.js /
|
||||
|
||||
33
k8s/blue.yaml
Normal file
33
k8s/blue.yaml
Normal file
@@ -0,0 +1,33 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
name: blue
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: blue
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
spec:
|
||||
containers:
|
||||
- image: jpetazzo/color
|
||||
name: color
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
name: blue
|
||||
spec:
|
||||
ports:
|
||||
- name: "80"
|
||||
port: 80
|
||||
selector:
|
||||
app: blue
|
||||
@@ -0,0 +1,12 @@
|
||||
# This removes the haproxy Deployment.
|
||||
|
||||
apiVersion: kustomize.config.k8s.io/v1alpha1
|
||||
kind: Component
|
||||
|
||||
patches:
|
||||
- patch: |-
|
||||
$patch: delete
|
||||
kind: Deployment
|
||||
apiVersion: apps/v1
|
||||
metadata:
|
||||
name: haproxy
|
||||
@@ -0,0 +1,14 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1alpha1
|
||||
kind: Component
|
||||
|
||||
# Within a Kustomization, it is not possible to specify in which
|
||||
# order transformations (patches, replacements, etc) should be
|
||||
# executed. If we want to execute transformations in a specific
|
||||
# order, one possibility is to put them in individual components,
|
||||
# and then invoke these components in the order we want.
|
||||
# It works, but it creates an extra level of indirection, which
|
||||
# reduces readability and complicates maintenance.
|
||||
|
||||
components:
|
||||
- setup
|
||||
- cleanup
|
||||
@@ -0,0 +1,20 @@
|
||||
global
|
||||
#log stdout format raw local0
|
||||
#daemon
|
||||
maxconn 32
|
||||
defaults
|
||||
#log global
|
||||
timeout client 1h
|
||||
timeout connect 1h
|
||||
timeout server 1h
|
||||
mode http
|
||||
option abortonclose
|
||||
frontend metrics
|
||||
bind :9000
|
||||
http-request use-service prometheus-exporter
|
||||
frontend ollama_frontend
|
||||
bind :8000
|
||||
default_backend ollama_backend
|
||||
maxconn 16
|
||||
backend ollama_backend
|
||||
server ollama_server localhost:11434 check
|
||||
@@ -0,0 +1,39 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: haproxy
|
||||
name: haproxy
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: haproxy
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: haproxy
|
||||
spec:
|
||||
volumes:
|
||||
- name: haproxy
|
||||
configMap:
|
||||
name: haproxy
|
||||
containers:
|
||||
- image: haproxy:3.0
|
||||
name: haproxy
|
||||
volumeMounts:
|
||||
- name: haproxy
|
||||
mountPath: /usr/local/etc/haproxy
|
||||
readinessProbe:
|
||||
httpGet:
|
||||
port: 9000
|
||||
ports:
|
||||
- name: haproxy
|
||||
containerPort: 8000
|
||||
- name: metrics
|
||||
containerPort: 9000
|
||||
resources:
|
||||
requests:
|
||||
cpu: 0.05
|
||||
limits:
|
||||
cpu: 1
|
||||
@@ -0,0 +1,75 @@
|
||||
# This adds a sidecar to the ollama Deployment, by taking
|
||||
# the pod template and volumes from the haproxy Deployment.
|
||||
# The idea is to allow to run ollama+haproxy in two modes:
|
||||
# - separately (each with their own Deployment),
|
||||
# - together in the same Pod, sidecar-style.
|
||||
# The YAML files define how to run them separetely, and this
|
||||
# "replacements" directive fetches a specific volume and
|
||||
# a specific container from the haproxy Deployment, to add
|
||||
# them to the ollama Deployment.
|
||||
#
|
||||
# This would be simpler if kustomize allowed to append or
|
||||
# merge lists in "replacements"; but it doesn't seem to be
|
||||
# possible at the moment.
|
||||
#
|
||||
# It would be even better if kustomize allowed to perform
|
||||
# a strategic merge using a fieldPath as the source, because
|
||||
# we could merge both the containers and the volumes in a
|
||||
# single operation.
|
||||
#
|
||||
# Note that technically, it might be possible to layer
|
||||
# multiple kustomizations so that one generates the patch
|
||||
# to be used in another; but it wouldn't be very readable
|
||||
# or maintainable so we decided to not do that right now.
|
||||
#
|
||||
# However, the current approach (fetching fields one by one)
|
||||
# has an advantage: it could let us transform the haproxy
|
||||
# container into a real sidecar (i.e. an initContainer with
|
||||
# a restartPolicy=Always).
|
||||
|
||||
apiVersion: kustomize.config.k8s.io/v1alpha1
|
||||
kind: Component
|
||||
|
||||
resources:
|
||||
- haproxy.yaml
|
||||
|
||||
configMapGenerator:
|
||||
- name: haproxy
|
||||
files:
|
||||
- haproxy.cfg
|
||||
|
||||
replacements:
|
||||
- source:
|
||||
kind: Deployment
|
||||
name: haproxy
|
||||
fieldPath: spec.template.spec.volumes.[name=haproxy]
|
||||
targets:
|
||||
- select:
|
||||
kind: Deployment
|
||||
name: ollama
|
||||
fieldPaths:
|
||||
- spec.template.spec.volumes.[name=haproxy]
|
||||
options:
|
||||
create: true
|
||||
- source:
|
||||
kind: Deployment
|
||||
name: haproxy
|
||||
fieldPath: spec.template.spec.containers.[name=haproxy]
|
||||
targets:
|
||||
- select:
|
||||
kind: Deployment
|
||||
name: ollama
|
||||
fieldPaths:
|
||||
- spec.template.spec.containers.[name=haproxy]
|
||||
options:
|
||||
create: true
|
||||
- source:
|
||||
kind: Deployment
|
||||
name: haproxy
|
||||
fieldPath: spec.template.spec.containers.[name=haproxy].ports.[name=haproxy].containerPort
|
||||
targets:
|
||||
- select:
|
||||
kind: Service
|
||||
name: ollama
|
||||
fieldPaths:
|
||||
- spec.ports.[name=11434].targetPort
|
||||
34
k8s/kustomize-examples/ollama-with-sidecar/blue.yaml
Normal file
34
k8s/kustomize-examples/ollama-with-sidecar/blue.yaml
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
name: blue
|
||||
spec:
|
||||
replicas: 2
|
||||
selector:
|
||||
matchLabels:
|
||||
app: blue
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
spec:
|
||||
containers:
|
||||
- image: jpetazzo/color
|
||||
name: color
|
||||
ports:
|
||||
- containerPort: 80
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: blue
|
||||
name: blue
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
selector:
|
||||
app: blue
|
||||
@@ -0,0 +1,94 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: Kustomization
|
||||
|
||||
# Each of these YAML files contains a Deployment and a Service.
|
||||
# The blue.yaml file is here just to demonstrate that the rest
|
||||
# of this Kustomization can be precisely scoped to the ollama
|
||||
# Deployment (and Service): the blue Deployment and Service
|
||||
# shouldn't be affected by our kustomize transformers.
|
||||
resources:
|
||||
- ollama.yaml
|
||||
- blue.yaml
|
||||
|
||||
buildMetadata:
|
||||
|
||||
# Add a label app.kubernetes.io/managed-by=kustomize-vX.Y.Z
|
||||
- managedByLabel
|
||||
|
||||
# Add an annotation config.kubernetes.io/origin, indicating:
|
||||
# - which file defined that resource;
|
||||
# - if it comes from a git repository, which one, and which
|
||||
# ref (tag, branch...) it was.
|
||||
- originAnnotations
|
||||
|
||||
# Add an annotation alpha.config.kubernetes.io/transformations
|
||||
# indicating which patches and other transformers have changed
|
||||
# each resource.
|
||||
- transformerAnnotations
|
||||
|
||||
# Let's generate a ConfigMap with literal values.
|
||||
# Note that this will actually add a suffix to the name of the
|
||||
# ConfigMaps (e.g.: ollama-8bk8bd8m76) and it will update all
|
||||
# references to the ConfigMap (e.g. in Deployment manifests)
|
||||
# accordingly. The suffix is a hash of the ConfigMap contents,
|
||||
# so that basically, if the ConfigMap is edited, any workload
|
||||
# using that ConfigMap will automatically do a rolling update.
|
||||
configMapGenerator:
|
||||
- name: ollama
|
||||
literals:
|
||||
- "model=gemma3:270m"
|
||||
- "prompt=If you visit Paris, I suggest that you"
|
||||
- "queue=4"
|
||||
name: ollama
|
||||
|
||||
patches:
|
||||
# The Deployment manifest in ollama.yaml doesn't specify
|
||||
# resource requests and limits, so that it can run on any
|
||||
# cluster (including resource-constrained local clusters
|
||||
# like KiND or minikube). The example belows add CPU
|
||||
# requests and limits using a strategic merge patch.
|
||||
# The patch is inlined here, but it could also be put
|
||||
# in a file and referenced with "path: xxxxxx.yaml".
|
||||
- patch: |
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: ollama
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: ollama
|
||||
resources:
|
||||
requests:
|
||||
cpu: 1
|
||||
limits:
|
||||
cpu: 2
|
||||
# This will have the same effect, with one little detail:
|
||||
# JSON patches cannot specify containers by name, so this
|
||||
# assumes that the ollama container is the first one in
|
||||
# the pod template (whereas the strategic merge patch can
|
||||
# use "merge keys" and identify containers by their name).
|
||||
#- target:
|
||||
# kind: Deployment
|
||||
# name: ollama
|
||||
# patch: |
|
||||
# - op: add
|
||||
# path: /spec/template/spec/containers/0/resources
|
||||
# value:
|
||||
# requests:
|
||||
# cpu: 1
|
||||
# limits:
|
||||
# cpu: 2
|
||||
|
||||
# A "component" is a bit like a "base", in the sense that
|
||||
# it lets us define some reusable resources and behaviors.
|
||||
# There is a key different, though:
|
||||
# - a "base" will be evaluated in isolation: it will
|
||||
# generate+transform some resources, then these resources
|
||||
# will be included in the main Kustomization;
|
||||
# - a "component" has access to all the resources that
|
||||
# have been generated by the main Kustomization, which
|
||||
# means that it can transform them (with patches etc).
|
||||
components:
|
||||
- add-haproxy-sidecar
|
||||
73
k8s/kustomize-examples/ollama-with-sidecar/ollama.yaml
Normal file
73
k8s/kustomize-examples/ollama-with-sidecar/ollama.yaml
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: ollama
|
||||
name: ollama
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: ollama
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: ollama
|
||||
spec:
|
||||
volumes:
|
||||
- name: ollama
|
||||
hostPath:
|
||||
path: /opt/ollama
|
||||
type: DirectoryOrCreate
|
||||
containers:
|
||||
- image: ollama/ollama
|
||||
name: ollama
|
||||
env:
|
||||
- name: OLLAMA_MAX_QUEUE
|
||||
valueFrom:
|
||||
configMapKeyRef:
|
||||
name: ollama
|
||||
key: queue
|
||||
- name: MODEL
|
||||
valueFrom:
|
||||
configMapKeyRef:
|
||||
name: ollama
|
||||
key: model
|
||||
volumeMounts:
|
||||
- name: ollama
|
||||
mountPath: /root/.ollama
|
||||
lifecycle:
|
||||
postStart:
|
||||
exec:
|
||||
command:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- ollama pull $MODEL
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
port: 11434
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- ollama show $MODEL
|
||||
ports:
|
||||
- name: ollama
|
||||
containerPort: 11434
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: ollama
|
||||
name: ollama
|
||||
spec:
|
||||
ports:
|
||||
- name: "11434"
|
||||
port: 11434
|
||||
protocol: TCP
|
||||
targetPort: 11434
|
||||
selector:
|
||||
app: ollama
|
||||
type: ClusterIP
|
||||
@@ -0,0 +1,5 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: Kustomization
|
||||
resources:
|
||||
- microservices
|
||||
- redis
|
||||
@@ -0,0 +1,13 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: Kustomization
|
||||
resources:
|
||||
- microservices.yaml
|
||||
transformers:
|
||||
- |
|
||||
apiVersion: builtin
|
||||
kind: PrefixSuffixTransformer
|
||||
metadata:
|
||||
name: use-ghcr-io
|
||||
prefix: ghcr.io/
|
||||
fieldSpecs:
|
||||
- path: spec/template/spec/containers/image
|
||||
@@ -0,0 +1,125 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
name: hasher
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: hasher
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/hasher:v0.1
|
||||
name: hasher
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
name: hasher
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: hasher
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
name: rng
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: rng
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/rng:v0.1
|
||||
name: rng
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
name: rng
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: rng
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
name: webui
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: webui
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/webui:v0.1
|
||||
name: webui
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
name: webui
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: webui
|
||||
type: NodePort
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: worker
|
||||
name: worker
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: worker
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: worker
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/worker:v0.1
|
||||
name: worker
|
||||
@@ -0,0 +1,4 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: Kustomization
|
||||
resources:
|
||||
- redis.yaml
|
||||
@@ -0,0 +1,35 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
name: redis
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: redis
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
spec:
|
||||
containers:
|
||||
- image: redis
|
||||
name: redis
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
name: redis
|
||||
spec:
|
||||
ports:
|
||||
- port: 6379
|
||||
protocol: TCP
|
||||
targetPort: 6379
|
||||
selector:
|
||||
app: redis
|
||||
type: ClusterIP
|
||||
@@ -0,0 +1,160 @@
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
name: hasher
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: hasher
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/hasher:v0.1
|
||||
name: hasher
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: hasher
|
||||
name: hasher
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: hasher
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
name: redis
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: redis
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
spec:
|
||||
containers:
|
||||
- image: redis
|
||||
name: redis
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: redis
|
||||
name: redis
|
||||
spec:
|
||||
ports:
|
||||
- port: 6379
|
||||
protocol: TCP
|
||||
targetPort: 6379
|
||||
selector:
|
||||
app: redis
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
name: rng
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: rng
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/rng:v0.1
|
||||
name: rng
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: rng
|
||||
name: rng
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: rng
|
||||
type: ClusterIP
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
name: webui
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: webui
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/webui:v0.1
|
||||
name: webui
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
app: webui
|
||||
name: webui
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 80
|
||||
selector:
|
||||
app: webui
|
||||
type: NodePort
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
labels:
|
||||
app: worker
|
||||
name: worker
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: worker
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: worker
|
||||
spec:
|
||||
containers:
|
||||
- image: dockercoins/worker:v0.1
|
||||
name: worker
|
||||
@@ -0,0 +1,30 @@
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: Kustomization
|
||||
resources:
|
||||
- dockercoins.yaml
|
||||
replacements:
|
||||
- sourceValue: ghcr.io/dockercoins
|
||||
targets:
|
||||
- select:
|
||||
kind: Deployment
|
||||
labelSelector: "app in (hasher,rng,webui,worker)"
|
||||
# It will soon be possible to use regexes in replacement selectors,
|
||||
# meaning that the "labelSelector:" above can be replaced with the
|
||||
# following "name:" selector which is a tiny bit simpler:
|
||||
#name: hasher|rng|webui|worker
|
||||
# Regex support in replacement selectors was added by this PR:
|
||||
# https://github.com/kubernetes-sigs/kustomize/pull/5863
|
||||
# This PR was merged in August 2025, but as of October 2025, the
|
||||
# latest release of Kustomize is 5.7.1, which was released in July.
|
||||
# Hopefully the feature will be available in the next release :)
|
||||
# Another possibility would be to select all Deployments, and then
|
||||
# reject the one(s) for which we don't want to update the registry;
|
||||
# for instance:
|
||||
#reject:
|
||||
# kind: Deployment
|
||||
# name: redis
|
||||
fieldPaths:
|
||||
- spec.template.spec.containers.*.image
|
||||
options:
|
||||
delimiter: "/"
|
||||
index: 0
|
||||
@@ -3,7 +3,6 @@ kind: ClusterPolicy
|
||||
metadata:
|
||||
name: pod-color-policy-1
|
||||
spec:
|
||||
validationFailureAction: enforce
|
||||
rules:
|
||||
- name: ensure-pod-color-is-valid
|
||||
match:
|
||||
@@ -18,5 +17,6 @@ spec:
|
||||
operator: NotIn
|
||||
values: [ red, green, blue ]
|
||||
validate:
|
||||
failureAction: Enforce
|
||||
message: "If it exists, the label color must be red, green, or blue."
|
||||
deny: {}
|
||||
|
||||
@@ -3,7 +3,6 @@ kind: ClusterPolicy
|
||||
metadata:
|
||||
name: pod-color-policy-2
|
||||
spec:
|
||||
validationFailureAction: enforce
|
||||
background: false
|
||||
rules:
|
||||
- name: prevent-color-change
|
||||
@@ -22,6 +21,7 @@ spec:
|
||||
operator: NotEquals
|
||||
value: ""
|
||||
validate:
|
||||
failureAction: Enforce
|
||||
message: "Once label color has been added, it cannot be changed."
|
||||
deny:
|
||||
conditions:
|
||||
|
||||
@@ -3,7 +3,6 @@ kind: ClusterPolicy
|
||||
metadata:
|
||||
name: pod-color-policy-3
|
||||
spec:
|
||||
validationFailureAction: enforce
|
||||
background: false
|
||||
rules:
|
||||
- name: prevent-color-change
|
||||
@@ -22,7 +21,6 @@ spec:
|
||||
operator: Equals
|
||||
value: ""
|
||||
validate:
|
||||
failureAction: Enforce
|
||||
message: "Once label color has been added, it cannot be removed."
|
||||
deny:
|
||||
conditions:
|
||||
|
||||
deny: {}
|
||||
|
||||
@@ -66,7 +66,7 @@ Here is where we look for credentials for each provider:
|
||||
- Civo: CLI configuration file (`~/.civo.json`)
|
||||
- Digital Ocean: CLI configuration file (`~/.config/doctl/config.yaml`)
|
||||
- Exoscale: CLI configuration file (`~/.config/exoscale/exoscale.toml`)
|
||||
- Google Cloud: FIXME, note that the project name is currently hard-coded to `prepare-tf`
|
||||
- Google Cloud: we're using "Application Default Credentials (ADC)"; run `gcloud auth application-default login`; note that we'll use the default "project" set in `gcloud` unless you set the `GOOGLE_PROJECT` environment variable
|
||||
- Hetzner: CLI configuration file (`~/.config/hcloud/cli.toml`)
|
||||
- Linode: CLI configuration file (`~/.config/linode-cli`)
|
||||
- OpenStack: you will need to write a tfvars file (check [that exemple](terraform/virtual-machines/openstack/tfvars.example))
|
||||
|
||||
@@ -5,19 +5,27 @@
|
||||
# 10% CPU
|
||||
# (See https://docs.google.com/document/d/1n0lwp6rQKQUIuo_A5LQ1dgCzrmjkDjmDtNj1Jn92UrI)
|
||||
# PRO2-XS = 4 core, 16 gb
|
||||
#
|
||||
# With vspod:
|
||||
# 800 MB RAM
|
||||
# 33% CPU
|
||||
#
|
||||
|
||||
set -e
|
||||
|
||||
PROVIDER=scaleway
|
||||
STUDENTS=30
|
||||
KONKTAG=konk
|
||||
PROVIDER=linode
|
||||
STUDENTS=5
|
||||
|
||||
case "$PROVIDER" in
|
||||
linode)
|
||||
export TF_VAR_node_size=g6-standard-6
|
||||
export TF_VAR_location=eu-west
|
||||
export TF_VAR_location=fr-par
|
||||
;;
|
||||
scaleway)
|
||||
export TF_VAR_node_size=PRO2-XS
|
||||
# For tiny testing purposes, these are okay too:
|
||||
#export TF_VAR_node_size=PLAY2-NANO
|
||||
export TF_VAR_location=fr-par-2
|
||||
;;
|
||||
esac
|
||||
@@ -26,17 +34,19 @@ esac
|
||||
export KUBECONFIG=~/kubeconfig
|
||||
|
||||
if [ "$PROVIDER" = "kind" ]; then
|
||||
kind create cluster --name konk
|
||||
kind create cluster --name $KONKTAG
|
||||
ADDRTYPE=InternalIP
|
||||
else
|
||||
./labctl create --mode mk8s --settings settings/konk.env --provider $PROVIDER --tag konk
|
||||
cp tags/konk/stage2/kubeconfig.101 $KUBECONFIG
|
||||
if ! [ -f tags/$KONKTAG/stage2/kubeconfig.101 ]; then
|
||||
./labctl create --mode mk8s --settings settings/konk.env --provider $PROVIDER --tag $KONKTAG
|
||||
fi
|
||||
cp tags/$KONKTAG/stage2/kubeconfig.101 $KUBECONFIG
|
||||
ADDRTYPE=ExternalIP
|
||||
fi
|
||||
|
||||
# set external_ip labels
|
||||
kubectl get nodes -o=jsonpath='{range .items[*]}{.metadata.name} {.status.addresses[?(@.type=="'$ADDRTYPE'")].address}{"\n"}{end}' |
|
||||
while read node address; do
|
||||
while read node address ignoredaddresses; do
|
||||
kubectl label node $node external_ip=$address
|
||||
done
|
||||
|
||||
|
||||
@@ -55,7 +55,7 @@ _cmd_codeserver() {
|
||||
need_tag
|
||||
|
||||
ARCH=${ARCHITECTURE-amd64}
|
||||
CODESERVER_VERSION=4.96.2
|
||||
CODESERVER_VERSION=4.96.4
|
||||
CODESERVER_URL=https://github.com/coder/code-server/releases/download/v${CODESERVER_VERSION}/code-server-${CODESERVER_VERSION}-linux-${ARCH}.tar.gz
|
||||
pssh "
|
||||
set -e
|
||||
@@ -76,7 +76,7 @@ Description=code-server
|
||||
WantedBy=default.target
|
||||
|
||||
[Service]
|
||||
ExecStart=/usr/local/bin/code-server --bind-addr 0:1789
|
||||
ExecStart=/usr/local/bin/code-server --bind-addr [::]:1789
|
||||
Restart=always
|
||||
EOF
|
||||
sudo systemctl --user -M $USER_LOGIN@ enable code-server.service --now
|
||||
@@ -270,7 +270,27 @@ _cmd_create() {
|
||||
|
||||
ln -s ../../$SETTINGS tags/$TAG/settings.env.orig
|
||||
cp $SETTINGS tags/$TAG/settings.env
|
||||
. $SETTINGS
|
||||
|
||||
# For Google Cloud, it is necessary to specify which "project" to use.
|
||||
# Unfortunately, the Terraform provider doesn't seem to have a way
|
||||
# to detect which Google Cloud project you want to use; it has to be
|
||||
# specified one way or another. Let's decide that it should be set with
|
||||
# the GOOGLE_PROJECT env var; and if that var is not set, we'll try to
|
||||
# figure it out from gcloud.
|
||||
# (See https://github.com/hashicorp/terraform-provider-google/issues/10907#issuecomment-1015721600)
|
||||
# Since we need that variable to be set each time we'll call Terraform
|
||||
# (e.g. when destroying the environment), let's save it to the settings.env
|
||||
# file.
|
||||
if [ "$PROVIDER" = "googlecloud" ]; then
|
||||
if ! [ "$GOOGLE_PROJECT" ]; then
|
||||
info "PROVIDER=googlecloud but GOOGLE_PROJECT is not set. Detecting it."
|
||||
GOOGLE_PROJECT=$(gcloud config get project)
|
||||
info "GOOGLE_PROJECT will be set to '$GOOGLE_PROJECT'."
|
||||
fi
|
||||
echo "export GOOGLE_PROJECT=$GOOGLE_PROJECT" >> tags/$TAG/settings.env
|
||||
fi
|
||||
|
||||
. tags/$TAG/settings.env
|
||||
|
||||
echo $MODE > tags/$TAG/mode
|
||||
echo $PROVIDER > tags/$TAG/provider
|
||||
@@ -374,9 +394,13 @@ _cmd_clusterize() {
|
||||
done < /tmp/cluster
|
||||
"
|
||||
|
||||
while read line; do
|
||||
printf '{"login": "%s", "password": "%s", "ipaddrs": "%s"}\n' "$USER_LOGIN" "$USER_PASSWORD" "$line"
|
||||
done < tags/$TAG/clusters.tsv > tags/$TAG/logins.jsonl
|
||||
jq --raw-input --compact-output \
|
||||
--arg USER_LOGIN "$USER_LOGIN" --arg USER_PASSWORD "$USER_PASSWORD" '
|
||||
{
|
||||
"login": $USER_LOGIN,
|
||||
"password": $USER_PASSWORD,
|
||||
"ipaddrs": .
|
||||
}' < tags/$TAG/clusters.tsv > tags/$TAG/logins.jsonl
|
||||
|
||||
echo cluster_ok > tags/$TAG/status
|
||||
}
|
||||
@@ -1116,7 +1140,7 @@ _cmd_tailhist () {
|
||||
set -e
|
||||
sudo apt-get install unzip -y
|
||||
wget -c https://github.com/joewalnes/websocketd/releases/download/v0.3.0/websocketd-0.3.0-linux_$ARCH.zip
|
||||
unzip websocketd-0.3.0-linux_$ARCH.zip websocketd
|
||||
unzip -o websocketd-0.3.0-linux_$ARCH.zip websocketd
|
||||
sudo mv websocketd /usr/local/bin/websocketd
|
||||
sudo mkdir -p /opt/tailhist
|
||||
sudo tee /opt/tailhist.service <<EOF
|
||||
@@ -1214,14 +1238,17 @@ fi
|
||||
"
|
||||
}
|
||||
|
||||
_cmd ssh "Open an SSH session to the first node of a tag"
|
||||
_cmd ssh "Open an SSH session to a node (first one by default)"
|
||||
_cmd_ssh() {
|
||||
TAG=$1
|
||||
need_tag
|
||||
IP=$(head -1 tags/$TAG/ips.txt)
|
||||
info "Logging into $IP (default password: $USER_PASSWORD)"
|
||||
ssh $SSHOPTS $USER_LOGIN@$IP
|
||||
|
||||
if [ "$2" ]; then
|
||||
ssh -l ubuntu -i tags/$TAG/id_rsa $2
|
||||
else
|
||||
IP=$(head -1 tags/$TAG/ips.txt)
|
||||
info "Logging into $IP (default password: $USER_PASSWORD)"
|
||||
ssh $SSHOPTS $USER_LOGIN@$IP
|
||||
fi
|
||||
}
|
||||
|
||||
_cmd tags "List groups of VMs known locally"
|
||||
@@ -1392,7 +1419,7 @@ WantedBy=multi-user.target
|
||||
|
||||
[Service]
|
||||
WorkingDirectory=/opt/webssh
|
||||
ExecStart=/usr/bin/env python run.py --fbidhttp=false --port=1080 --policy=reject
|
||||
ExecStart=/usr/bin/env python3 run.py --fbidhttp=false --port=1080 --policy=reject
|
||||
User=nobody
|
||||
Group=nogroup
|
||||
Restart=always
|
||||
|
||||
@@ -23,6 +23,14 @@ pssh() {
|
||||
# necessary - or down to zero, too.
|
||||
sleep ${PSSH_DELAY_PRE-1}
|
||||
|
||||
# When things go wrong, it's convenient to ask pssh to show the output
|
||||
# of the failed command. Let's make that easy with a DEBUG env var.
|
||||
if [ "$DEBUG" ]; then
|
||||
PSSH_I=-i
|
||||
else
|
||||
PSSH_I=""
|
||||
fi
|
||||
|
||||
$(which pssh || which parallel-ssh) -h $HOSTFILE -l ubuntu \
|
||||
--par ${PSSH_PARALLEL_CONNECTIONS-100} \
|
||||
--timeout 300 \
|
||||
@@ -31,5 +39,6 @@ pssh() {
|
||||
-O UserKnownHostsFile=/dev/null \
|
||||
-O StrictHostKeyChecking=no \
|
||||
-O ForwardAgent=yes \
|
||||
$PSSH_I \
|
||||
"$@"
|
||||
}
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
#export TF_VAR_node_size=GP2.4
|
||||
#export TF_VAR_node_size=GP4.4
|
||||
#export TF_VAR_node_size=g6-standard-6
|
||||
#export TF_VAR_node_size=m7i.xlarge
|
||||
|
||||
|
||||
@@ -2,7 +2,11 @@ terraform {
|
||||
required_providers {
|
||||
kubernetes = {
|
||||
source = "hashicorp/kubernetes"
|
||||
version = "2.16.1"
|
||||
version = "~> 2.38.0"
|
||||
}
|
||||
helm = {
|
||||
source = "hashicorp/helm"
|
||||
version = "~> 3.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -16,7 +20,7 @@ provider "kubernetes" {
|
||||
|
||||
provider "helm" {
|
||||
alias = "cluster_${index}"
|
||||
kubernetes {
|
||||
kubernetes = {
|
||||
config_path = "./kubeconfig.${index}"
|
||||
}
|
||||
}
|
||||
@@ -51,42 +55,37 @@ resource "helm_release" "shpod_${index}" {
|
||||
name = "shpod"
|
||||
namespace = "shpod"
|
||||
create_namespace = false
|
||||
set {
|
||||
name = "service.type"
|
||||
value = "NodePort"
|
||||
}
|
||||
set {
|
||||
name = "resources.requests.cpu"
|
||||
value = "100m"
|
||||
}
|
||||
set {
|
||||
name = "resources.requests.memory"
|
||||
value = "500M"
|
||||
}
|
||||
set {
|
||||
name = "resources.limits.cpu"
|
||||
value = "1"
|
||||
}
|
||||
set {
|
||||
name = "resources.limits.memory"
|
||||
value = "1000M"
|
||||
}
|
||||
set {
|
||||
name = "persistentVolume.enabled"
|
||||
value = "true"
|
||||
}
|
||||
set {
|
||||
name = "ssh.password"
|
||||
value = random_string.shpod_${index}.result
|
||||
}
|
||||
set {
|
||||
name = "rbac.cluster.clusterRoles"
|
||||
value = "{cluster-admin}"
|
||||
}
|
||||
set {
|
||||
name = "codeServer.enabled"
|
||||
value = "true"
|
||||
}
|
||||
values = [
|
||||
yamlencode({
|
||||
service = {
|
||||
type = "NodePort"
|
||||
}
|
||||
resources = {
|
||||
requests = {
|
||||
cpu = "100m"
|
||||
memory = "500M"
|
||||
}
|
||||
limits = {
|
||||
cpu = "1"
|
||||
memory = "1000M"
|
||||
}
|
||||
}
|
||||
persistentVolume = {
|
||||
enabled = true
|
||||
}
|
||||
ssh = {
|
||||
password = random_string.shpod_${index}.result
|
||||
}
|
||||
rbac = {
|
||||
cluster = {
|
||||
clusterRoles = [ "cluster-admin" ]
|
||||
}
|
||||
}
|
||||
codeServer = {
|
||||
enabled = true
|
||||
}
|
||||
})
|
||||
]
|
||||
}
|
||||
|
||||
resource "helm_release" "metrics_server_${index}" {
|
||||
@@ -101,13 +100,75 @@ resource "helm_release" "metrics_server_${index}" {
|
||||
name = "metrics-server"
|
||||
namespace = "metrics-server"
|
||||
create_namespace = true
|
||||
set {
|
||||
name = "args"
|
||||
value = "{--kubelet-insecure-tls}"
|
||||
}
|
||||
values = [
|
||||
yamlencode({
|
||||
args = [ "--kubelet-insecure-tls" ]
|
||||
})
|
||||
]
|
||||
}
|
||||
|
||||
# As of October 2025, the ebs-csi-driver addon (which is used on EKS
|
||||
# to provision persistent volumes) doesn't automatically create a
|
||||
# StorageClass. Here, we're trying to detect the DaemonSet created
|
||||
# by the ebs-csi-driver; and if we find it, we create the corresponding
|
||||
# StorageClass.
|
||||
data "kubernetes_resources" "ebs_csi_node_${index}" {
|
||||
provider = kubernetes.cluster_${index}
|
||||
api_version = "apps/v1"
|
||||
kind = "DaemonSet"
|
||||
label_selector = "app.kubernetes.io/name=aws-ebs-csi-driver"
|
||||
namespace = "kube-system"
|
||||
}
|
||||
|
||||
resource "kubernetes_storage_class" "ebs_csi_${index}" {
|
||||
count = (length(data.kubernetes_resources.ebs_csi_node_${index}.objects) > 0) ? 1 : 0
|
||||
provider = kubernetes.cluster_${index}
|
||||
metadata {
|
||||
name = "ebs-csi"
|
||||
annotations = {
|
||||
"storageclass.kubernetes.io/is-default-class" = "true"
|
||||
}
|
||||
}
|
||||
storage_provisioner = "ebs.csi.aws.com"
|
||||
}
|
||||
|
||||
# This section here deserves a little explanation.
|
||||
#
|
||||
# When we access a cluster with shpod (either through SSH or code-server)
|
||||
# there is no kubeconfig file - we simply use "in-cluster" authentication
|
||||
# with a ServiceAccount token. This is a bit unusual, and ideally, I would
|
||||
# prefer to have a "normal" kubeconfig file in the students' shell.
|
||||
#
|
||||
# So what we're doing here, is that we're populating a ConfigMap with
|
||||
# a kubeconfig file; and in the initialization scripts (e.g. bashrc) we
|
||||
# automatically download the kubeconfig file from the ConfigMap and place
|
||||
# it in ~/.kube/kubeconfig.
|
||||
#
|
||||
# But, which kubeconfig file should we use? We could use the "normal"
|
||||
# kubeconfig file that was generated by the provider; but in some cases,
|
||||
# that kubeconfig file might use a token instead of a certificate for
|
||||
# user authentication - and ideally, I would like to have a certificate
|
||||
# so that in the section about auth and RBAC, we can dissect that TLS
|
||||
# certificate and explain where our permissions come from.
|
||||
#
|
||||
# So we're creating a TLS key pair; using the CSR API to issue a user
|
||||
# certificate belongong to a special group; and grant the cluster-admin
|
||||
# role to that group; then we use the kubeconfig file generated by the
|
||||
# provider but override the user with that TLS key pair.
|
||||
#
|
||||
# This is not strictly necessary but it streamlines the lesson on auth.
|
||||
#
|
||||
# Lastly - in the ConfigMap we actually put both the original kubeconfig,
|
||||
# and the one where we injected our new user (just in case we want to
|
||||
# use or look at the original for any reason).
|
||||
#
|
||||
# One more thing: the kubernetes.io/kube-apiserver-client signer is
|
||||
# disabled on EKS, so... we don't generate that ConfigMap on EKS.
|
||||
# To detect if we're on EKS, we're looking for the ebs-csi-node DaemonSet.
|
||||
# (Which means that the detection will break if the ebs-csi addon is missing.)
|
||||
|
||||
resource "kubernetes_config_map" "kubeconfig_${index}" {
|
||||
count = (length(data.kubernetes_resources.ebs_csi_node_${index}.objects) > 0) ? 0 : 1
|
||||
provider = kubernetes.cluster_${index}
|
||||
metadata {
|
||||
name = "kubeconfig"
|
||||
@@ -133,7 +194,7 @@ resource "kubernetes_config_map" "kubeconfig_${index}" {
|
||||
- name: cluster-admin
|
||||
user:
|
||||
client-key-data: $${base64encode(tls_private_key.cluster_admin_${index}.private_key_pem)}
|
||||
client-certificate-data: $${base64encode(kubernetes_certificate_signing_request_v1.cluster_admin_${index}.certificate)}
|
||||
client-certificate-data: $${base64encode(kubernetes_certificate_signing_request_v1.cluster_admin_${index}[0].certificate)}
|
||||
EOT
|
||||
}
|
||||
}
|
||||
@@ -153,7 +214,25 @@ resource "tls_cert_request" "cluster_admin_${index}" {
|
||||
}
|
||||
}
|
||||
|
||||
resource "kubernetes_cluster_role_binding" "shpod_cluster_admin_${index}" {
|
||||
provider = kubernetes.cluster_${index}
|
||||
metadata {
|
||||
name = "shpod-cluster-admin"
|
||||
}
|
||||
role_ref {
|
||||
api_group = "rbac.authorization.k8s.io"
|
||||
kind = "ClusterRole"
|
||||
name = "cluster-admin"
|
||||
}
|
||||
subject {
|
||||
api_group = "rbac.authorization.k8s.io"
|
||||
kind = "Group"
|
||||
name = "shpod-cluster-admins"
|
||||
}
|
||||
}
|
||||
|
||||
resource "kubernetes_certificate_signing_request_v1" "cluster_admin_${index}" {
|
||||
count = (length(data.kubernetes_resources.ebs_csi_node_${index}.objects) > 0) ? 0 : 1
|
||||
provider = kubernetes.cluster_${index}
|
||||
metadata {
|
||||
name = "cluster-admin"
|
||||
|
||||
@@ -23,7 +23,7 @@ variable "node_size" {
|
||||
}
|
||||
|
||||
variable "location" {
|
||||
type = string
|
||||
type = string
|
||||
default = null
|
||||
}
|
||||
|
||||
|
||||
@@ -1,60 +1,45 @@
|
||||
# Taken from:
|
||||
# https://github.com/hashicorp/learn-terraform-provision-eks-cluster/blob/main/main.tf
|
||||
|
||||
data "aws_availability_zones" "available" {}
|
||||
|
||||
module "vpc" {
|
||||
source = "terraform-aws-modules/vpc/aws"
|
||||
version = "3.19.0"
|
||||
|
||||
name = var.cluster_name
|
||||
|
||||
cidr = "10.0.0.0/16"
|
||||
azs = slice(data.aws_availability_zones.available.names, 0, 3)
|
||||
|
||||
private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
|
||||
public_subnets = ["10.0.4.0/24", "10.0.5.0/24", "10.0.6.0/24"]
|
||||
|
||||
enable_nat_gateway = true
|
||||
single_nat_gateway = true
|
||||
enable_dns_hostnames = true
|
||||
|
||||
public_subnet_tags = {
|
||||
"kubernetes.io/cluster/${var.cluster_name}" = "shared"
|
||||
"kubernetes.io/role/elb" = 1
|
||||
}
|
||||
|
||||
private_subnet_tags = {
|
||||
"kubernetes.io/cluster/${var.cluster_name}" = "shared"
|
||||
"kubernetes.io/role/internal-elb" = 1
|
||||
}
|
||||
data "aws_eks_cluster_versions" "_" {
|
||||
default_only = true
|
||||
}
|
||||
|
||||
module "eks" {
|
||||
source = "terraform-aws-modules/eks/aws"
|
||||
version = "19.5.1"
|
||||
|
||||
cluster_name = var.cluster_name
|
||||
cluster_version = "1.24"
|
||||
|
||||
vpc_id = module.vpc.vpc_id
|
||||
subnet_ids = module.vpc.private_subnets
|
||||
cluster_endpoint_public_access = true
|
||||
|
||||
eks_managed_node_group_defaults = {
|
||||
ami_type = "AL2_x86_64"
|
||||
source = "terraform-aws-modules/eks/aws"
|
||||
version = "~> 21.0"
|
||||
name = var.cluster_name
|
||||
kubernetes_version = data.aws_eks_cluster_versions._.cluster_versions[0].cluster_version
|
||||
vpc_id = local.vpc_id
|
||||
subnet_ids = local.subnet_ids
|
||||
endpoint_public_access = true
|
||||
enable_cluster_creator_admin_permissions = true
|
||||
upgrade_policy = {
|
||||
# The default policy is EXTENDED, which incurs additional costs
|
||||
# when running an old control plane. We don't advise to run old
|
||||
# control planes, but we also don't want to incur costs if an
|
||||
# old version is chosen accidentally.
|
||||
support_type = "STANDARD"
|
||||
}
|
||||
|
||||
addons = {
|
||||
coredns = {}
|
||||
eks-pod-identity-agent = {
|
||||
before_compute = true
|
||||
}
|
||||
kube-proxy = {}
|
||||
vpc-cni = {
|
||||
before_compute = true
|
||||
}
|
||||
aws-ebs-csi-driver = {
|
||||
service_account_role_arn = module.irsa-ebs-csi.iam_role_arn
|
||||
}
|
||||
}
|
||||
|
||||
eks_managed_node_groups = {
|
||||
one = {
|
||||
name = "node-group-one"
|
||||
|
||||
x86 = {
|
||||
name = "x86"
|
||||
instance_types = [local.node_size]
|
||||
|
||||
min_size = var.min_nodes_per_pool
|
||||
max_size = var.max_nodes_per_pool
|
||||
desired_size = var.min_nodes_per_pool
|
||||
min_size = var.min_nodes_per_pool
|
||||
max_size = var.max_nodes_per_pool
|
||||
desired_size = var.min_nodes_per_pool
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -66,7 +51,7 @@ data "aws_iam_policy" "ebs_csi_policy" {
|
||||
|
||||
module "irsa-ebs-csi" {
|
||||
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role-with-oidc"
|
||||
version = "4.7.0"
|
||||
version = "~> 5.39.0"
|
||||
|
||||
create_role = true
|
||||
role_name = "AmazonEKSTFEBSCSIRole-${module.eks.cluster_name}"
|
||||
@@ -75,13 +60,9 @@ module "irsa-ebs-csi" {
|
||||
oidc_fully_qualified_subjects = ["system:serviceaccount:kube-system:ebs-csi-controller-sa"]
|
||||
}
|
||||
|
||||
resource "aws_eks_addon" "ebs-csi" {
|
||||
cluster_name = module.eks.cluster_name
|
||||
addon_name = "aws-ebs-csi-driver"
|
||||
addon_version = "v1.5.2-eksbuild.1"
|
||||
service_account_role_arn = module.irsa-ebs-csi.iam_role_arn
|
||||
tags = {
|
||||
"eks_addon" = "ebs-csi"
|
||||
"terraform" = "true"
|
||||
}
|
||||
resource "aws_vpc_security_group_ingress_rule" "_" {
|
||||
security_group_id = module.eks.node_security_group_id
|
||||
cidr_ipv4 = "0.0.0.0/0"
|
||||
ip_protocol = -1
|
||||
description = "Allow all traffic to Kubernetes nodes (so that we can use NodePorts, hostPorts, etc.)"
|
||||
}
|
||||
@@ -2,7 +2,7 @@ terraform {
|
||||
required_providers {
|
||||
aws = {
|
||||
source = "hashicorp/aws"
|
||||
version = "~> 4.47.0"
|
||||
version = "~> 6.17.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
61
prepare-labs/terraform/one-kubernetes/aws/vpc.tf
Normal file
61
prepare-labs/terraform/one-kubernetes/aws/vpc.tf
Normal file
@@ -0,0 +1,61 @@
|
||||
# OK, we have two options here.
|
||||
# 1. Create our own VPC
|
||||
# - Pros: provides good isolation from other stuff deployed in the
|
||||
# AWS account; makes sure that we don't interact with
|
||||
# existing security groups, subnets, etc.
|
||||
# - Cons: by default, there is a quota of 5 VPC per region, so
|
||||
# we can only deploy 5 clusters
|
||||
# 2. Use the default VPC
|
||||
# - Pros/cons: the opposite :)
|
||||
|
||||
variable "use_default_vpc" {
|
||||
type = bool
|
||||
default = true
|
||||
}
|
||||
|
||||
data "aws_vpc" "default" {
|
||||
default = true
|
||||
}
|
||||
|
||||
data "aws_subnets" "default" {
|
||||
filter {
|
||||
name = "vpc-id"
|
||||
values = [data.aws_vpc.default.id]
|
||||
}
|
||||
}
|
||||
|
||||
data "aws_availability_zones" "available" {}
|
||||
|
||||
module "vpc" {
|
||||
count = var.use_default_vpc ? 0 : 1
|
||||
source = "terraform-aws-modules/vpc/aws"
|
||||
version = "~> 6.0"
|
||||
|
||||
name = var.cluster_name
|
||||
|
||||
cidr = "10.0.0.0/16"
|
||||
azs = slice(data.aws_availability_zones.available.names, 0, 3)
|
||||
|
||||
private_subnets = ["10.0.11.0/24", "10.0.12.0/24", "10.0.13.0/24"]
|
||||
public_subnets = ["10.0.21.0/24", "10.0.22.0/24", "10.0.23.0/24"]
|
||||
|
||||
enable_nat_gateway = true
|
||||
single_nat_gateway = true
|
||||
enable_dns_hostnames = true
|
||||
map_public_ip_on_launch = true
|
||||
|
||||
public_subnet_tags = {
|
||||
"kubernetes.io/cluster/${var.cluster_name}" = "shared"
|
||||
"kubernetes.io/role/elb" = 1
|
||||
}
|
||||
|
||||
private_subnet_tags = {
|
||||
"kubernetes.io/cluster/${var.cluster_name}" = "shared"
|
||||
"kubernetes.io/role/internal-elb" = 1
|
||||
}
|
||||
}
|
||||
|
||||
locals {
|
||||
vpc_id = var.use_default_vpc ? data.aws_vpc.default.id : module.vpc[0].vpc_id
|
||||
subnet_ids = var.use_default_vpc ? data.aws_subnets.default.ids : module.vpc[0].public_subnets
|
||||
}
|
||||
@@ -1,12 +0,0 @@
|
||||
locals {
|
||||
location = var.location != null ? var.location : "europe-north1-a"
|
||||
region = replace(local.location, "/-[a-z]$/", "")
|
||||
# Unfortunately, the following line doesn't work
|
||||
# (that attribute just returns an empty string)
|
||||
# so we have to hard-code the project name.
|
||||
#project = data.google_client_config._.project
|
||||
project = "prepare-tf"
|
||||
}
|
||||
|
||||
data "google_client_config" "_" {}
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
resource "google_container_cluster" "_" {
|
||||
name = var.cluster_name
|
||||
project = local.project
|
||||
location = local.location
|
||||
name = var.cluster_name
|
||||
location = local.location
|
||||
deletion_protection = false
|
||||
#min_master_version = var.k8s_version
|
||||
|
||||
# To deploy private clusters, uncomment the section below,
|
||||
@@ -42,7 +42,7 @@ resource "google_container_cluster" "_" {
|
||||
node_pool {
|
||||
name = "x86"
|
||||
node_config {
|
||||
tags = var.common_tags
|
||||
tags = ["lab-${var.cluster_name}"]
|
||||
machine_type = local.node_size
|
||||
}
|
||||
initial_node_count = var.min_nodes_per_pool
|
||||
@@ -62,3 +62,25 @@ resource "google_container_cluster" "_" {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
resource "google_compute_firewall" "_" {
|
||||
name = "lab-${var.cluster_name}"
|
||||
network = "default"
|
||||
|
||||
allow {
|
||||
protocol = "tcp"
|
||||
ports = ["0-65535"]
|
||||
}
|
||||
|
||||
allow {
|
||||
protocol = "udp"
|
||||
ports = ["0-65535"]
|
||||
}
|
||||
|
||||
allow {
|
||||
protocol = "icmp"
|
||||
}
|
||||
|
||||
source_ranges = ["0.0.0.0/0"]
|
||||
target_tags = ["lab-${var.cluster_name}"]
|
||||
}
|
||||
|
||||
@@ -6,6 +6,8 @@ output "has_metrics_server" {
|
||||
value = true
|
||||
}
|
||||
|
||||
data "google_client_config" "_" {}
|
||||
|
||||
output "kubeconfig" {
|
||||
sensitive = true
|
||||
value = <<-EOT
|
||||
|
||||
@@ -1,8 +0,0 @@
|
||||
terraform {
|
||||
required_providers {
|
||||
google = {
|
||||
source = "hashicorp/google"
|
||||
version = "4.5.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
1
prepare-labs/terraform/one-kubernetes/googlecloud/provider.tf
Symbolic link
1
prepare-labs/terraform/one-kubernetes/googlecloud/provider.tf
Symbolic link
@@ -0,0 +1 @@
|
||||
../../providers/googlecloud/provider.tf
|
||||
@@ -30,7 +30,7 @@ resource "scaleway_k8s_pool" "_" {
|
||||
max_size = var.max_nodes_per_pool
|
||||
autoscaling = var.max_nodes_per_pool > var.min_nodes_per_pool
|
||||
autohealing = true
|
||||
depends_on = [ scaleway_instance_security_group._ ]
|
||||
depends_on = [scaleway_instance_security_group._]
|
||||
}
|
||||
|
||||
data "scaleway_k8s_version" "_" {
|
||||
|
||||
@@ -4,25 +4,36 @@ resource "helm_release" "_" {
|
||||
create_namespace = true
|
||||
repository = "https://charts.loft.sh"
|
||||
chart = "vcluster"
|
||||
version = "0.19.7"
|
||||
set {
|
||||
name = "service.type"
|
||||
value = "NodePort"
|
||||
}
|
||||
set {
|
||||
name = "storage.persistence"
|
||||
value = "false"
|
||||
}
|
||||
set {
|
||||
name = "sync.nodes.enabled"
|
||||
value = "true"
|
||||
}
|
||||
set {
|
||||
name = "sync.nodes.syncAllNodes"
|
||||
value = "true"
|
||||
}
|
||||
set {
|
||||
name = "syncer.extraArgs"
|
||||
value = "{--tls-san=${local.guest_api_server_host}}"
|
||||
}
|
||||
version = "0.27.1"
|
||||
values = [
|
||||
yamlencode({
|
||||
controlPlane = {
|
||||
proxy = {
|
||||
extraSANs = [ local.guest_api_server_host ]
|
||||
}
|
||||
service = {
|
||||
spec = {
|
||||
type = "NodePort"
|
||||
}
|
||||
}
|
||||
statefulSet = {
|
||||
persistence = {
|
||||
volumeClaim = {
|
||||
enabled = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
sync = {
|
||||
fromHost = {
|
||||
nodes = {
|
||||
enabled = true
|
||||
selector = {
|
||||
all = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
})
|
||||
]
|
||||
}
|
||||
|
||||
@@ -0,0 +1,8 @@
|
||||
terraform {
|
||||
required_providers {
|
||||
helm = {
|
||||
source = "hashicorp/helm"
|
||||
version = "~> 3.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
8
prepare-labs/terraform/providers/googlecloud/provider.tf
Normal file
8
prepare-labs/terraform/providers/googlecloud/provider.tf
Normal file
@@ -0,0 +1,8 @@
|
||||
terraform {
|
||||
required_providers {
|
||||
google = {
|
||||
source = "hashicorp/google"
|
||||
version = "~> 7.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -9,5 +9,9 @@ variable "node_sizes" {
|
||||
|
||||
variable "location" {
|
||||
type = string
|
||||
default = null
|
||||
default = "europe-north1-a"
|
||||
}
|
||||
|
||||
locals {
|
||||
location = (var.location != "" && var.location != null) ? var.location : "europe-north1-a"
|
||||
}
|
||||
@@ -13,6 +13,11 @@ variable "proxmox_password" {
|
||||
default = null
|
||||
}
|
||||
|
||||
variable "proxmox_storage" {
|
||||
type = string
|
||||
default = "local"
|
||||
}
|
||||
|
||||
variable "proxmox_template_node_name" {
|
||||
type = string
|
||||
default = null
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
provider "helm" {
|
||||
kubernetes {
|
||||
kubernetes = {
|
||||
config_path = "~/kubeconfig"
|
||||
}
|
||||
}
|
||||
|
||||
1
prepare-labs/terraform/virtual-machines/googlecloud/common.tf
Symbolic link
1
prepare-labs/terraform/virtual-machines/googlecloud/common.tf
Symbolic link
@@ -0,0 +1 @@
|
||||
../common.tf
|
||||
1
prepare-labs/terraform/virtual-machines/googlecloud/config.tf
Symbolic link
1
prepare-labs/terraform/virtual-machines/googlecloud/config.tf
Symbolic link
@@ -0,0 +1 @@
|
||||
../../providers/googlecloud/config.tf
|
||||
54
prepare-labs/terraform/virtual-machines/googlecloud/main.tf
Normal file
54
prepare-labs/terraform/virtual-machines/googlecloud/main.tf
Normal file
@@ -0,0 +1,54 @@
|
||||
# Note: names and tags on GCP have to match a specific regex:
|
||||
# (?:[a-z](?:[-a-z0-9]{0,61}[a-z0-9])?)
|
||||
# In other words, they must start with a letter; and generally,
|
||||
# we make them start with a number (year-month-day-etc, so 2025-...)
|
||||
# so we prefix names and tags with "lab-" in this configuration.
|
||||
|
||||
resource "google_compute_instance" "_" {
|
||||
for_each = local.nodes
|
||||
zone = var.location
|
||||
name = "lab-${each.value.node_name}"
|
||||
tags = ["lab-${var.tag}"]
|
||||
machine_type = each.value.node_size
|
||||
boot_disk {
|
||||
initialize_params {
|
||||
image = "ubuntu-os-cloud/ubuntu-2404-lts-amd64"
|
||||
}
|
||||
}
|
||||
network_interface {
|
||||
network = "default"
|
||||
access_config {}
|
||||
}
|
||||
metadata = {
|
||||
"ssh-keys" = "ubuntu:${tls_private_key.ssh.public_key_openssh}"
|
||||
}
|
||||
}
|
||||
|
||||
locals {
|
||||
ip_addresses = {
|
||||
for key, value in local.nodes :
|
||||
key => google_compute_instance._[key].network_interface[0].access_config[0].nat_ip
|
||||
}
|
||||
}
|
||||
|
||||
resource "google_compute_firewall" "_" {
|
||||
name = "lab-${var.tag}"
|
||||
network = "default"
|
||||
|
||||
allow {
|
||||
protocol = "tcp"
|
||||
ports = ["0-65535"]
|
||||
}
|
||||
|
||||
allow {
|
||||
protocol = "udp"
|
||||
ports = ["0-65535"]
|
||||
}
|
||||
|
||||
allow {
|
||||
protocol = "icmp"
|
||||
}
|
||||
|
||||
source_ranges = ["0.0.0.0/0"]
|
||||
target_tags = ["lab-${var.tag}"]
|
||||
}
|
||||
1
prepare-labs/terraform/virtual-machines/googlecloud/provider.tf
Symbolic link
1
prepare-labs/terraform/virtual-machines/googlecloud/provider.tf
Symbolic link
@@ -0,0 +1 @@
|
||||
../../providers/googlecloud/provider.tf
|
||||
1
prepare-labs/terraform/virtual-machines/googlecloud/variables.tf
Symbolic link
1
prepare-labs/terraform/virtual-machines/googlecloud/variables.tf
Symbolic link
@@ -0,0 +1 @@
|
||||
../../providers/googlecloud/variables.tf
|
||||
@@ -8,6 +8,7 @@ resource "proxmox_virtual_environment_vm" "_" {
|
||||
node_name = local.pve_nodes[each.value.node_index % length(local.pve_nodes)]
|
||||
for_each = local.nodes
|
||||
name = each.value.node_name
|
||||
tags = ["container.training", var.tag]
|
||||
stop_on_destroy = true
|
||||
cpu {
|
||||
cores = split(" ", each.value.node_size)[0]
|
||||
@@ -17,7 +18,7 @@ resource "proxmox_virtual_environment_vm" "_" {
|
||||
dedicated = split(" ", each.value.node_size)[1]
|
||||
}
|
||||
#disk {
|
||||
# datastore_id = "ceph"
|
||||
# datastore_id = var.proxmox_storage
|
||||
# file_id = proxmox_virtual_environment_file._.id
|
||||
# interface = "scsi0"
|
||||
# size = 30
|
||||
@@ -26,12 +27,13 @@ resource "proxmox_virtual_environment_vm" "_" {
|
||||
clone {
|
||||
vm_id = var.proxmox_template_vm_id
|
||||
node_name = var.proxmox_template_node_name
|
||||
full = false
|
||||
}
|
||||
agent {
|
||||
enabled = true
|
||||
}
|
||||
initialization {
|
||||
datastore_id = "ceph"
|
||||
datastore_id = var.proxmox_storage
|
||||
user_account {
|
||||
username = "ubuntu"
|
||||
keys = [trimspace(tls_private_key.ssh.public_key_openssh)]
|
||||
|
||||
@@ -8,6 +8,9 @@ proxmox_endpoint = "https://localhost:8006/"
|
||||
proxmox_username = "terraform@pve"
|
||||
proxmox_password = "CHANGEME"
|
||||
|
||||
# Which storage to use for VM disks. Defaults to "local".
|
||||
#proxmox_storage = "ceph"
|
||||
|
||||
proxmox_template_node_name = "CHANGEME"
|
||||
proxmox_template_vm_id = CHANGEME
|
||||
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
#/ /kube-halfday.yml.html 200!
|
||||
#/ /kube-fullday.yml.html 200!
|
||||
#/ /kube-twodays.yml.html 200!
|
||||
/ /kube.yml.html 200!
|
||||
|
||||
# And this allows to do "git clone https://container.training".
|
||||
/info/refs service=git-upload-pack https://github.com/jpetazzo/container.training/info/refs?service=git-upload-pack
|
||||
|
||||
@@ -84,9 +84,9 @@ like Windows, macOS, Solaris, FreeBSD ...
|
||||
|
||||
* Each `lxc-start` process exposes a custom API over a local UNIX socket, allowing to interact with the container.
|
||||
|
||||
* No notion of image (container filesystems have to be managed manually).
|
||||
* No notion of image (container filesystems had be managed manually).
|
||||
|
||||
* Networking has to be set up manually.
|
||||
* Networking had to be set up manually.
|
||||
|
||||
---
|
||||
|
||||
@@ -98,10 +98,22 @@ like Windows, macOS, Solaris, FreeBSD ...
|
||||
|
||||
* Daemon exposing a REST API.
|
||||
|
||||
* Can run containers and virtual machines.
|
||||
|
||||
* Can manage images, snapshots, migrations, networking, storage.
|
||||
|
||||
* "offers a user experience similar to virtual machines but using Linux containers instead."
|
||||
|
||||
* Driven by Canonical.
|
||||
|
||||
---
|
||||
|
||||
## Incus
|
||||
|
||||
* Community-driven fork of LXD.
|
||||
|
||||
* Relatively recent [announced in August 2023](https://linuxcontainers.org/incus/announcement/) so time will tell what the notable differences will be.
|
||||
|
||||
---
|
||||
|
||||
## CRI-O
|
||||
@@ -140,7 +152,7 @@ We're not aware of anyone using it directly (i.e. outside of Kubernetes).
|
||||
|
||||
---
|
||||
|
||||
## Kata containers
|
||||
## [Kata containers](https://katacontainers.io/)
|
||||
|
||||
* OCI-compliant runtime.
|
||||
|
||||
@@ -152,7 +164,7 @@ We're not aware of anyone using it directly (i.e. outside of Kubernetes).
|
||||
|
||||
---
|
||||
|
||||
## gVisor
|
||||
## [gVisor](https://gvisor.dev/)
|
||||
|
||||
* OCI-compliant runtime.
|
||||
|
||||
@@ -170,7 +182,17 @@ We're not aware of anyone using it directly (i.e. outside of Kubernetes).
|
||||
|
||||
---
|
||||
|
||||
## Overall ...
|
||||
## Others
|
||||
|
||||
- Micro VMs: Firecracker, Edera...
|
||||
|
||||
- [crun](https://github.com/containers/crun) (runc rewritten in C)
|
||||
|
||||
- [youki](https://youki-dev.github.io/youki/) (runc rewritten in Rust)
|
||||
|
||||
---
|
||||
|
||||
## To Docker Or Not To Docker
|
||||
|
||||
* The Docker Engine is very developer-centric:
|
||||
|
||||
@@ -184,8 +206,26 @@ We're not aware of anyone using it directly (i.e. outside of Kubernetes).
|
||||
|
||||
* As a result, it is a fantastic tool in development environments.
|
||||
|
||||
* On servers:
|
||||
* On Kubernetes clusters, containerd or CRI-O are better choices.
|
||||
|
||||
- Docker is a good default choice
|
||||
* On Kubernetes clusters, the container engine is an implementation detail.
|
||||
|
||||
- If you use Kubernetes, the engine doesn't matter
|
||||
---
|
||||
|
||||
## Different levels
|
||||
|
||||
- Directly use namespaces, cgroups, capabilities with custom code or scripts
|
||||
|
||||
*useful for troubleshooting/debugging and for educative purposes; e.g. pipework*
|
||||
|
||||
- Use low-level engines like runc, crun, youki
|
||||
|
||||
*useful when building custom architectures; e.g. a brand new orchestrator*
|
||||
|
||||
- Use low-level APIs like CRI or containerd grpc API
|
||||
|
||||
*useful to achieve high-level features like Docker, but without Docker; e.g. ctr, nerdctl*
|
||||
|
||||
- Use high-level APIs like Docker and Kubernetes
|
||||
|
||||
*that's what most people will do*
|
||||
|
||||
@@ -327,9 +327,7 @@ class: extra-details
|
||||
|
||||
## Which one is the best?
|
||||
|
||||
- Eventually, overlay2 should be the best option.
|
||||
|
||||
- It is available on all modern systems.
|
||||
- In modern (2015+) systems, overlay2 should be the best option.
|
||||
|
||||
- Its memory usage is better than Device Mapper, BTRFS, or ZFS.
|
||||
|
||||
|
||||
@@ -141,3 +141,13 @@ class: pic
|
||||
* etc.
|
||||
|
||||
* Docker Inc. launches commercial offers.
|
||||
|
||||
---
|
||||
|
||||
## Standardization of container runtimes
|
||||
|
||||
- Docker 1.11 (2016) introduces containerd and runc
|
||||
|
||||
- [Kubernetes 1.5 (2016)](https://kubernetes.io/blog/2016/12/kubernetes-1-5-supporting-production-workloads/) introduces the CRI
|
||||
|
||||
- First releases of CRI-O (2017), kata containers...
|
||||
|
||||
5
slides/containers/Exercise_Dockerfile_Buildkit.md
Normal file
5
slides/containers/Exercise_Dockerfile_Buildkit.md
Normal file
@@ -0,0 +1,5 @@
|
||||
# Exercise — BuildKit cache mounts
|
||||
|
||||
We want to make our builds faster by leveraging BuildKit cache mounts.
|
||||
|
||||
Of course, if we don't make any changes to the code, the build should be instantaneous. Therefore, to benchmark our changes, we will make trivial changes to the code (e.g. change the message in a "print" statement) and measure (e.g. with `time`) how long it takes to rebuild the image.
|
||||
@@ -1,4 +1,4 @@
|
||||
# Exercise — writing better Dockerfiles
|
||||
# Exercise — multi-stage builds
|
||||
|
||||
Let's update our Dockerfiles to leverage multi-stage builds!
|
||||
|
||||
249
slides/containers/Images_Deep_Dive.md
Normal file
249
slides/containers/Images_Deep_Dive.md
Normal file
@@ -0,0 +1,249 @@
|
||||
# Deep Dive Into Images
|
||||
|
||||
- Image = files (layers) + metadata (configuration)
|
||||
|
||||
- Layers = regular tar archives
|
||||
|
||||
(potentially with *whiteouts*)
|
||||
|
||||
- Configuration = everything needed to run the container
|
||||
|
||||
(e.g. Cmd, Env, WorkdingDir...)
|
||||
|
||||
---
|
||||
|
||||
## Image formats
|
||||
|
||||
- Docker image [v1] (no longer used, except in `docker save` and `docker load`)
|
||||
|
||||
- Docker image v1.1 (IDs are now hashes instead of random values)
|
||||
|
||||
- Docker image [v2] (multi-arch support; content-addressable images)
|
||||
|
||||
- [OCI image format][oci] (almost the same, except for media types)
|
||||
|
||||
[v1]: https://github.com/moby/docker-image-spec?tab=readme-ov-file
|
||||
[v2]: https://github.com/distribution/distribution/blob/main/docs/content/spec/manifest-v2-2.md
|
||||
[oci]: https://github.com/opencontainers/image-spec/blob/main/spec.md
|
||||
|
||||
---
|
||||
|
||||
## OCI images
|
||||
|
||||
- Manifest = JSON document
|
||||
|
||||
- Used by container engines to know "what should I download to unpack this image?"
|
||||
|
||||
- Contains references to blobs, identified by their sha256 digest + size
|
||||
|
||||
- config (single sha256 digest)
|
||||
|
||||
- layers (list of sha256 digests)
|
||||
|
||||
- Also annotations (key/values)
|
||||
|
||||
- It's also possible to have a manifest list, or "fat manifest"
|
||||
|
||||
(which lists multiple manifests; this is used for multi-arch support)
|
||||
|
||||
---
|
||||
|
||||
## Config blob
|
||||
|
||||
- Also a JSON document
|
||||
|
||||
- `architecture` string (e.g. `amd64`)
|
||||
|
||||
- `config` object
|
||||
|
||||
Cmd, Entrypoint, Env, ExposedPorts, StopSignal, User, Volumes, WorkingDir
|
||||
|
||||
- `history` list
|
||||
|
||||
purely informative; shown with e.g. `docker history`
|
||||
|
||||
- `rootfs` object
|
||||
|
||||
`type` (always `layers`) + list of "diff ids"
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Layers vs layers
|
||||
|
||||
- The image configuration contains digests of *uncompressed layers*
|
||||
|
||||
- The image manifest contains digests of *compressed layers*
|
||||
|
||||
(layer blobs in the registry can be tar, tar+gzip, tar+zstd)
|
||||
|
||||
---
|
||||
|
||||
## Layer format
|
||||
|
||||
- Layer = completely normal tar archive
|
||||
|
||||
- When a file is added or modified, it is added to the archive
|
||||
|
||||
(note: trivial changes, e.g. permissions, require to re-add the whole file!)
|
||||
|
||||
- When a file is deleted, a *whiteout* file is created
|
||||
|
||||
e.g. `rm hello.txt` results in a file named `.wh.hello.txt`
|
||||
|
||||
- Files starting with `.wh.` are forbidden in containers
|
||||
|
||||
- There is a special file, `.wh..wh..opq`, which means "remove all siblings"
|
||||
|
||||
(optimization to completely empty a directory)
|
||||
|
||||
- See [layer specification](https://github.com/opencontainers/image-spec/blob/main/layer.md) for details
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Origin of layer format
|
||||
|
||||
- The initial storage driver for Docker was AUFS
|
||||
|
||||
- AUFS is out-of-tree but Debian and Ubuntu included it
|
||||
|
||||
(they used it for live CD / live USB boot)
|
||||
|
||||
- It meant that Docker could work out of the box on these distros
|
||||
|
||||
- Later, Docker added support for other systems
|
||||
|
||||
(devicemapper thin provisioning, btrfs, overlay...)
|
||||
|
||||
- Today, overlay is the best compromise for most use-cases
|
||||
|
||||
---
|
||||
|
||||
## Inspecting images
|
||||
|
||||
- `skopeo` can copy images between different places
|
||||
|
||||
(registries, Docker Engine, local storage as used by podman...)
|
||||
|
||||
- Example:
|
||||
```bash
|
||||
skopeo copy docker://alpine oci:/tmp/alpine.oci
|
||||
```
|
||||
|
||||
- The image manifest will be in `/tmp/alpine.oci/index.json`
|
||||
|
||||
- Blobs (image configuration and layers) will be in `/tmp/alpine.oci/blobs/sha256`
|
||||
|
||||
- Note: as of version 1.20, `skopeo` doesn't handle extensions like stargz yet
|
||||
|
||||
(copying stargz images won't transfer the special index blobs)
|
||||
|
||||
---
|
||||
|
||||
## Layer surgery
|
||||
|
||||
Here is an example of how to manually edit an image.
|
||||
|
||||
https://github.com/jpetazzo/layeremove
|
||||
|
||||
It removes a specific layer from an image.
|
||||
|
||||
Note: it would be better to use a buildkit cache mount instead.
|
||||
|
||||
(This is just an educative example!)
|
||||
|
||||
---
|
||||
|
||||
## Stargz
|
||||
|
||||
- [Stargz] = Seekable Tar Gz, or "stargazer"
|
||||
|
||||
- Goal: start a container *before* its image has been fully downloaded
|
||||
|
||||
- Particularly useful for huge images that take minutes to download
|
||||
|
||||
- Also known as "streamable images" or "lazy loading"
|
||||
|
||||
- Alternative: [SOCI]
|
||||
|
||||
[stargz]: https://github.com/containerd/stargz-snapshotter
|
||||
[SOCI]: https://github.com/awslabs/soci-snapshotter
|
||||
|
||||
---
|
||||
|
||||
## Stargz architecture
|
||||
|
||||
- Combination of:
|
||||
|
||||
- a backward-compatible extension to the OCI image format
|
||||
|
||||
- a containerd *snapshotter*
|
||||
|
||||
(=containerd component responsible for managing container and image storage)
|
||||
|
||||
- tooling to create, convert, optimize images
|
||||
|
||||
- Installation requires:
|
||||
|
||||
- running the snapshotter daemon
|
||||
|
||||
- configuring containerd
|
||||
|
||||
- building new images or converting the existing ones
|
||||
|
||||
---
|
||||
|
||||
## Stargz principle
|
||||
|
||||
- Normal image layer = tar.gz = gzip(tar(file1, file2, ...))
|
||||
|
||||
- Can't access fileN without uncompressing everything before it
|
||||
|
||||
- Seekable Tar Gz = gzip(tar(file1)) + gzip(tar(file2)) + ... + index
|
||||
|
||||
(big files can also be chunked)
|
||||
|
||||
- Can access individual files
|
||||
|
||||
(and even individual chunks, if needed)
|
||||
|
||||
- Downside: lower compression ratio
|
||||
|
||||
(less compression context; extra gzip headers)
|
||||
|
||||
---
|
||||
|
||||
## Stargz format
|
||||
|
||||
- The index mentioned above is stored in separate registry blobs
|
||||
|
||||
(one index for each layer)
|
||||
|
||||
- The digest of the index blobs is stored in annotations in normal OCI images
|
||||
|
||||
- Fully compatible with existing registries
|
||||
|
||||
- Existing container engines will load images transparently
|
||||
|
||||
(without leveraging stargz capabilities)
|
||||
|
||||
---
|
||||
|
||||
## Stargz limitations
|
||||
|
||||
- Tools like `skopeo` will ignore index blobs
|
||||
|
||||
(=copying images across registries will discard stargz capabilities)
|
||||
|
||||
- Indexes need to be downloaded before container can be started
|
||||
|
||||
(=still significant start time when there are many files in images)
|
||||
|
||||
- Significant latency when accessing a file lazily
|
||||
|
||||
(need to hit the registry, typically with a range header, uncompress file)
|
||||
|
||||
- Images can be optimized to pre-load important files
|
||||
File diff suppressed because it is too large
Load Diff
75
slides/containers/Rootless_Networking.md
Normal file
75
slides/containers/Rootless_Networking.md
Normal file
@@ -0,0 +1,75 @@
|
||||
# Rootless Networking
|
||||
|
||||
The "classic" approach for container networking is `veth` + bridge.
|
||||
|
||||
Pros:
|
||||
|
||||
- good performance
|
||||
|
||||
- easy to manage and understand
|
||||
|
||||
- flexible (possibility to use multiple, isolated bridges)
|
||||
|
||||
Cons:
|
||||
|
||||
- requires root access on the host to set up networking
|
||||
|
||||
---
|
||||
|
||||
## Rootless options
|
||||
|
||||
- Locked down helpers
|
||||
|
||||
- daemon, scripts started through sudo...
|
||||
|
||||
- used by some desktop virtualization platforms
|
||||
|
||||
- still requires root access at some point
|
||||
|
||||
- Userland networking stacks
|
||||
|
||||
- true solution that does not require root privileges
|
||||
|
||||
- lower performance
|
||||
|
||||
---
|
||||
|
||||
## Userland stacks
|
||||
|
||||
- [SLiRP](https://en.wikipedia.org/wiki/Slirp)
|
||||
|
||||
*the OG project that inspired the other ones!*
|
||||
|
||||
- [VPNKit](https://github.com/moby/vpnkit)
|
||||
|
||||
*introduced by Docker Desktop to play nice with enterprise VPNs*
|
||||
|
||||
- [slirp4netns](https://github.com/rootless-containers/slirp4netns)
|
||||
|
||||
*slirp adapted for network namespaces, and therefore, containers; better performance*
|
||||
|
||||
- [passt and pasta](https://passt.top/)
|
||||
|
||||
*more modern approach; better support for inbound traffic; IPv6...)*
|
||||
|
||||
---
|
||||
|
||||
## Passt/Pasta
|
||||
|
||||
- No dependencies
|
||||
|
||||
- NAT (like slirp4netns) or no-NAT (for e.g. KubeVirt)
|
||||
|
||||
- Can handle inbound traffic dynamically
|
||||
|
||||
- No dynamic memory allocation
|
||||
|
||||
- Good security posture
|
||||
|
||||
- IPv6 support
|
||||
|
||||
- Reasonable performance
|
||||
|
||||
---
|
||||
|
||||
## Demo?
|
||||
162
slides/containers/Security.md
Normal file
162
slides/containers/Security.md
Normal file
@@ -0,0 +1,162 @@
|
||||
# Security models
|
||||
|
||||
In this section, we want to address a few security-related questions:
|
||||
|
||||
- What permissions do we need to run containers or a container engine?
|
||||
|
||||
- Can we use containers to escalate permissions?
|
||||
|
||||
- Can we break out of a container (move from container to host)?
|
||||
|
||||
- Is it safe to run untrusted code in containers?
|
||||
|
||||
- What about Kubernetes?
|
||||
|
||||
---
|
||||
|
||||
## Running Docker, containerd, podman...
|
||||
|
||||
- In the early days, running containers required root permissions
|
||||
|
||||
(to set up namespaces, cgroups, networking, mount filesystems...)
|
||||
|
||||
- Eventually, new kernel features were developed to allow "rootless" operation
|
||||
|
||||
(user namespaces and associated tweaks)
|
||||
|
||||
- Rootless requires a little bit of additional setup on the system (e.g. subuid)
|
||||
|
||||
(although this is increasingly often automated in modern distros)
|
||||
|
||||
- Docker runs as root by default; Podman runs rootless by default
|
||||
|
||||
---
|
||||
|
||||
## Advantages of rootless
|
||||
|
||||
- Containers can run without any intervention from root
|
||||
|
||||
(no package install, no daemon running as root...)
|
||||
|
||||
- Containerized processes run with non-privileged UID
|
||||
|
||||
- Container escape doesn't automatically result in full host compromise
|
||||
|
||||
- Can isolate workloads by using different UID
|
||||
|
||||
---
|
||||
|
||||
## Downsides of rootless
|
||||
|
||||
- *Relatively* newer (rootless Docker was introduced in 2019)
|
||||
|
||||
- many quirks/issues/limitations in the initial implementations
|
||||
|
||||
- kernel features and other mechanisms were introduced over time
|
||||
|
||||
- they're not always very well documented
|
||||
|
||||
- I/O performance (disk, network) is typically lower
|
||||
|
||||
(due to using special mechanisms instead of more direct access)
|
||||
|
||||
- Rootless and rootful engines must use different image storage
|
||||
|
||||
(due to UID mapping)
|
||||
|
||||
---
|
||||
|
||||
## Why not rootless everywhere?
|
||||
|
||||
- Not very useful on clusters
|
||||
|
||||
- users shouldn't log into cluster nodes
|
||||
|
||||
- questionable security improvement
|
||||
|
||||
- lower I/O performance
|
||||
|
||||
- Not very useful with Docker Desktop / Podman Desktop
|
||||
|
||||
- container workloads are already inside a VM
|
||||
|
||||
- could arguably provide a layer of inter-workload isolation
|
||||
|
||||
- would require new APIs and concepts
|
||||
|
||||
---
|
||||
|
||||
## Permission escalation
|
||||
|
||||
- Access to the Docker socket = root access to the machine
|
||||
```bash
|
||||
docker run --privileged -v /:/hostfs -ti alpine
|
||||
```
|
||||
|
||||
- That's why by default, the Docker socket access is locked down
|
||||
|
||||
(only accessible by `root` and group `docker`)
|
||||
|
||||
- If user `alice` has access to the Docker socket:
|
||||
|
||||
*compromising user `alice` leads to whole host compromise!*
|
||||
|
||||
- Doesn't fundamentally change the threat model
|
||||
|
||||
(if `alice` gets compromised in the first place, we're in trouble!)
|
||||
|
||||
- Enables new threats (persistence, kernel access...)
|
||||
|
||||
---
|
||||
|
||||
## Avoiding the problem
|
||||
|
||||
- Rootless containers
|
||||
|
||||
- Container VM (Docker Desktop, Podman Desktop, Orbstack...)
|
||||
|
||||
- Unfortunately: no fine-grained access to the Docker API
|
||||
|
||||
(no way to e.g. disable privileged containers, volume mounts...)
|
||||
|
||||
---
|
||||
|
||||
## Escaping containers
|
||||
|
||||
- Very easy with some features
|
||||
|
||||
(privileged containers, volume mounts, device access)
|
||||
|
||||
- Otherwise impossible in theory
|
||||
|
||||
(but of course, vulnerabilities do exist!)
|
||||
|
||||
- **Be careful with scripts invoking `docker run`, or Compose files!**
|
||||
|
||||
---
|
||||
|
||||
## Untrusted code
|
||||
|
||||
- Should be safe as long as we're not enabling dangerous features
|
||||
|
||||
(privileged containers, volume mounts, device access, capabilities...)
|
||||
|
||||
- Remember that by default, containers can make network calls
|
||||
|
||||
(but see: `--net none` and also `docker network create --internal`)
|
||||
|
||||
- And of course, again: vulnerabilities do exist!
|
||||
|
||||
---
|
||||
|
||||
## What about Kubernetes?
|
||||
|
||||
- Ability to run arbitrary pods = dangerous
|
||||
|
||||
- But there are multiple safety mechanisms available:
|
||||
|
||||
- Pod Security Settings (limit "dangerous" features)
|
||||
|
||||
- RBAC (control who can do what)
|
||||
|
||||
- webhooks and policy engines for even finer grained control
|
||||
159
slides/exercises/container-from-scratch-details.md
Normal file
159
slides/exercises/container-from-scratch-details.md
Normal file
@@ -0,0 +1,159 @@
|
||||
# Exercise — Build a container from scratch
|
||||
|
||||
Our goal will be to execute a container running a simple web server.
|
||||
|
||||
(Example: NGINX, or https://github.com/jpetazzo/color.)
|
||||
|
||||
We want the web server to be isolated:
|
||||
|
||||
- it shouldn't be able to access the outside world,
|
||||
|
||||
- but we should be able to connect to it from our machine.
|
||||
|
||||
Make sure to automate / script things as much as possible!
|
||||
|
||||
---
|
||||
|
||||
## Steps
|
||||
|
||||
1. Prepare the filesystem
|
||||
|
||||
2. Run it with chroot
|
||||
|
||||
3. Isolation with namespaces
|
||||
|
||||
4. Network configuration
|
||||
|
||||
5. Cgroups
|
||||
|
||||
6. Non-root
|
||||
|
||||
---
|
||||
|
||||
## Prepare the filesystem
|
||||
|
||||
- Obtain a root filesystem with one of the following methods:
|
||||
|
||||
- download an Alpine mini root fs
|
||||
|
||||
- export an Alpine or NGINX container image with Docker
|
||||
|
||||
- download and convert a container image with Skopeo
|
||||
|
||||
- make it from scratch with busybox + a static [jpetazzo/color](https://github.com/jpetazzo/color)
|
||||
|
||||
- ...anything you want! (Nix, anyone?)
|
||||
|
||||
- Enter the root filesystem with `chroot`
|
||||
|
||||
---
|
||||
|
||||
## Help, network does not work!
|
||||
|
||||
- Check that you have external connectivity from the chroot:
|
||||
```bash
|
||||
ping 1.1.1.1
|
||||
```
|
||||
(that *should* work; if it doesn't, we have a serious problem!)
|
||||
|
||||
- Check that DNS resolution works:
|
||||
```bash
|
||||
ping enix.io
|
||||
```
|
||||
|
||||
- If you're having a DNS resolution error, configure DNS in the container:
|
||||
```bash
|
||||
echo nameserver 1.1.1.1 > /etc/resolv.conf
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Running a web server
|
||||
|
||||
Here are a few possibilities...
|
||||
|
||||
- Install the NGINX package and run it with `nginx`
|
||||
|
||||
(note: by default it will start in the background)
|
||||
|
||||
- Run NGINX in the foreground with `nginx -g "daemon off;"`
|
||||
|
||||
- Install the package Caddy and run `caddy file-server -ab`
|
||||
|
||||
(it will remain in the foreground and show logs; **RECOMMENDED**)
|
||||
|
||||
- Download and/or build https://github.com/jpetazzo/color
|
||||
|
||||
(if you're familiar with the Go ecosystem!)
|
||||
|
||||
---
|
||||
|
||||
## Run with chroot
|
||||
|
||||
- Start the web server from within the chroot
|
||||
|
||||
- Confirm that you can connect to it from outside
|
||||
|
||||
- Write a script to start our "proto-container"
|
||||
|
||||
---
|
||||
|
||||
## Isolation with namespaces
|
||||
|
||||
- Now, enter the root filesystem with `unshare`
|
||||
|
||||
(enable all the namespaces you want; maybe not `user` yet, though!)
|
||||
|
||||
- Start the web server
|
||||
|
||||
(you might need to configure at least the loopback network interface!)
|
||||
|
||||
- Confirm that we *cannot* connect from outside
|
||||
|
||||
- Update the our start script to use unshare
|
||||
|
||||
- Automate network configuration
|
||||
|
||||
(pay attention to the fact that network tools *may not* exist in the container)
|
||||
|
||||
---
|
||||
|
||||
## Network configuration
|
||||
|
||||
- While our "container" is running, create a `veth` pair
|
||||
|
||||
- Move one `veth` to the container
|
||||
|
||||
- Assign addresses to both `veth`
|
||||
|
||||
- Confirm that we can connect to the web server from outside
|
||||
|
||||
(using the address assigned to the container's `veth`)
|
||||
|
||||
- Update our start script to automate the setup of the `veth` pair
|
||||
|
||||
- Bonus points: update the script to that it can start *multiple* containers
|
||||
|
||||
---
|
||||
|
||||
## Cgroups
|
||||
|
||||
- Create a cgroup for our container
|
||||
|
||||
- Move the container to the cgroup
|
||||
|
||||
- Set a very low CPU limit and confirm that it slows down the server
|
||||
|
||||
(but doesn't affect the rest of the system)
|
||||
|
||||
- Update the script to automate this
|
||||
|
||||
---
|
||||
|
||||
## Non-root
|
||||
|
||||
- Switch to a non-privileged user when starting the container
|
||||
|
||||
- Adjust the web server configuration so that it starts
|
||||
|
||||
(non-privileged users cannot bind to ports below 1024)
|
||||
32
slides/exercises/dmuc-auth-details.md
Normal file
32
slides/exercises/dmuc-auth-details.md
Normal file
@@ -0,0 +1,32 @@
|
||||
# Exercise — enable auth
|
||||
|
||||
- We want to enable authentication and authorization
|
||||
|
||||
- Checklist:
|
||||
|
||||
- non-privileged user can deploy in their namespace
|
||||
<br/>(and nowhere else)
|
||||
|
||||
- each controller uses its own key, certificate, and identity
|
||||
|
||||
- each node uses its own key, certificate, and identity
|
||||
|
||||
- Service Accounts work properly
|
||||
|
||||
- See next slide for help / hints!
|
||||
|
||||
---
|
||||
|
||||
## Checklist
|
||||
|
||||
- Generate keys, certs, and kubeconfig for everything that needs them
|
||||
|
||||
(cluster admin, cluster user, controller manager, scheduler, kubelet)
|
||||
|
||||
- Reconfigure and restart each component to use its new identity
|
||||
|
||||
- Turn on `RBAC` and `Node` authorizers on the API server
|
||||
|
||||
- Check that everything works properly
|
||||
|
||||
(e.g. that you can create and scale a Deployment using the "cluster user" identity)
|
||||
51
slides/exercises/dmuc-networking-details.md
Normal file
51
slides/exercises/dmuc-networking-details.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# Exercise — networking
|
||||
|
||||
- We want to install extra networking components:
|
||||
|
||||
- a CNI configuration
|
||||
|
||||
- kube-proxy
|
||||
|
||||
- CoreDNS
|
||||
|
||||
- After doing that, we should be able to deploy a "complex" app
|
||||
|
||||
(with multiple containers communicating together + service discovery)
|
||||
|
||||
---
|
||||
|
||||
## CNI
|
||||
|
||||
- Easy option: Weave
|
||||
|
||||
https://github.com/weaveworks/weave/releases
|
||||
|
||||
- Better option: Cilium
|
||||
|
||||
https://docs.cilium.io/en/stable/gettingstarted/k8s-install-default/#install-the-cilium-cli
|
||||
|
||||
or https://docs.cilium.io/en/stable/installation/k8s-install-helm/#installation-using-helm
|
||||
|
||||
---
|
||||
|
||||
## kube-proxy
|
||||
|
||||
- Option 1: author a DaemonSet
|
||||
|
||||
- Option 2: leverage the CNI (some CNIs like Cilium can replace kube-proxy)
|
||||
|
||||
---
|
||||
|
||||
## CoreDNS
|
||||
|
||||
- Suggested method: Helm chart
|
||||
|
||||
(available on https://github.com/coredns/helm)
|
||||
|
||||
---
|
||||
|
||||
## Testing
|
||||
|
||||
- Try to deploy DockerCoins and confirm that it works
|
||||
|
||||
(for instance with [this YAML file](https://raw.githubusercontent.com/jpetazzo/container.training/refs/heads/main/k8s/dockercoins.yaml))
|
||||
22
slides/exercises/dmuc-staticpods-details.md
Normal file
22
slides/exercises/dmuc-staticpods-details.md
Normal file
@@ -0,0 +1,22 @@
|
||||
# Exercise — static pods
|
||||
|
||||
- We want to run the control plane in static pods
|
||||
|
||||
(etcd, API server, controller manager, scheduler)
|
||||
|
||||
- For Kubernetes components, we can use [these images](https://kubernetes.io/releases/download/#container-images)
|
||||
|
||||
- For etcd, we can use [this image](https://quay.io/repository/coreos/etcd?tab=tags)
|
||||
|
||||
- If we're using keys, certificates... We can use [hostPath volumes](https://kubernetes.io/docs/concepts/storage/volumes/#hostpath)
|
||||
|
||||
---
|
||||
|
||||
## Testing
|
||||
|
||||
After authoring our static pod manifests and placing them in the right directory,
|
||||
we should be able to start our cluster simply by starting kubelet.
|
||||
|
||||
(Assuming that the container engine is already running.)
|
||||
|
||||
For bonus points: write and enable a systemd unit for kubelet!
|
||||
@@ -26,7 +26,7 @@
|
||||
|
||||
- it should initially show a few milliseconds latency
|
||||
|
||||
- that will increase when we scale up
|
||||
- that will increase when we scale up the number of `worker` Pods
|
||||
|
||||
- it will also let us detect when the service goes "boom"
|
||||
|
||||
|
||||
35
slides/exercises/image-from-scratch-details.md
Normal file
35
slides/exercises/image-from-scratch-details.md
Normal file
@@ -0,0 +1,35 @@
|
||||
# Exercise — Images from scratch
|
||||
|
||||
There are two parts in this exercise:
|
||||
|
||||
1. Obtaining and unpacking an image from scratch
|
||||
|
||||
2. Adding overlay mounts to the "container from scratch" lab
|
||||
|
||||
---
|
||||
|
||||
## Pulling from scratch, easy mode
|
||||
|
||||
- Download manifest and layers with `skopeo`
|
||||
|
||||
- Parse manifest and configuration with e.g. `jq`
|
||||
|
||||
- Uncompress the layers in a directory
|
||||
|
||||
- Check that the result works (using `chroot`)
|
||||
|
||||
---
|
||||
|
||||
## Pulling from scratch, medium mode
|
||||
|
||||
- Don't use `skopeo`
|
||||
|
||||
- Hints: if pulling from the Docker Hub, you'll need a token
|
||||
|
||||
(there are examples in Docker's documentation)
|
||||
|
||||
---
|
||||
|
||||
## Pulling from scratch, hard mode
|
||||
|
||||
- Handle whiteouts!
|
||||
@@ -26,8 +26,8 @@ When a Service gets created...
|
||||
|
||||
- We want to use a Kyverno `generate` ClusterPolicy
|
||||
|
||||
- For step 1, check [Generate Resources](https://kyverno.io/docs/writing-policies/generate/) documentation
|
||||
- For step 1, check [Generate Resources](https://kyverno.io/docs/policy-types/cluster-policy/generate/) documentation
|
||||
|
||||
- For step 2, check [Preconditions](https://kyverno.io/docs/writing-policies/preconditions/) documentation
|
||||
- For step 2, check [Preconditions](https://kyverno.io/docs/policy-types/cluster-policy/preconditions/) documentation
|
||||
|
||||
- For step 3, check [External Data Sources](https://kyverno.io/docs/writing-policies/external-data-sources/) documentation
|
||||
- For step 3, check [External Data Sources](https://kyverno.io/docs/policy-types/cluster-policy/external-data-sources/) documentation
|
||||
|
||||
51
slides/exercises/monokube-details.md
Normal file
51
slides/exercises/monokube-details.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# Exercise — Monokube static pods
|
||||
|
||||
- We want to run a very basic Kubernetes cluster by starting only:
|
||||
|
||||
- kubelet
|
||||
|
||||
- a container engine (e.g. Docker)
|
||||
|
||||
- The other components (control plane and otherwise) should be started with:
|
||||
|
||||
- static pods
|
||||
|
||||
- "classic" manifests loaded with e.g. `kubectl apply`
|
||||
|
||||
- This should be done with the "monokube" VM
|
||||
|
||||
(which has Docker and kubelet 1.19 binaries available)
|
||||
|
||||
---
|
||||
|
||||
## Images to use
|
||||
|
||||
Here are some suggestions of images:
|
||||
|
||||
- etcd → `quay.io/coreos/etcd:vX.Y.Z`
|
||||
|
||||
- Kubernetes components → `registry.k8s.io/kube-XXX:vX.Y.Z`
|
||||
|
||||
(where `XXX` = `apiserver`, `scheduler`, `controller-manager`)
|
||||
|
||||
To know which versions to use, check the version of the binaries installed on the `monokube` VM, and use the same ones.
|
||||
|
||||
See next slide for more hints!
|
||||
|
||||
---
|
||||
|
||||
## Inventory
|
||||
|
||||
We'll need to run:
|
||||
|
||||
- kubelet (with the flag for static pod manifests)
|
||||
|
||||
- Docker
|
||||
|
||||
- static pods for control plane components
|
||||
|
||||
(suggestion: use `hostNetwork`)
|
||||
|
||||
- static pod or DaemonSet for `kube-proxy`
|
||||
|
||||
(will require a privileged security context)
|
||||
86
slides/exercises/yaml-bluegreen-details.md
Normal file
86
slides/exercises/yaml-bluegreen-details.md
Normal file
@@ -0,0 +1,86 @@
|
||||
# Exercise — Writing blue/green YAML
|
||||
|
||||
- We want to author YAML manifests for the "color" app
|
||||
|
||||
(use image `jpetazzo/color` or `ghcr.io/jpetazzo/color`)
|
||||
|
||||
- That app serves web requests on port 80
|
||||
|
||||
- We want to deploy two instances of that app (`blue` and `green`)
|
||||
|
||||
- We want to expose the app with a service named `front`, such that:
|
||||
|
||||
90% of the requests are sent to `blue`, and 10% to `green`
|
||||
|
||||
---
|
||||
|
||||
## End goal
|
||||
|
||||
- We want to be able to do something like:
|
||||
```bash
|
||||
kubectl apply -f blue-green-demo.yaml
|
||||
```
|
||||
|
||||
- Then connect to the `front` service and see responses from `blue` and `green`
|
||||
|
||||
- Then measure e.g. on 100 requests how many go to `blue` and `green`
|
||||
|
||||
(we want a 90/10 traffic split)
|
||||
|
||||
- Go ahead, or check the next slides for hints!
|
||||
|
||||
---
|
||||
|
||||
## Step 1
|
||||
|
||||
- Test the app in isolation:
|
||||
|
||||
- create a Deployment called `blue`
|
||||
|
||||
- expose it with a Service
|
||||
|
||||
- connect to the service and see a "blue" reply
|
||||
|
||||
- If you use a `ClusterIP` service:
|
||||
|
||||
- if you're logged directly on the clusters you can connect directly
|
||||
|
||||
- otherwise you can use `kubectl port-forward`
|
||||
|
||||
- Otherwise, you can use a `NodePort` or `LoadBalancer` service
|
||||
|
||||
---
|
||||
|
||||
## Step 2
|
||||
|
||||
- Add the `green` Deployment
|
||||
|
||||
- Create the `front` service
|
||||
|
||||
- Edit the `front` service to replace its selector with a custom one
|
||||
|
||||
- Edit `blue` and `green` to add the label(s) of your custom selector
|
||||
|
||||
- Check that traffic hits both green and blue
|
||||
|
||||
- Think about how to obtain the 90/10 traffic split
|
||||
|
||||
---
|
||||
|
||||
## Step 3
|
||||
|
||||
- Generate, write, extract, ... YAML manifests for all components
|
||||
|
||||
(`blue` and `green` Deployments, `front` Service)
|
||||
|
||||
- Check that applying the manifests (e.g. in a brand new namespace) works
|
||||
|
||||
- Bonus points: add a one-shot pod to check the traffic split!
|
||||
|
||||
---
|
||||
|
||||
## Discussion
|
||||
|
||||
- Would this be a viable option to obtain, say, a 95% / 5% traffic split?
|
||||
|
||||
- What about 99% / 1 %?
|
||||
126
slides/flux/add-cluster.md
Normal file
126
slides/flux/add-cluster.md
Normal file
@@ -0,0 +1,126 @@
|
||||
|
||||
## Flux install
|
||||
|
||||
We'll install `Flux`.
|
||||
And replay the all scenario a 2nd time.
|
||||
Let's face it: we don't have that much time. 😅
|
||||
|
||||
Since all our install and configuration is `GitOps`-based, we might just leverage on copy-paste and code configuration…
|
||||
Maybe.
|
||||
|
||||
Let's copy the 📂 `./clusters/CLOUDY` folder and rename it 📂 `./clusters/METAL`.
|
||||
|
||||
---
|
||||
|
||||
### Modifying Flux config 📄 files
|
||||
|
||||
- In 📄 file `./clusters/METAL/flux-system/gotk-sync.yaml`
|
||||
</br>change the `Kustomization` value `spec.path: ./clusters/METAL`
|
||||
- ⚠️ We'll have to adapt the `Flux` _CLI_ command line
|
||||
|
||||
- And that's pretty much it!
|
||||
- We'll see if anything goes wrong on that new cluster
|
||||
|
||||
---
|
||||
|
||||
### Connecting to our dedicated `Github` repo to host Flux config
|
||||
|
||||
.lab[
|
||||
|
||||
- let's replace `GITHUB_TOKEN` and `GITHUB_REPO` values
|
||||
- don't forget to change the patch to `clusters/METAL`
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ export GITHUB_TOKEN="my-token" && \
|
||||
export GITHUB_USER="container-training-fleet" && \
|
||||
export GITHUB_REPO="fleet-config-using-flux-XXXXX"
|
||||
|
||||
k8s@shpod:~$ flux bootstrap github \
|
||||
--owner=${GITHUB_USER} \
|
||||
--repository=${GITHUB_REPO} \
|
||||
--team=OPS \
|
||||
--team=ROCKY --team=MOVY \
|
||||
--path=clusters/METAL
|
||||
```
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Flux deployed our complete stack
|
||||
|
||||
Everything seems to be here but…
|
||||
|
||||
- one database is in `Pending` state
|
||||
|
||||
- our `ingresses` don't work well
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ curl --header 'Host: rocky.test.enixdomain.com' http://${myIngressControllerSvcIP}
|
||||
curl: (52) Empty reply from server
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Fixing the Ingress
|
||||
|
||||
The current `ingress-nginx` configuration leverages on specific annotations used by Scaleway to bind a _IaaS_ load-balancer to the `ingress-controller`.
|
||||
We don't have such kind of things here.😕
|
||||
|
||||
- We could bind our `ingress-controller` to a `NodePort`.
|
||||
`ingress-nginx` install manifests propose it here:
|
||||
</br>https://github.com/kubernetes/ingress-nginx/deploy/static/provider/baremetal
|
||||
|
||||
- In the 📄file `./clusters/METAL/ingress-nginx/sync.yaml`,
|
||||
</br>change the `Kustomization` value `spec.path: ./deploy/static/provider/baremetal`
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Troubleshooting the database
|
||||
|
||||
One of our `db-0` pod is in `Pending` state.
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ k get pods db-0 -n *-test -oyaml
|
||||
(…)
|
||||
status:
|
||||
conditions:
|
||||
- lastProbeTime: null
|
||||
lastTransitionTime: "2025-06-11T11:15:42Z"
|
||||
message: '0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims.
|
||||
preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.'
|
||||
reason: Unschedulable
|
||||
status: "False"
|
||||
type: PodScheduled
|
||||
phase: Pending
|
||||
qosClass: Burstable
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Troubleshooting the PersistentVolumeClaims
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ k get pvc postgresql-data-db-0 -n *-test -o yaml
|
||||
(…)
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal FailedBinding 9s (x182 over 45m) persistentvolume-controller no persistent volumes available for this claim and no storage class is set
|
||||
```
|
||||
|
||||
No `storage class` is available on this cluster.
|
||||
We hadn't the problem on our managed cluster since a default storage class was configured and then associated to our `PersistentVolumeClaim`.
|
||||
|
||||
Why is there no problem with the other database?
|
||||
|
||||
417
slides/flux/app1-rocky-test.md
Normal file
417
slides/flux/app1-rocky-test.md
Normal file
@@ -0,0 +1,417 @@
|
||||
# R01- Configuring **_🎸ROCKY_** deployment with Flux
|
||||
|
||||
The **_⚙️OPS_** team manages 2 distinct envs: **_⚗️TEST_** et _**🚜PROD**_
|
||||
|
||||
Thanks to _Kustomize_
|
||||
1. it creates a **_base_** common config
|
||||
2. this common config is overwritten with a **_⚗️TEST_** _tenant_-specific configuration
|
||||
3. the same applies with a _**🚜PROD**_-specific configuration
|
||||
|
||||
> 💡 This seems complex, but no worries: Flux's CLI handles most of it.
|
||||
|
||||
---
|
||||
|
||||
## Creating the **_🎸ROCKY_**-dedicated _tenant_ in **_⚗️TEST_** env
|
||||
|
||||
- Using the `flux` _CLI_, we create the file configuring the **_🎸ROCKY_** team's dedicated _tenant_…
|
||||
- … this file takes place in the `base` common configuration for both envs
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
mkdir -p ./tenants/base/rocky && \
|
||||
flux create tenant rocky \
|
||||
--with-namespace=rocky-test \
|
||||
--cluster-role=rocky-full-access \
|
||||
--export > ./tenants/base/rocky/rbac.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### 📂 ./tenants/base/rocky/rbac.yaml
|
||||
|
||||
Let's see our file…
|
||||
|
||||
3 resources are created: `Namespace`, `ServiceAccount`, and `ClusterRoleBinding`
|
||||
|
||||
`Flux` **impersonates** as this `ServiceAccount` when it applies any resources found in this _tenant_-dedicated source(s)
|
||||
|
||||
- By default, the `ServiceAccount` is bound to the `cluster-admin` `ClusterRole`
|
||||
- The team maintaining the sourced `Github` repository is almighty at cluster scope
|
||||
|
||||
A not that much isolated _tenant_! 😕
|
||||
|
||||
That's why the **_⚙️OPS_** team enforces specific `ClusterRoles` with restricted permissions
|
||||
|
||||
Let's create these permissions!
|
||||
|
||||
---
|
||||
|
||||
## _namespace_ isolation for **_🎸ROCKY_**
|
||||
|
||||
.lab[
|
||||
|
||||
- Here are the restricted permissions to use in the `rocky-test` `Namespace`
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cp ~/container.training/k8s/M6-rocky-cluster-role.yaml ./tenants/base/rocky/
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
> 💡 Note that some resources are managed at cluster scope (like `PersistentVolumes`).
|
||||
> We need specific permissions, then…
|
||||
|
||||
---
|
||||
|
||||
## Creating `Github` source in Flux for **_🎸ROCKY_** app repository
|
||||
|
||||
A specific _branch_ of the `Github` repository is monitored by the `Flux` source
|
||||
|
||||
.lab[
|
||||
|
||||
- ⚠️ you may change the **repository URL** to the one of your own clone
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create source git rocky-app \
|
||||
--namespace=rocky-test \
|
||||
--url=https://github.com/Musk8teers/container.training-spring-music/ \
|
||||
--branch=rocky --export > ./tenants/base/rocky/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Creating `kustomization` in Flux for **_🎸ROCKY_** app repository
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create kustomization rocky \
|
||||
--namespace=rocky-test \
|
||||
--service-account=rocky \
|
||||
--source=GitRepository/rocky-app \
|
||||
--path="./k8s/" --export >> ./tenants/base/rocky/sync.yaml
|
||||
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cd ./tenants/base/rocky/ && \
|
||||
kustomize create --autodetect && \
|
||||
cd -
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### 📂 Flux config files
|
||||
|
||||
Let's review our `Flux` configuration files
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cat ./tenants/base/rocky/sync.yaml && \
|
||||
cat ./tenants/base/rocky/kustomization.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Adding a kustomize patch for **_⚗️TEST_** cluster deployment
|
||||
|
||||
💡 Remember the DRY strategy!
|
||||
|
||||
- The `Flux` tenant-dedicated configuration is looking for this file: `.tenants/test/rocky/kustomization.yaml`
|
||||
- It has been configured here: `clusters/CLOUDY/tenants.yaml`
|
||||
|
||||
- All the files we just created are located in `.tenants/base/rocky`
|
||||
- So we have to create a specific kustomization in the right location
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
mkdir -p ./tenants/test/rocky && \
|
||||
cp ~/container.training/k8s/M6-rocky-test-patch.yaml ./tenants/test/rocky/ && \
|
||||
cp ~/container.training/k8s/M6-rocky-test-kustomization.yaml ./tenants/test/rocky/kustomization.yaml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Synchronizing Flux config with its Github repo
|
||||
|
||||
Locally, our `Flux` config repo is ready
|
||||
The **_⚙️OPS_** team has to push it to `Github` for `Flux` controllers to watch and catch it!
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
git add . && \
|
||||
git commit -m':wrench: :construction_worker: add ROCKY tenant configuration' && \
|
||||
git push
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux resources for ROCKY tenant 1/2
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux get all -A
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
flux-system gitrepository/flux-system main@sha1:8ffd72cf False
|
||||
True stored artifact for revision 'main@sha1:8ffd72cf'
|
||||
rocky-test gitrepository/rocky-app rocky@sha1:ffe9f3fe False
|
||||
True stored artifact for revision 'rocky@sha1:ffe9f3fe'
|
||||
(…)
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux resources for ROCKY _tenant_ 2/2
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux get all -A
|
||||
(…)
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
flux-system kustomization/flux-system main@sha1:8ffd72cf False
|
||||
True Applied revision: main@sha1:8ffd72cf
|
||||
flux-system kustomization/tenant-prod False
|
||||
False kustomization path not found: stat /tmp/kustomization-1164119282/tenants/prod: no such file or directory
|
||||
flux-system kustomization/tenant-test main@sha1:8ffd72cf False
|
||||
True Applied revision: main@sha1:8ffd72cf
|
||||
rocky-test kustomization/rocky False
|
||||
False StatefulSet/db dry-run failed (Forbidden): statefulsets.apps "db" is forbidden: User "system:serviceaccount:rocky-test:rocky" cannot patch resource "statefulsets" in API group "apps" at the cluster scope
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
And here is our 2nd Flux error(s)! 😅
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux Kustomization, mutability, …
|
||||
|
||||
🔍 Notice that none of the expected resources is created:
|
||||
the whole kustomization is rejected, even if the `StatefulSet` is this only resource that fails!
|
||||
|
||||
🔍 Flux Kustomization uses the dry-run feature to templatize the resources and then applying patches onto them
|
||||
Good but some resources are not completely mutable, such as `StatefulSets`
|
||||
|
||||
We have to fix the mutation by applying the change without having to patch the resource.
|
||||
|
||||
🔍 Simply add the `spec.targetNamespace: rocky-test` to the `Kustomization` named `rocky`
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## And then it's deployed 1/2
|
||||
|
||||
You should see the following resources in the `rocky-test` namespace
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod-578d64468-tp7r2 ~/$ k get pods,svc,deployments -n rocky-test
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
pod/db-0 1/1 Running 0 47s
|
||||
pod/web-6c677bf97f-c7pkv 0/1 Running 1 (22s ago) 47s
|
||||
pod/web-6c677bf97f-p7b4r 0/1 Running 1 (19s ago) 47s
|
||||
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
service/db ClusterIP 10.32.6.128 <none> 5432/TCP 48s
|
||||
service/web ClusterIP 10.32.2.202 <none> 80/TCP 48s
|
||||
|
||||
NAME READY UP-TO-DATE AVAILABLE AGE
|
||||
deployment.apps/web 0/2 2 0 47s
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## And then it's deployed 2/2
|
||||
|
||||
You should see the following resources in the `rocky-test` namespace
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod-578d64468-tp7r2 ~/$ k get statefulsets,pvc,pv -n rocky-test
|
||||
NAME READY AGE
|
||||
statefulset.apps/db 1/1 47s
|
||||
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
|
||||
persistentvolumeclaim/postgresql-data-db-0 Bound pvc-c1963a2b-4fc9-4c74-9c5a-b0870b23e59a 1Gi RWO sbs-default <unset> 47s
|
||||
|
||||
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
|
||||
persistentvolume/postgresql-data 1Gi RWO,RWX Retain Available <unset> 47s
|
||||
persistentvolume/pvc-150fcef5-ebba-458e-951f-68a7e214c635 1G RWO Delete Bound shpod/shpod sbs-default <unset> 4h46m
|
||||
persistentvolume/pvc-c1963a2b-4fc9-4c74-9c5a-b0870b23e59a 1Gi RWO Delete Bound rocky-test/postgresql-data-db-0 sbs-default <unset> 47s
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### PersistentVolumes are using a default `StorageClass`
|
||||
|
||||
💡 This managed cluster comes with custom `StorageClasses` leveraging on Cloud _IaaS_ capabilities (i.e. block devices)
|
||||
|
||||

|
||||
|
||||
- a default `StorageClass` is applied if none is specified (like here)
|
||||
- for **_🏭PROD_** purpose, ops team might enforce a more performant `StorageClass`
|
||||
- on a bare-metal cluster, **_🏭PROD_** team has to configure and provide `StorageClasses` on its own
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
|
||||
## Upgrading ROCKY app
|
||||
|
||||
The Git source named `rocky-app` is pointing at
|
||||
- a Github repository named [Musk8teers/container.training-spring-music](https://github.com/Musk8teers/container.training-spring-music/)
|
||||
- on its branch named `rocky`
|
||||
|
||||
This branch deploy the v1.0.0 of the _Web_ app:
|
||||
`spec.template.spec.containers.image: ghcr.io/musk8teers/container.training-spring-music:1.0.0`
|
||||
|
||||
What happens if the **_🎸ROCKY_** team upgrades its branch to deploy `v1.0.1` of the _Web_ app?
|
||||
|
||||
---
|
||||
|
||||
## _tenant_ **_🏭PROD_**
|
||||
|
||||
💡 **_🏭PROD_** _tenant_ is still waiting for its `Flux` configuration, but don't bother for it right now.
|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:3
|
||||
branch MOVY order:4
|
||||
branch YouRHere order:5
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
</pre>
|
||||
320
slides/flux/app2-movy-test.md
Normal file
320
slides/flux/app2-movy-test.md
Normal file
@@ -0,0 +1,320 @@
|
||||
# M01- Configuring **_🎬MOVY_** deployment with Flux
|
||||
|
||||
**_🎸ROCKY_** _tenant_ is now fully usable in **_⚗️TEST_** env, let's do the same for another _dev_ team: **_🎬MOVY_**
|
||||
|
||||
😈 We could do it by using `Flux` _CLI_,
|
||||
but let's see if we can succeed by just adding manifests in our `Flux` configuration repository.
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Impact study
|
||||
|
||||
In our `Flux` configuration repository:
|
||||
|
||||
- Creation of the following 📂 folders: `./tenants/[base|test]/MOVY`
|
||||
|
||||
- Modification of the following 📄 file: `./clusters/CLOUDY/tenants.yaml`?
|
||||
- Well, we don't need to: the watched path include the whole `./tenants/[test]/*` folder
|
||||
|
||||
In the app repository:
|
||||
|
||||
- Creation of a `movy` branch to deploy another version of the app dedicated to movie soundtracks
|
||||
|
||||
---
|
||||
|
||||
### Creation of the 📂 folders
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cp -pr tenants/base/rocky tenants/base/movy
|
||||
cp -pr tenants/test/rocky tenants/test/movy
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Modification of tenants/[base|test]/movy/* 📄 files
|
||||
|
||||
- For 📄`M6-rocky-*.yaml`, change the file names…
|
||||
- and update the 📄`kustomization.yaml` file as a result
|
||||
|
||||
- In any file, replace any `rocky` entry by `movy`
|
||||
|
||||
- In 📄 `sync.yaml` be aware of what repository and what branch you want `Flux` to watch for **_🎬MOVY_** app deployment.
|
||||
- for this demo, let's assume we create a `movy` branch
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### What about reusing rocky-cluster-roles?
|
||||
|
||||
💡 In 📄`M6-movy-cluster-role.yaml` and 📄`rbac.yaml`, we could have reused the already existing `ClusterRoles`: `rocky-full-access`, and `rocky-pv-access`
|
||||
|
||||
A `ClusterRole` is cluster wide. It is not dedicated to a namespace.
|
||||
- Its permissions are restrained to a specific namespace by being bound to a `ServiceAccount` by a `RoleBinding`.
|
||||
- Whereas a `ClusterRoleBinding` extends the permissions to the whole cluster scope.
|
||||
|
||||
But a _tenant_ is a **_tenant_** and permissions might evolved separately for **_🎸ROCKY_** and **_🎬MOVY_**.
|
||||
|
||||
So [we got to keep'em separated](https://www.youtube.com/watch?v=GHUql3OC_uU).
|
||||
|
||||
---
|
||||
|
||||
### Let-su-go!
|
||||
|
||||
The **_⚙️OPS_** team push this new tenant configuration to `Github` for `Flux` controllers to watch and catch it!
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
git add . && \
|
||||
git commit -m':wrench: :construction_worker: add MOVY tenant configuration' && \
|
||||
git push
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Another Flux error?
|
||||
|
||||
.lab[
|
||||
|
||||
- It seems that our `movy` branch is not present in the app repository
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux get kustomization -A
|
||||
NAMESPACE NAME REVISION SUSPENDED MESSAGE
|
||||
(…)
|
||||
flux-system tenant-prod False False kustomization path not found: stat /tmp/kustomization-113582828/tenants/prod: no such file or directory
|
||||
(…)
|
||||
movy-test movy False False Source artifact not found, retrying in 30s
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Creating the `movy` branch
|
||||
|
||||
- Let's create this new `movy` branch from `rocky` branch
|
||||
|
||||
.lab[
|
||||
|
||||
- You can force immediate reconciliation by typing this command:
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux reconcile source git movy-app -n movy-test
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### New branch detected
|
||||
|
||||
You now have a second app responding on [http://movy.test.mybestdomain.com]
|
||||
But as of now, it's just the same as the **_🎸ROCKY_** one.
|
||||
|
||||
We want a specific (pink-colored) version with a dataset full of movie soundtracks.
|
||||
|
||||
---
|
||||
|
||||
## New version of the **_🎬MOVY_** app
|
||||
|
||||
In our branch `movy`…
|
||||
Let's modify our `deployment.yaml` file with 2 modifications.
|
||||
|
||||
- in `spec.template.spec.containers.image` change the container image tag to `1.0.3`
|
||||
|
||||
- and… let's introduce some evil enthropy by changing this line… 😈😈😈
|
||||
|
||||
```yaml
|
||||
value: jdbc:postgresql://db/music
|
||||
```
|
||||
|
||||
by this one
|
||||
|
||||
```yaml
|
||||
value: jdbc:postgresql://db.rocky-test/music
|
||||
```
|
||||
|
||||
And push the modifications…
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### MOVY app is connected to ROCKY database
|
||||
|
||||
How evil have we been! 😈
|
||||
We connected the **_🎬MOVY_** app to the **_🎸ROCKY_** database.
|
||||
|
||||
Even if our tenants are isolated in how they manage their Kubernetes resources…
|
||||
pod network is still full mesh and any connection is authorized.
|
||||
|
||||
> The **_⚙️OPS_** team should fix this!
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Adding NetworkPolicies to **_🎸ROCKY_** and **_🎬MOVY_** namespaces
|
||||
|
||||
`Network policies` may be seen as the firewall feature in the pod network.
|
||||
They rules ingress and egress network connections considering a described subset of pods.
|
||||
|
||||
Please, refer to the [`Network policies` chapter in the High Five M4 module](./4.yml.html#toc-network-policies)
|
||||
|
||||
- In our case, we just add the file `~/container.training/k8s/M6-network-policies.yaml`
|
||||
</br>in our `./tenants/base/movy` folder
|
||||
|
||||
- without forgetting to update our `kustomization.yaml` file
|
||||
|
||||
- and without forgetting to commit 😁
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:3
|
||||
branch MOVY order:4
|
||||
branch YouRHere order:5
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'k0s install on METAL cluster' tag:'K01'
|
||||
commit id:'Flux config. for METAL cluster' tag:'K02'
|
||||
branch METAL_TEST-PROD order:3
|
||||
commit id:'ROCKY/MOVY tenants on METAL' type: HIGHLIGHT
|
||||
checkout OPS
|
||||
commit id:'Flux config. for OpenEBS' tag:'K03'
|
||||
checkout METAL_TEST-PROD
|
||||
merge OPS id:'openEBS on METAL' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Prometheus install'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Kyverno install'
|
||||
commit id:'Kyverno rules'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
</pre>
|
||||
410
slides/flux/bootstrap.md
Normal file
410
slides/flux/bootstrap.md
Normal file
@@ -0,0 +1,410 @@
|
||||
# T02- creating **_⚗️TEST_** env on our **_☁️CLOUDY_** cluster
|
||||
|
||||
Let's take a look at our **_☁️CLOUDY_** cluster!
|
||||
|
||||
**_☁️CLOUDY_** is a Kubernetes cluster created with [Scaleway Kapsule](https://www.scaleway.com/en/kubernetes-kapsule/) managed service
|
||||
|
||||
This managed cluster comes preinstalled with specific features:
|
||||
- Kubernetes dashboard
|
||||
- specific _Storage Classes_ based on Scaleway _IaaS_ block storage offerings
|
||||
- a `Cilium` _CNI_ stack already set up
|
||||
|
||||
---
|
||||
|
||||
## Accessing the managed Kubernetes cluster
|
||||
|
||||
To access our cluster, we'll connect via [`shpod`](https://github.com/jpetazzo/shpod)
|
||||
|
||||
.lab[
|
||||
|
||||
- If you already have a kubectl on your desktop computer
|
||||
```bash
|
||||
kubectl -n shpod run shpod --image=jpetazzo/shpod
|
||||
kubectl -n shpod exec -it shpod -- bash
|
||||
```
|
||||
- or directly via ssh
|
||||
```bash
|
||||
ssh -p myPort k8s@mySHPODSvcIpAddress
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Flux installation
|
||||
|
||||
Once `Flux` is installed,
|
||||
the **_⚙️OPS_** team exclusively operates its clusters by updating a code base in a `Github` repository
|
||||
|
||||
_GitOps_ and `Flux` enable the **_⚙️OPS_** team to rely on the _first-class citizen pattern_ in Kubernetes' world through these steps:
|
||||
|
||||
- describe the **desired target state**
|
||||
- and let the **automated convergence** happens
|
||||
|
||||
---
|
||||
|
||||
### Checking prerequisites
|
||||
|
||||
The `Flux` _CLI_ is available in our `shpod` pod
|
||||
|
||||
Before installation, we need to check that:
|
||||
- `Flux` _CLI_ is correctly installed
|
||||
- it can connect to the `API server`
|
||||
- our versions of `Flux` and Kubernetes are compatible
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux --version
|
||||
flux version 2.5.1
|
||||
|
||||
k8s@shpod:~$ flux check --pre
|
||||
► checking prerequisites
|
||||
✔ Kubernetes 1.32.3 >=1.30.0-0
|
||||
✔ prerequisites checks passed
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Git repository for Flux configuration
|
||||
|
||||
The **_⚙️OPS_** team uses `Flux` _CLI_
|
||||
- to create a `git` repository named `fleet-config-using-flux-XXXXX` (⚠ replace `XXXXX` by a personnal suffix)
|
||||
- in our `Github` organization named `container-training-fleet`
|
||||
|
||||
Prerequisites are:
|
||||
- `Flux` _CLI_ needs a `Github` personal access token (_PAT_)
|
||||
- to create and/or access the `Github` repository
|
||||
- to give permissions to existing teams in our `Github` organization
|
||||
- The PAT needs _CRUD_ permissions on our `Github` organization
|
||||
- repositories
|
||||
- admin:public_key
|
||||
- users
|
||||
|
||||
- As **_⚙️OPS_** team, let's creates a `Github` personal access token…
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Creating dedicated `Github` repo to host Flux config
|
||||
|
||||
.lab[
|
||||
|
||||
- let's replace the `GITHUB_TOKEN` value by our _Personal Access Token_
|
||||
- and the `GITHUB_REPO` value by our specific repository name
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ export GITHUB_TOKEN="my-token" && \
|
||||
export GITHUB_USER="container-training-fleet" && \
|
||||
export GITHUB_REPO="fleet-config-using-flux-XXXXX"
|
||||
|
||||
k8s@shpod:~$ flux bootstrap github \
|
||||
--owner=${GITHUB_USER} \
|
||||
--repository=${GITHUB_REPO} \
|
||||
--team=OPS \
|
||||
--team=ROCKY --team=MOVY \
|
||||
--path=clusters/CLOUDY
|
||||
```
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
Here is the result
|
||||
|
||||
```bash
|
||||
✔ repository "https://github.com/container-training-fleet/fleet-config-using-flux-XXXXX" created
|
||||
► reconciling repository permissions
|
||||
✔ granted "maintain" permissions to "OPS"
|
||||
✔ granted "maintain" permissions to "ROCKY"
|
||||
✔ granted "maintain" permissions to "MOVY"
|
||||
► reconciling repository permissions
|
||||
✔ reconciled repository permissions
|
||||
► cloning branch "main" from Git repository "https://github.com/container-training-fleet/fleet-config-using-flux-XXXXX.git"
|
||||
✔ cloned repository
|
||||
► generating component manifests
|
||||
✔ generated component manifests
|
||||
✔ committed component manifests to "main" ("7c97bdeb5b932040fd8d8a65fe1dc84c66664cbf")
|
||||
► pushing component manifests to "https://github.com/container-training-fleet/fleet-config-using-flux-XXXXX.git"
|
||||
✔ component manifests are up to date
|
||||
► installing components in "flux-system" namespace
|
||||
✔ installed components
|
||||
✔ reconciled components
|
||||
► determining if source secret "flux-system/flux-system" exists
|
||||
► generating source secret
|
||||
✔ public key: ecdsa-sha2-nistp384 AAAAE2VjZHNhLXNoYTItbmlzdHAzODQAAAAIbmlzdHAzODQAAABhBFqaT8B8SezU92qoE+bhnv9xONv9oIGuy7yVAznAZfyoWWEVkgP2dYDye5lMbgl6MorG/yjfkyo75ETieAE49/m9D2xvL4esnSx9zsOLdnfS9W99XSfFpC2n6soL+Exodw==
|
||||
✔ configured deploy key "flux-system-main-flux-system-./clusters/CLOUDY" for "https://github.com/container-training-fleet/fleet-config-using-flux-XXXXX"
|
||||
► applying source secret "flux-system/flux-system"
|
||||
✔ reconciled source secret
|
||||
► generating sync manifests
|
||||
✔ generated sync manifests
|
||||
✔ committed sync manifests to "main" ("11035e19cabd9fd2c7c94f6e93707f22d69a5ff2")
|
||||
► pushing sync manifests to "https://github.com/container-training-fleet/fleet-config-using-flux-XXXXX.git"
|
||||
► applying sync manifests
|
||||
✔ reconciled sync configuration
|
||||
◎ waiting for GitRepository "flux-system/flux-system" to be reconciled
|
||||
✔ GitRepository reconciled successfully
|
||||
◎ waiting for Kustomization "flux-system/flux-system" to be reconciled
|
||||
✔ Kustomization reconciled successfully
|
||||
► confirming components are healthy
|
||||
✔ helm-controller: deployment ready
|
||||
✔ kustomize-controller: deployment ready
|
||||
✔ notification-controller: deployment ready
|
||||
✔ source-controller: deployment ready
|
||||
✔ all components are healthy
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Flux configures Github repository access for teams
|
||||
|
||||
- `Flux` sets up permissions that allow teams within our organization to **access** the `Github` repository as maintainers
|
||||
- Teams need to exist before `Flux` proceeds to this configuration
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### ⚠️ Disclaimer
|
||||
|
||||
- In this lab, adding these teams as maintainers was merely a demonstration of how `Flux` _CLI_ sets up permissions in Github
|
||||
|
||||
- But there is no need for dev teams to have access to this `Github` repository
|
||||
|
||||
- One advantage of _GitOps_ lies in its ability to easily set up 💪🏼 **Separation of concerns** by using multiple `Flux` sources
|
||||
|
||||
---
|
||||
|
||||
### 📂 Flux config files
|
||||
|
||||
`Flux` has been successfully installed onto our **_☁️CLOUDY_** Kubernetes cluster!
|
||||
|
||||
Its configuration is managed through a _Gitops_ workflow sourced directly from our `Github` repository
|
||||
|
||||
Let's review our `Flux` configuration files we've created and pushed into the `Github` repository…
|
||||
… as well as the corresponding components running in our Kubernetes cluster
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
<!-- FIXME: wrong schema -->
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux resources 1/2
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ kubectl get all --namespace flux-system
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
pod/helm-controller-b6767d66-h6qhk 1/1 Running 0 5m
|
||||
pod/kustomize-controller-57c7ff5596-94rnd 1/1 Running 0 5m
|
||||
pod/notification-controller-58ffd586f7-zxfvk 1/1 Running 0 5m
|
||||
pod/source-controller-6ff87cb475-g6gn6 1/1 Running 0 5m
|
||||
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
service/notification-controller ClusterIP 10.104.139.156 <none> 80/TCP 5m1s
|
||||
service/source-controller ClusterIP 10.106.120.137 <none> 80/TCP 5m
|
||||
service/webhook-receiver ClusterIP 10.96.28.236 <none> 80/TCP 5m
|
||||
(…)
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux resources 2/2
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ kubectl get all --namespace flux-system
|
||||
(…)
|
||||
NAME READY UP-TO-DATE AVAILABLE AGE
|
||||
deployment.apps/helm-controller 1/1 1 1 5m
|
||||
deployment.apps/kustomize-controller 1/1 1 1 5m
|
||||
deployment.apps/notification-controller 1/1 1 1 5m
|
||||
deployment.apps/source-controller 1/1 1 1 5m
|
||||
|
||||
NAME DESIRED CURRENT READY AGE
|
||||
replicaset.apps/helm-controller-b6767d66 1 1 1 5m
|
||||
replicaset.apps/kustomize-controller-57c7ff5596 1 1 1 5m
|
||||
replicaset.apps/notification-controller-58ffd586f7 1 1 1 5m
|
||||
replicaset.apps/source-controller-6ff87cb475 1 1 1 5m
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Flux components
|
||||
|
||||
- the `source controller` monitors `Git` repositories to apply Kubernetes resources on the cluster
|
||||
|
||||
- the `Helm controller` checks for new `Helm` _charts_ releases in `Helm` repositories and installs updates as needed
|
||||
|
||||
- _CRDs_ store `Flux` configuration within the Kubernetes control plane
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux resources that have been created
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux get all --all-namespaces
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
flux-system gitrepository/flux-system main@sha1:d48291a8 False
|
||||
True stored artifact for revision 'main@sha1:d48291a8'
|
||||
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
flux-system kustomization/flux-system main@sha1:d48291a8 False
|
||||
True Applied revision: main@sha1:d48291a8
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Flux CLI
|
||||
|
||||
`Flux` Command-Line Interface fulfills 3 primary functions:
|
||||
|
||||
1. It installs and configures first mandatory `Flux` resources in a _Gitops_ `git` repository
|
||||
- ensuring proper access and permissions
|
||||
|
||||
2. It locally generates `YAML` files for desired `Flux` resources so that we just need to `git push` them
|
||||
- _tenants_
|
||||
- sources
|
||||
- …
|
||||
|
||||
3. It requests the API server to manage `Flux`-related resources
|
||||
- _operators_
|
||||
- _CRDs_
|
||||
- logs
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Flux -- for more info
|
||||
|
||||
Please, refer to the [`Flux` chapter in the High Five M3 module](./3.yml.html#toc-helm-chart-format)
|
||||
|
||||
---
|
||||
|
||||
### Flux relies on Kustomize
|
||||
|
||||
The `Flux` component named `kustomize controller` look for `Kustomize` resources in `Flux` code-based sources
|
||||
|
||||
1. `Kustomize` look for `YAML` manifests listed in the `kustomization.yaml` file
|
||||
|
||||
2. and aggregates, hydrates and patches them following the `kustomization` configuration
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### 2 different kustomization resources
|
||||
|
||||
⚠️ `Flux` uses 2 distinct resources with `kind: kustomization`
|
||||
|
||||
```yaml
|
||||
apiVersion: kustomize.config.k8s.io/v1beta1
|
||||
kind: kustomization
|
||||
```
|
||||
|
||||
describes how Kustomize (the _CLI_ tool) appends and transforms `YAML` manifests into a single bunch of `YAML` described resources
|
||||
|
||||
```yaml
|
||||
apiVersion: kustomize.toolkit.fluxcd.io/v1 group
|
||||
kind: Kustomization
|
||||
```
|
||||
|
||||
describes where `Flux kustomize-controller` looks for a `kustomization.yaml` file in a given `Flux` code-based source
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Kustomize -- for more info
|
||||
|
||||
Please, refer to the [`Kustomize` chapter in the High Five M3 module](./3.yml.html#toc-kustomize)
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Group / Version / Kind -- for more info
|
||||
|
||||
For more info about how Kubernetes resource natures are identified by their `Group / Version / Kind` triplet…
|
||||
… please, refer to the [`Kubernetes API` chapter in the High Five M5 module](./5.yml.html#toc-the-kubernetes-api)
|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:3
|
||||
branch MOVY order:4
|
||||
branch YouRHere order:5
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
</pre>
|
||||
284
slides/flux/ingress.md
Normal file
284
slides/flux/ingress.md
Normal file
@@ -0,0 +1,284 @@
|
||||
# T05- Configuring ingress for **_🎸ROCKY_** app
|
||||
|
||||
🍾 **_🎸ROCKY_** team has just deployed its `v1.0.0`
|
||||
|
||||
We would like to reach it from our workstations
|
||||
The regular way to do it in Kubernetes is to configure an `Ingress` resource.
|
||||
|
||||
- `Ingress` is an abstract resource that manages how services are exposed outside of the Kubernetes cluster (Layer 7).
|
||||
- It relies on `ingress-controller`(s) that are technical solutions to handle all the rules related to ingress.
|
||||
|
||||
- Available features vary, depending on the `ingress-controller`: load-balancing, networking, firewalling, API management, throttling, TLS encryption, etc.
|
||||
- `ingress-controller` may provision Cloud _IaaS_ network resources such as load-balancer, persistent IPs, etc.
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Ingress -- for more info
|
||||
|
||||
Please, refer to the [`Ingress` chapter in the High Five M2 module](./2.yml.html#toc-exposing-http-services-with-ingress-resources)
|
||||
|
||||
---
|
||||
|
||||
## Installing `ingress-nginx` as our `ingress-controller`
|
||||
|
||||
We'll use `ingress-nginx` (relying on `NGinX`), quite a popular choice.
|
||||
|
||||
- It is able to provision IaaS load-balancer in ScaleWay Cloud services
|
||||
- As a reverse-proxy, it is able to balance HTTP connections on an on-premises cluster
|
||||
|
||||
The **_⚙️OPS_** Team add this new install to its `Flux` config. repo
|
||||
|
||||
---
|
||||
|
||||
### Creating a `Github` source in Flux for `ingress-nginx`
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
mkdir -p ./clusters/CLOUDY/ingress-nginx && \
|
||||
flux create source git ingress-nginx \
|
||||
--namespace=ingress-nginx \
|
||||
--url=https://github.com/kubernetes/ingress-nginx/ \
|
||||
--branch=release-1.12 \
|
||||
--export > ./clusters/CLOUDY/ingress-nginx/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Creating `kustomization` in Flux for `ingress-nginx`
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create kustomization ingress-nginx \
|
||||
--namespace=ingress-nginx \
|
||||
--source=GitRepository/ingress-nginx \
|
||||
--path="./deploy/static/provider/scw/" \
|
||||
--export >> ./clusters/CLOUDY/ingress-nginx/sync.yaml
|
||||
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cp -p ~/container.training/k8s/M6-ingress-nginx-kustomization.yaml \
|
||||
./clusters/CLOUDY/ingress-nginx/kustomization.yaml && \
|
||||
cp -p ~/container.training/k8s/M6-ingress-nginx-components.yaml \
|
||||
~/container.training/k8s/M6-ingress-nginx-*-patch.yaml \
|
||||
./clusters/CLOUDY/ingress-nginx/
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Applying the new config
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
git add ./clusters/CLOUDY/ingress-nginx && \
|
||||
git commit -m':wrench: :rocket: add Ingress-controller' && \
|
||||
git push
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Using external Git source
|
||||
|
||||
💡 Note that you can directly use pubilc `Github` repository (not maintained by your company).
|
||||
|
||||
- If you have to alter the configuration, `Kustomize` patching capabilities might help.
|
||||
|
||||
- Depending on the _gitflow_ this repository uses, updates will be deployed automatically to your cluster (here we're using a `release` branch).
|
||||
|
||||
- This repo exposes a `kustomization.yaml`. Well done!
|
||||
|
||||
---
|
||||
|
||||
## Adding the `ingress` resource to ROCKY app
|
||||
|
||||
.lab[
|
||||
|
||||
- Add the new manifest to our kustomization bunch
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
cp -pr ~/container.training/k8s/M6-rocky-ingress.yaml ./tenants/base/rocky && \
|
||||
echo '- M6-rocky-ingress.yaml' >> ./tenants/base/rocky/kustomization.yaml
|
||||
```
|
||||
|
||||
- Commit and its done
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
git add . && \
|
||||
git commit -m':wrench: :rocket: add Ingress' && \
|
||||
git push
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Here is the result
|
||||
|
||||
After Flux reconciled the whole bunch of sources and kustomizations, you should see
|
||||
|
||||
- `Ingress-NGinX` controller components in `ingress-nginx` namespace
|
||||
- A new `Ingress` in `rocky-test` namespace
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ kubectl get all -n ingress-nginx && \
|
||||
kubectl get ingress -n rocky-test
|
||||
|
||||
k8s@shpod:~$ \
|
||||
PublicIP=$(kubectl get ingress rocky -n rocky-test \
|
||||
-o jsonpath='{.status.loadBalancer.ingress[0].ip}')
|
||||
|
||||
k8s@shpod:~$ \
|
||||
curl --header 'rocky.test.mybestdomain.com' http://$PublicIP/
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Upgrading **_🎸ROCKY_** app
|
||||
|
||||
**_🎸ROCKY_** team is now fully able to upgrade and deploy its app autonomously.
|
||||
|
||||
Just give it a try!
|
||||
- In the `deployment.yaml` file
|
||||
- in the app repo ([https://github.com/Musk8teers/container.training-spring-music/])
|
||||
- you can change the `spec.template.spec.containers.image` to `1.0.1` and then to `1.0.2`
|
||||
|
||||
Dont' forget which branch is watched by `Flux` Git source named `rocky`
|
||||
|
||||
Don't forget to commit!
|
||||
|
||||
---
|
||||
|
||||
## Few considerations
|
||||
|
||||
- The **_⚙️OPS_** team has to decide how to manage name resolution for public IPs
|
||||
- Scaleway propose to expose a wildcard domain for its Kubernetes clusters
|
||||
|
||||
- Here, we chose that `Ingress-controller` (that makes sense) but `Ingress` as well were managed by the **_⚙️OPS_** team.
|
||||
- It might have been done in many different ways!
|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:3
|
||||
branch MOVY order:4
|
||||
branch YouRHere order:5
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
</pre>
|
||||
241
slides/flux/kyverno.md
Normal file
241
slides/flux/kyverno.md
Normal file
@@ -0,0 +1,241 @@
|
||||
## introducing Kyverno
|
||||
|
||||
Kyverno is a tool to extend Kubernetes permission management to express complex policies…
|
||||
</br>… and override manifests delivered by client teams.
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
### Kyverno -- for more info
|
||||
|
||||
Please, refer to the [`Setting up Kubernetes` chapter in the High Five M4 module](./4.yml.html#toc-policy-management-with-kyverno) for more infos about `Kyverno`.
|
||||
|
||||
---
|
||||
|
||||
## Creating an `Helm` source in Flux for OpenEBS Helm chart
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
mkdir -p clusters/CLOUDY/kyverno && \
|
||||
cp -pr ~/container.training/k8s/
|
||||
|
||||
k8s@shpod ~$ flux create source helm kyverno \
|
||||
--namespace=kyverno \
|
||||
--url=https://kyverno.github.io/kyverno/ \
|
||||
--interval=3m \
|
||||
--export > ./clusters/CLOUDY/kyverno/sync2.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Creating the `HelmRelease` in Flux
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ flux create helmrelease kyverno \
|
||||
--namespace=kyverno \
|
||||
--source=HelmRepository/kyverno.flux-system \
|
||||
--target-namespace=kyverno \
|
||||
--create-target-namespace=true \
|
||||
--chart-version=">=3.4.2" \
|
||||
--chart=kyverno \
|
||||
--export >> ./clusters/CLOUDY/kyverno/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Add Kyverno policy
|
||||
|
||||
This polivy is just an example.
|
||||
It enforces the use of a `Service Account` in `Flux` configurations
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
mkdir -p clusters/CLOUDY/kyverno-policies && \
|
||||
cp -pr ~/container.training/k8s/M6-kyverno-enforce-service-account.yaml \
|
||||
./clusters/CLOUDY/kyverno-policies/
|
||||
|
||||
---
|
||||
|
||||
### Creating `kustomization` in Flux for Kyverno policies
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
flux create kustomization kyverno-policies \
|
||||
--namespace=kyverno \
|
||||
--source=GitRepository/flux-system \
|
||||
--path="./clusters/CLOUDY/kyverno-policies/" \
|
||||
--prune true --interval 5m \
|
||||
--depends-on kyverno \
|
||||
--export >> ./clusters/CLOUDY/kyverno-policies/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
|
||||
## Apply Kyverno policy
|
||||
```bash
|
||||
flux create kustomization
|
||||
|
||||
--path
|
||||
--source GitRepository/
|
||||
--export > ./clusters/CLOUDY/kyverno-policies/sync.yaml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Add Kyverno dependency for **_⚗️TEST_** cluster
|
||||
|
||||
- Now that we've got `Kyverno` policies,
|
||||
- ops team will enforce any upgrade from any kustomization in our dev team tenants
|
||||
- to wait for the `kyverno` policies to be reconciled (in a `Flux` perspective)
|
||||
|
||||
- upgrade file `./clusters/CLOUDY/tenants.yaml`,
|
||||
- by adding this property: `spec.dependsOn.{name: kyverno-policies}`
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Debugging
|
||||
|
||||
`Kyverno-policies` `Kustomization` failed because `spec.dependsOn` property can only target a resource from the same `Kind`.
|
||||
|
||||
- Let's suppress the `spec.dependsOn` property.
|
||||
|
||||
Now `Kustomizations` for **_🎸ROCKY_** and **_🎬MOVY_** tenants failed because of our policies.
|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:4
|
||||
branch MOVY order:5
|
||||
branch YouRHere order:6
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT tag:'T07'
|
||||
|
||||
checkout OPS
|
||||
commit id:'k0s install on METAL cluster' tag:'K01'
|
||||
commit id:'Flux config. for METAL cluster' tag:'K02'
|
||||
branch METAL_TEST-PROD order:3
|
||||
commit id:'ROCKY/MOVY tenants on METAL' type: HIGHLIGHT
|
||||
checkout OPS
|
||||
commit id:'Flux config. for OpenEBS' tag:'K03'
|
||||
checkout METAL_TEST-PROD
|
||||
merge OPS id:'openEBS on METAL' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Prometheus install'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Kyverno install'
|
||||
commit id:'Kyverno rules'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for PROD tenant' tag:'P01'
|
||||
branch PROD-env order:2
|
||||
commit id:'ROCKY tenant on PROD'
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for PROD' tag:'R04'
|
||||
checkout PROD-env
|
||||
merge OPS id:'PROD ready to deploy ROCKY' type: HIGHLIGHT
|
||||
checkout PROD-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY HELM chart' tag:'M03'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0'
|
||||
</pre>
|
||||
251
slides/flux/observability.md
Normal file
251
slides/flux/observability.md
Normal file
@@ -0,0 +1,251 @@
|
||||
# Install monitoring stack
|
||||
|
||||
The **_⚙️OPS_** team wants to have a real monitoring stack for its clusters.
|
||||
Let's deploy `Prometheus` and `Grafana` onto the clusters.
|
||||
|
||||
Note:
|
||||
|
||||
---
|
||||
|
||||
## Creating `Github` source in Flux for monitoring components install repository
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ mkdir -p clusters/CLOUDY/kube-prometheus-stack
|
||||
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create source git monitoring \
|
||||
--namespace=monitoring \
|
||||
--url=https://github.com/fluxcd/flux2-monitoring-example.git \
|
||||
--branch=main --export > ./clusters/CLOUDY/kube-prometheus-stack/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Creating `kustomization` in Flux for monitoring stack
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create kustomization monitoring \
|
||||
--namespace=monitoring \
|
||||
--source=GitRepository/monitoring \
|
||||
--path="./monitoring/controllers/kube-prometheus-stack/" \
|
||||
--export >> ./clusters/CLOUDY/kube-prometheus-stack/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Install Flux Grafana dashboards
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux create kustomization dashboards \
|
||||
--namespace=monitoring \
|
||||
--source=GitRepository/monitoring \
|
||||
--path="./monitoring/configs/" \
|
||||
--export >> ./clusters/CLOUDY/kube-prometheus-stack/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Flux repository synchro is broken😅
|
||||
|
||||
It seems that `Flux` on **_☁️CLOUDY_** cluster is not able to authenticate with `ssh` on its `Github` config repository!
|
||||
|
||||
What happened?
|
||||
When we install `Flux` on **_🤘METAL_** cluster, it generates a new `ssh` keypair and override the one used by **_☁️CLOUDY_** among the "deployment keys" of the `Github` repository.
|
||||
|
||||
⚠️ Beware of flux bootstrap command!
|
||||
|
||||
We have to
|
||||
- generate a new keypair (or reuse an already existing one)
|
||||
- add the private key to the Flux-dedicated secrets in **_☁️CLOUDY_** cluster
|
||||
- add it to the "deployment keys" of the `Github` repository
|
||||
|
||||
---
|
||||
|
||||
### the command
|
||||
|
||||
.lab[
|
||||
|
||||
- `Flux` _CLI_ helps to recreate the secret holding the `ssh` **private** key.
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ flux create secret git flux-system \
|
||||
--url=ssh://git@github.com/container-training-fleet/fleet-config-using-flux-XXXXX \
|
||||
--private-key-file=/home/k8s/.ssh/id_ed25519
|
||||
```
|
||||
|
||||
- copy the **public** key into the deployment keys of the `Github` repository
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## Access the Grafana dashboard
|
||||
|
||||
.lab[
|
||||
|
||||
- Get the `Host` and `IP` address to request
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ kubectl -n monitoring get ingress
|
||||
NAME CLASS HOSTS ADDRESS PORTS AGE
|
||||
grafana nginx grafana.test.metal.mybestdomain.com 62.210.39.83 80 6m30s
|
||||
```
|
||||
|
||||
- Get the `Grafana` admin password
|
||||
|
||||
```bash
|
||||
k8s@shpod:~$ k get secret kube-prometheus-stack-grafana -n monitoring \
|
||||
-o jsonpath='{.data.admin-password}' | base64 -d
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
## And browse…
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:4
|
||||
branch MOVY order:5
|
||||
branch YouRHere order:6
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT tag:'T07'
|
||||
|
||||
checkout OPS
|
||||
commit id:'k0s install on METAL cluster' tag:'K01'
|
||||
commit id:'Flux config. for METAL cluster' tag:'K02'
|
||||
branch METAL_TEST-PROD order:3
|
||||
commit id:'ROCKY/MOVY tenants on METAL' type: HIGHLIGHT
|
||||
checkout OPS
|
||||
commit id:'Flux config. for OpenEBS' tag:'K03'
|
||||
checkout METAL_TEST-PROD
|
||||
merge OPS id:'openEBS on METAL' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Prometheus install'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Kyverno install'
|
||||
commit id:'Kyverno rules'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for PROD tenant' tag:'P01'
|
||||
branch PROD-env order:2
|
||||
commit id:'ROCKY tenant on PROD'
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for PROD' tag:'R04'
|
||||
checkout PROD-env
|
||||
merge OPS id:'PROD ready to deploy ROCKY' type: HIGHLIGHT
|
||||
checkout PROD-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY HELM chart' tag:'M03'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0'
|
||||
</pre>
|
||||
129
slides/flux/openebs.md
Normal file
129
slides/flux/openebs.md
Normal file
@@ -0,0 +1,129 @@
|
||||
# K03- Installing OpenEBS as our CSI
|
||||
|
||||
`OpenEBS` is a _CSI_ solution capable of hyperconvergence, synchronous replication and other extra features.
|
||||
It installs with `Helm` charts.
|
||||
|
||||
- `Flux` is able to watch `Helm` repositories and install `HelmReleases`
|
||||
- To inject its configuration into the `Helm chart` , `Flux` relies on a `ConfigMap` including the `values.yaml` file
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ mkdir -p ./clusters/METAL/openebs/ && \
|
||||
cp -pr ~/container.training/k8s/M6-openebs-*.yaml \
|
||||
./clusters/METAL/openebs/ && \
|
||||
cd ./clusters/METAL/openebs/ && \
|
||||
mv M6-openebs-kustomization.yaml kustomization.yaml && \
|
||||
cd -
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Creating an `Helm` source in Flux for OpenEBS Helm chart
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ flux create source helm openebs \
|
||||
--url=https://openebs.github.io/openebs \
|
||||
--interval=3m \
|
||||
--export > ./clusters/METAL/openebs/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Creating the `HelmRelease` in Flux
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ flux create helmrelease openebs \
|
||||
--namespace=openebs \
|
||||
--source=HelmRepository/openebs.flux-system \
|
||||
--chart=openebs \
|
||||
--values-from=ConfigMap/openebs-values \
|
||||
--export >> ./clusters/METAL/openebs/sync.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## 📂 Let's review the files
|
||||
|
||||
- `M6-openebs-components.yaml`
|
||||
</br>To include the `Flux` resources in the same _namespace_ where `Flux` installs the `OpenEBS` resources, we need to create the _namespace_ **before** the installation occurs
|
||||
|
||||
- `sync.yaml`
|
||||
</br>The resources `Flux` uses to watch and get the `Helm chart`
|
||||
|
||||
- `M6-openebs-values.yaml`
|
||||
</br> the `values.yaml` file that will be injected into the `Helm chart`
|
||||
|
||||
- `kustomization.yaml`
|
||||
</br>This one is a bit special: it includes a [ConfigMap generator](https://kubectl.docs.kubernetes.io/references/kustomize/kustomization/configmapgenerator/)
|
||||
|
||||
- `M6-openebs-kustomizeconfig.yaml`
|
||||
</br></br>This one is tricky: in order for `Flux` to trigger an upgrade of the `Helm Release` when the `ConfigMap` is altered, you need to explain to the `Kustomize ConfigMap generator` how the resources are relating with each others. 🤯
|
||||
|
||||
And here we go!
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## And the result
|
||||
|
||||
Now, we have a _cluster_ featuring `openEBS`.
|
||||
But still… The PersistentVolumeClaim remains in `Pending` state!😭
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ kubectl get storageclass
|
||||
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
|
||||
openebs-hostpath openebs.io/local Delete WaitForFirstConsumer false 82m
|
||||
```
|
||||
We still don't have a default `StorageClass`!😤
|
||||
|
||||
---
|
||||
|
||||
### Manually enforcing the default `StorageClass`
|
||||
|
||||
Even if Flux is constantly reconciling our resources, we still are able to test evolutions by hand.
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ flux suspend helmrelease openebs -n openebs
|
||||
► suspending helmrelease openebs in openebs namespace
|
||||
✔ helmrelease suspended
|
||||
k8s@shpod ~$ kubectl patch storageclass openebs-hostpath \
|
||||
-p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
|
||||
|
||||
k8s@shpod ~$ k get storageclass
|
||||
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
|
||||
openebs-hostpath (default) openebs.io/local Delete WaitForFirstConsumer false 82m
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### Now the database is OK
|
||||
|
||||
```bash
|
||||
k8s@shpod ~$ get pvc,pods -n movy-test
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
|
||||
persistentvolumeclaim/postgresql-data-db-0 Bound pvc-ede1634f-2478-42cd-8ee3-7547cd7cdde2 1Gi RWO openebs-hostpath <unset> 20m
|
||||
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
pod/db-0 1/1 Running 0 5h43m
|
||||
(…)
|
||||
```
|
||||
354
slides/flux/scenario.md
Normal file
354
slides/flux/scenario.md
Normal file
@@ -0,0 +1,354 @@
|
||||
# Kubernetes in production — <br/>an end-to-end example
|
||||
|
||||
- Previous training modules focused on individual topics
|
||||
|
||||
(e.g. RBAC, network policies, CRDs, Helm...)
|
||||
|
||||
- We will now show how to put everything together to deploy apps in production
|
||||
|
||||
(dealing with typical challenges like: multiple apps, multiple teams, multiple clusters...)
|
||||
|
||||
- Our first challenge will be to pick and choose which components to use
|
||||
|
||||
(among the vast [Cloud Native Landscape](https://landscape.cncf.io/))
|
||||
|
||||
- We'll start with a basic Kubernetes cluster (on cloud or on premises)
|
||||
|
||||
- We'll and enhance it by adding features one at a time
|
||||
|
||||
---
|
||||
|
||||
## The cast
|
||||
|
||||
There are 3 teams in our company:
|
||||
|
||||
- **_⚙️OPS_** is the platform engineering team
|
||||
|
||||
- they're responsible for building and configuring Kubernetes clusters
|
||||
|
||||
- the **_🎸ROCKY_** team develops and manages the **_🎸ROCKY_** app
|
||||
|
||||
- that app manages a collection of _rock & pop_ albums
|
||||
|
||||
- it's deployed with plain YAML manifests
|
||||
|
||||
- the **_🎬MOVY_** team develops and manages the **_🎬MOVY_** app
|
||||
|
||||
- that app manages a collection of _movie soundtrack_ albums
|
||||
|
||||
- it's deployed with Helm charts
|
||||
|
||||
---
|
||||
|
||||
## Code and team organization
|
||||
|
||||
- **_🎸ROCKY_** and **_🎬MOVY_** reside in separate git repositories
|
||||
|
||||
- Each team can write code, build package, and deploy their applications:
|
||||
|
||||
- independently
|
||||
<br/>(= without having to worry about what's happening in the other repo)
|
||||
|
||||
- autonomously
|
||||
<br/>(= without having to synchronize or obtain privileges from another team)
|
||||
|
||||
---
|
||||
|
||||
## Cluster organization
|
||||
|
||||
The **_⚙️OPS_** team manages 2 Kubernetes clusters:
|
||||
|
||||
- **_☁️CLOUDY_**: managed cluster from a public cloud provider
|
||||
|
||||
- **_🤘METAL_**: custom-built cluster installed on bare Linux servers
|
||||
|
||||
Let's see the differences between these clusters.
|
||||
|
||||
---
|
||||
|
||||
## **_☁️CLOUDY_** cluster
|
||||
|
||||
- Managed cluster from a public cloud provider ("Kubernetes-as-a-Service")
|
||||
|
||||
- HA control plane deployed and managed by the cloud provider
|
||||
|
||||
- Two worker nodes (potentially with cluster autoscaling)
|
||||
|
||||
- Usually comes pre-installed with some basic features
|
||||
|
||||
(e.g. metrics-server, CNI, CSI, sometimes an ingress controller)
|
||||
|
||||
- Requires extra components to be production-ready
|
||||
|
||||
(e.g. Flux or other gitops pipeline, observability...)
|
||||
|
||||
- Example: [Scaleway Kapsule][kapsule] (but many other KaaS options are available)
|
||||
|
||||
[kapsule]: https://www.scaleway.com/en/kubernetes-kapsule/
|
||||
|
||||
---
|
||||
|
||||
## **_🤘METAL_** cluster
|
||||
|
||||
- Custom-built cluster installed on bare Linux servers
|
||||
|
||||
- HA control plane deployed and managed by the **_⚙️OPS_** team
|
||||
|
||||
- 3 nodes
|
||||
|
||||
- in our example, the nodes will run both the control plane and our apps
|
||||
|
||||
- it is more typical to use dedicated control plane nodes
|
||||
<br/>(example: 3 control plane nodes + at least 3 worker nodes)
|
||||
|
||||
- Comes with even less pre-installed components than **_☁️CLOUDY_**
|
||||
|
||||
(requiring more work from our **_⚙️OPS_** team)
|
||||
|
||||
- Example: we'll use [k0s] (but many other distros are available)
|
||||
|
||||
[k0s]: https://k0sproject.io/
|
||||
|
||||
---
|
||||
|
||||
## **_⚗️TEST_** and **_🏭PROD_**
|
||||
|
||||
- The **_⚙️OPS_** team creates 2 environments for each dev team
|
||||
|
||||
(**_⚗️TEST_** and **_🏭PROD_**)
|
||||
|
||||
- These environments exist on both clusters
|
||||
|
||||
(meaning 2 apps × 2 clusters × 2 envs = 8 envs total)
|
||||
|
||||
- The setup for each env and cluster should follow DRY principles
|
||||
|
||||
(to ensure configurations are consistent and minimize maintenance)
|
||||
|
||||
- Each cluster and each env has its own lifecycle
|
||||
|
||||
(= it should be possible to deploy, add an extra components/feature...
|
||||
<br/>on one env without impacting the other)
|
||||
|
||||
---
|
||||
|
||||
### Multi-tenancy
|
||||
|
||||
Both **_🎸ROCKY_** and **_🎬MOVY_** teams should use **dedicated _"tenants"_** on each cluster/env
|
||||
|
||||
- the **_🎸ROCKY_** team should be able to deploy, upgrade and configure its app within its dedicated **namespace** without anybody else involved
|
||||
|
||||
- and the same for **_🎬MOVY_**
|
||||
|
||||
- neither team's deployments might interfere with the other, maintaining a clean and conflict-free environment
|
||||
|
||||
---
|
||||
|
||||
## Application overview
|
||||
|
||||
- Both dev teams are working on an app to manage music albums
|
||||
|
||||
- This app is mostly based on a `Spring` framework demo called spring-music
|
||||
|
||||
- This lab uses a dedicated fork [container.training-spring-music](https://github.com/Musk8teers/container.training-spring-music):
|
||||
- with 2 branches dedicated to the **_🎸ROCKY_** and **_🎬MOVY_** teams
|
||||
|
||||
- The app architecture consists of 2 tiers:
|
||||
- a `Java/Spring` Web app
|
||||
- a `PostgreSQL` database
|
||||
|
||||
---
|
||||
|
||||
### 📂 specific file: application.yaml
|
||||
|
||||
This is where we configure the application to connect to the `PostgreSQL` database.
|
||||
|
||||
.lab[
|
||||
|
||||
🔍 Location: [/src/main/resources/application.yml](https://github.com/Musk8teers/container.training-spring-music/blob/main/src/main/resources/application.yml)
|
||||
|
||||
]
|
||||
|
||||
`PROFILE=postgres` env var is set in [docker-compose.yaml](https://github.com/Musk8teers/container.training-spring-music/blob/main/docker-compose.yml) file, for example…
|
||||
|
||||
---
|
||||
|
||||
### 📂 specific file: AlbumRepositoryPopulator.java
|
||||
|
||||
|
||||
This is where the album collection is initially loaded from the file [`album.json`](https://github.com/Musk8teers/container.training-spring-music/blob/main/src/main/resources/albums.json)
|
||||
|
||||
.lab[
|
||||
|
||||
🔍 Location: [`/src/main/java/org/cloudfoundry/samples/music/repositories/AlbumRepositoryPopulator.java`](https://github.com/Musk8teers/container.training-spring-music/blob/main/src/main/java/org/cloudfoundry/samples/music/repositories/AlbumRepositoryPopulator.java)
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## 🚚 How to deploy?
|
||||
|
||||
The **_⚙️OPS_** team offers 2 deployment strategies that dev teams can use autonomously:
|
||||
|
||||
- **_🎸ROCKY_** uses a `Flux` _GitOps_ workflow based on regular Kubernetes `YAML` resources
|
||||
|
||||
- **_🎬MOVY_** uses a `Flux` _GitOps_ workflow based on `Helm` charts
|
||||
|
||||
---
|
||||
|
||||
## 🍱 What features?
|
||||
|
||||
<!-- TODO: complete this slide when all the modules are there -->
|
||||
The **_⚙️OPS_** team aims to provide clusters offering the following features to its users:
|
||||
|
||||
- a network stack with efficient workload isolation
|
||||
|
||||
- ingress and load-balancing capabilites
|
||||
|
||||
- an enterprise-grade monitoring solution for real-time insights
|
||||
|
||||
- automated policy rule enforcement to control Kubernetes resources requested by dev teams
|
||||
|
||||
<!-- - HA PostgreSQL -->
|
||||
|
||||
<!-- - HTTPs certificates to expose the applications -->
|
||||
|
||||
---
|
||||
|
||||
## 🌰 In a nutshell
|
||||
|
||||
- 3 teams: **_⚙️OPS_**, **_🎸ROCKY_**, **_🎬MOVY_**
|
||||
|
||||
- 2 clusters: **_☁️CLOUDY_**, **_🤘METAL_**
|
||||
|
||||
- 2 envs per cluster and per dev team: **_⚗️TEST_**, **_🏭PROD_**
|
||||
|
||||
- 2 Web apps Java/Spring + PostgreSQL: one for pop and rock albums, another for movie soundtrack albums
|
||||
|
||||
- 2 deployment strategies: regular `YAML` resources + `Kustomize`, `Helm` charts
|
||||
|
||||
|
||||
> 💻 `Flux` is used both
|
||||
> - to operate the clusters
|
||||
> - and to manage the _GitOps_ deployment workflows
|
||||
|
||||
---
|
||||
|
||||
### What our scenario might look like…
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:4
|
||||
branch MOVY order:5
|
||||
branch YouRHere order:6
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
|
||||
checkout OPS
|
||||
commit id:'Ingress-controller config.' tag:'T05'
|
||||
checkout TEST-env
|
||||
merge OPS id:'Ingress-controller install' type: HIGHLIGHT tag:'T06'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for ingress config.' tag:'R03'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ingress config. for ROCKY app'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'blue color' tag:'v1.0.1'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.1'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'pink color' tag:'v1.0.2'
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout OPS
|
||||
commit id:'FLUX config for MOVY deployment' tag:'M01'
|
||||
checkout TEST-env
|
||||
merge OPS id:'FLUX ready to deploy MOVY' type: HIGHLIGHT tag:'M02'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY' tag:'v1.0.3'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0.3' type: REVERSE
|
||||
|
||||
checkout OPS
|
||||
commit id:'Network policies'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT tag:'T07'
|
||||
|
||||
checkout OPS
|
||||
commit id:'k0s install on METAL cluster' tag:'K01'
|
||||
commit id:'Flux config. for METAL cluster' tag:'K02'
|
||||
branch METAL_TEST-PROD order:3
|
||||
commit id:'ROCKY/MOVY tenants on METAL' type: HIGHLIGHT
|
||||
checkout OPS
|
||||
commit id:'Flux config. for OpenEBS' tag:'K03'
|
||||
checkout METAL_TEST-PROD
|
||||
merge OPS id:'openEBS on METAL' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Prometheus install'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Kyverno install'
|
||||
commit id:'Kyverno rules'
|
||||
checkout TEST-env
|
||||
merge OPS type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for PROD tenant' tag:'P01'
|
||||
branch PROD-env order:2
|
||||
commit id:'ROCKY tenant on PROD'
|
||||
checkout OPS
|
||||
commit id:'ROCKY patch for PROD' tag:'R04'
|
||||
checkout PROD-env
|
||||
merge OPS id:'PROD ready to deploy ROCKY' type: HIGHLIGHT
|
||||
checkout PROD-env
|
||||
merge ROCKY tag:'ROCKY v1.0.2'
|
||||
|
||||
checkout MOVY
|
||||
commit id:'MOVY HELM chart' tag:'M03'
|
||||
checkout TEST-env
|
||||
merge MOVY tag:'MOVY v1.0'
|
||||
</pre>
|
||||
200
slides/flux/tenants.md
Normal file
200
slides/flux/tenants.md
Normal file
@@ -0,0 +1,200 @@
|
||||
# Multi-tenants management with Flux
|
||||
|
||||
💡 Thanks to `Flux`, we can manage Kubernetes resources from inside the clusters.
|
||||
|
||||
The **_⚙️OPS_** team uses `Flux` with a _GitOps_ code base to:
|
||||
- configure the clusters
|
||||
- deploy tools and components to extend the clusters capabilites
|
||||
- configure _GitOps_ workflow for dev teams in **dedicated and isolated _tenants_**
|
||||
|
||||
The **_🎸ROCKY_** team uses `Flux` to deploy every new release of its app, by detecting every new `git push` events happening in its app `Github` repository
|
||||
|
||||
|
||||
The **_🎬MOVY_** team uses `Flux` to deploy every new release of its app, packaged and published in a new `Helm` chart release
|
||||
|
||||
---
|
||||
|
||||
## Creating _tenants_ with Flux
|
||||
|
||||
While basic `Flux` behavior is to use a single configuration directory applied by a cluster-wide role…
|
||||
|
||||
… it can also enable _multi-tenant_ configuration by:
|
||||
- creating dedicated directories for each _tenant_ in its configuration code base
|
||||
- and using a dedicated `ServiceAccount` with limited permissions to operate in each _tenant_
|
||||
|
||||
Several _tenants_ are created
|
||||
- per env
|
||||
- for **_⚗️TEST_**
|
||||
- and **_🏭PROD_**
|
||||
- per team
|
||||
- for **_🎸ROCKY_**
|
||||
- and **_🎬MOVY_**
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Flux CLI works locally
|
||||
|
||||
First, we have to **locally** clone your `Flux` configuration `Github` repository
|
||||
|
||||
- create an ssh key pair
|
||||
- add the **public** key to your `Github` repository (**with write access**)
|
||||
- and git clone the repository
|
||||
|
||||
---
|
||||
|
||||
### The command line 1/2
|
||||
|
||||
Creating the **_⚗️TEST_** _tenant_
|
||||
|
||||
.lab[
|
||||
|
||||
- ⚠️ Think about renaming the repo with your own suffix
|
||||
```bash
|
||||
k8s@shpod:~$ cd fleet-config-using-flux-XXXXX/
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
flux create kustomization tenant-test \
|
||||
--namespace=flux-system \
|
||||
--source=GitRepository/flux-system \
|
||||
--path ./tenants/test \
|
||||
--interval=1m \
|
||||
--prune --export >> clusters/CLOUDY/tenants.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### The command line 2/2
|
||||
|
||||
Then we create the **_🏭PROD_** _tenant_
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ \
|
||||
flux create kustomization tenant-prod \
|
||||
--namespace=flux-system \
|
||||
--source=GitRepository/flux-system \
|
||||
--path ./tenants/prod \
|
||||
--interval=3m \
|
||||
--prune --export >> clusters/CLOUDY/tenants.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
### 📂 Flux tenants.yaml files
|
||||
|
||||
Let's review the `fleet-config-using-flux-XXXXX/clusters/CLOUDY/tenants.yaml` file
|
||||
|
||||
|
||||
|
||||
|
||||
⚠️ The last command we type in `Flux` _CLI_ creates the `YAML` manifest **locally**
|
||||
|
||||
> ☝🏻 Don't forget to `git commit` and `git push` to `Github`!
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
### Our 1st Flux error
|
||||
|
||||
.lab[
|
||||
|
||||
```bash
|
||||
k8s@shpod:~/fleet-config-using-flux-XXXXX$ flux get all
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
flux-system gitrepository/flux-system main@sha1:0466652e False
|
||||
True stored artifact for revision 'main@sha1:0466652e'
|
||||
|
||||
NAMESPACE NAME REVISION SUSPENDED
|
||||
READY MESSAGE
|
||||
kustomization/flux-system main@sha1:0466652e False True
|
||||
Applied revision: main@sha1:0466652e
|
||||
kustomization/tenant-prod False False
|
||||
kustomization path not found: stat /tmp/kustomization-417981261/tenants/prod: no such file or directory
|
||||
kustomization/tenant-test False False
|
||||
kustomization path not found: stat /tmp/kustomization-2532810750/tenants/test: no such file or directory
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
> Our configuration may be incomplete 😅
|
||||
|
||||
---
|
||||
|
||||
## Configuring Flux for the **_🎸ROCKY_** team
|
||||
|
||||
What the **_⚙️OPS_** team has to do:
|
||||
|
||||
- 🔧 Create a dedicated `rocky` _tenant_ for **_⚗️TEST_** and **_🏭PROD_** envs on the cluster
|
||||
|
||||
- 🔧 Create the `Flux` source pointing to the `Github` repository embedding the **_🎸ROCKY_** app source code
|
||||
|
||||
- 🔧 Add a `kustomize` _patch_ into the global `Flux` config to include this specific `Flux` config. dedicated to the deployment of the **_🎸ROCKY_** app
|
||||
|
||||
What the **_🎸ROCKY_** team has to do:
|
||||
|
||||
- 👨💻 Create the `kustomization.yaml` file in the **_🎸ROCKY_** app source code repository on `Github`
|
||||
|
||||
---
|
||||
|
||||
### 🗺️ Where are we in our scenario?
|
||||
|
||||
<pre class="mermaid">
|
||||
%%{init:
|
||||
{
|
||||
"theme": "default",
|
||||
"gitGraph": {
|
||||
"mainBranchName": "OPS",
|
||||
"mainBranchOrder": 0
|
||||
}
|
||||
}
|
||||
}%%
|
||||
gitGraph
|
||||
commit id:"0" tag:"start"
|
||||
branch ROCKY order:3
|
||||
branch MOVY order:4
|
||||
branch YouRHere order:5
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux install on CLOUDY cluster' tag:'T01'
|
||||
branch TEST-env order:1
|
||||
commit id:'FLUX install on TEST' tag:'T02' type: HIGHLIGHT
|
||||
|
||||
checkout OPS
|
||||
commit id:'Flux config. for TEST tenant' tag:'T03'
|
||||
commit id:'namespace isolation by RBAC'
|
||||
checkout TEST-env
|
||||
merge OPS id:'ROCKY tenant creation' tag:'T04'
|
||||
|
||||
checkout YouRHere
|
||||
commit id:'x'
|
||||
checkout OPS
|
||||
merge YouRHere id:'YOU ARE HERE'
|
||||
|
||||
checkout OPS
|
||||
commit id:'ROCKY deploy. config.' tag:'R01'
|
||||
|
||||
checkout TEST-env
|
||||
merge OPS id:'TEST ready to deploy ROCKY' type: HIGHLIGHT tag:'R02'
|
||||
|
||||
checkout ROCKY
|
||||
commit id:'ROCKY' tag:'v1.0.0'
|
||||
|
||||
checkout TEST-env
|
||||
merge ROCKY tag:'ROCKY v1.0.0'
|
||||
</pre>
|
||||
5
slides/images/admission-control-phases.svg
Normal file
5
slides/images/admission-control-phases.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 29 KiB |
BIN
slides/images/konnectivity.png
Normal file
BIN
slides/images/konnectivity.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 71 KiB |
@@ -54,10 +54,11 @@ content:
|
||||
- containers/Multi_Stage_Builds.md
|
||||
#- containers/Publishing_To_Docker_Hub.md
|
||||
- containers/Dockerfile_Tips.md
|
||||
- containers/Exercise_Dockerfile_Advanced.md
|
||||
- containers/Exercise_Dockerfile_Multistage.md
|
||||
#- containers/Docker_Machine.md
|
||||
#- containers/Advanced_Dockerfiles.md
|
||||
#- containers/Buildkit.md
|
||||
#- containers/Exercise_Dockerfile_Buildkit.md
|
||||
#- containers/Init_Systems.md
|
||||
#- containers/Application_Configuration.md
|
||||
#- containers/Logging.md
|
||||
@@ -65,6 +66,7 @@ content:
|
||||
#- containers/Copy_On_Write.md
|
||||
#- containers/Containers_From_Scratch.md
|
||||
#- containers/Container_Engines.md
|
||||
#- containers/Security.md
|
||||
#- containers/Pods_Anatomy.md
|
||||
#- containers/Ecosystem.md
|
||||
#- containers/Orchestration_Overview.md
|
||||
|
||||
@@ -40,7 +40,7 @@ content:
|
||||
- - containers/Multi_Stage_Builds.md
|
||||
- containers/Publishing_To_Docker_Hub.md
|
||||
- containers/Dockerfile_Tips.md
|
||||
- containers/Exercise_Dockerfile_Advanced.md
|
||||
- containers/Exercise_Dockerfile_Multistage.md
|
||||
- - containers/Naming_And_Inspecting.md
|
||||
- containers/Labels.md
|
||||
- containers/Getting_Inside.md
|
||||
@@ -58,13 +58,17 @@ content:
|
||||
- containers/Docker_Machine.md
|
||||
- - containers/Advanced_Dockerfiles.md
|
||||
- containers/Buildkit.md
|
||||
- containers/Exercise_Dockerfile_Buildkit.md
|
||||
- containers/Init_Systems.md
|
||||
- containers/Application_Configuration.md
|
||||
- containers/Logging.md
|
||||
- containers/Resource_Limits.md
|
||||
- - containers/Namespaces_Cgroups.md
|
||||
- containers/Copy_On_Write.md
|
||||
#- containers/Containers_From_Scratch.md
|
||||
- containers/Containers_From_Scratch.md
|
||||
- containers/Security.md
|
||||
- containers/Rootless_Networking.md
|
||||
- containers/Images_Deep_Dive.md
|
||||
- - containers/Container_Engines.md
|
||||
- containers/Pods_Anatomy.md
|
||||
- containers/Ecosystem.md
|
||||
|
||||
@@ -41,7 +41,7 @@ content:
|
||||
- containers/Dockerfile_Tips.md
|
||||
- containers/Multi_Stage_Builds.md
|
||||
- containers/Publishing_To_Docker_Hub.md
|
||||
- containers/Exercise_Dockerfile_Advanced.md
|
||||
- containers/Exercise_Dockerfile_Multistage.md
|
||||
-
|
||||
- containers/Naming_And_Inspecting.md
|
||||
- containers/Labels.md
|
||||
@@ -64,6 +64,7 @@ content:
|
||||
- containers/Init_Systems.md
|
||||
- containers/Advanced_Dockerfiles.md
|
||||
- containers/Buildkit.md
|
||||
- containers/Exercise_Dockerfile_Buildkit.md
|
||||
-
|
||||
- containers/Application_Configuration.md
|
||||
- containers/Logging.md
|
||||
@@ -77,5 +78,7 @@ content:
|
||||
#- containers/Namespaces_Cgroups.md
|
||||
#- containers/Copy_On_Write.md
|
||||
#- containers/Containers_From_Scratch.md
|
||||
#- containers/Rootless_Networking.md
|
||||
#- containers/Security.md
|
||||
#- containers/Pods_Anatomy.md
|
||||
#- containers/Ecosystem.md
|
||||
|
||||
@@ -32,7 +32,7 @@
|
||||
|
||||
- Problem mitigation
|
||||
|
||||
*block nodes with vulnerable kernels, inject log4j mitigations...*
|
||||
*block nodes with vulnerable kernels, inject log4j mitigations, rewrite images...*
|
||||
|
||||
- Extended validation for operators
|
||||
|
||||
@@ -583,19 +583,38 @@ Shell to the rescue!
|
||||
|
||||
---
|
||||
|
||||
## Coming soon...
|
||||
## Real world examples
|
||||
|
||||
- [kube-image-keeper][kuik] rewrites image references to use cached images
|
||||
|
||||
(e.g. `nginx` → `localhost:7439/nginx`)
|
||||
|
||||
- [Kyverno] implements very extensive policies
|
||||
|
||||
(validation, generation... it deserves a whole chapter on its own!)
|
||||
|
||||
[kuik]: https://github.com/enix/kube-image-keeper
|
||||
[kyverno]: https://kyverno.io/
|
||||
|
||||
---
|
||||
|
||||
## Alternatives
|
||||
|
||||
- Kubernetes Validating Admission Policies
|
||||
|
||||
- Integrated with the Kubernetes API server
|
||||
- Relatively recent (alpha: 1.26, beta: 1.28, GA: 1.30)
|
||||
|
||||
- Lets us define policies using [CEL (Common Expression Language)][cel-spec]
|
||||
- Declare validation rules with Common Expression Language ([CEL][cel-spec])
|
||||
|
||||
- Available in beta in Kubernetes 1.28 <!-- ##VERSION## -->
|
||||
- Validation is done entirely within the API server
|
||||
|
||||
- Check this [CNCF Blog Post][cncf-blog-vap] for more details
|
||||
(no external webhook = no latency, no deployment complexity...)
|
||||
|
||||
[cncf-blog-vap]: https://www.cncf.io/blog/2023/09/14/policy-management-in-kubernetes-is-changing/
|
||||
- Not as powerful as full-fledged webhook engines like Kyverno
|
||||
|
||||
(see e.g. [this page of the Kyverno doc][kyverno-vap] for a comparison)
|
||||
|
||||
[kyverno-vap]: https://kyverno.io/docs/policy-types/validating-policy/
|
||||
[cel-spec]: https://github.com/google/cel-spec
|
||||
|
||||
???
|
||||
|
||||
@@ -35,7 +35,7 @@
|
||||
|
||||
## The chain of handlers
|
||||
|
||||
- API requests go through a complex chain of filters ([src](https://github.com/kubernetes/apiserver/blob/release-1.19/pkg/server/config.go#L671))
|
||||
- API requests go through a complex chain of filters ([src](https://github.com/kubernetes/apiserver/blob/release-1.32/pkg/server/config.go#L1004))
|
||||
|
||||
(note when reading that code: requests start at the bottom and go up)
|
||||
|
||||
|
||||
@@ -183,49 +183,98 @@
|
||||
|
||||
- But we also need to specify:
|
||||
|
||||
- an environment variable to specify that we want etcdctl v3
|
||||
|
||||
- the address of the server to back up
|
||||
|
||||
- the path to the key, certificate, and CA certificate
|
||||
<br/>(if our etcd uses TLS certificates)
|
||||
|
||||
- an environment variable to specify that we want etcdctl v3
|
||||
<br/>(not necessary anymore with recent versions of etcd)
|
||||
|
||||
---
|
||||
|
||||
## Snapshotting etcd on kubeadm
|
||||
## Snapshotting etcd on kubeadm
|
||||
|
||||
- The following command will work on clusters deployed with kubeadm
|
||||
- Here is a strategy that works on clusters deployed with kubeadm
|
||||
|
||||
(and maybe others)
|
||||
|
||||
- It should be executed on a master node
|
||||
- We're going to:
|
||||
|
||||
```bash
|
||||
docker run --rm --net host -v $PWD:/vol \
|
||||
-v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd:ro \
|
||||
-e ETCDCTL_API=3 k8s.gcr.io/etcd:3.3.10 \
|
||||
etcdctl --endpoints=https://[127.0.0.1]:2379 \
|
||||
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
|
||||
--cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
|
||||
--key=/etc/kubernetes/pki/etcd/healthcheck-client.key \
|
||||
snapshot save /vol/snapshot
|
||||
```
|
||||
- identify a node running the control plane
|
||||
|
||||
- It will create a file named `snapshot` in the current directory
|
||||
- identify the etcd image
|
||||
|
||||
- execute `etcdctl snapshot` in a *debug container*
|
||||
|
||||
- transfer the resulting snapshot with another *debug container*
|
||||
|
||||
---
|
||||
|
||||
## How can we remember all these flags?
|
||||
## Finding an etcd node and image
|
||||
|
||||
- Older versions of kubeadm did add a healthcheck probe with all these flags
|
||||
These commands let us retrieve the node and image automatically.
|
||||
|
||||
- That healthcheck probe was calling `etcdctl` with all the right flags
|
||||
.lab[
|
||||
|
||||
- With recent versions of kubeadm, we're on our own!
|
||||
- Get the name of a control plane node:
|
||||
```bash
|
||||
NODE=$(kubectl get nodes \
|
||||
--selector=node-role.kubernetes.io/control-plane \
|
||||
-o jsonpath={.items[0].metadata.name})
|
||||
```
|
||||
|
||||
- Exercise: write the YAML for a batch job to perform the backup
|
||||
- Get the etcd image:
|
||||
```bash
|
||||
IMAGE=$(kubectl get pods --namespace kube-system etcd-$NODE \
|
||||
-o jsonpath={..containers[].image})
|
||||
```
|
||||
|
||||
(how will you access the key and certificate required to connect?)
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Making a snapshot
|
||||
|
||||
This relies on the fact that in a `node` debug pod:
|
||||
|
||||
- the host filesystem is mounted in `/host`,
|
||||
- the debug pod is using the host's network.
|
||||
|
||||
.lab[
|
||||
|
||||
- Execute `etcdctl` in a debug pod:
|
||||
```bash
|
||||
kubectl debug --attach --profile=general \
|
||||
node/$NODE --image $IMAGE -- \
|
||||
etcdctl --endpoints=https://[127.0.0.1]:2379 \
|
||||
--cacert=/host/etc/kubernetes/pki/etcd/ca.crt \
|
||||
--cert=/host/etc/kubernetes/pki/etcd/healthcheck-client.crt \
|
||||
--key=/host/etc/kubernetes/pki/etcd/healthcheck-client.key \
|
||||
snapshot save /host/tmp/snapshot
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Transfer the snapshot
|
||||
|
||||
We're going to use base64 encoding to ensure that the snapshot
|
||||
doesn't get corrupted in transit.
|
||||
|
||||
.lab[
|
||||
|
||||
- Retrieve the snapshot:
|
||||
```bash
|
||||
kubectl debug --attach --profile=general --quiet \
|
||||
node/$NODE --image $IMAGE -- \
|
||||
base64 /host/tmp/snapshot | base64 -d > snapshot
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
We can now work with the `snapshot` file in the current directory!
|
||||
|
||||
---
|
||||
|
||||
@@ -252,8 +301,7 @@ docker run --rm --net host -v $PWD:/vol \
|
||||
1. Create a new data directory from the snapshot:
|
||||
```bash
|
||||
sudo rm -rf /var/lib/etcd
|
||||
docker run --rm -v /var/lib:/var/lib -v $PWD:/vol \
|
||||
-e ETCDCTL_API=3 k8s.gcr.io/etcd:3.3.10 \
|
||||
docker run --rm -v /var/lib:/var/lib -v $PWD:/vol $IMAGE \
|
||||
etcdctl snapshot restore /vol/snapshot --data-dir=/var/lib/etcd
|
||||
```
|
||||
|
||||
@@ -281,6 +329,20 @@ docker run --rm --net host -v $PWD:/vol \
|
||||
|
||||
---
|
||||
|
||||
## Accessing etcd directly
|
||||
|
||||
- Data in etcd is encoded in a binary format
|
||||
|
||||
- We can retrieve the data with etcdctl, but it's hard to read
|
||||
|
||||
- There is a tool to decode that data: `auger`
|
||||
|
||||
- Check the [use cases][auger-use-cases] for an example of how to retrieve and modify etcd data!
|
||||
|
||||
[auger-use-cases]: https://github.com/etcd-io/auger?tab=readme-ov-file#use-cases
|
||||
|
||||
---
|
||||
|
||||
## More information about etcd backups
|
||||
|
||||
- [Kubernetes documentation](https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#built-in-snapshot) about etcd backups
|
||||
@@ -291,6 +353,8 @@ docker run --rm --net host -v $PWD:/vol \
|
||||
|
||||
- [Another good blog post by consol labs](https://labs.consol.de/kubernetes/2018/05/25/kubeadm-backup.html) on the same topic
|
||||
|
||||
- [auger](https://github.com/etcd-io/auger), a tool to directly access Kubernetes objects stored in etcd
|
||||
|
||||
---
|
||||
|
||||
## Don't forget ...
|
||||
@@ -346,19 +410,15 @@ docker run --rm --net host -v $PWD:/vol \
|
||||
|
||||
## More backup tools
|
||||
|
||||
- [Stash](https://appscode.com/products/stash/)
|
||||
- [Stash](https://stash.run/)
|
||||
|
||||
back up Kubernetes persistent volumes
|
||||
|
||||
- [ReShifter](https://github.com/mhausenblas/reshifter)
|
||||
|
||||
cluster state management
|
||||
|
||||
- ~~Heptio Ark~~ [Velero](https://github.com/heptio/velero)
|
||||
- ~~Heptio Ark~~ [Velero](https://velero.io/)
|
||||
|
||||
full cluster backup
|
||||
|
||||
- [kube-backup](https://github.com/pieterlange/kube-backup)
|
||||
- [kube-backup](https://github.com/pieterlange/kube-backup) (unmaintained)
|
||||
|
||||
simple scripts to save resource YAML to a git repository
|
||||
|
||||
@@ -366,6 +426,10 @@ docker run --rm --net host -v $PWD:/vol \
|
||||
|
||||
Backup Interface for Volumes Attached to Containers
|
||||
|
||||
- [Veeam Kasten](https://www.veeam.com/products/cloud/kubernetes-data-protection.html)
|
||||
|
||||
commercial product; compares to Velero
|
||||
|
||||
???
|
||||
|
||||
:EN:- Backing up clusters
|
||||
|
||||
@@ -18,7 +18,7 @@
|
||||
|
||||
- API backend
|
||||
|
||||
- database (that we will keep out of Kubernetes for now)
|
||||
- database
|
||||
|
||||
- We have built images for our frontend and backend components
|
||||
|
||||
@@ -33,7 +33,15 @@
|
||||
---
|
||||
|
||||
|
||||
## Basic things we can ask Kubernetes to do
|
||||
## Kubernetes, level 1
|
||||
|
||||
--
|
||||
|
||||
- Leave our database outside of Kubernetes (because database be scary🥺)
|
||||
|
||||
--
|
||||
|
||||
- Deploy a managed Kubernetes cluster (cloud or [professional services][enix-k8s-expert])
|
||||
|
||||
--
|
||||
|
||||
@@ -63,18 +71,24 @@
|
||||
|
||||
- Keep processing requests during the upgrade; update my containers one at a time
|
||||
|
||||
[enix-k8s-expert]: https://enix.io/en/kubernetes-expert/
|
||||
|
||||
---
|
||||
|
||||
## Other things that Kubernetes can do for us
|
||||
## Kubernetes, level 2
|
||||
|
||||
- Deploy a pre-production environment
|
||||
|
||||
(still using our external database, for now)
|
||||
|
||||
- Resource management and scheduling
|
||||
|
||||
(reserve CPU/RAM for containers; placement constraints; priorities)
|
||||
|
||||
- Autoscaling
|
||||
|
||||
(straightforward on CPU; more complex on other metrics)
|
||||
|
||||
- Resource management and scheduling
|
||||
|
||||
(reserve CPU/RAM for containers; placement constraints)
|
||||
|
||||
- Advanced rollout patterns
|
||||
|
||||
(blue/green deployment, canary deployment)
|
||||
@@ -95,24 +109,74 @@ class: pic
|
||||
|
||||
---
|
||||
|
||||
## More things that Kubernetes can do for us
|
||||
## Kubernetes, level 3
|
||||
|
||||
- Batch jobs
|
||||
- Run staging databases on the cluster
|
||||
|
||||
(one-off; parallel; also cron-style periodic execution)
|
||||
(no replication, no backups, no scaling)
|
||||
|
||||
- Automatic or semi-automatic deployment of feature branches
|
||||
|
||||
(each with its own database)
|
||||
|
||||
- Fine-grained access control
|
||||
|
||||
(defining *what* can be done by *whom* on *which* resources)
|
||||
|
||||
- Stateful services
|
||||
- Batch jobs
|
||||
|
||||
(one-off; parallel; also cron-style periodic execution)
|
||||
|
||||
- Package applications with e.g. Helm charts
|
||||
|
||||
---
|
||||
|
||||
## Kubernetes, level 4
|
||||
|
||||
- Stateful services with persistence, replication, backups
|
||||
|
||||
(databases, message queues, etc.)
|
||||
|
||||
- Automating complex tasks with *operators*
|
||||
- Automate complex tasks with *operators*
|
||||
|
||||
(e.g. database replication, failover, etc.)
|
||||
|
||||
- Combine the two previous points with database operators like [CloudNativePG][cnpg]
|
||||
|
||||
(learn more about database operators: [FR][pirates-video-fr], [EN][pirates-video-en])
|
||||
|
||||
- Leverage advanced storage with e.g. local ZFS volumes
|
||||
|
||||
(learn more about ZFS and databases on k8s: [FR][zfs-video-fr], [EN][zfs-video-en])
|
||||
|
||||
- Deploy and manage clusters in-house
|
||||
|
||||
[cnpg]: https://cloudnative-pg.io/
|
||||
[pirates-video-fr]: https://www.youtube.com/watch?v=d_ka7PlWo1I
|
||||
[pirates-video-en]: https://www.youtube.com/watch?v=ojUdBjbiKWk&t=5s
|
||||
[zfs-video-fr]: https://www.youtube.com/watch?v=XN9YL93f8tI
|
||||
[zfs-video-en]: https://www.youtube.com/watch?v=3sJIYiDnod4
|
||||
|
||||
---
|
||||
|
||||
## Kubernetes, level 5
|
||||
|
||||
- Deploying and managing clusters at scale
|
||||
|
||||
(hundreds of clusters, thousands of nodes...)
|
||||
|
||||
- Writing custom operators
|
||||
|
||||
- Hybrid deployments
|
||||
|
||||
---
|
||||
|
||||
## Disclaimer
|
||||
|
||||
The levels mentioned in the previous slides are not necessarily linear.
|
||||
|
||||
They aren't exhaustive either (we didn't mention e.g. observability and alerting).
|
||||
|
||||
---
|
||||
|
||||
## Kubernetes architecture
|
||||
@@ -406,7 +470,7 @@ class: pic
|
||||
- all the NGINX containers would be on the same node
|
||||
|
||||
- they would all have the same IP address
|
||||
<br/>(resulting in `Address alreading in use` errors)
|
||||
<br/>(resulting in `Address already in use` errors)
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -22,11 +22,13 @@
|
||||
|
||||
## Authentication and authorization
|
||||
|
||||
- Authentication (checking "who you are") is done with mutual TLS
|
||||
- Authentication (checking "who you are") can be done in different ways:
|
||||
|
||||
(both the client and the server need to hold a valid certificate)
|
||||
- with mutual TLS (both client and server need to hold a valid certificate)
|
||||
|
||||
- Authorization (checking "what you can do") is done in different ways
|
||||
- with service account tokens (issued by the Kubernetes API server)
|
||||
|
||||
- Authorization (checking "what you can do") can also be done in multiple ways:
|
||||
|
||||
- the API server implements a sophisticated permission logic (with RBAC)
|
||||
|
||||
@@ -34,6 +36,30 @@
|
||||
|
||||
- some services require a certificate signed by a particular CA / sub-CA
|
||||
|
||||
- there is also a special "Node Authorizer" (for kubelet API access)
|
||||
|
||||
---
|
||||
|
||||
## Mutual TLS vs tokens
|
||||
|
||||
- Service account tokens:
|
||||
|
||||
- automatically generated by API server
|
||||
|
||||
- can be exposed to pods through e.g. volume mounts
|
||||
|
||||
- require the control plane to be up and running
|
||||
|
||||
- can't be used by kubelets or by static pods
|
||||
|
||||
- Mutual TLS:
|
||||
|
||||
- requires manual generation (and renewal!)
|
||||
|
||||
- doesn't require the control plane to be up and running
|
||||
|
||||
- particularly relevant for kubelets and static pods
|
||||
|
||||
---
|
||||
|
||||
## In practice
|
||||
@@ -114,22 +140,17 @@
|
||||
|
||||
---
|
||||
|
||||
## API server authentication with TLS certificates
|
||||
|
||||
## API server clients
|
||||
- Some control plane components will authenticate with TLS certificates
|
||||
|
||||
- The API server has a sophisticated authentication and authorization system
|
||||
|
||||
- For connections coming from other components of the control plane:
|
||||
|
||||
- authentication uses certificates (trusting the certificates' subject or CN)
|
||||
|
||||
- authorization uses whatever mechanism is enabled (most oftentimes, RBAC)
|
||||
(typically: scheduler, controller manager; also: kubelets!)
|
||||
|
||||
- The relevant API server flags are:
|
||||
|
||||
`--client-ca-file`, `--tls-cert-file`, `--tls-private-key-file`
|
||||
|
||||
- Each component connecting to the API server takes a `--kubeconfig` flag
|
||||
- These clients will typically accept a `--kubeconfig` flag
|
||||
|
||||
(to specify a kubeconfig file containing the CA cert, client key, and client cert)
|
||||
|
||||
@@ -137,6 +158,84 @@
|
||||
|
||||
---
|
||||
|
||||
## API server authentication with tokens
|
||||
|
||||
- Some control plane components may authenticate with Service Account tokens
|
||||
|
||||
(typically: controllers like CNI, CSI, Ingress...)
|
||||
|
||||
- The relevant API server flags are:
|
||||
|
||||
`--service-account-signing-key-file`, `--service-account-issuer`, `--service-account-key-file`
|
||||
|
||||
- These clients will automatically detect that they should use "in cluster config"
|
||||
|
||||
- That detection relies on the following things to exist:
|
||||
|
||||
- environment variables `KUBERNETES_SERVICE_HOST` and `KUBERNETES_SERVICE_PORT`
|
||||
|
||||
- token in file `/var/run/secrets/kubernetes.io/serviceaccount/token`
|
||||
|
||||
---
|
||||
|
||||
## API server clients authorization
|
||||
|
||||
- Most clients will rely on the `RBAC` authorizer
|
||||
|
||||
- enabled with API server flag `--authorization-mode=RBAC`
|
||||
|
||||
- that flag will automatically create a bunch of roles and bindings
|
||||
|
||||
- clients should use standard names (e.g. `system:kube-scheduler`)
|
||||
|
||||
- Kubelets will rely on the `Node` authorizer
|
||||
|
||||
- enabled with API server flag `--authorization-mode=Node`
|
||||
|
||||
- this authorizer makes sure that kubelets work on a "need-to-know" basis
|
||||
|
||||
- kubelets should use standard names (`system:node:<name-of-the-node>`)
|
||||
|
||||
- Note: to enable both authorizers, use `--authorization-mode=RBAC,Node`
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## How are these permissions set up?
|
||||
|
||||
- A bunch of roles and bindings are defined as constants in the API server code:
|
||||
|
||||
[auth/authorizer/rbac/bootstrappolicy/policy.go](https://github.com/kubernetes/kubernetes/blob/release-1.19/plugin/pkg/auth/authorizer/rbac/bootstrappolicy/policy.go#L188)
|
||||
|
||||
- They are created automatically when the API server starts:
|
||||
|
||||
[registry/rbac/rest/storage_rbac.go](https://github.com/kubernetes/kubernetes/blob/release-1.19/pkg/registry/rbac/rest/storage_rbac.go#L140)
|
||||
|
||||
- We must use the correct Common Names (`CN`) for the control plane certificates
|
||||
|
||||
(since the bindings defined above refer to these common names)
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## The Node Authorizer
|
||||
|
||||
- Question: when should node `X` be able to access secret `Y`?
|
||||
|
||||
--
|
||||
|
||||
- Answer: if, and only if, node `X` runs a pod that uses secret `Y`
|
||||
|
||||
- The Node Authorizer implements that kind of logic
|
||||
|
||||
- It also allows kubelets to set labels and taints for themselves
|
||||
|
||||
(but not for other nodes)
|
||||
|
||||
---
|
||||
|
||||
## Kubelet and API server
|
||||
|
||||
- Communication between kubelet and API server can be established both ways
|
||||
@@ -167,6 +266,12 @@
|
||||
|
||||
(it will authenticate like any other client)
|
||||
|
||||
- Authorization will typically require the Node Authorizer mentioned earlier
|
||||
|
||||
⚠️ Kubelet certificates need to be renewed regularly!
|
||||
|
||||
- This is typically done through the CSR API
|
||||
|
||||
---
|
||||
|
||||
## API server → kubelet
|
||||
@@ -203,37 +308,31 @@
|
||||
|
||||
- Its certificate will have `CN=system:kube-controller-manager`
|
||||
|
||||
- To improve security posture, each controller can use an individual Service Account
|
||||
|
||||
- This is enabled with flag `--use-service-account-credentials=true`
|
||||
|
||||
---
|
||||
|
||||
## Controller manager keys
|
||||
|
||||
- The controller can create Secrets holding Service Account tokens
|
||||
|
||||
- this is enabled with flag `--service-account-private-key-file`
|
||||
|
||||
- this was used in older versions of Kubernetes (before *bound tokens*)
|
||||
|
||||
- in modern clusters, kubelet uses the `TokenRequest` API instead
|
||||
|
||||
- If we use the CSR API, the controller manager needs the CA cert and key
|
||||
|
||||
(passed with flags `--cluster-signing-cert-file` and `--cluster-signing-key-file`)
|
||||
- the CSR API is used in many clusters to renew kubelet certificates
|
||||
|
||||
- We usually want the controller manager to generate tokens for service accounts
|
||||
|
||||
- These tokens deserve some details (on the next slide!)
|
||||
- it's enabled with `--cluster-signing-cert-file` and `--cluster-signing-key-file`
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## How are these permissions set up?
|
||||
|
||||
- A bunch of roles and bindings are defined as constants in the API server code:
|
||||
|
||||
[auth/authorizer/rbac/bootstrappolicy/policy.go](https://github.com/kubernetes/kubernetes/blob/release-1.19/plugin/pkg/auth/authorizer/rbac/bootstrappolicy/policy.go#L188)
|
||||
|
||||
- They are created automatically when the API server starts:
|
||||
|
||||
[registry/rbac/rest/storage_rbac.go](https://github.com/kubernetes/kubernetes/blob/release-1.19/pkg/registry/rbac/rest/storage_rbac.go#L140)
|
||||
|
||||
- We must use the correct Common Names (`CN`) for the control plane certificates
|
||||
|
||||
(since the bindings defined above refer to these common names)
|
||||
|
||||
---
|
||||
|
||||
## Service account tokens
|
||||
|
||||
- Each time we create a service account, the controller manager generates a token
|
||||
## Service account tokens recap
|
||||
|
||||
- These tokens are JWT tokens, signed with a particular key
|
||||
|
||||
@@ -241,13 +340,14 @@ class: extra-details
|
||||
|
||||
(and therefore, the API server needs to be able to verify their integrity)
|
||||
|
||||
- This uses another keypair:
|
||||
- That key is passed to the API server using a couple of flags:
|
||||
|
||||
- the private key (used for signature) is passed to the controller manager
|
||||
<br/>(using flags `--service-account-private-key-file` and `--root-ca-file`)
|
||||
- `--service-account-private-key-file` (used to issue tokens)
|
||||
|
||||
- the public key (used for verification) is passed to the API server
|
||||
<br/>(using flag `--service-account-key-file`)
|
||||
- `--service-account-key-file` (used to verify tokens)
|
||||
|
||||
- The private key is also passed to the controller manager
|
||||
<br/>(using flag `--service-account-private-key-file`)
|
||||
|
||||
---
|
||||
|
||||
@@ -261,8 +361,14 @@ class: extra-details
|
||||
|
||||
- It will authenticate using the token of that Service Account
|
||||
|
||||
- It's also possible (but rare) to run it with e.g. static pods
|
||||
|
||||
(it will then require TLS keys; possibly the same as kubelet's!)
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Webhooks
|
||||
|
||||
- We mentioned webhooks earlier; how does that really work?
|
||||
@@ -283,6 +389,8 @@ class: extra-details
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Subject Access Review
|
||||
|
||||
Here is an example showing how to check if `jean.doe` can `get` some `pods` in `kube-system`:
|
||||
|
||||
@@ -6,7 +6,7 @@ We are going to cover:
|
||||
|
||||
- Controllers
|
||||
|
||||
- Dynamic Admission Webhooks
|
||||
- Admission Control
|
||||
|
||||
- Custom Resource Definitions (CRDs)
|
||||
|
||||
@@ -128,23 +128,38 @@ then make or request changes where needed.*
|
||||
|
||||
---
|
||||
|
||||
## Admission controllers
|
||||
## Admission control
|
||||
|
||||
- Admission controllers can vet or transform API requests
|
||||
- Validate (approve/deny) or mutate (modify) API requests
|
||||
|
||||
- The diagram on the next slide shows the path of an API request
|
||||
- In modern Kubernetes, we have at least 3 ways to achieve that:
|
||||
|
||||
(courtesy of Banzai Cloud)
|
||||
- [admission controllers][ac-controllers] (built in the API server)
|
||||
|
||||
- [dynamic admission control][ac-webhooks] (with webhooks)
|
||||
|
||||
- [validating admission policies][ac-vap] (using CEL, Common Expression Language)
|
||||
|
||||
- More is coming; e.g. [mutating admission policies][ac-map]
|
||||
|
||||
(alpha in Kubernetes 1.32, beta in Kubernetes 1.34)
|
||||
|
||||
[ac-controllers]: https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/
|
||||
[ac-webhooks]: https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/
|
||||
[ac-vap]: https://kubernetes.io/docs/reference/access-authn-authz/validating-admission-policy/
|
||||
[ac-map]: https://kubernetes.io/docs/reference/access-authn-authz/mutating-admission-policy/
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||

|
||||
|
||||
---
|
||||
|
||||
## Types of admission controllers
|
||||
## Admission controllers
|
||||
|
||||
- Built in the API server
|
||||
|
||||
- *Validating* admission controllers can accept/reject the API call
|
||||
|
||||
@@ -156,9 +171,13 @@ class: pic
|
||||
|
||||
- There are a number of built-in admission controllers
|
||||
|
||||
(see [documentation](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#what-does-each-admission-controller-do) for a list)
|
||||
([and a bunch of them are enabled by default][ac-default])
|
||||
|
||||
- We can also dynamically define and register our own
|
||||
- They can be enabled/disabled with API server command-line flags
|
||||
|
||||
(this is not always possible when using *managed* Kubernetes!)
|
||||
|
||||
[ac-default]: https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#which-plugins-are-enabled-by-default
|
||||
|
||||
---
|
||||
|
||||
@@ -202,6 +221,8 @@ class: extra-details
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Webhook Configuration
|
||||
|
||||
- A ValidatingWebhookConfiguration or MutatingWebhookConfiguration contains:
|
||||
@@ -229,15 +250,39 @@ class: extra-details
|
||||
|
||||
- Sidecar injection
|
||||
|
||||
(Used by some service meshes)
|
||||
(used by some service meshes)
|
||||
|
||||
- Type validation
|
||||
|
||||
(More on this later, in the CRD section)
|
||||
(more on this later, in the CRD section)
|
||||
|
||||
- And many other creative + useful scenarios!
|
||||
|
||||
(for example in [kube-image-keeper][kuik], to rewrite image references)
|
||||
|
||||
[kuik]: https://github.com/enix/kube-image-keeper
|
||||
|
||||
---
|
||||
|
||||
## Kubernetes API types
|
||||
## Validating Admission Policies
|
||||
|
||||
- Relatively recent (alpha: 1.26, beta: 1.28, GA: 1.30)
|
||||
|
||||
- Declare validation rules with Common Expression Language (CEL)
|
||||
|
||||
- Validation is done entirely within the API server
|
||||
|
||||
(no external webhook = no latency, no deployment complexity...)
|
||||
|
||||
- Not as powerful as full-fledged webhook engines like Kyverno
|
||||
|
||||
(see e.g. [this page of the Kyverno doc][kyverno-vap] for a comparison)
|
||||
|
||||
[kyverno-vap]: https://kyverno.io/docs/policy-types/validating-policy/
|
||||
|
||||
---
|
||||
|
||||
## Kubernetes API resource types
|
||||
|
||||
- Almost everything in Kubernetes is materialized by a resource
|
||||
|
||||
@@ -271,21 +316,21 @@ class: extra-details
|
||||
|
||||
## Examples
|
||||
|
||||
- Representing configuration for controllers and operators
|
||||
|
||||
(e.g. Prometheus scrape targets, gitops configuration, certificates...)
|
||||
|
||||
- Representing composite resources
|
||||
|
||||
(e.g. clusters like databases, messages queues ...)
|
||||
(e.g. database cluster, message queue...)
|
||||
|
||||
- Representing external resources
|
||||
|
||||
(e.g. virtual machines, object store buckets, domain names ...)
|
||||
|
||||
- Representing configuration for controllers and operators
|
||||
|
||||
(e.g. custom Ingress resources, certificate issuers, backups ...)
|
||||
(e.g. virtual machines, object store buckets, domain names...)
|
||||
|
||||
- Alternate representations of other objects; services and service instances
|
||||
|
||||
(e.g. encrypted secret, git endpoints ...)
|
||||
(e.g. encrypted secret, git endpoints...)
|
||||
|
||||
---
|
||||
|
||||
@@ -339,17 +384,18 @@ class: extra-details
|
||||
|
||||
---
|
||||
|
||||
## Documentation
|
||||
## And more...
|
||||
|
||||
- [Custom Resource Definitions: when to use them](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/)
|
||||
- Some specifics areas of Kubernetes also have extension points
|
||||
|
||||
- [Custom Resources Definitions: how to use them](https://kubernetes.io/docs/tasks/access-kubernetes-api/custom-resources/custom-resource-definitions/)
|
||||
- Example: scheduler
|
||||
|
||||
- [Built-in Admission Controllers](https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/)
|
||||
- it's possible to [customize the behavior of the scheduler][sched-config]
|
||||
|
||||
- [Dynamic Admission Controllers](https://kubernetes.io/docs/reference/access-authn-authz/extensible-admission-controllers/)
|
||||
- or even run [multiple schedulers][sched-multiple]
|
||||
|
||||
- [Aggregation Layer](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/apiserver-aggregation/)
|
||||
[sched-config]: https://kubernetes.io/docs/reference/scheduling/config/
|
||||
[sched-multiple]: https://kubernetes.io/docs/tasks/extend-kubernetes/configure-multiple-schedulers/
|
||||
|
||||
???
|
||||
|
||||
|
||||
523
slides/k8s/gateway-api.md
Normal file
523
slides/k8s/gateway-api.md
Normal file
@@ -0,0 +1,523 @@
|
||||
# The Gateway API
|
||||
|
||||
- Over time, Kubernetes has introduced multiple ways to expose containers
|
||||
|
||||
- In the first versions of Kubernetes, we would use a `Service` of type `LoadBalancer`
|
||||
|
||||
- HTTP services often need extra features, though:
|
||||
|
||||
- content-based routing (route requests with URI, HTTP headers...)
|
||||
|
||||
- TLS termination
|
||||
|
||||
- middlewares (e.g. authentication)
|
||||
|
||||
- etc.
|
||||
|
||||
- This led to the introduction of the `Ingress` resource
|
||||
|
||||
---
|
||||
|
||||
## History of Ingress
|
||||
|
||||
- Kubernetes 1.8 (September 2017) introduced `Ingress` (v1beta1)
|
||||
|
||||
- Kubernetes 1.19 (August 2020) graduated `Ingress` to GA (v1)
|
||||
|
||||
- Ingress supports:
|
||||
|
||||
- content-based routing with URI or HTTP `Host:` header
|
||||
|
||||
- TLS termination (with neat integration with e.g. cert-manager)
|
||||
|
||||
- Ingress doesn't support:
|
||||
|
||||
- content-based routing with other headers (e.g. cookies)
|
||||
|
||||
- middlewares
|
||||
|
||||
- traffic split for e.g. canary deployments
|
||||
|
||||
---
|
||||
|
||||
## Everyone needed something better
|
||||
|
||||
- Virtually *every* ingress controller added proprietary extensions:
|
||||
|
||||
- `nginx.ingress.kubernetes.io/configuration-snippet` annotation
|
||||
|
||||
- Traefik has CRDs like `IngressRoute`, `TraefikService`, `Middleware`...
|
||||
|
||||
- HAProxy has CRDs like `Backend`, `TCP`...
|
||||
|
||||
- etc.
|
||||
|
||||
- Ingress was too specific to L7 (HTTP) traffic
|
||||
|
||||
- We needed a totally new set of APIs and resources!
|
||||
|
||||
---
|
||||
|
||||
## Gateway API in a nutshell
|
||||
|
||||
- Handle HTTP, GRPC, TCP, TLS, UDP routes
|
||||
|
||||
(note: as of October 2025, only HTTP and GRPC routes are in GA)
|
||||
|
||||
- Finer-grained permission model
|
||||
|
||||
(e.g. define which namespaces can use a specific "gateway"; more on that later)
|
||||
|
||||
- Standardize more "core" features than Ingress
|
||||
|
||||
(header-based routing, traffic weighing, rewrite requests and responses...)
|
||||
|
||||
- Pave the way for further extension thanks to different feature sets
|
||||
|
||||
(`Core` vs `Extended` vs `Implementation-specific`)
|
||||
|
||||
- Can also be used for service meshes
|
||||
|
||||
---
|
||||
|
||||
## Gateway API personas
|
||||
|
||||
- Ingress informally had two personas:
|
||||
|
||||
- cluster administrator (installs and manages the Ingress Controller)
|
||||
|
||||
- application developer (creates Ingress resources)
|
||||
|
||||
- Gateway [formally defines three personas][gateway-personas]:
|
||||
|
||||
- infrastructure provider
|
||||
<br/>
|
||||
(~network admin; potentially works within managed providers)
|
||||
|
||||
- cluster operator
|
||||
<br/>
|
||||
(~Kubernetes admin; potentially manages multiple clusters)
|
||||
|
||||
- application developer
|
||||
|
||||
[gateway-personas]: https://gateway-api.sigs.k8s.io/concepts/roles-and-personas/
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||
## Gateway API resources
|
||||
|
||||
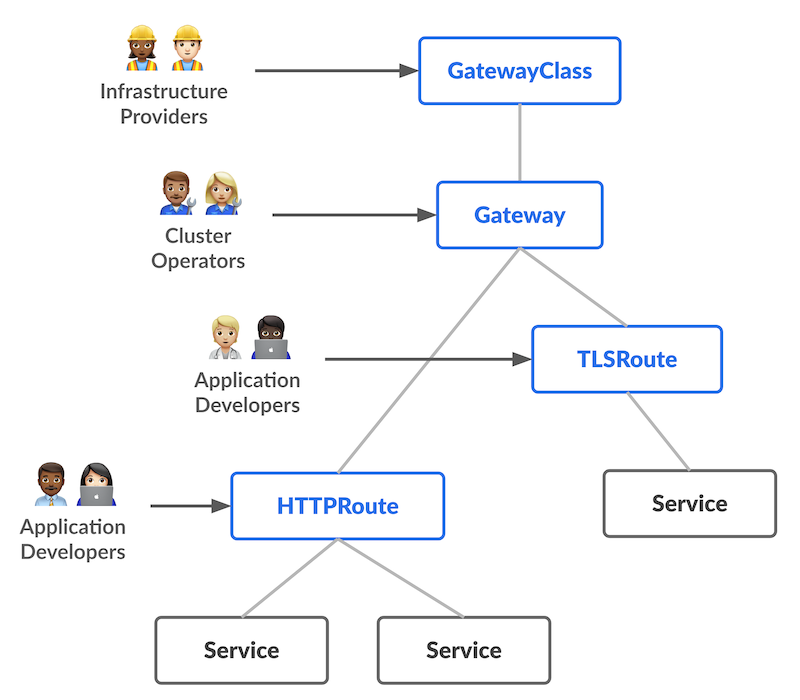
|
||||
|
||||
---
|
||||
|
||||
## Gateway API resources
|
||||
|
||||
- `Service` = our good old Kubernetes service
|
||||
|
||||
- `HTTPRoute` = describes which requests should go to which `Service`
|
||||
|
||||
(similar to the `Ingress` resource)
|
||||
|
||||
- `Gateway` = how traffic enters the system
|
||||
|
||||
(could correspond to e.g. a `LoadBalancer` `Service`)
|
||||
|
||||
- `GatewayClass` = represents different types of `Gateways`
|
||||
|
||||
(many gateway controllers will offer only one)
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute` anatomy
|
||||
|
||||
- `spec.parentRefs` = where requests come from
|
||||
|
||||
- typically a single `Gateway`
|
||||
|
||||
- could be multiple `Gateway` resources
|
||||
|
||||
- can also be a `Service` (for cluster mesh uses)
|
||||
|
||||
- `spec.hostnames` = which hosts (HTTP `Host:` header) this applies to
|
||||
|
||||
- `spec.rules[].matches` = which requests this applies to (match paths, headers...)
|
||||
|
||||
- `spec.rules[].filters` = optional transformations (change headers, rewrite URI...)
|
||||
|
||||
- `spec.rules[].backendRefs` = where requests go to
|
||||
|
||||
---
|
||||
|
||||
## Minimal `HTTPRoute`
|
||||
|
||||
```yaml
|
||||
apiVersion: gateway.networking.k8s.io/v1
|
||||
kind: HTTPRoute
|
||||
metadata:
|
||||
name: xyz
|
||||
spec:
|
||||
parentRefs:
|
||||
- group: gateway.networking.k8s.io
|
||||
kind: Gateway
|
||||
name: my-gateway
|
||||
namespace: my-gateway-namespace
|
||||
hostnames: [ xyz.example.com ]
|
||||
rules:
|
||||
- backendRefs:
|
||||
- name: xyz
|
||||
port: 80
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Gateway API in action
|
||||
|
||||
- Let's deploy Traefik in Gateway API mode!
|
||||
|
||||
- We'll use the [official Helm chart for Traefik][traefik-chart]
|
||||
|
||||
- We'll need to set a few values
|
||||
|
||||
- `providers.kubernetesGateway.enabled=true`
|
||||
|
||||
*enable Gateway API provisioning*
|
||||
|
||||
- `gateway.listeners.web.namespacePolicy.from=All`
|
||||
|
||||
*allow `HTTPRoutes` in all namespaces to refer to the default `Gateway`*
|
||||
|
||||
[traefik-chart]: https://artifacthub.io/packages/helm/traefik/traefik
|
||||
|
||||
---
|
||||
|
||||
## `LoadBalancer` vs `hostPort`
|
||||
|
||||
- If we're using a managed Kubernetes cluster, we'll use the default mode:
|
||||
|
||||
- Traefik runs with a `Deployment`
|
||||
|
||||
- Traefik `Service` has type `LoadBalancer`
|
||||
|
||||
- we connect to the `LoadBalancer` public IP address
|
||||
|
||||
- If we don't have a CCM (or `LoadBalancer` `Service`), we'll do things differently:
|
||||
|
||||
- Traefik runs with a `DaemonSet`
|
||||
|
||||
- Traefik `Service` has type `ClusterIP` (not strictly necessary but cleaner)
|
||||
|
||||
- we connect to any node's public IP address
|
||||
|
||||
---
|
||||
|
||||
## Installing Traefik (with `LoadBalancer`)
|
||||
|
||||
Install the Helm chart:
|
||||
```bash
|
||||
helm upgrade --install --namespace traefik --create-namespace \
|
||||
--repo https://traefik.github.io/charts traefik traefik \
|
||||
--version 37.1.2 \
|
||||
--set providers.kubernetesGateway.enabled=true \
|
||||
--set gateway.listeners.web.namespacePolicy.from=All \
|
||||
#
|
||||
```
|
||||
|
||||
We'll connect by using the public IP address of the load balancer:
|
||||
```bash
|
||||
kubectl get services --namespace traefik
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Installing Traefik (with `hostPort`)
|
||||
|
||||
Install the Helm chart:
|
||||
```bash
|
||||
helm upgrade --install --namespace traefik --create-namespace \
|
||||
--repo https://traefik.github.io/charts traefik traefik \
|
||||
--version 37.1.2 \
|
||||
--set deployment.kind=DaemonSet \
|
||||
--set ports.web.hostPort=80 \
|
||||
--set ports.websecure.hostPort=443 \
|
||||
--set service.type=ClusterIP \
|
||||
--set providers.kubernetesGateway.enabled=true \
|
||||
--set gateway.listeners.web.namespacePolicy.from=All \
|
||||
#
|
||||
```
|
||||
|
||||
We'll connect by using the public IP address of any node of the cluster.
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Taints and tolerations
|
||||
|
||||
- By default, Traefik Pods will respect node taints
|
||||
|
||||
- If some nodes have taints (e.g. control plane nodes) we might need tolerations
|
||||
|
||||
(if we want to run Traefik on all nodes)
|
||||
|
||||
- Adding the corresponding tolerations is left as an exercise for the reader!
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Rolling updates with `hostPort`
|
||||
|
||||
- It is not possible to have two pods on the same node using the same `hostPort`
|
||||
|
||||
- Therefore, it is important to pay attention to the `DaemonSet` rolling update parameters
|
||||
|
||||
- If `maxUnavailable` is non-zero:
|
||||
|
||||
- old pods will be shutdown first
|
||||
|
||||
- new pods will start without a problem
|
||||
|
||||
- there will be a short interruption of service
|
||||
|
||||
- If `maxSurge` is non-zero:
|
||||
|
||||
- new pods will be created but won't be able to start (since the `hostPort` is taken)
|
||||
|
||||
- old pods will remain running and the rolling update will not proceed
|
||||
|
||||
---
|
||||
|
||||
## Testing our Gateway controller
|
||||
|
||||
- Send a test request to Traefik
|
||||
|
||||
(e.g. with `curl http://<ipaddress>`)
|
||||
|
||||
- For now we should get a `404 not found`
|
||||
|
||||
(as there are no routes configured)
|
||||
|
||||
---
|
||||
|
||||
## A basic HTTP route
|
||||
|
||||
- Create a basic HTTP container and expose it with a Service; e.g.:
|
||||
```bash
|
||||
kubectl create deployment blue --image jpetazzo/color --port 80
|
||||
kubectl expose deployment blue
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## A basic HTTP route
|
||||
|
||||
- Create an `HTTPRoute` with the following YAML:
|
||||
```yaml
|
||||
apiVersion: gateway.networking.k8s.io/v1
|
||||
kind: HTTPRoute
|
||||
metadata:
|
||||
name: blue
|
||||
spec:
|
||||
parentRefs:
|
||||
- group: gateway.networking.k8s.io
|
||||
kind: Gateway
|
||||
name: traefik-gateway
|
||||
namespace: traefik
|
||||
rules:
|
||||
- backendRefs:
|
||||
- name: blue
|
||||
port: 80
|
||||
```
|
||||
|
||||
- Our `curl` command should now show a response from the `blue` pod
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Traefik dashboard
|
||||
|
||||
- By default, Traefik exposes a dashboard
|
||||
|
||||
(on a different port than the one used for "normal" traffic)
|
||||
|
||||
- To access it:
|
||||
```bash
|
||||
kubectl port-forward --namespace traefik daemonset/traefik 1234:8080
|
||||
```
|
||||
|
||||
(replace `daemonset` with `deployment` if necessary)
|
||||
|
||||
|
||||
- Then connect to http://localhost:1234/dashboard/ (pay attention to the final `/`!)
|
||||
|
||||
---
|
||||
|
||||
## `Core` vs `Extended` vs `Implementation-specific`
|
||||
|
||||
- All Gateway controllers must support `Core` features
|
||||
|
||||
- Some optional features are in the `Extended` set:
|
||||
|
||||
- they may or may not supported
|
||||
|
||||
- but at least, their specification is part of the API definition
|
||||
|
||||
- Gateway controllers can also have `Implementation-specific` features
|
||||
|
||||
(=proprietary extensions)
|
||||
|
||||
- In the following slides, we'll tag features with `Core` or `Extended`
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute.spec.rules[].matches`
|
||||
|
||||
Some fields are part of the `Core` set; some are part of the `Extended` set.
|
||||
|
||||
```yaml
|
||||
match:
|
||||
path: # Core
|
||||
value: /hello
|
||||
type: PathPrefix # default value; can also be "Exact"
|
||||
headers: # Core
|
||||
- name: x-custom-header
|
||||
value: foo
|
||||
queryparams: # Extended
|
||||
- type: Exact # can also have implementation-specific values, e.g. Regex
|
||||
name: product
|
||||
value: pizza
|
||||
method: GET # Extended
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute.spec.rules[].filters.*HeaderModifier`
|
||||
|
||||
`RequestHeaderModifier` is `Core`
|
||||
|
||||
`ResponseHeaderModifier` is `Extended`
|
||||
|
||||
```yaml
|
||||
type: RequestHeaderModifier # or ResponseHeaderModifier
|
||||
requestHeaderModifier: # or responseHeaderModifier
|
||||
set: # replace an existing header
|
||||
- name: x-my-header
|
||||
value: hello
|
||||
add: # appends to an existing header
|
||||
- name: x-my-header # (adding a comma if it's already set)
|
||||
value: hello
|
||||
remove:
|
||||
- x-my-header
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute.spec.rules[].filters.RequestRedirect`
|
||||
|
||||
```yaml
|
||||
type: RequestRedirect
|
||||
requestRedirect:
|
||||
scheme: https # http or https
|
||||
hostname: newxyz.example.com
|
||||
path: /new
|
||||
port: 8080
|
||||
statusCode: 302 # default=302; can be 301 302 303 307 308
|
||||
```
|
||||
|
||||
All fields are optional. Empty fields mean "leave as is".
|
||||
|
||||
Note that while `RequestRedirect` is `Core`, some options are `Extended`!
|
||||
|
||||
(See the [API specification for details][http-request-redirect].)
|
||||
|
||||
[http-request-redirect]: https://gateway-api.sigs.k8s.io/reference/spec/#httprequestredirectfilter
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute.spec.rules[].filters.URLRewrite`
|
||||
|
||||
```yaml
|
||||
type: URLRewrite
|
||||
urlRewrite:
|
||||
hostname: newxyz.example.com
|
||||
path: /new
|
||||
```
|
||||
|
||||
`hostname` will rewrite the HTTP `Host:` header.
|
||||
|
||||
This is an `Extended` feature.
|
||||
|
||||
It conflicts with `HTTPRequestRedirect`.
|
||||
|
||||
---
|
||||
|
||||
## `HTTPRoute.spec.rules[].filters.RequestMirror`
|
||||
|
||||
This is an `Extended` feature. It sends a copy of all (or a fraction) of requests to another backend. Responses from the mirrored backend are ignored.
|
||||
|
||||
```yaml
|
||||
type: RequestMirror
|
||||
requestMirror:
|
||||
percent: 10
|
||||
fraction:
|
||||
numerator: 1
|
||||
denominator: 10
|
||||
backendRef:
|
||||
group: "" # default
|
||||
kind: Service # default
|
||||
name: log-some-requests
|
||||
namespace: my-observability-namespace # defaults to same namespace
|
||||
port: 80
|
||||
hostname: newxyz.example.com
|
||||
```
|
||||
|
||||
Specify `percent` or `fraction`, not both. If neither is specified, all requests get mirrored.
|
||||
|
||||
---
|
||||
|
||||
## Other routes
|
||||
|
||||
- `GRPCRoute` can use GRPC services and methods to route requests
|
||||
|
||||
*this is useful if you're using GRPC; otherwise you can ignore it!*
|
||||
|
||||
- `TLSRoute` can use SNI header to route requests (without decrypting traffic)
|
||||
|
||||
*this is useful to host multiple TLS services on a single address with end-to-end encryption*
|
||||
|
||||
- `TCPRoute` can route TCP connections
|
||||
|
||||
*this is useful to colocate multiple protocols on the same address, e.g. HTTP+HTTPS+SSH*
|
||||
|
||||
- `UDPRoute` can route UDP packets
|
||||
|
||||
*ditto, e.g. for DNS/UDP, DNS/TCP, DNS/HTTPS*
|
||||
|
||||
---
|
||||
|
||||
## `gateway.spec.listeners.allowedRoutes`
|
||||
|
||||
- With `Ingress`, any `Ingress` resource can "catch" traffic
|
||||
|
||||
- This could be a problem e.g. if a dev/staging environment accidentally (or maliciously) creates an `Ingress` with a production hostname
|
||||
|
||||
- Gateway API introduces guardrails
|
||||
|
||||
- A `Gateway` can indicate if it can be referred by routes:
|
||||
|
||||
- from all namespaces (like with `Ingress`)
|
||||
|
||||
- only from the same namespace
|
||||
|
||||
- only from specific namespaces matching a selector
|
||||
|
||||
- That's why we specified `gateway.listeners.web.namespacePolicy.from=All` when deploying Traefik
|
||||
|
||||
???
|
||||
|
||||
:EN:- The Gateway API
|
||||
:FR:- La Gateway API
|
||||
|
||||
@@ -55,7 +55,7 @@
|
||||
- We're going to talk mostly about "Kubernetes cluster centric" approaches here
|
||||
|
||||
[ArgoCD]: https://argoproj.github.io/cd/
|
||||
[Flux]: https://fluxcd.io/
|
||||
[FluxCD]: https://fluxcd.io/
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -171,10 +171,12 @@ Note: it might take a minute or two for the worker to start.
|
||||
|
||||
- save successive revisions, allowing us to rollback
|
||||
|
||||
[Helm docs](https://helm.sh/docs/topics/chart_best_practices/labels/)
|
||||
and [Kubernetes docs](https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/)
|
||||
[Helm docs][helm-labels] and [Kubernetes docs][k8s-labels]
|
||||
have details about recommended annotations and labels.
|
||||
|
||||
[helm-labels]: https://helm.sh/docs/chart_best_practices/labels/
|
||||
[k8s-labels]: https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/
|
||||
|
||||
---
|
||||
|
||||
## Cleaning up
|
||||
|
||||
@@ -18,51 +18,7 @@
|
||||
|
||||
---
|
||||
|
||||
## From `kubectl run` to YAML
|
||||
|
||||
- We can create resources with one-line commands
|
||||
|
||||
(`kubectl run`, `kubectl create deployment`, `kubectl expose`...)
|
||||
|
||||
- We can also create resources by loading YAML files
|
||||
|
||||
(with `kubectl apply -f`, `kubectl create -f`...)
|
||||
|
||||
- There can be multiple resources in a single YAML files
|
||||
|
||||
(making them convenient to deploy entire stacks)
|
||||
|
||||
- However, these YAML bundles often need to be customized
|
||||
|
||||
(e.g.: number of replicas, image version to use, features to enable...)
|
||||
|
||||
---
|
||||
|
||||
## Beyond YAML
|
||||
|
||||
- Very often, after putting together our first `app.yaml`, we end up with:
|
||||
|
||||
- `app-prod.yaml`
|
||||
|
||||
- `app-staging.yaml`
|
||||
|
||||
- `app-dev.yaml`
|
||||
|
||||
- instructions indicating to users "please tweak this and that in the YAML"
|
||||
|
||||
- That's where using something like
|
||||
[CUE](https://github.com/cue-labs/cue-by-example/tree/main/003_kubernetes_tutorial),
|
||||
[Kustomize](https://kustomize.io/),
|
||||
or [Helm](https://helm.sh/) can help!
|
||||
|
||||
- Now we can do something like this:
|
||||
```bash
|
||||
helm install app ... --set this.parameter=that.value
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Other features of Helm
|
||||
## Helm features
|
||||
|
||||
- With Helm, we create "charts"
|
||||
|
||||
@@ -270,7 +226,7 @@ class: extra-details
|
||||
|
||||
]
|
||||
|
||||
Then go to → https://artifacthub.io/packages/helm/seccurecodebox/juice-shop
|
||||
Then go to → https://artifacthub.io/packages/helm/securecodebox/juice-shop
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -164,3 +164,8 @@ As seen in [this example](https://github.com/jpetazzo/beyond-load-balancers/blob
|
||||
- one helmfile for the application stack
|
||||
<br/>
|
||||
(Bento, PostgreSQL cluster, RabbitMQ)
|
||||
|
||||
???
|
||||
|
||||
:EN:- Deploying with Helmfile
|
||||
:FR:- Déployer avec Helmfile
|
||||
|
||||
390
slides/k8s/k0s.md
Normal file
390
slides/k8s/k0s.md
Normal file
@@ -0,0 +1,390 @@
|
||||
# K01 - Setting up a cluster with k0s
|
||||
|
||||
- Running a Kubernetes cluster in the cloud can be relatively straightforward
|
||||
|
||||
- If our cloud provider offers a managed Kubernetes service, it can be as easy as...:
|
||||
|
||||
- clicking a few buttons in their web console
|
||||
|
||||
- a short one-liner leveraging their CLI
|
||||
|
||||
- applying a [Terraform / OpenTofu configuration][one-kubernetes]
|
||||
|
||||
- What if our cloud provider does not offer a managed Kubernetes service?
|
||||
|
||||
- What if we want to run Kubernetes on premises?
|
||||
|
||||
[one-kubernetes]: https://github.com/jpetazzo/container.training/tree/main/prepare-labs/terraform/one-kubernetes
|
||||
|
||||
---
|
||||
|
||||
## A typical managed Kubernetes cluster
|
||||
|
||||
For instance, with Scaleway's Kapsule, we can easily get a cluster with:
|
||||
|
||||
- a CNI configuration providing pod network connectivity and network policies
|
||||
|
||||
(Cilium by default; Calico and Kilo are also supported)
|
||||
|
||||
- a Cloud Controller Manager
|
||||
|
||||
(to automatically label nodes; and to implement `Services` of type `LoadBalancer`)
|
||||
|
||||
- a CSI plugin and `StorageClass` leveraging their network-attached block storage API
|
||||
|
||||
- `metrics-server` to check resource utilization and horizontal pod autoscaling
|
||||
|
||||
- optionally, the cluster autoscaler to dynamically add/remove nodes
|
||||
|
||||
- optionally, a management web interface with the Kubernetes dashboard
|
||||
|
||||
---
|
||||
|
||||
## A typical cluster installed with `kubeadm`
|
||||
|
||||
When using a tool like `kubeadm`, we get:
|
||||
|
||||
- a basic control plane running on a single node
|
||||
|
||||
- some basic services like CoreDNS and kube-proxy
|
||||
|
||||
- no CNI configuration
|
||||
|
||||
(our cluster won't work without one; we need to pick one and set it up ourselves)
|
||||
|
||||
- no Cloud Controller Manager
|
||||
|
||||
- no CSI plugin, no `StorageClass`
|
||||
|
||||
- no `metrics-server`, no cluster autoscaler, no dashboard
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## On premises Kubernetes distributions
|
||||
|
||||
As of October 2025, the [CNCF landscape](https://landscape.cncf.io/?fullscreen=yes&zoom=200&group=certified-partners-and-providers) lists:
|
||||
|
||||
- more than 60 [distributions](https://landscape.cncf.io/guide#platform--certified-kubernetes-distribution),
|
||||
|
||||
- at least 18 [installers](https://landscape.cncf.io/guide#platform--certified-kubernetes-installer),
|
||||
|
||||
- more than 20 [container runtimes](https://landscape.cncf.io/guide#runtime--container-runtime),
|
||||
|
||||
- more than 25 Cloud Native [network](https://landscape.cncf.io/guide#runtime--cloud-native-network) solutions,
|
||||
|
||||
- more than 70 Cloud Native [storage](https://landscape.cncf.io/guide#runtime--cloud-native-storage) solutions.
|
||||
|
||||
Which one(s) are we going to choose? And Why?
|
||||
|
||||
---
|
||||
|
||||
## Lightweight distributions
|
||||
|
||||
- Some Kubernetes distributions put an emphasis on being "lightweight":
|
||||
|
||||
- removing non-essential features or making them optional
|
||||
|
||||
- reducing or removing dependencies on external programs and libraries
|
||||
|
||||
- optionally replacing etcd with another data store (e.g. built-in sqlite)
|
||||
|
||||
- sometimes bundling together multiple components in a single binary for simplicity
|
||||
|
||||
- It often promises easier maintenance (e.g. upgrades)
|
||||
|
||||
- This makes them ideal for "edge" and development environments
|
||||
|
||||
- And sometimes they also fit the bill for regular production clusters!
|
||||
|
||||
---
|
||||
|
||||
## Introducing k0s
|
||||
|
||||
- Open source Kubernetes lightweight distribution
|
||||
|
||||
- Developed and maintained by Mirantis
|
||||
|
||||
- long-time software vendor in the Kubernetes ecosystem
|
||||
|
||||
- bought Docker Enterprise in 2019
|
||||
|
||||
- Addresses multiple segments:
|
||||
|
||||
- edge computing
|
||||
|
||||
- development
|
||||
|
||||
- enterprise-grade HA environments
|
||||
|
||||
- Fully supported by Mirantis (used in [MKE4], [k0rdent], [k0smotron]...)
|
||||
|
||||
[MKE4]: https://www.mirantis.com/blog/mirantis-kubernetes-engine-4-released/
|
||||
[k0rdent]: https://k0rdent.io/
|
||||
[k0smotron]: https://k0smotron.io/
|
||||
|
||||
---
|
||||
|
||||
## `k0s` package
|
||||
|
||||
Its single binary includes:
|
||||
|
||||
- the `kubectl` CLI
|
||||
|
||||
- `kubelet` and a container engine (`containerd`)
|
||||
|
||||
- Kubernetes core control plane components
|
||||
|
||||
(API server, scheduler, controller manager, etcd)
|
||||
|
||||
- Network components
|
||||
|
||||
(like `konnectivity` and core CNI plugins)
|
||||
|
||||
- install, uninstall, back up, restore features
|
||||
|
||||
- helpers to fetch images needed for airgap environments (CoreDNS, kube-proxy...)
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Konnectivity
|
||||
|
||||
- Kubernetes cluster architecture is very versatile
|
||||
|
||||
(the control plane can run inside or outside of the cluster, in pods or not...)
|
||||
|
||||
- The control plane needs to [communicate with kubelets][api-server-to-kubelet]
|
||||
|
||||
(e.g. to retrieve logs, attach to containers, forward ports...)
|
||||
|
||||
- The control plane also needs to [communicate with pods][api-server-to-nodes-pods-services]
|
||||
|
||||
(e.g. when running admission or conversion webhooks, or aggregated APIs, in Pods)
|
||||
|
||||
- In some scenarios, there is no easy way for the control plane to reach nodes and pods
|
||||
|
||||
- The traditional approach has been to use SSH tunnels
|
||||
|
||||
- The modern approach is to use Konnectivity
|
||||
|
||||
[api-server-to-kubelet]: https://kubernetes.io/docs/concepts/architecture/control-plane-node-communication/#api-server-to-kubelet
|
||||
[api-server-to-nodes-pods-services]: https://kubernetes.io/docs/concepts/architecture/control-plane-node-communication/#api-server-to-nodes-pods-and-services
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Konnectivity architecture
|
||||
|
||||
- A konnectivity *server* (or *proxy*) runs on the control plane
|
||||
|
||||
- A konnectivity *agent* runs on each worker node (typically through a DaemonSet)
|
||||
|
||||
- Each agent maintains an RPC tunnel to the server
|
||||
|
||||
- When the control plane needs to connect to a pod or node, it solicits the proxy
|
||||
|
||||
---
|
||||
|
||||
class: pic
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## `k0sctl`
|
||||
|
||||
- It is possible to use "raw" `k0s`
|
||||
|
||||
(that works great for e.g. single-node clusters)
|
||||
|
||||
- There is also a tool called `k0sctl`
|
||||
|
||||
(wrapping `k0s` and facilitating multi-nodes installations)
|
||||
|
||||
.lab[
|
||||
|
||||
- Download the `k0sctl` binary
|
||||
|
||||
```bash
|
||||
curl -fsSL https://github.com/k0sproject/k0sctl/releases/download/v0.25.1/k0sctl-linux-amd64 \
|
||||
> /usr/local/bin/k0sctl
|
||||
chmod +x /usr/local/bin/k0sctl
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## `k0sctl` configuration file
|
||||
|
||||
.lab[
|
||||
|
||||
- Create a default configuration file:
|
||||
```bash
|
||||
k0sctl init \
|
||||
--controller-count 3 \
|
||||
--user docker \
|
||||
--k0s m621 m622 m623 > k0sctl.yaml
|
||||
```
|
||||
|
||||
- Edit the following field so that controller nodes also run kubelet:
|
||||
|
||||
`spec.hosts[*].role: controller+worker`
|
||||
|
||||
- Add the following fields so that controller nodes can run normal workloads:
|
||||
|
||||
`spec.hosts[*].noTaints: true`
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Deploy the cluster
|
||||
|
||||
- `k0sctl` will connect to all our nodes using SSH
|
||||
|
||||
- It will copy `k0s` to the nodes
|
||||
|
||||
- ...And invoke it with the correct parameters
|
||||
|
||||
- ✨️ Magic! ✨️
|
||||
|
||||
.lab[
|
||||
|
||||
- Let's do this!
|
||||
```bash
|
||||
k0sctl apply --config k0sctl.yaml
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Check the results
|
||||
|
||||
- `k0s` has multiple troubleshooting commands to check cluster health
|
||||
|
||||
.lab[
|
||||
|
||||
- Check cluster status:
|
||||
```bash
|
||||
sudo k0s status
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
- The result should look like this:
|
||||
```
|
||||
Version: v1.33.1+k0s.1
|
||||
Process ID: 60183
|
||||
Role: controller
|
||||
Workloads: true
|
||||
SingleNode: false
|
||||
Kube-api probing successful: true
|
||||
Kube-api probing last error:
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Checking etcd status
|
||||
|
||||
- We can also check the status of our etcd cluster
|
||||
|
||||
.lab[
|
||||
|
||||
- Check that the etcd cluster has 3 members:
|
||||
```bash
|
||||
sudo k0s etcd member-list
|
||||
```
|
||||
]
|
||||
|
||||
- The result should look like this:
|
||||
```
|
||||
{"members":{"m621":"https://10.10.3.190:2380","m622":"https://10.10.2.92:2380",
|
||||
"m623":"https://10.10.2.110:2380"}}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Running `kubectl `commands
|
||||
|
||||
- `k0s` embeds `kubectl` as well
|
||||
|
||||
.lab[
|
||||
|
||||
- Check that our nodes are all `Ready`:
|
||||
```bash
|
||||
sudo k0s kubectl get nodes
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
- The result should look like this:
|
||||
```
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
m621 Ready control-plane 66m v1.33.1+k0s
|
||||
m622 Ready control-plane 66m v1.33.1+k0s
|
||||
m623 Ready control-plane 66m v1.33.1+k0s
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Single node install (FYI!)
|
||||
|
||||
Just in case you need to quickly get a single-node cluster with `k0s`...
|
||||
|
||||
Download `k0s`:
|
||||
```bash
|
||||
curl -sSLf https://get.k0s.sh | sudo sh
|
||||
```
|
||||
|
||||
Set up the control plane and other components:
|
||||
```bash
|
||||
sudo k0s install controller --single
|
||||
```
|
||||
|
||||
Start it:
|
||||
```bash
|
||||
sudo k0s start
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
class: extra-details
|
||||
|
||||
## Single node uninstall
|
||||
|
||||
To stop the running cluster:
|
||||
```bash
|
||||
sudo k0s start
|
||||
```
|
||||
|
||||
Reset and wipe its state:
|
||||
```bash
|
||||
sudo k0s reset
|
||||
```
|
||||
|
||||
]
|
||||
|
||||
---
|
||||
|
||||
## Deploying shpod
|
||||
|
||||
- Our machines might be very barebones
|
||||
|
||||
- Let's get ourselves an environment with completion, colors, Helm, etc.
|
||||
|
||||
.lab[
|
||||
|
||||
- Run shpod:
|
||||
```bash
|
||||
curl https://shpod.in | sh
|
||||
```
|
||||
|
||||
]
|
||||
134
slides/k8s/kuik.md
Normal file
134
slides/k8s/kuik.md
Normal file
@@ -0,0 +1,134 @@
|
||||
# Kube Image Keeper
|
||||
|
||||
- Open source solution to improve registry availability
|
||||
|
||||
- Not-too-simple, not-too-complex operator
|
||||
|
||||
(nothing "magic" in the way it works)
|
||||
|
||||
- Leverages various Kubernetes features
|
||||
|
||||
(CRD, mutation webhooks...)
|
||||
|
||||
- Written in Go, with the kubebuilder framework
|
||||
|
||||
---
|
||||
|
||||
## Registry problems that can happen
|
||||
|
||||
- Registry is unavailable or slow
|
||||
|
||||
(e.g. [registry.k8s.io outage in April 2023][registry-k8s-outage])
|
||||
|
||||
- Image was deleted from registry
|
||||
|
||||
(accidentally, or by retention policy)
|
||||
|
||||
- Registry has pull quotas
|
||||
|
||||
(hello Docker Hub!)
|
||||
|
||||
[registry-k8s-outage]: https://github.com/kubernetes/registry.k8s.io/issues/234#issuecomment-1524456564
|
||||
|
||||
---
|
||||
|
||||
## Registries are hard to monitor
|
||||
|
||||
- Most Kubernetes clusters use images from many registries
|
||||
|
||||
(should we continuously monitor all of them?)
|
||||
|
||||
- Registry can be up, but image can be missing
|
||||
|
||||
(should we monitor every image individually?)
|
||||
|
||||
- Some registries have quotas
|
||||
|
||||
(can we even monitor them without triggering these quotas?)
|
||||
|
||||
---
|
||||
|
||||
## Can't we mirror registries?
|
||||
|
||||
- Not as straightforward as, say, mirroring package repositories
|
||||
|
||||
- Requires container engine configuration or rewriting image references
|
||||
|
||||
---
|
||||
|
||||
## How it works
|
||||
|
||||
- A mutating webhook rewrites image references:
|
||||
|
||||
`ghcr.io/foo/bar:lol` → `localhost:7439/ghcr.io/foo/bar:lol`
|
||||
|
||||
- `localhost:7439` is served by the kuik-proxy DaemonSet
|
||||
|
||||
- It serves images either from a cache, or directly from origin
|
||||
|
||||
- The cache is a regular registry running on the cluster
|
||||
|
||||
(it can be stateless, stateful, backed by PVC, object store...)
|
||||
|
||||
- Images are put in cache by the kuik-controller
|
||||
|
||||
- Images are tracked by a CachedImage Custom Resource
|
||||
|
||||
---
|
||||
|
||||
## Some diagrams
|
||||
|
||||
See diagrams in [this presentation][kuik-slides].
|
||||
|
||||
(The full video of the presentation is available [here][kuik-video].)
|
||||
|
||||
[kuik-slides]: https://docs.google.com/presentation/d/19eEogm2HFRNTSqr_1ItLf2wZZP34TUl_RHFhwj3RZEY/edit#slide=id.g27e8d88ad7c_0_142
|
||||
|
||||
[kuik-video]: https://www.youtube.com/watch?v=W1wcIdn0DHY
|
||||
|
||||
---
|
||||
|
||||
## Operator (SRE) analysis
|
||||
|
||||
*After using kuik in production for a few years...*
|
||||
|
||||
- Prevented many outages or quasi-outages
|
||||
|
||||
(e.g. hitting quotas while scaling up or replacing nodes)
|
||||
|
||||
- Running in stateless mode is possible but *not recommended*
|
||||
|
||||
(it's mostly for testing and quick deployments!)
|
||||
|
||||
- When managing many clusters, it would be nice to share the cache
|
||||
|
||||
(not just to save space, but get better performance for common images)
|
||||
|
||||
- Kuik architecture makes it suitable to virtually *any* cluster
|
||||
|
||||
(not tied to a particular distribution, container engine...)
|
||||
|
||||
---
|
||||
|
||||
## Operator (CRD) analysis
|
||||
|
||||
- Nothing "magic"
|
||||
|
||||
- The mutating webhook might even be replaced with Kyverno, CEL... in the long run
|
||||
|
||||
- The CachedImage CR exposes internal data (reference count, age, etc)
|
||||
|
||||
- Leverages kubebuilder (not reinventing too many wheels, hopefully!)
|
||||
|
||||
- Leverages existing building blocks (like the image registry)
|
||||
|
||||
- Some minor inefficiencies (e.g. double pull when image is not in cache)
|
||||
|
||||
- Breaks semantics for `imagePullPolicy: Always` (but [this is tunable][kuik-ippa])
|
||||
|
||||
[kuik-ippa]: https://github.com/enix/kube-image-keeper/issues/156#issuecomment-2312966436
|
||||
|
||||
???
|
||||
|
||||
:EN:- Image retention with Kube Image Keeper
|
||||
:FR:- Mise en cache des images avec KUIK
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user