mirror of
https://github.com/fluxcd/flagger.git
synced 2026-04-15 06:57:34 +00:00
Update NGINX ingress Helm repository
Signed-off-by: Stefan Prodan <stefan.prodan@gmail.com>
This commit is contained in:
@@ -6,20 +6,21 @@ This guide shows you how to use the NGINX ingress controller and Flagger to auto
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.14** or newer and NGINX ingress **0.24** or newer.
|
||||
Flagger requires a Kubernetes cluster **v1.14** or newer and NGINX ingress **v0.41** or newer.
|
||||
|
||||
Install NGINX with Helm v3:
|
||||
Install the NGINX ingress controller with Helm v3:
|
||||
|
||||
```bash
|
||||
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
|
||||
kubectl create ns ingress-nginx
|
||||
helm upgrade -i nginx-ingress stable/nginx-ingress \
|
||||
helm upgrade -i ingress-nginx ingress-nginx/ingress-nginx \
|
||||
--namespace ingress-nginx \
|
||||
--set controller.metrics.enabled=true \
|
||||
--set controller.podAnnotations."prometheus\.io/scrape"=true \
|
||||
--set controller.podAnnotations."prometheus\.io/port"=10254
|
||||
```
|
||||
|
||||
Install Flagger and the Prometheus add-on in the same namespace as NGINX:
|
||||
Install Flagger and the Prometheus add-on in the same namespace as the ingress controller:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
@@ -30,20 +31,11 @@ helm upgrade -i flagger flagger/flagger \
|
||||
--set meshProvider=nginx
|
||||
```
|
||||
|
||||
Optionally you can enable Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace ingress-nginx \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and canary ingress\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and canary ingress).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -64,7 +56,7 @@ helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Create an ingress definition \(replace `app.example.com` with your own domain\):
|
||||
Create an ingress definition (replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.k8s.io/v1beta1
|
||||
@@ -92,7 +84,7 @@ Save the above resource as podinfo-ingress.yaml and then apply it:
|
||||
kubectl apply -f ./podinfo-ingress.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -186,7 +178,9 @@ ingresses.extensions/podinfo-canary
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
|
||||

|
||||
|
||||
@@ -257,7 +251,9 @@ Generate HTTP 500 errors:
|
||||
watch curl http://app.example.com/status/500
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold,
|
||||
the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -286,7 +282,8 @@ Events:
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request duration histogram to validate the canary.
|
||||
The demo app is instrumented with Prometheus so you can create a custom check
|
||||
that will use the HTTP request duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
@@ -326,7 +323,8 @@ Edit the canary analysis and add the latency check:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second then the analysis will fail and the canary will not be promoted.
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over
|
||||
half a second then the analysis will fail and the canary will not be promoted.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -363,7 +361,9 @@ If you have alerting configured, Flagger will send a notification with the reaso
|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
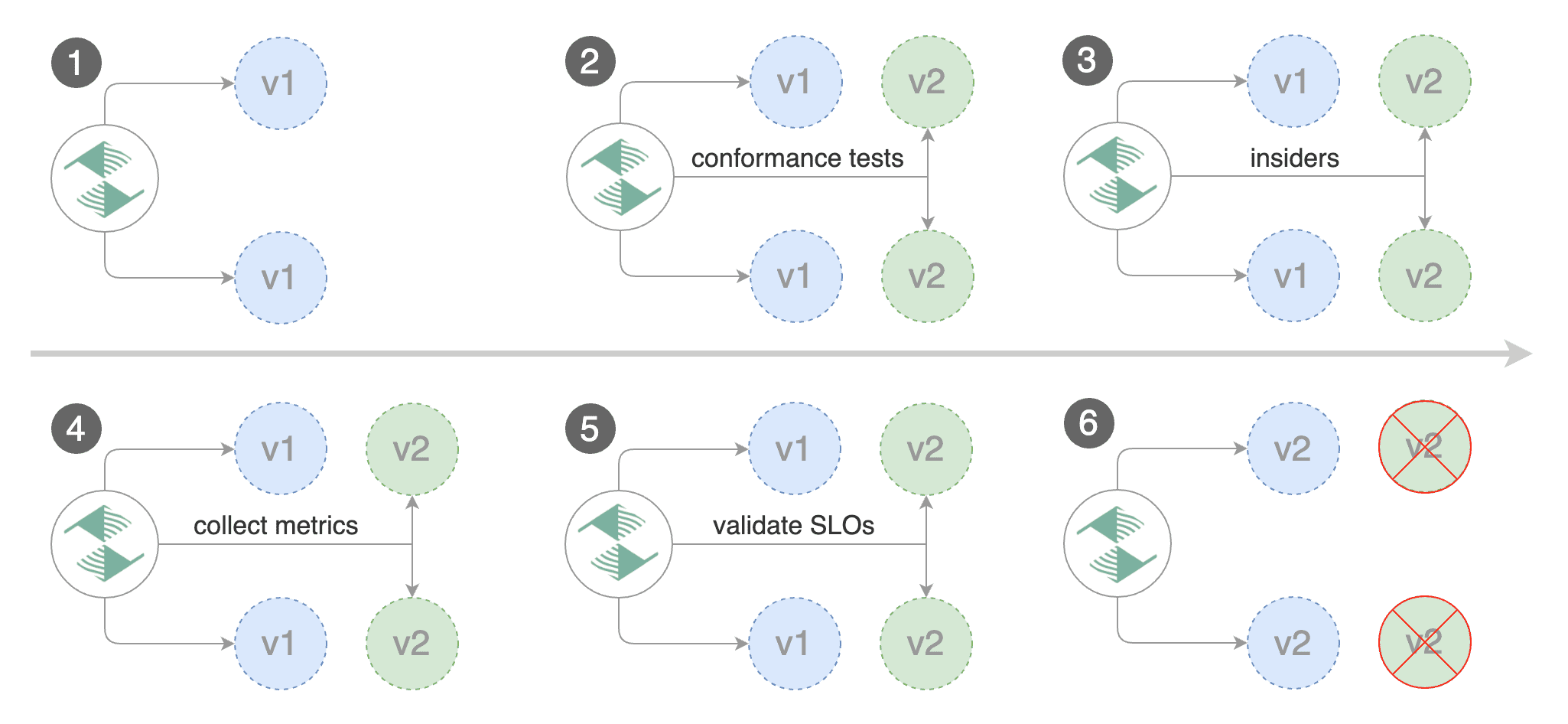
|
||||
|
||||
@@ -396,7 +396,8 @@ Edit the canary analysis, remove the max/step weight and add the match condition
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: canary=always' http://app.example.com/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `canary` cookie set to `always` or those that call the service using the `X-Canary: insider` header.
|
||||
The above configuration will run an analysis for ten minutes targeting users that have
|
||||
a `canary` cookie set to `always` or those that call the service using the `X-Canary: insider` header.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -434,5 +435,8 @@ Events:
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks, [webhooks](../usage/webhooks.md), [manual promotion](../usage/webhooks.md#manual-gating) approval and [Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
The above procedure can be extended with
|
||||
[custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
Reference in New Issue
Block a user