mirror of
https://github.com/fluxcd/flagger.git
synced 2026-04-15 06:57:34 +00:00
Update website to v1.0.0-rc.1
This commit is contained in:
3
.gitignore
vendored
3
.gitignore
vendored
@@ -61,4 +61,5 @@ typings/
|
||||
.next
|
||||
|
||||
bin/
|
||||
docs/.vuepress/dist/
|
||||
docs/.vuepress/dist/
|
||||
Makefile.dev
|
||||
@@ -2,18 +2,80 @@ module.exports = {
|
||||
title: 'Flagger',
|
||||
description: 'Progressive Delivery operator for Kubernetes (Canary, A/B Testing and Blue/Green deployments)',
|
||||
themeConfig: {
|
||||
search: false,
|
||||
search: true,
|
||||
activeHeaderLinks: false,
|
||||
docsDir: 'docs',
|
||||
repo: 'weaveworks/flagger',
|
||||
nav: [
|
||||
{ text: 'Docs', link: 'https://docs.flagger.app' },
|
||||
{ text: 'Changelog', link: 'https://github.com/weaveworks/flagger/blob/master/CHANGELOG.md' }
|
||||
],
|
||||
sidebar: [
|
||||
'/',
|
||||
{
|
||||
title: 'Introduction',
|
||||
path: '/intro/',
|
||||
collapsable: false,
|
||||
children: [
|
||||
['/intro/', 'Get Started'],
|
||||
['/intro/faq', 'FAQ'],
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'Install',
|
||||
path: '/install/flagger-install-on-kubernetes',
|
||||
collapsable: false,
|
||||
children: [
|
||||
['/install/flagger-install-on-kubernetes', 'On Kubernetes'],
|
||||
['/install/flagger-install-on-google-cloud', 'On GKE Istio'],
|
||||
['/install/flagger-install-on-eks-appmesh', 'On EKS App Mesh'],
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'Usage',
|
||||
path: '/usage/how-it-works',
|
||||
collapsable: false,
|
||||
children: [
|
||||
['/usage/how-it-works', 'How it works'],
|
||||
['/usage/deployment-strategies', 'Deployment Strategies'],
|
||||
['/usage/metrics', 'Metrics Analysis'],
|
||||
['/usage/webhooks', 'Webhooks'],
|
||||
['/usage/alerting', 'Alerting'],
|
||||
['/usage/monitoring', 'Monitoring'],
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'Tutorials',
|
||||
path: '/tutorials/istio-progressive-delivery',
|
||||
collapsable: false,
|
||||
children: [
|
||||
['/tutorials/istio-progressive-delivery', 'Istio Canaries'],
|
||||
['/tutorials/istio-ab-testing', 'Istio A/B Testing'],
|
||||
['/tutorials/linkerd-progressive-delivery', 'Linkerd Canaries'],
|
||||
['/tutorials/appmesh-progressive-delivery', 'App Mesh Canaries'],
|
||||
['/tutorials/nginx-progressive-delivery', 'NGINX Ingress Canaries'],
|
||||
['/tutorials/gloo-progressive-delivery', 'Gloo Canaries'],
|
||||
['/tutorials/contour-progressive-delivery', 'Contour Canaries'],
|
||||
['/tutorials/kubernetes-blue-green', 'Kubernetes Blue/Green'],
|
||||
['/tutorials/canary-helm-gitops', 'Canaries with Helm charts and GitOps'],
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'Dev',
|
||||
path: '/dev/dev-guide',
|
||||
collapsable: false,
|
||||
children: [
|
||||
['/dev/dev-guide', 'Development Guide'],
|
||||
['/dev/release-guide', 'Release Guide'],
|
||||
['/dev/upgrade-guide', 'Upgrade Guide'],
|
||||
],
|
||||
},
|
||||
]
|
||||
},
|
||||
head: [
|
||||
['link', { rel: 'icon', href: '/favicon.png' }],
|
||||
['link', { rel: 'stylesheet', href: '/website.css' }],
|
||||
['meta', { name: 'keywords', content: 'gitops kubernetes flagger istio linkerd appmesh' }],
|
||||
['meta', { name: 'keywords', content: 'gitops kubernetes flagger istio linkerd appmesh contour gloo nginx' }],
|
||||
['meta', { name: 'twitter:card', content: 'summary_large_image' }],
|
||||
['meta', { name: 'twitter:title', content: 'Flagger' }],
|
||||
['meta', { name: 'twitter:description', content: 'Progressive delivery Kubernetes operator (Canary, A/B Testing and Blue/Green deployments)' }],
|
||||
|
||||
@@ -7,3 +7,6 @@
|
||||
background: url(favicon.png) left 50% no-repeat;
|
||||
background-size: 20px 20px;
|
||||
}
|
||||
/*.theme-container .theme-default-content:not(.custom) {*/
|
||||
/* max-width: 920px;*/
|
||||
/*}*/
|
||||
@@ -11,8 +11,8 @@ features:
|
||||
- title: Flexible Traffic Routing
|
||||
details: Shift and route traffic between app versions using a service mesh like Istio, Linkerd or AWS App Mesh. Or if a service mesh does not meet your needs, use an Ingress controller like Contour, Gloo or NGINX.
|
||||
- title: Extensible Validation
|
||||
details: Besides the builtin metrics checks, you can extend your application analysis with custom Prometheus metrics and webooks for running acceptance tests, load tests, or any other custom validation.
|
||||
footer: Apache License 2.0 | Copyright © 2019 Weaveworks
|
||||
details: Besides the builtin metrics checks, you can extend your application analysis with custom Prometheus, Datadog, CloudWatch metrics and webooks for running acceptance tests, load tests, or any other custom validation.
|
||||
footer: Apache License 2.0 | Copyright © 2018-2020 Weaveworks
|
||||
---
|
||||
|
||||
## Progressive Delivery
|
||||
@@ -30,25 +30,25 @@ about how the new version impacts the production environment.
|
||||
|
||||
Flagger can run automated application analysis, testing, promotion and rollback for the following deployment strategies:
|
||||
* **Canary** (progressive traffic shifting)
|
||||
* [Istio](https://docs.flagger.app/usage/progressive-delivery),
|
||||
[Linkerd](https://docs.flagger.app/usage/linkerd-progressive-delivery),
|
||||
[App Mesh](https://docs.flagger.app/usage/appmesh-progressive-delivery),
|
||||
[Contour](https://docs.flagger.app/usage/contour-progressive-delivery),
|
||||
[Gloo](https://docs.flagger.app/usage/gloo-progressive-delivery),
|
||||
[NGINX](https://docs.flagger.app/usage/nginx-progressive-delivery)
|
||||
* [Istio](https://docs.flagger.app/tutorials/istio-progressive-delivery),
|
||||
[Linkerd](https://docs.flagger.app/tutorials/linkerd-progressive-delivery),
|
||||
[App Mesh](https://docs.flagger.app/tutorials/appmesh-progressive-delivery),
|
||||
[Contour](https://docs.flagger.app/tutorials/contour-progressive-delivery),
|
||||
[Gloo](https://docs.flagger.app/tutorials/gloo-progressive-delivery),
|
||||
[NGINX](https://docs.flagger.app/tutorials/nginx-progressive-delivery)
|
||||
|
||||
* **A/B Testing** (HTTP headers and cookies traffic routing)
|
||||
* [Istio](https://docs.flagger.app/usage/ab-testing),
|
||||
[App Mesh](hhttps://docs.flagger.app/usage/appmesh-progressive-delivery#a-b-testing),
|
||||
[Contour](https://docs.flagger.app/usage/contour-progressive-delivery),
|
||||
[NGINX](https://docs.flagger.app/usage/nginx-progressive-delivery)
|
||||
* **Blue/Green** (traffic switching)
|
||||
* [Kubernetes CNI](https://docs.flagger.app/usage/blue-green),
|
||||
Istio, Linkerd, App Mesh, Contour, Gloo, NGINX
|
||||
* [Istio](https://docs.flagger.app/tutorials/istio-ab-testing),
|
||||
[App Mesh](hhttps://docs.flagger.app/tutorials/appmesh-progressive-delivery#a-b-testing),
|
||||
[Contour](https://docs.flagger.app/tutorials/contour-progressive-delivery#a-b-testing),
|
||||
[NGINX](https://docs.flagger.app/tutorials/nginx-progressive-delivery#a-b-testing)
|
||||
* **Blue/Green** (traffic switching and mirroring)
|
||||
* [Kubernetes CNI](https://docs.flagger.app/tutorials/kubernetes-blue-green),
|
||||
[Istio](https://docs.flagger.app/tutorials/istio-progressive-delivery#traffic-mirroring),
|
||||
Linkerd, App Mesh, Contour, Gloo, NGINX
|
||||
|
||||
Flagger can be configured to send notifications to a
|
||||
[Slack](https://docs.flagger.app/usage/alerting#slack) or
|
||||
[Microsoft Teams](https://docs.flagger.app/usage/alerting#microsoft-teams) channel.
|
||||
Flagger can be configured to [send notifications](https://docs.flagger.app/usage/alerting) to
|
||||
Slack, Microsoft Teams, Discord or Rocket.
|
||||
It will post messages when a deployment has been initialised,
|
||||
when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||
|
||||
0
docs/dev/README.md
Normal file
0
docs/dev/README.md
Normal file
211
docs/dev/dev-guide.md
Normal file
211
docs/dev/dev-guide.md
Normal file
@@ -0,0 +1,211 @@
|
||||
# Development Guide
|
||||
|
||||
This document describes how to build, test and run Flagger from source.
|
||||
|
||||
## Setup dev environment
|
||||
|
||||
Flagger is written in Go and uses Go modules for dependency management.
|
||||
|
||||
On your dev machine install the following tools:
|
||||
* go >= 1.13
|
||||
* git >= 2.20
|
||||
* bash >= 5.0
|
||||
* make >= 3.81
|
||||
* kubectl >= 1.16
|
||||
* kustomize >= 3.5
|
||||
* helm >= 3.0
|
||||
* docker >= 19.03
|
||||
|
||||
You'll also need a Kubernetes cluster for testing Flagger.
|
||||
You can use Minikube, Kind, Docker desktop or any remote cluster
|
||||
(AKS/EKS/GKE/etc) Kubernetes version 1.14 or newer.
|
||||
|
||||
To start contributing to Flagger, fork the [repository](https://github.com/weaveworks/flagger) on GitHub.
|
||||
|
||||
Create a dir inside your `GOPATH`:
|
||||
|
||||
```bash
|
||||
mkdir -p $GOPATH/src/github.com/weaveworks
|
||||
```
|
||||
|
||||
Clone your fork:
|
||||
|
||||
```bash
|
||||
cd $GOPATH/src/github.com/weaveworks
|
||||
git clone https://github.com/YOUR_USERNAME/flagger
|
||||
cd flagger
|
||||
```
|
||||
|
||||
Set Flagger repository as upstream:
|
||||
|
||||
```bash
|
||||
git remote add upstream https://github.com/weaveworks/flagger.git
|
||||
```
|
||||
|
||||
Sync your fork regularly to keep it up-to-date with upstream:
|
||||
|
||||
```bash
|
||||
git fetch upstream
|
||||
git checkout master
|
||||
git merge upstream/master
|
||||
```
|
||||
|
||||
## Build
|
||||
|
||||
Download Go modules:
|
||||
|
||||
```bash
|
||||
go mod download
|
||||
```
|
||||
|
||||
Build Flagger binary and container image:
|
||||
|
||||
```bash
|
||||
make build
|
||||
```
|
||||
|
||||
Build load tester binary and container image:
|
||||
|
||||
```bash
|
||||
make loadtester-build
|
||||
```
|
||||
|
||||
## Code changes
|
||||
|
||||
Before submitting a PR, make sure your changes are covered by unit tests.
|
||||
|
||||
If you made changes to `go.mod` run:
|
||||
|
||||
```bash
|
||||
go mod tidy
|
||||
```
|
||||
|
||||
If you made changes to `pkg/apis` regenerate Kubernetes client sets with:
|
||||
|
||||
```bash
|
||||
make codegen
|
||||
```
|
||||
|
||||
Run code formatters:
|
||||
|
||||
```bash
|
||||
make fmt
|
||||
```
|
||||
|
||||
Run unit tests:
|
||||
|
||||
```bash
|
||||
make test
|
||||
```
|
||||
|
||||
## API changes
|
||||
|
||||
If you made changes to `pkg/apis` regenerate the Kubernetes client sets with:
|
||||
|
||||
```bash
|
||||
make codegen
|
||||
```
|
||||
|
||||
Update the validation spec in `artifacts/flagger/crd.yaml` and run:
|
||||
|
||||
```bash
|
||||
make crd
|
||||
```
|
||||
|
||||
Note that any change to the CRDs must be accompanied by an update to the Open API schema.
|
||||
|
||||
## Manual testing
|
||||
|
||||
Install a service mesh and/or an ingress controller on your cluster and deploy Flagger
|
||||
using one of the install options [listed here](../install/flagger-install-on-kubernetes).
|
||||
|
||||
If you made changes to the CRDs, apply your local copy with:
|
||||
|
||||
```bash
|
||||
kubectl apply -f artifacts/flagger/crd.yaml
|
||||
```
|
||||
|
||||
Shutdown the Flagger instance installed on your cluster (replace the namespace with your mesh/ingress one):
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system scale deployment/flagger --replicas=0
|
||||
```
|
||||
|
||||
Port forward to your Prometheus instance:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/prometheus 9090:9090
|
||||
```
|
||||
|
||||
Run Flagger locally against your remote cluster by specifying a kubeconfig path:
|
||||
|
||||
```bash
|
||||
go run cmd/flagger/ -kubeconfig=$HOME/.kube/config \
|
||||
-log-level=info \
|
||||
-mesh-provider=istio \
|
||||
-metrics-server=http://localhost:9090
|
||||
```
|
||||
|
||||
Another option to manually test your changes is to build and push the image to your container registry:
|
||||
|
||||
```bash
|
||||
make build
|
||||
docker tag weaveworks/flagger:latest <YOUR-DOCKERHUB-USERNAME>/flagger:<YOUR-TAG>
|
||||
docker push <YOUR-DOCKERHUB-USERNAME>/flagger:<YOUR-TAG>
|
||||
```
|
||||
|
||||
Deploy your image on the cluster and scale up Flagger:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system set image deployment/flagger flagger=<YOUR-DOCKERHUB-USERNAME>/flagger:<YOUR-TAG>
|
||||
kubectl -n istio-system scale deployment/flagger --replicas=1
|
||||
```
|
||||
|
||||
Now you can use one of the [tutorials](../intro/) to manually test your changes.
|
||||
|
||||
## Integration testing
|
||||
|
||||
Flagger end-to-end tests can be run locally with [Kubernetes Kind](https://github.com/kubernetes-sigs/kind).
|
||||
|
||||
Create a Kind cluster:
|
||||
|
||||
```bash
|
||||
kind create cluster
|
||||
```
|
||||
|
||||
Install a service mesh and/or an ingress controller in Kind.
|
||||
|
||||
Linkerd example:
|
||||
|
||||
```bash
|
||||
linkerd install | kubectl apply -f -
|
||||
linkerd check
|
||||
```
|
||||
|
||||
Build Flagger container image and load it on the cluster:
|
||||
|
||||
```bash
|
||||
make build
|
||||
docker tag weaveworks/flagger:latest test/flagger:latest
|
||||
kind load docker-image test/flagger:latest
|
||||
```
|
||||
|
||||
Install Flagger on the cluster and set the test image:
|
||||
|
||||
```bash
|
||||
kubectl apply -k ./kustomize/linkerd
|
||||
kubectl -n linkerd set image deployment/flagger flagger=test/flagger:latest
|
||||
kubectl -n linkerd rollout status deployment/flagger
|
||||
```
|
||||
|
||||
Run the Linkerd e2e tests:
|
||||
|
||||
```bash
|
||||
./test/e2e-linkerd-tests.sh
|
||||
```
|
||||
|
||||
For each service mesh and ingress controller there is a dedicated e2e test suite,
|
||||
chose one that matches your changes from this [list](https://github.com/weaveworks/flagger/tree/master/test).
|
||||
|
||||
When you open a pull request on Flagger repo, the unit and integration tests will be run in CI.
|
||||
|
||||
34
docs/dev/release-guide.md
Normal file
34
docs/dev/release-guide.md
Normal file
@@ -0,0 +1,34 @@
|
||||
# Release Guide
|
||||
|
||||
This document describes how to release Flagger.
|
||||
|
||||
## Release
|
||||
|
||||
To release a new Flagger version (e.g. `2.0.0`) follow these steps:
|
||||
* create a branch `git checkout -b prep-2.0.0`
|
||||
* set the version in code and manifests `TAG=2.0.0 make version-set`
|
||||
* commit changes and merge PR
|
||||
* checkout master `git checkout master && git pull`
|
||||
* tag master `make release`
|
||||
|
||||
## CI
|
||||
|
||||
After the tag has been pushed to GitHub, the CI release pipeline does the following:
|
||||
* creates a GitHub release
|
||||
* pushes the Flagger binary and change log to GitHub release
|
||||
* pushes the Flagger container image to Docker Hub
|
||||
* pushes the Helm chart to github-pages branch
|
||||
* GitHub pages publishes the new chart version on the Helm repository
|
||||
|
||||
## Docs
|
||||
|
||||
The documentation [website](https://docs.flagger.app) is built from the `docs` branch.
|
||||
|
||||
After a Flagger release, publish the docs with:
|
||||
* `git checkout master && git pull`
|
||||
* `git checkout docs`
|
||||
* `git rebase master`
|
||||
* `git push origin docs`
|
||||
|
||||
|
||||
|
||||
41
docs/dev/upgrade-guide.md
Normal file
41
docs/dev/upgrade-guide.md
Normal file
@@ -0,0 +1,41 @@
|
||||
# Upgrade Guide
|
||||
|
||||
This document describes how to upgrade Flagger.
|
||||
|
||||
## Upgrade canaries v1alpha3 to v1beta1
|
||||
|
||||
Canary CRD changes in `canaries.flagger.app/v1beta1`:
|
||||
* the `spec.canaryAnalysis` field has been deprecated and replaced with `spec.analysis`
|
||||
* the `spec.analysis.interval` and `spec.analysis.threshold` fields are required
|
||||
* the `status.lastAppliedSpec` and `status.lastPromotedSpec` hashing algorithm changed to `hash/fnv`
|
||||
* the `spec.analysis.alerts` array can reference `alertproviders.flagger.app/v1beta1` resources
|
||||
* the `spec.analysis.metrics[].templateRef` can reference a `metrictemplate.flagger.app/v1beta1` resource
|
||||
* the `metric.threshold` field has been deprecated and replaced with `metric.thresholdRange`
|
||||
* the `spec.targetRef` can reference `DaemonSet` kind
|
||||
|
||||
Upgrade procedure:
|
||||
* install the `v1beta1` CRDs
|
||||
* update Flagger deployment
|
||||
* replace `apiVersion: flagger.app/v1alpha3` with `apiVersion: flagger.app/v1beta1` in all canary manifests
|
||||
* replace `spec.canaryAnalysis` with `spec.analysis` in all canary manifests
|
||||
* update canary manifests in cluster
|
||||
|
||||
**Note** that after upgrading Flagger, all canaries will be triggered as the hash value used for tracking changes
|
||||
is computed differently. You can set `spec.skipAnalysis: true` in all canary manifests before upgrading Flagger,
|
||||
do the upgrade, wait for Flagger to finish the no-op promotions and finally set `skipAnalysis` to `false`.
|
||||
|
||||
Update builtin metrics:
|
||||
* replace `threshold` with `thresholdRange.min` for request-success-rate
|
||||
* replace `threshold` with `thresholdRange.max` for request-duration
|
||||
|
||||
```yaml
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 1m
|
||||
```
|
||||
0
docs/install/README.md
Normal file
0
docs/install/README.md
Normal file
194
docs/install/flagger-install-on-eks-appmesh.md
Normal file
194
docs/install/flagger-install-on-eks-appmesh.md
Normal file
@@ -0,0 +1,194 @@
|
||||
# Flagger Install on EKS App Mesh
|
||||
|
||||
This guide walks you through setting up Flagger and AWS App Mesh on EKS.
|
||||
|
||||
## App Mesh
|
||||
|
||||
The App Mesh integration with EKS is made out of the following components:
|
||||
|
||||
* Kubernetes custom resources
|
||||
* `mesh.appmesh.k8s.aws` defines a logical boundary for network traffic between the services
|
||||
* `virtualnode.appmesh.k8s.aws` defines a logical pointer to a Kubernetes workload
|
||||
* `virtualservice.appmesh.k8s.aws` defines the routing rules for a workload inside the mesh
|
||||
* CRD controller - keeps the custom resources in sync with the App Mesh control plane
|
||||
* Admission controller - injects the Envoy sidecar and assigns Kubernetes pods to App Mesh virtual nodes
|
||||
* Telemetry service - Prometheus instance that collects and stores Envoy's metrics
|
||||
|
||||
## Create a Kubernetes cluster
|
||||
|
||||
In order to create an EKS cluster you can use [eksctl](https://eksctl.io). Eksctl is an open source command-line utility made by Weaveworks in collaboration with Amazon.
|
||||
|
||||
On MacOS you can install eksctl with Homebrew:
|
||||
|
||||
```bash
|
||||
brew tap weaveworks/tap
|
||||
brew install weaveworks/tap/eksctl
|
||||
```
|
||||
|
||||
Create an EKS cluster:
|
||||
|
||||
```bash
|
||||
eksctl create cluster --name=appmesh \
|
||||
--region=us-west-2 \
|
||||
--nodes 3 \
|
||||
--node-volume-size=120 \
|
||||
--appmesh-access
|
||||
```
|
||||
|
||||
The above command will create a two nodes cluster with App Mesh [IAM policy](https://docs.aws.amazon.com/app-mesh/latest/userguide/MESH_IAM_user_policies.html) attached to the EKS node instance role.
|
||||
|
||||
Verify the install with:
|
||||
|
||||
```bash
|
||||
kubectl get nodes
|
||||
```
|
||||
|
||||
## Install Helm
|
||||
|
||||
Install the [Helm](https://docs.helm.sh/using_helm/#installing-helm) command-line tool:
|
||||
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
Create a service account and a cluster role binding for Tiller:
|
||||
|
||||
```bash
|
||||
kubectl -n kube-system create sa tiller
|
||||
|
||||
kubectl create clusterrolebinding tiller-cluster-rule \
|
||||
--clusterrole=cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
Deploy Tiller in the `kube-system` namespace:
|
||||
|
||||
```bash
|
||||
helm init --service-account tiller
|
||||
```
|
||||
|
||||
You should consider using SSL between Helm and Tiller, for more information on securing your Helm installation see [docs.helm.sh](https://docs.helm.sh/using_helm/#securing-your-helm-installation).
|
||||
|
||||
## Enable horizontal pod auto-scaling
|
||||
|
||||
Install the Horizontal Pod Autoscaler \(HPA\) metrics provider:
|
||||
|
||||
```bash
|
||||
helm upgrade -i metrics-server stable/metrics-server \
|
||||
--namespace kube-system \
|
||||
--set args[0]=--kubelet-preferred-address-types=InternalIP
|
||||
```
|
||||
|
||||
After a minute, the metrics API should report CPU and memory usage for pods. You can very the metrics API with:
|
||||
|
||||
```bash
|
||||
kubectl -n kube-system top pods
|
||||
```
|
||||
|
||||
## Install the App Mesh components
|
||||
|
||||
Create the `appmesh-system` namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns appmesh-system
|
||||
```
|
||||
|
||||
Apply the App Mesh CRDs:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/aws/eks-charts/stable/appmesh-controller//crds
|
||||
```
|
||||
|
||||
Add the EKS repository to Helm:
|
||||
|
||||
```bash
|
||||
helm repo add eks https://aws.github.io/eks-charts
|
||||
```
|
||||
|
||||
Install the App Mesh CRD controller:
|
||||
|
||||
```bash
|
||||
helm upgrade -i appmesh-controller eks/appmesh-controller \
|
||||
--wait --namespace appmesh-system
|
||||
```
|
||||
|
||||
Install the App Mesh admission controller and create a mesh called `global`:
|
||||
|
||||
```bash
|
||||
helm upgrade -i appmesh-inject eks/appmesh-inject \
|
||||
--wait --namespace appmesh-system \
|
||||
--set mesh.create=true \
|
||||
--set mesh.name=global
|
||||
```
|
||||
|
||||
Verify that the global mesh is active:
|
||||
|
||||
```bash
|
||||
kubectl describe mesh
|
||||
|
||||
Status:
|
||||
Mesh Condition:
|
||||
Status: True
|
||||
Type: MeshActive
|
||||
```
|
||||
|
||||
In order to collect the App Mesh metrics that Flagger needs to run the canary analysis, you'll need to setup a Prometheus instance to scrape the Envoy sidecars.
|
||||
|
||||
Install the App Mesh Prometheus:
|
||||
|
||||
```bash
|
||||
helm upgrade -i appmesh-prometheus eks/appmesh-prometheus \
|
||||
--wait --namespace appmesh-system
|
||||
```
|
||||
|
||||
## Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install Flagger's Canary CRD:
|
||||
|
||||
```yaml
|
||||
kubectl apply -f https://raw.githubusercontent.com/weaveworks/flagger/master/artifacts/flagger/crd.yaml
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**appmesh-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=appmesh-system \
|
||||
--set crd.create=false \
|
||||
--set meshProvider=appmesh \
|
||||
--set metricsServer=http://appmesh-prometheus:9090
|
||||
```
|
||||
|
||||
You can enable Slack or MS Teams notifications with:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace=appmesh-system \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis. Deploy Grafana in the _**appmesh-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=appmesh-system \
|
||||
--set url=http://appmesh-prometheus:9090
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n appmesh-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
Now that you have Flagger running you can try the [App Mesh canary deployments tutorial](https://docs.flagger.app/usage/appmesh-progressive-delivery).
|
||||
|
||||
400
docs/install/flagger-install-on-google-cloud.md
Normal file
400
docs/install/flagger-install-on-google-cloud.md
Normal file
@@ -0,0 +1,400 @@
|
||||
# Flagger Install on GKE Istio
|
||||
|
||||
This guide walks you through setting up Flagger and Istio on Google Kubernetes Engine.
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You will be creating a cluster on Google’s Kubernetes Engine \(GKE\), if you don’t have an account you can sign up [here](https://cloud.google.com/free/) for free credits.
|
||||
|
||||
Login into Google Cloud, create a project and enable billing for it.
|
||||
|
||||
Install the [gcloud](https://cloud.google.com/sdk/) command line utility and configure your project with `gcloud init`.
|
||||
|
||||
Set the default project \(replace `PROJECT_ID` with your own project\):
|
||||
|
||||
```text
|
||||
gcloud config set project PROJECT_ID
|
||||
```
|
||||
|
||||
Set the default compute region and zone:
|
||||
|
||||
```text
|
||||
gcloud config set compute/region us-central1
|
||||
gcloud config set compute/zone us-central1-a
|
||||
```
|
||||
|
||||
Enable the Kubernetes and Cloud DNS services for your project:
|
||||
|
||||
```text
|
||||
gcloud services enable container.googleapis.com
|
||||
gcloud services enable dns.googleapis.com
|
||||
```
|
||||
|
||||
Install the kubectl command-line tool:
|
||||
|
||||
```text
|
||||
gcloud components install kubectl
|
||||
```
|
||||
|
||||
## GKE cluster setup
|
||||
|
||||
Create a cluster with the Istio add-on:
|
||||
|
||||
```bash
|
||||
K8S_VERSION=$(gcloud container get-server-config --format=json \
|
||||
| jq -r '.validMasterVersions[0]')
|
||||
|
||||
gcloud beta container clusters create istio \
|
||||
--cluster-version=${K8S_VERSION} \
|
||||
--zone=us-central1-a \
|
||||
--num-nodes=2 \
|
||||
--machine-type=n1-highcpu-4 \
|
||||
--preemptible \
|
||||
--no-enable-cloud-logging \
|
||||
--no-enable-cloud-monitoring \
|
||||
--disk-size=30 \
|
||||
--enable-autorepair \
|
||||
--addons=HorizontalPodAutoscaling,Istio \
|
||||
--istio-config=auth=MTLS_PERMISSIVE
|
||||
```
|
||||
|
||||
The above command will create a default node pool consisting of two `n1-highcpu-4` \(vCPU: 4, RAM 3.60GB, DISK: 30GB\) preemptible VMs. Preemptible VMs are up to 80% cheaper than regular instances and are terminated and replaced after a maximum of 24 hours.
|
||||
|
||||
Set up credentials for `kubectl`:
|
||||
|
||||
```bash
|
||||
gcloud container clusters get-credentials istio
|
||||
```
|
||||
|
||||
Create a cluster admin role binding:
|
||||
|
||||
```bash
|
||||
kubectl create clusterrolebinding "cluster-admin-$(whoami)" \
|
||||
--clusterrole=cluster-admin \
|
||||
--user="$(gcloud config get-value core/account)"
|
||||
```
|
||||
|
||||
Validate your setup with:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system get svc
|
||||
```
|
||||
|
||||
In a couple of seconds GCP should allocate an external IP to the `istio-ingressgateway` service.
|
||||
|
||||
## Cloud DNS setup
|
||||
|
||||
You will need an internet domain and access to the registrar to change the name servers to Google Cloud DNS.
|
||||
|
||||
Create a managed zone named `istio` in Cloud DNS \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
gcloud dns managed-zones create \
|
||||
--dns-name="example.com." \
|
||||
--description="Istio zone" "istio"
|
||||
```
|
||||
|
||||
Look up your zone's name servers:
|
||||
|
||||
```bash
|
||||
gcloud dns managed-zones describe istio
|
||||
```
|
||||
|
||||
Update your registrar's name server records with the records returned by the above command.
|
||||
|
||||
Wait for the name servers to change \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
watch dig +short NS example.com
|
||||
```
|
||||
|
||||
Create a static IP address named `istio-gateway` using the Istio ingress IP:
|
||||
|
||||
```bash
|
||||
export GATEWAY_IP=$(kubectl -n istio-system get svc/istio-ingressgateway -ojson \
|
||||
| jq -r .status.loadBalancer.ingress[0].ip)
|
||||
|
||||
gcloud compute addresses create istio-gateway --addresses ${GATEWAY_IP} --region us-central1
|
||||
```
|
||||
|
||||
Create the following DNS records \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
DOMAIN="example.com"
|
||||
|
||||
gcloud dns record-sets transaction start --zone=istio
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="www.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction add --zone=istio \
|
||||
--name="*.${DOMAIN}" --ttl=300 --type=A ${GATEWAY_IP}
|
||||
|
||||
gcloud dns record-sets transaction execute --zone istio
|
||||
```
|
||||
|
||||
Verify that the wildcard DNS is working \(replace `example.com` with your domain\):
|
||||
|
||||
```bash
|
||||
watch host test.example.com
|
||||
```
|
||||
|
||||
## Install Helm
|
||||
|
||||
Install the [Helm](https://docs.helm.sh/using_helm/#installing-helm) command-line tool:
|
||||
|
||||
```text
|
||||
brew install kubernetes-helm
|
||||
```
|
||||
|
||||
Create a service account and a cluster role binding for Tiller:
|
||||
|
||||
```bash
|
||||
kubectl -n kube-system create sa tiller
|
||||
|
||||
kubectl create clusterrolebinding tiller-cluster-rule \
|
||||
--clusterrole=cluster-admin \
|
||||
--serviceaccount=kube-system:tiller
|
||||
```
|
||||
|
||||
Deploy Tiller in the `kube-system` namespace:
|
||||
|
||||
```bash
|
||||
helm init --service-account tiller
|
||||
```
|
||||
|
||||
You should consider using SSL between Helm and Tiller, for more information on securing your Helm installation see [docs.helm.sh](https://docs.helm.sh/using_helm/#securing-your-helm-installation).
|
||||
|
||||
## Install cert-manager
|
||||
|
||||
Jetstack's [cert-manager](https://github.com/jetstack/cert-manager) is a Kubernetes operator that automatically creates and manages TLS certs issued by Let’s Encrypt.
|
||||
|
||||
You'll be using cert-manager to provision a wildcard certificate for the Istio ingress gateway.
|
||||
|
||||
Install cert-manager's CRDs:
|
||||
|
||||
```bash
|
||||
CERT_REPO=https://raw.githubusercontent.com/jetstack/cert-manager
|
||||
|
||||
kubectl apply -f ${CERT_REPO}/release-0.10/deploy/manifests/00-crds.yaml
|
||||
```
|
||||
|
||||
Create the cert-manager namespace and disable resource validation:
|
||||
|
||||
```bash
|
||||
kubectl create namespace cert-manager
|
||||
|
||||
kubectl label namespace cert-manager certmanager.k8s.io/disable-validation=true
|
||||
```
|
||||
|
||||
Install cert-manager with Helm:
|
||||
|
||||
```bash
|
||||
helm repo add jetstack https://charts.jetstack.io && \
|
||||
helm repo update && \
|
||||
helm upgrade -i cert-manager \
|
||||
--namespace cert-manager \
|
||||
--version v0.10.0 \
|
||||
jetstack/cert-manager
|
||||
```
|
||||
|
||||
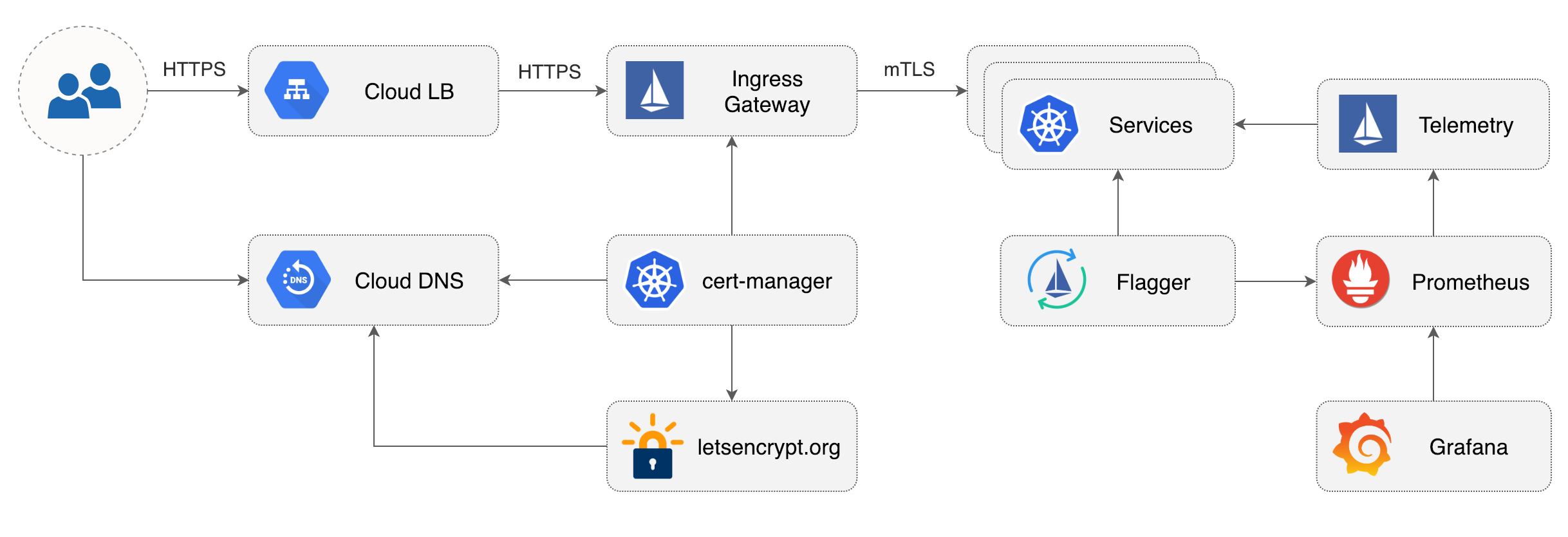
## Istio Gateway TLS setup
|
||||
|
||||
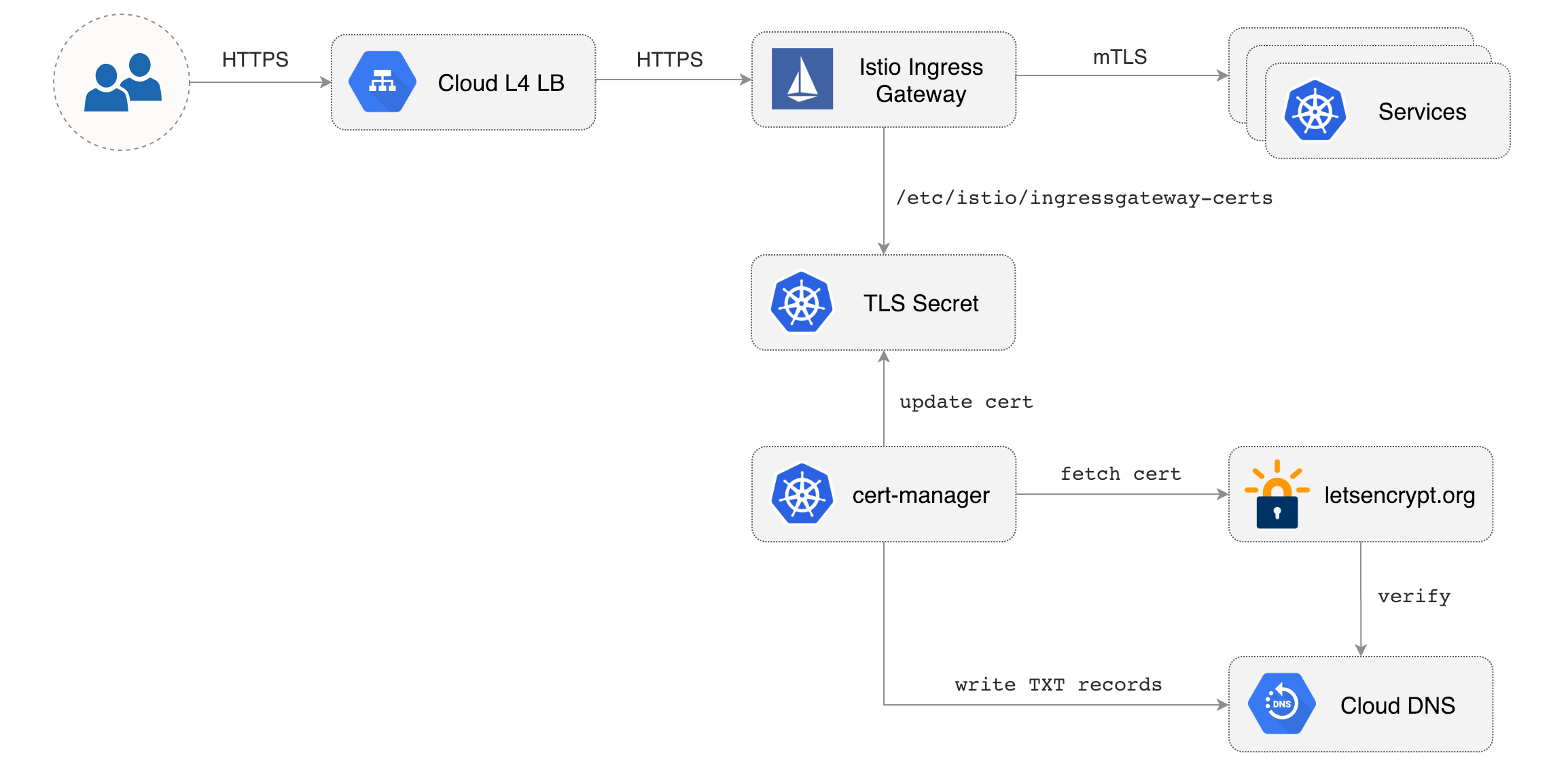
|
||||
|
||||
Create a generic Istio Gateway to expose services outside the mesh on HTTPS:
|
||||
|
||||
```bash
|
||||
REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/gke/istio-gateway.yaml
|
||||
```
|
||||
|
||||
Create a service account with Cloud DNS admin role \(replace `my-gcp-project` with your project ID\):
|
||||
|
||||
```bash
|
||||
GCP_PROJECT=my-gcp-project
|
||||
|
||||
gcloud iam service-accounts create dns-admin \
|
||||
--display-name=dns-admin \
|
||||
--project=${GCP_PROJECT}
|
||||
|
||||
gcloud iam service-accounts keys create ./gcp-dns-admin.json \
|
||||
--iam-account=dns-admin@${GCP_PROJECT}.iam.gserviceaccount.com \
|
||||
--project=${GCP_PROJECT}
|
||||
|
||||
gcloud projects add-iam-policy-binding ${GCP_PROJECT} \
|
||||
--member=serviceAccount:dns-admin@${GCP_PROJECT}.iam.gserviceaccount.com \
|
||||
--role=roles/dns.admin
|
||||
```
|
||||
|
||||
Create a Kubernetes secret with the GCP Cloud DNS admin key:
|
||||
|
||||
```bash
|
||||
kubectl create secret generic cert-manager-credentials \
|
||||
--from-file=./gcp-dns-admin.json \
|
||||
--namespace=istio-system
|
||||
```
|
||||
|
||||
Create a letsencrypt issuer for CloudDNS \(replace `email@example.com` with a valid email address and `my-gcp-project`with your project ID\):
|
||||
|
||||
```yaml
|
||||
apiVersion: certmanager.k8s.io/v1alpha1
|
||||
kind: Issuer
|
||||
metadata:
|
||||
name: letsencrypt-prod
|
||||
namespace: istio-system
|
||||
spec:
|
||||
acme:
|
||||
server: https://acme-v02.api.letsencrypt.org/directory
|
||||
email: email@example.com
|
||||
privateKeySecretRef:
|
||||
name: letsencrypt-prod
|
||||
dns01:
|
||||
providers:
|
||||
- name: cloud-dns
|
||||
clouddns:
|
||||
serviceAccountSecretRef:
|
||||
name: cert-manager-credentials
|
||||
key: gcp-dns-admin.json
|
||||
project: my-gcp-project
|
||||
```
|
||||
|
||||
Save the above resource as letsencrypt-issuer.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./letsencrypt-issuer.yaml
|
||||
```
|
||||
|
||||
Create a wildcard certificate \(replace `example.com` with your domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: certmanager.k8s.io/v1alpha1
|
||||
kind: Certificate
|
||||
metadata:
|
||||
name: istio-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
secretName: istio-ingressgateway-certs
|
||||
issuerRef:
|
||||
name: letsencrypt-prod
|
||||
commonName: "*.example.com"
|
||||
acme:
|
||||
config:
|
||||
- dns01:
|
||||
provider: cloud-dns
|
||||
domains:
|
||||
- "*.example.com"
|
||||
- "example.com"
|
||||
```
|
||||
|
||||
Save the above resource as istio-gateway-cert.yaml and then apply it:
|
||||
|
||||
```text
|
||||
kubectl apply -f ./istio-gateway-cert.yaml
|
||||
```
|
||||
|
||||
In a couple of seconds cert-manager should fetch a wildcard certificate from letsencrypt.org:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system describe certificate istio-gateway
|
||||
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal CertIssued 1m52s cert-manager Certificate issued successfully
|
||||
```
|
||||
|
||||
Recreate Istio ingress gateway pods:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system get pods -l istio=ingressgateway
|
||||
```
|
||||
|
||||
Note that Istio gateway doesn't reload the certificates from the TLS secret on cert-manager renewal. Since the GKE cluster is made out of preemptible VMs the gateway pods will be replaced once every 24h, if your not using preemptible nodes then you need to manually delete the gateway pods every two months before the certificate expires.
|
||||
|
||||
## Install Prometheus
|
||||
|
||||
The GKE Istio add-on does not include a Prometheus instance that scrapes the Istio telemetry service. Because Flagger uses the Istio HTTP metrics to run the canary analysis you have to deploy the following Prometheus configuration that's similar to the one that comes with the official Istio Helm chart.
|
||||
|
||||
Find the GKE Istio version with:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system get deploy istio-pilot -oyaml | grep image:
|
||||
```
|
||||
|
||||
Install Prometheus in istio-system namespace:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system apply -f \
|
||||
https://storage.googleapis.com/gke-release/istio/release/1.0.6-gke.3/patches/install-prometheus.yaml
|
||||
```
|
||||
|
||||
## Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install Flagger's Canary CRD:
|
||||
|
||||
```yaml
|
||||
kubectl apply -f https://raw.githubusercontent.com/weaveworks/flagger/master/artifacts/flagger/crd.yaml
|
||||
```
|
||||
|
||||
Deploy Flagger in the `istio-system` namespace with Slack notifications enabled:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set crd.create=false \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Deploy Grafana in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=replace-me
|
||||
```
|
||||
|
||||
Expose Grafana through the public gateway by creating a virtual service \(replace `example.com` with your domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: grafana
|
||||
namespace: istio-system
|
||||
spec:
|
||||
hosts:
|
||||
- "grafana.example.com"
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
http:
|
||||
- route:
|
||||
- destination:
|
||||
host: flagger-grafana
|
||||
```
|
||||
|
||||
Save the above resource as grafana-virtual-service.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./grafana-virtual-service.yaml
|
||||
```
|
||||
|
||||
Navigate to `http://grafana.example.com` in your browser and you should be redirected to the HTTPS version.
|
||||
|
||||
280
docs/install/flagger-install-on-kubernetes.md
Normal file
280
docs/install/flagger-install-on-kubernetes.md
Normal file
@@ -0,0 +1,280 @@
|
||||
# Flagger Install on Kubernetes
|
||||
|
||||
This guide walks you through setting up Flagger on a Kubernetes cluster with Helm v3 or Kustomize.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer.
|
||||
|
||||
## Install Flagger with Helm
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install Flagger's Canary CRD:
|
||||
|
||||
```yaml
|
||||
kubectl apply -f https://raw.githubusercontent.com/weaveworks/flagger/master/artifacts/flagger/crd.yaml
|
||||
```
|
||||
|
||||
Deploy Flagger for Istio:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set crd.create=false \
|
||||
--set meshProvider=istio \
|
||||
--set metricsServer=http://prometheus:9090
|
||||
```
|
||||
|
||||
Note that Flagger depends on Istio telemetry and Prometheus, if you're installing Istio with istioctl
|
||||
then you should be using the [default profile](https://istio.io/docs/setup/additional-setup/config-profiles/).
|
||||
|
||||
For Istio multi-cluster shared control plane you can install Flagger
|
||||
on each remote cluster and set the Istio control plane host cluster kubeconfig:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set crd.create=false \
|
||||
--set meshProvider=istio \
|
||||
--set metricsServer=http://istio-cluster-prometheus:9090 \
|
||||
--set istio.kubeconfig.secretName=istio-kubeconfig \
|
||||
--set istio.kubeconfig.key=kubeconfig
|
||||
```
|
||||
|
||||
Note that the Istio kubeconfig must be stored in a Kubernetes secret with a data key named `kubeconfig`.
|
||||
For more details on how to configure Istio multi-cluster credentials
|
||||
read the [Istio docs](https://istio.io/docs/setup/install/multicluster/shared-vpn/#credentials).
|
||||
|
||||
Deploy Flagger for Linkerd:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=linkerd \
|
||||
--set crd.create=false \
|
||||
--set meshProvider=linkerd \
|
||||
--set metricsServer=http://linkerd-prometheus:9090
|
||||
```
|
||||
|
||||
Deploy Flagger for App Mesh:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=appmesh-system \
|
||||
--set crd.create=false \
|
||||
--set meshProvider=appmesh \
|
||||
--set metricsServer=http://appmesh-prometheus:9090
|
||||
```
|
||||
|
||||
You can install Flagger in any namespace as long as it can talk to the Prometheus service on port 9090.
|
||||
|
||||
For ingress controllers, the install instructions are:
|
||||
|
||||
* [Contour](https://docs.flagger.app/tutorials/contour-progressive-delivery)
|
||||
* [Gloo](https://docs.flagger.app/tutorials/gloo-progressive-delivery)
|
||||
* [NGINX](https://docs.flagger.app/tutorials/nginx-progressive-delivery)
|
||||
|
||||
Enable **Slack** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set crd.create=false \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Enable **Microsoft Teams** notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set crd.create=false \
|
||||
--set msteams.url=https://outlook.office.com/webhook/YOUR/TEAMS/WEBHOOK
|
||||
```
|
||||
|
||||
You can use the helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm fetch --untar --untardir . flagger/flagger &&
|
||||
helm template flagger ./flagger \
|
||||
--namespace=istio-system \
|
||||
--set metricsServer=http://prometheus.istio-system:9090 \
|
||||
> flagger.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f flagger.yaml
|
||||
```
|
||||
|
||||
To uninstall the Flagger release with Helm run:
|
||||
|
||||
```text
|
||||
helm delete flagger
|
||||
```
|
||||
|
||||
The command removes all the Kubernetes components associated with the chart and deletes the release.
|
||||
|
||||
> **Note** that on uninstall the Canary CRD will not be removed. Deleting the CRD will make Kubernetes
|
||||
>remove all the objects owned by Flagger like Istio virtual services, Kubernetes deployments and ClusterIP services.
|
||||
|
||||
If you want to remove all the objects created by Flagger you have delete the Canary CRD with kubectl:
|
||||
|
||||
```text
|
||||
kubectl delete crd canaries.flagger.app
|
||||
```
|
||||
|
||||
## Install Grafana with Helm
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary analysis.
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090 \
|
||||
--set user=admin \
|
||||
--set password=change-me
|
||||
```
|
||||
|
||||
Or use helm template command and apply the generated yaml with kubectl:
|
||||
|
||||
```bash
|
||||
# generate
|
||||
helm fetch --untar --untardir . flagger/grafana &&
|
||||
helm template flagger-grafana ./grafana \
|
||||
--namespace=istio-system \
|
||||
> flagger-grafana.yaml
|
||||
|
||||
# apply
|
||||
kubectl apply -f flagger-grafana.yaml
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
## Install Flagger with Kustomize
|
||||
|
||||
As an alternative to Helm, Flagger can be installed with Kustomize.
|
||||
|
||||
**Service mesh specific installers**
|
||||
|
||||
Install Flagger for Istio:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/istio
|
||||
```
|
||||
|
||||
This deploys Flagger in the `istio-system` namespace and sets the metrics server URL to Istio's Prometheus instance.
|
||||
|
||||
Note that you'll need kubectl 1.14 to run the above the command or you can download
|
||||
the [kustomize binary](https://github.com/kubernetes-sigs/kustomize/releases) and run:
|
||||
|
||||
```bash
|
||||
kustomize build github.com/weaveworks/flagger//kustomize/istio | kubectl apply -f -
|
||||
```
|
||||
|
||||
Install Flagger for AWS App Mesh:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/appmesh
|
||||
```
|
||||
|
||||
This deploys Flagger and sets the metrics server URL to App Mesh's Prometheus instance.
|
||||
|
||||
Install Flagger for Linkerd:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/linkerd
|
||||
```
|
||||
|
||||
This deploys Flagger in the `linkerd` namespace and sets the metrics server URL to Linkerd's Prometheus instance.
|
||||
|
||||
If you want to install a specific Flagger release, add the version number to the URL:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/linkerd?ref=0.18.0
|
||||
```
|
||||
|
||||
**Generic installer**
|
||||
|
||||
Install Flagger and Prometheus:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/kubernetes
|
||||
```
|
||||
|
||||
This deploys Flagger and Prometheus in the `flagger-system` namespace, sets the metrics server URL
|
||||
to `http://flagger-prometheus.flagger-system:9090` and the mesh provider to `kubernetes`.
|
||||
|
||||
The Prometheus instance has a two hours data retention and is configured to scrape all pods in your cluster
|
||||
that have the `prometheus.io/scrape: "true"` annotation.
|
||||
|
||||
To target a different provider you can specify it in the canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: app
|
||||
namespace: test
|
||||
spec:
|
||||
# can be: kubernetes, istio, linkerd, appmesh, nginx, gloo
|
||||
# use the kubernetes provider for Blue/Green style deployments
|
||||
provider: nginx
|
||||
```
|
||||
|
||||
**Customized installer**
|
||||
|
||||
Create a kustomization file using flagger as base:
|
||||
|
||||
```bash
|
||||
cat > kustomization.yaml <<EOF
|
||||
namespace: istio-system
|
||||
bases:
|
||||
- github.com/weaveworks/flagger/kustomize/base/flagger
|
||||
patchesStrategicMerge:
|
||||
- patch.yaml
|
||||
EOF
|
||||
```
|
||||
|
||||
Create a patch and enable Slack notifications by setting the slack channel and hook URL:
|
||||
|
||||
```bash
|
||||
cat > patch.yaml <<EOF
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: flagger
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: flagger
|
||||
args:
|
||||
- -mesh-provider=istio
|
||||
- -metrics-server=http://prometheus.istio-system:9090
|
||||
- -slack-user=flagger
|
||||
- -slack-channel=alerts
|
||||
- -slack-url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK
|
||||
EOF
|
||||
```
|
||||
|
||||
Install Flagger with Slack:
|
||||
|
||||
```bash
|
||||
kubectl apply -k .
|
||||
```
|
||||
|
||||
If you want to use MS Teams instead of Slack, replace `-slack-url` with `-msteams-url` and set the webhook address
|
||||
to `https://outlook.office.com/webhook/YOUR/TEAMS/WEBHOOK`.
|
||||
|
||||
39
docs/intro/README.md
Normal file
39
docs/intro/README.md
Normal file
@@ -0,0 +1,39 @@
|
||||
# Introduction
|
||||
|
||||
[Flagger](https://github.com/weaveworks/flagger) is a **Kubernetes** operator that automates the promotion of
|
||||
canary deployments using **Istio**, **Linkerd**, **App Mesh**, **NGINX**, **Contour** or **Gloo** routing for
|
||||
traffic shifting and **Prometheus** metrics for canary analysis. The canary analysis can be extended with webhooks for
|
||||
running system integration/acceptance tests, load tests, or any other custom validation.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators
|
||||
like HTTP requests success rate, requests average duration and pods health.
|
||||
Based on analysis of the **KPIs** a canary is promoted or aborted, and the analysis result is published to **Slack** or **MS Teams**.
|
||||
|
||||
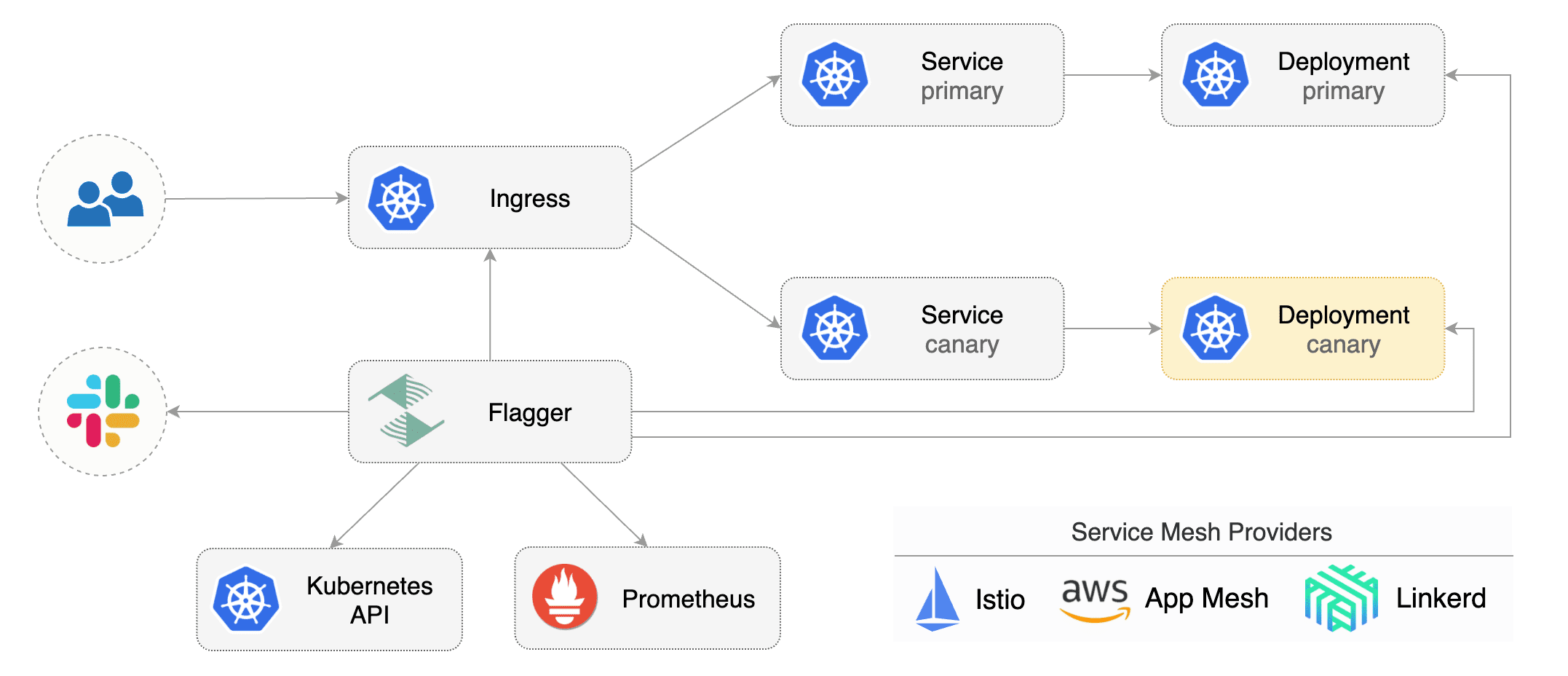
|
||||
|
||||
Flagger can be configured with Kubernetes custom resources and is compatible with any CI/CD solutions made for Kubernetes.
|
||||
Since Flagger is declarative and reacts to Kubernetes events,
|
||||
it can be used in **GitOps** pipelines together with Flux CD or JenkinsX.
|
||||
|
||||
To get started with Flagger, chose one of the supported routing providers
|
||||
and [install](../install/flagger-install-on-kubernetes) Flagger with Helm or Kustomize.
|
||||
|
||||
After install Flagger, you can follow one of the tutorials:
|
||||
|
||||
**Service mesh tutorials**
|
||||
|
||||
* [Istio](../tutorials/istio-progressive-delivery)
|
||||
* [Linkerd](../tutorials/linkerd-progressive-delivery)
|
||||
* [AWS App Mesh](../tutorials/appmesh-progressive-delivery)
|
||||
|
||||
**Ingress controller tutorials**
|
||||
|
||||
* [Contour](../tutorials/contour-progressive-delivery)
|
||||
* [Gloo](../tutorials/gloo-progressive-delivery)
|
||||
* [NGINX Ingress](../tutorials/nginx-progressive-delivery)
|
||||
|
||||
**Hands-on GitOps workshops**
|
||||
|
||||
* [Istio](https://github.com/stefanprodan/gitops-istio)
|
||||
* [Linkerd](https://helm.workshop.flagger.dev)
|
||||
* [AWS App Mesh](https://eks.hands-on.flagger.dev)
|
||||
640
docs/intro/faq.md
Normal file
640
docs/intro/faq.md
Normal file
@@ -0,0 +1,640 @@
|
||||
# Frequently asked questions
|
||||
|
||||
## Deployment Strategies
|
||||
|
||||
**Which deployment strategies are supported by Flagger?**
|
||||
|
||||
Flagger implements the following deployment strategies:
|
||||
* [Canary Release](../usage/deployment-strategies.md#canary-release)
|
||||
* [A/B Testing](../usage/deployment-strategies.md#a-b-testing)
|
||||
* [Blue/Green](../usage/deployment-strategies.md#blue-green-deployments)
|
||||
* [Blue/Green Mirroring](../usage/deployment-strategies.md#blue-green-with-traffic-mirroring)
|
||||
|
||||
**When should I use A/B testing instead of progressive traffic shifting?**
|
||||
|
||||
For frontend applications that require session affinity you should use HTTP headers or cookies match conditions
|
||||
to ensure a set of users will stay on the same version for the whole duration of the canary analysis.
|
||||
|
||||
**Can I use Flagger to manage applications that live outside of a service mesh?**
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate Blue/Green style deployments
|
||||
with Kubernetes L4 networking.
|
||||
|
||||
**When can I use traffic mirroring?**
|
||||
|
||||
Traffic mirroring can be used for Blue/Green deployment strategy or a pre-stage in a Canary release.
|
||||
Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service.
|
||||
Mirroring should be used for requests that are **idempotent** or capable of being processed twice (once by the primary and once by the canary).
|
||||
|
||||
## Kubernetes services
|
||||
|
||||
**How is an application exposed inside the cluster?**
|
||||
|
||||
Assuming the app name is podinfo you can define a canary like:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
service:
|
||||
# service name (optional)
|
||||
name: podinfo
|
||||
# ClusterIP port number (required)
|
||||
port: 9898
|
||||
# container port name or number
|
||||
targetPort: http
|
||||
# port name can be http or grpc (default http)
|
||||
portName: http
|
||||
```
|
||||
|
||||
If the `service.name` is not specified, then `targetRef.name` is used for the apex domain and canary/primary services name prefix.
|
||||
You should treat the service name as an immutable field, changing it could result in routing conflicts.
|
||||
|
||||
Based on the canary spec service, Flagger generates the following Kubernetes ClusterIP service:
|
||||
|
||||
* `<service.name>.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>-primary`
|
||||
* `<service.name>-primary.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>-primary`
|
||||
* `<service.name>-canary.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>`
|
||||
|
||||
This ensures that traffic coming from a namespace outside the mesh to `podinfo.test:9898`
|
||||
will be routed to the latest stable release of your app.
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: podinfo
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
app: podinfo-primary
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: http
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: podinfo-primary
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
app: podinfo-primary
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: http
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: podinfo-canary
|
||||
spec:
|
||||
type: ClusterIP
|
||||
selector:
|
||||
app: podinfo
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: http
|
||||
```
|
||||
|
||||
The `podinfo-canary.test:9898` address is available only during the
|
||||
canary analysis and can be used for conformance testing or load testing.
|
||||
|
||||
## Multiple ports
|
||||
|
||||
**My application listens on multiple ports, how can I expose them inside the cluster?**
|
||||
|
||||
If port discovery is enabled, Flagger scans the deployment spec and extracts the containers
|
||||
ports excluding the port specified in the canary service and Envoy sidecar ports.
|
||||
These ports will be used when generating the ClusterIP services.
|
||||
|
||||
For a deployment that exposes two ports:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
metadata:
|
||||
annotations:
|
||||
prometheus.io/scrape: "true"
|
||||
prometheus.io/port: "9899"
|
||||
spec:
|
||||
containers:
|
||||
- name: app
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
- containerPort: 9090
|
||||
```
|
||||
|
||||
You can enable port discovery so that Prometheus will be able to reach port `9090` over mTLS:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
# container port used for canary analysis
|
||||
port: 8080
|
||||
# port name can be http or grpc (default http)
|
||||
portName: http
|
||||
# add all the other container ports
|
||||
# to the ClusterIP services (default false)
|
||||
portDiscovery: true
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: ISTIO_MUTUAL
|
||||
```
|
||||
|
||||
Both port `8080` and `9090` will be added to the ClusterIP services.
|
||||
|
||||
## Label selectors
|
||||
|
||||
**What labels selectors are supported by Flagger?**
|
||||
|
||||
The target deployment must have a single label selector in the format `app: <DEPLOYMENT-NAME>`:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: podinfo
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: podinfo
|
||||
```
|
||||
|
||||
Besides `app` Flagger supports `name` and `app.kubernetes.io/name` selectors. If you use a different
|
||||
convention you can specify your label with the `-selector-labels` flag.
|
||||
|
||||
**Is pod affinity and anti affinity supported?**
|
||||
|
||||
For pod affinity to work you need to use a different label than the `app`, `name` or `app.kubernetes.io/name`.
|
||||
|
||||
Anti affinity example:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: podinfo
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
affinity: podinfo
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: podinfo
|
||||
affinity: podinfo
|
||||
spec:
|
||||
affinity:
|
||||
podAntiAffinity:
|
||||
preferredDuringSchedulingIgnoredDuringExecution:
|
||||
- weight: 100
|
||||
podAffinityTerm:
|
||||
labelSelector:
|
||||
matchLabels:
|
||||
affinity: podinfo
|
||||
topologyKey: kubernetes.io/hostname
|
||||
```
|
||||
|
||||
## Metrics
|
||||
|
||||
**How does Flagger measures the request success rate and duration?**
|
||||
|
||||
Flagger measures the request success rate and duration using Prometheus queries.
|
||||
|
||||
**HTTP requests success rate percentage**
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
Istio query:
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload",
|
||||
response_code!~"5.*"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace=~"$namespace",
|
||||
destination_workload=~"$workload"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
Envoy query (App Mesh, Contour or Gloo):
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="$namespace",
|
||||
kubernetes_pod_name=~"$workload",
|
||||
envoy_response_code!~"5.*"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="$namespace",
|
||||
kubernetes_pod_name=~"$workload"
|
||||
}[$interval]
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
**HTTP requests milliseconds duration P99**
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
Istio query:
|
||||
|
||||
```javascript
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
irate(
|
||||
istio_request_duration_seconds_bucket{
|
||||
reporter="destination",
|
||||
destination_workload=~"$workload",
|
||||
destination_workload_namespace=~"$namespace"
|
||||
}[$interval]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
Envoy query (App Mesh, Contour or Gloo):
|
||||
|
||||
```javascript
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
irate(
|
||||
envoy_cluster_upstream_rq_time_bucket{
|
||||
kubernetes_pod_name=~"$workload",
|
||||
kubernetes_namespace=~"$namespace"
|
||||
}[$interval]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
> **Note** that the metric interval should be lower or equal to the control loop interval.
|
||||
|
||||
**Can I use custom metrics?**
|
||||
|
||||
The analysis can be extended with metrics provided by Prometheus, Datadog and AWS CloudWatch. For more details
|
||||
on how custom metrics can be used please read the [metrics docs](../usage/metrics.md).
|
||||
|
||||
## Istio routing
|
||||
|
||||
**How does Flagger interact with Istio?**
|
||||
|
||||
Flagger creates an Istio Virtual Service and Destination Rules based on the Canary service spec.
|
||||
The service configuration lets you expose an app inside or outside the mesh.
|
||||
You can also define traffic policies, HTTP match conditions, URI rewrite rules, CORS policies, timeout and retries.
|
||||
|
||||
The following spec exposes the `frontend` workload inside the mesh on `frontend.test.svc.cluster.local:9898`
|
||||
and outside the mesh on `frontend.example.com`. You'll have to specify an Istio ingress gateway for external hosts.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# service port name (optional, will default to "http")
|
||||
portName: http-frontend
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
# Istio traffic policy
|
||||
trafficPolicy:
|
||||
tls:
|
||||
# use ISTIO_MUTUAL when mTLS is enabled
|
||||
mode: DISABLE
|
||||
# HTTP match conditions (optional)
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
# HTTP rewrite (optional)
|
||||
rewrite:
|
||||
uri: /
|
||||
# Istio retry policy (optional)
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 1s
|
||||
retryOn: "gateway-error,connect-failure,refused-stream"
|
||||
# Add headers (optional)
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-some-header: "value"
|
||||
# cross-origin resource sharing policy (optional)
|
||||
corsPolicy:
|
||||
allowOrigin:
|
||||
- example.com
|
||||
allowMethods:
|
||||
- GET
|
||||
allowCredentials: false
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
maxAge: 24h
|
||||
```
|
||||
|
||||
For the above spec Flagger will generate the following virtual service:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1beta1
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: podinfo
|
||||
uid: 3a4a40dd-3875-11e9-8e1d-42010a9c0fd1
|
||||
spec:
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
- mesh
|
||||
hosts:
|
||||
- frontend.example.com
|
||||
- frontend
|
||||
http:
|
||||
- corsPolicy:
|
||||
allowHeaders:
|
||||
- x-some-header
|
||||
allowMethods:
|
||||
- GET
|
||||
allowOrigin:
|
||||
- example.com
|
||||
maxAge: 24h
|
||||
headers:
|
||||
request:
|
||||
add:
|
||||
x-some-header: "value"
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
rewrite:
|
||||
uri: /
|
||||
route:
|
||||
- destination:
|
||||
host: podinfo-primary
|
||||
weight: 100
|
||||
- destination:
|
||||
host: podinfo-canary
|
||||
weight: 0
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 1s
|
||||
retryOn: "gateway-error,connect-failure,refused-stream"
|
||||
```
|
||||
|
||||
For each destination in the virtual service a rule is generated:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: DestinationRule
|
||||
metadata:
|
||||
name: frontend-primary
|
||||
namespace: test
|
||||
spec:
|
||||
host: frontend-primary
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: DISABLE
|
||||
---
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: DestinationRule
|
||||
metadata:
|
||||
name: frontend-canary
|
||||
namespace: test
|
||||
spec:
|
||||
host: frontend-canary
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: DISABLE
|
||||
```
|
||||
|
||||
Flagger keeps in sync the virtual service and destination rules with the canary service spec.
|
||||
Any direct modification to the virtual service spec will be overwritten.
|
||||
|
||||
To expose a workload inside the mesh on `http://backend.test.svc.cluster.local:9898`,
|
||||
the service spec can contain only the container port and the traffic policy:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: backend
|
||||
namespace: test
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: DISABLE
|
||||
```
|
||||
|
||||
Based on the above spec, Flagger will create several ClusterIP services like:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: backend-primary
|
||||
ownerReferences:
|
||||
- apiVersion: flagger.app/v1beta1
|
||||
blockOwnerDeletion: true
|
||||
controller: true
|
||||
kind: Canary
|
||||
name: backend
|
||||
uid: 2ca1a9c7-2ef6-11e9-bd01-42010a9c0145
|
||||
spec:
|
||||
type: ClusterIP
|
||||
ports:
|
||||
- name: http
|
||||
port: 9898
|
||||
protocol: TCP
|
||||
targetPort: 9898
|
||||
selector:
|
||||
app: backend-primary
|
||||
```
|
||||
|
||||
Flagger works for user facing apps exposed outside the cluster via an ingress gateway
|
||||
and for backend HTTP APIs that are accessible only from inside the mesh.
|
||||
|
||||
## Istio Ingress Gateway
|
||||
|
||||
**How can I expose multiple canaries on the same external domain?**
|
||||
|
||||
Assuming you have two apps, one that servers the main website and one that serves the REST API.
|
||||
For each app you can define a canary object as:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: website
|
||||
spec:
|
||||
service:
|
||||
port: 8080
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
hosts:
|
||||
- my-site.com
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
rewrite:
|
||||
uri: /
|
||||
---
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: webapi
|
||||
spec:
|
||||
service:
|
||||
port: 8080
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
hosts:
|
||||
- my-site.com
|
||||
match:
|
||||
- uri:
|
||||
prefix: /api
|
||||
rewrite:
|
||||
uri: /
|
||||
```
|
||||
|
||||
Based on the above configuration, Flagger will create two virtual services bounded to the same ingress gateway and external host.
|
||||
Istio Pilot will [merge](https://istio.io/help/ops/traffic-management/deploy-guidelines/#multiple-virtual-services-and-destination-rules-for-the-same-host)
|
||||
the two services and the website rule will be moved to the end of the list in the merged configuration.
|
||||
|
||||
Note that host merging only works if the canaries are bounded to a ingress gateway other than the `mesh` gateway.
|
||||
|
||||
## Istio Mutual TLS
|
||||
|
||||
**How can I enable mTLS for a canary?**
|
||||
|
||||
When deploying Istio with global mTLS enabled, you have to set the TLS mode to `ISTIO_MUTUAL`:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: ISTIO_MUTUAL
|
||||
```
|
||||
|
||||
If you run Istio in permissive mode you can disable TLS:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: DISABLE
|
||||
```
|
||||
|
||||
**If Flagger is outside of the mesh, how can it start the load test?**
|
||||
|
||||
In order for Flagger to be able to call the load tester service from outside the mesh, you need to disable mTLS on port 80:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: DestinationRule
|
||||
metadata:
|
||||
name: flagger-loadtester
|
||||
namespace: test
|
||||
spec:
|
||||
host: "flagger-loadtester.test.svc.cluster.local"
|
||||
trafficPolicy:
|
||||
tls:
|
||||
mode: DISABLE
|
||||
---
|
||||
apiVersion: authentication.istio.io/v1alpha1
|
||||
kind: Policy
|
||||
metadata:
|
||||
name: flagger-loadtester
|
||||
namespace: test
|
||||
spec:
|
||||
targets:
|
||||
- name: flagger-loadtester
|
||||
ports:
|
||||
- number: 80
|
||||
```
|
||||
0
docs/tutorials/README.md
Normal file
0
docs/tutorials/README.md
Normal file
394
docs/tutorials/appmesh-progressive-delivery.md
Normal file
394
docs/tutorials/appmesh-progressive-delivery.md
Normal file
@@ -0,0 +1,394 @@
|
||||
# App Mesh Canary Deployments
|
||||
|
||||
This guide shows you how to use App Mesh and Flagger to automate canary deployments. You'll need an EKS cluster configured with App Mesh, you can find the install guide [here](https://docs.flagger.app/install/flagger-install-on-eks-appmesh).
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services, App Mesh virtual nodes and services\). These objects expose the application on the mesh and drive the canary analysis and promotion. The only App Mesh object you need to create by yourself is the mesh resource.
|
||||
|
||||
Create a mesh called `global`:
|
||||
|
||||
```bash
|
||||
cat << EOF | kubectl apply -f -
|
||||
apiVersion: appmesh.k8s.aws/v1beta1
|
||||
kind: Mesh
|
||||
metadata:
|
||||
name: global
|
||||
spec:
|
||||
serviceDiscoveryType: dns
|
||||
EOF
|
||||
```
|
||||
|
||||
Create a test namespace with App Mesh sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
cat << EOF | kubectl apply -f -
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: test
|
||||
labels:
|
||||
appmesh.k8s.aws/sidecarInjectorWebhook: enabled
|
||||
EOF
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set meshName=global \
|
||||
--set "backends[0]=podinfo.test" \
|
||||
--set "backends[1]=podinfo-canary.test"
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# container port name (optional)
|
||||
# can be http or grpc
|
||||
portName: http
|
||||
# App Mesh reference
|
||||
meshName: global
|
||||
# App Mesh ingress (optional)
|
||||
hosts:
|
||||
- "*"
|
||||
# App Mesh ingress timeout (optional)
|
||||
timeout: 5s
|
||||
# App Mesh egress (optional)
|
||||
backends:
|
||||
- backend.test
|
||||
# App Mesh retry policy (optional)
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 5s
|
||||
retryOn: "gateway-error,client-error,stream-error"
|
||||
# define the canary analysis timing and KPIs
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# App Mesh Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary.test:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated Kubernetes objects
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
|
||||
# generated App Mesh objects
|
||||
virtualnode.appmesh.k8s.aws/podinfo
|
||||
virtualnode.appmesh.k8s.aws/podinfo-canary
|
||||
virtualnode.appmesh.k8s.aws/podinfo-primary
|
||||
virtualservice.appmesh.k8s.aws/podinfo.test
|
||||
virtualservice.appmesh.k8s.aws/podinfo-canary.test
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
The App Mesh specific settings are:
|
||||
|
||||
```yaml
|
||||
service:
|
||||
port: 9898
|
||||
meshName: global
|
||||
backends:
|
||||
- backend1.test
|
||||
- backend2.test
|
||||
```
|
||||
|
||||
App Mesh blocks all egress traffic by default. If your application needs to call another service, you have to create an App Mesh virtual service for it and add the virtual service name to the backend list.
|
||||
|
||||
## Setup App Mesh Gateway \(optional\)
|
||||
|
||||
In order to expose the podinfo app outside the mesh you'll be using an Envoy-powered ingress gateway and an AWS network load balancer. The gateway binds to an internet domain and forwards the calls into the mesh through the App Mesh sidecar. If podinfo becomes unavailable due to a cluster downscaling or a node restart, the gateway will retry the calls for a short period of time.
|
||||
|
||||
Deploy the gateway behind an AWS NLB:
|
||||
|
||||
```bash
|
||||
helm upgrade -i appmesh-gateway flagger/appmesh-gateway \
|
||||
--namespace test \
|
||||
--set mesh.name=global
|
||||
```
|
||||
|
||||
Find the gateway public address:
|
||||
|
||||
```bash
|
||||
export URL="http://$(kubectl -n test get svc/appmesh-gateway -ojson | jq -r ".status.loadBalancer.ingress[].hostname")"
|
||||
echo $URL
|
||||
```
|
||||
|
||||
Wait for the NLB to become active:
|
||||
|
||||
```bash
|
||||
watch curl -sS $URL
|
||||
```
|
||||
|
||||
Open your browser and navigate to the ingress address to access podinfo UI.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
New revision detected! Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
During the analysis the canary’s progress can be monitored with Grafana. The App Mesh dashboard URL is [http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo](http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo)
|
||||
|
||||

|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-10-02T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-10-02T16:15:07Z
|
||||
prod backend Failed 0 2019-10-02T17:05:07Z
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors or high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger a canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it deploy/flagger-loadtester bash
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
hey -z 1m -c 5 -q 5 http://podinfo-canary.test:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl http://podinfo-canary.test:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n appmesh-system logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Starting canary analysis for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Halt podinfo.test advancement request duration 1.20s > 0.5s
|
||||
Halt podinfo.test advancement request duration 1.45s > 0.5s
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded, or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
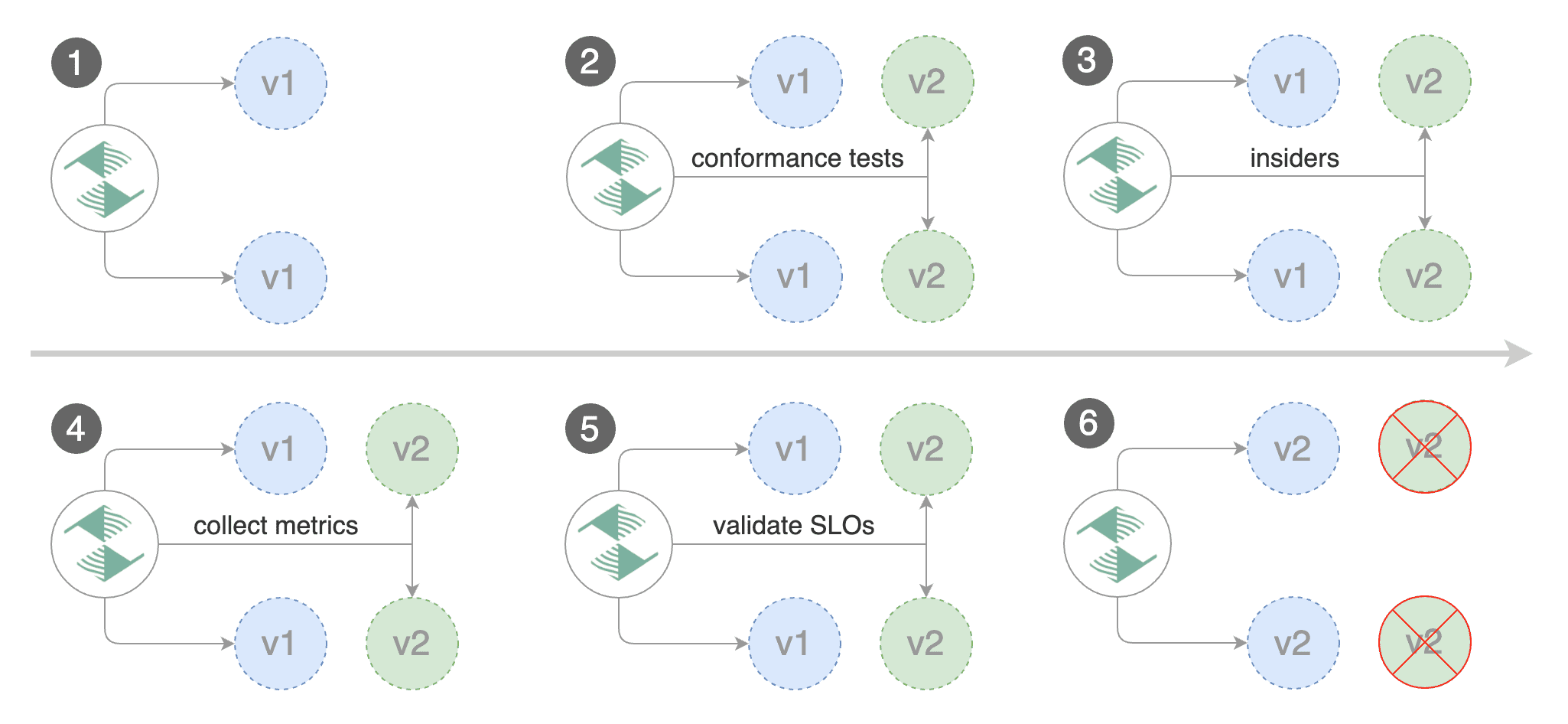
|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 5
|
||||
iterations: 10
|
||||
match:
|
||||
- headers:
|
||||
x-canary:
|
||||
exact: "insider"
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'X-Canary: insider' http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `X-Canary: insider` header.
|
||||
|
||||
You can also use a HTTP cookie, to target all users with a `canary` cookie set to `insider` the match condition should be:
|
||||
|
||||
```yaml
|
||||
match:
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(canary=insider)(;.*)?$"
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: canary=insider' http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the A/B test:
|
||||
|
||||
```text
|
||||
kubectl -n appmesh-system logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Starting canary analysis for podinfo.test
|
||||
Advance podinfo.test canary iteration 1/10
|
||||
Advance podinfo.test canary iteration 2/10
|
||||
Advance podinfo.test canary iteration 3/10
|
||||
Advance podinfo.test canary iteration 4/10
|
||||
Advance podinfo.test canary iteration 5/10
|
||||
Advance podinfo.test canary iteration 6/10
|
||||
Advance podinfo.test canary iteration 7/10
|
||||
Advance podinfo.test canary iteration 8/10
|
||||
Advance podinfo.test canary iteration 9/10
|
||||
Advance podinfo.test canary iteration 10/10
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
356
docs/tutorials/canary-helm-gitops.md
Normal file
356
docs/tutorials/canary-helm-gitops.md
Normal file
@@ -0,0 +1,356 @@
|
||||
# Canaries with Helm charts and GitOps
|
||||
|
||||
This guide shows you how to package a web app into a Helm chart, trigger canary deployments on Helm upgrade and automate the chart release process with Weave Flux.
|
||||
|
||||
## Packaging
|
||||
|
||||
You'll be using the [podinfo](https://github.com/stefanprodan/k8s-podinfo) chart. This chart packages a web app made with Go, it's configuration, a horizontal pod autoscaler \(HPA\) and the canary configuration file.
|
||||
|
||||
```text
|
||||
├── Chart.yaml
|
||||
├── README.md
|
||||
├── templates
|
||||
│ ├── NOTES.txt
|
||||
│ ├── _helpers.tpl
|
||||
│ ├── canary.yaml
|
||||
│ ├── configmap.yaml
|
||||
│ ├── deployment.yaml
|
||||
│ ├── hpa.yaml
|
||||
│ ├── service.yaml
|
||||
│ └── tests
|
||||
│ ├── test-config.yaml
|
||||
│ └── test-pod.yaml
|
||||
└── values.yaml
|
||||
```
|
||||
|
||||
You can find the chart source [here](https://github.com/stefanprodan/flagger/tree/master/charts/podinfo).
|
||||
|
||||
## Install
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Install podinfo with the release name `frontend` \(replace `example.com` with your own domain\):
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=frontend \
|
||||
--set backend=http://backend.test:9898/echo \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=true \
|
||||
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
||||
--set canary.istioIngress.host=frontend.istio.example.com
|
||||
```
|
||||
|
||||
Flagger takes a Kubernetes deployment and a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and Istio virtual services\). These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
|
||||
```bash
|
||||
# generated by Helm
|
||||
configmap/frontend
|
||||
deployment.apps/frontend
|
||||
horizontalpodautoscaler.autoscaling/frontend
|
||||
canary.flagger.app/frontend
|
||||
|
||||
# generated by Flagger
|
||||
configmap/frontend-primary
|
||||
deployment.apps/frontend-primary
|
||||
horizontalpodautoscaler.autoscaling/frontend-primary
|
||||
service/frontend
|
||||
service/frontend-canary
|
||||
service/frontend-primary
|
||||
virtualservice.networking.istio.io/frontend
|
||||
```
|
||||
|
||||
When the `frontend-primary` deployment comes online, Flagger will route all traffic to the primary pods and scale to zero the `frontend` deployment.
|
||||
|
||||
Open your browser and navigate to the frontend URL:
|
||||
|
||||

|
||||
|
||||
Now let's install the `backend` release without exposing it outside the mesh:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo \
|
||||
--namespace test \
|
||||
--set nameOverride=backend \
|
||||
--set canary.enabled=true \
|
||||
--set canary.istioIngress.enabled=false
|
||||
```
|
||||
|
||||
Check if Flagger has successfully deployed the canaries:
|
||||
|
||||
```text
|
||||
kubectl -n test get canaries
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Initialized 0 2019-02-12T18:53:18Z
|
||||
frontend Initialized 0 2019-02-12T17:50:50Z
|
||||
```
|
||||
|
||||
Click on the ping button in the `frontend` UI to trigger a HTTP POST request that will reach the `backend` app:
|
||||
|
||||

|
||||
|
||||
We'll use the `/echo` endpoint \(same as the one the ping button calls\) to generate load on both apps during a canary deployment.
|
||||
|
||||
## Upgrade
|
||||
|
||||
First let's install a load testing service that will generate traffic during analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Install Flagger's helm test runner in the `kube-system` using `tiller` service account:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-helmtester flagger/loadtester \
|
||||
--namespace=kube-system \
|
||||
--set serviceAccountName=tiller
|
||||
```
|
||||
|
||||
Enable the load and helm tester and deploy a new `frontend` version:
|
||||
|
||||
```bash
|
||||
helm upgrade -i frontend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set canary.helmtest.enabled=true \
|
||||
--set image.tag=3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the canary analysis:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system logs deployment/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Scaling up frontend.test
|
||||
Halt advancement frontend.test waiting for rollout to finish: 0 of 2 updated replicas are available
|
||||
Starting canary analysis for frontend.test
|
||||
Pre-rollout check helm test passed
|
||||
Advance frontend.test canary weight 5
|
||||
Advance frontend.test canary weight 10
|
||||
Advance frontend.test canary weight 15
|
||||
Advance frontend.test canary weight 20
|
||||
Advance frontend.test canary weight 25
|
||||
Advance frontend.test canary weight 30
|
||||
Advance frontend.test canary weight 35
|
||||
Advance frontend.test canary weight 40
|
||||
Advance frontend.test canary weight 45
|
||||
Advance frontend.test canary weight 50
|
||||
Copying frontend.test template spec to frontend-primary.test
|
||||
Halt advancement frontend-primary.test waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Promotion completed! Scaling down frontend.test
|
||||
```
|
||||
|
||||
You can monitor the canary deployment with Grafana. Open the Flagger dashboard, select `test` from the namespace dropdown, `frontend-primary` from the primary dropdown and `frontend` from the canary dropdown.
|
||||
|
||||
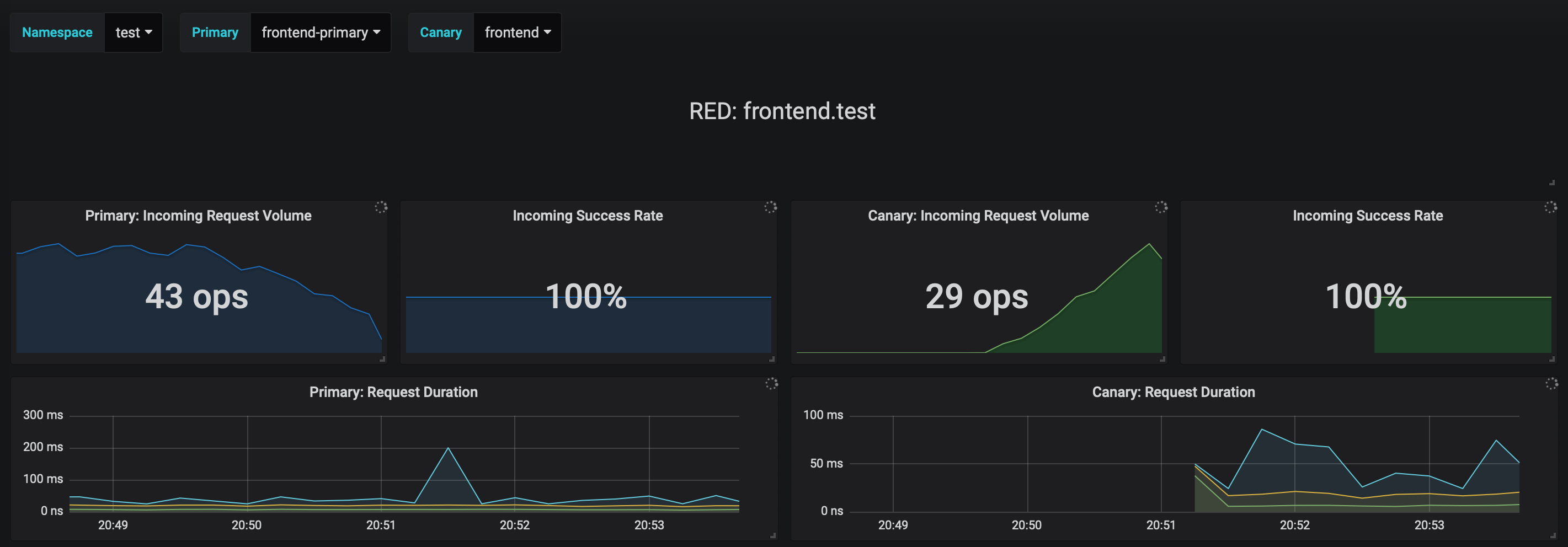
|
||||
|
||||
Now trigger a canary deployment for the `backend` app, but this time you'll change a value in the configmap:
|
||||
|
||||
```bash
|
||||
helm upgrade -i backend flagger/podinfo/ \
|
||||
--namespace test \
|
||||
--reuse-values \
|
||||
--set canary.loadtest.enabled=true \
|
||||
--set canary.helmtest.enabled=true \
|
||||
--set httpServer.timeout=25s
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
||||
|
||||
watch curl http://backend-canary:9898/delay/1
|
||||
```
|
||||
|
||||
Flagger detects the config map change and starts a canary analysis. Flagger will pause the advancement when the HTTP success rate drops under 99% or when the average request duration in the last minute is over 500ms:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary backend
|
||||
|
||||
Events:
|
||||
|
||||
ConfigMap backend has changed
|
||||
New revision detected! Scaling up backend.test
|
||||
Starting canary analysis for backend.test
|
||||
Advance backend.test canary weight 5
|
||||
Advance backend.test canary weight 10
|
||||
Advance backend.test canary weight 15
|
||||
Advance backend.test canary weight 20
|
||||
Advance backend.test canary weight 25
|
||||
Advance backend.test canary weight 30
|
||||
Advance backend.test canary weight 35
|
||||
Halt backend.test advancement success rate 62.50% < 99%
|
||||
Halt backend.test advancement success rate 88.24% < 99%
|
||||
Advance backend.test canary weight 40
|
||||
Advance backend.test canary weight 45
|
||||
Halt backend.test advancement request duration 2.415s > 500ms
|
||||
Halt backend.test advancement request duration 2.42s > 500ms
|
||||
Advance backend.test canary weight 50
|
||||
ConfigMap backend-primary synced
|
||||
Copying backend.test template spec to backend-primary.test
|
||||
Promotion completed! Scaling down backend.test
|
||||
```
|
||||
|
||||
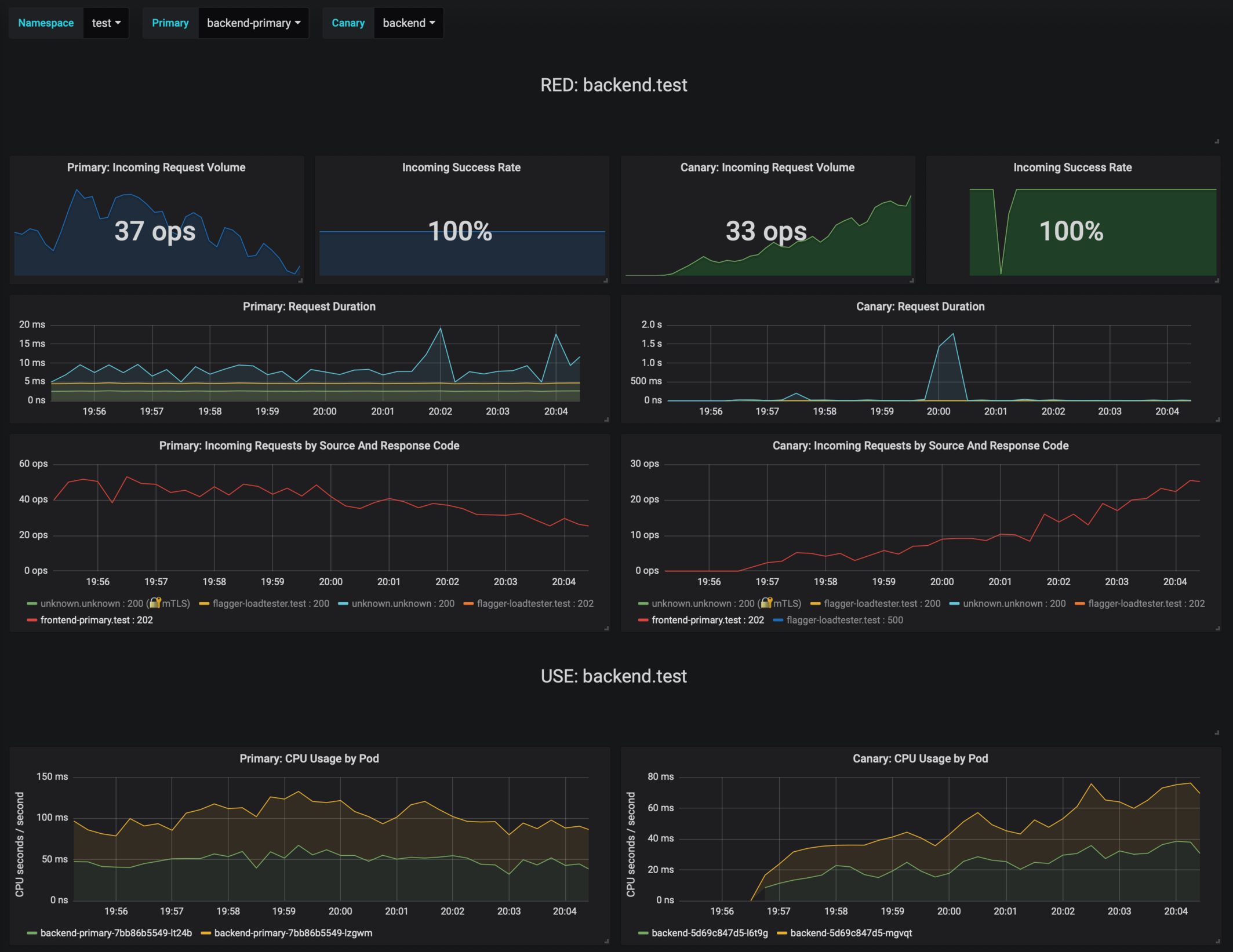
|
||||
|
||||
If the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```bash
|
||||
kubectl -n test get canary
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
backend Succeeded 0 2019-02-12T19:33:11Z
|
||||
frontend Failed 0 2019-02-12T19:47:20Z
|
||||
```
|
||||
|
||||
If you've enabled the Slack notifications, you'll receive an alert with the reason why the `backend` promotion failed.
|
||||
|
||||
## GitOps automation
|
||||
|
||||
Instead of using Helm CLI from a CI tool to perform the install and upgrade, you could use a Git based approach. GitOps is a way to do Continuous Delivery, it works by using Git as a source of truth for declarative infrastructure and workloads. In the [GitOps model](https://www.weave.works/technologies/gitops/), any change to production must be committed in source control prior to being applied on the cluster. This way rollback and audit logs are provided by Git.
|
||||
|
||||
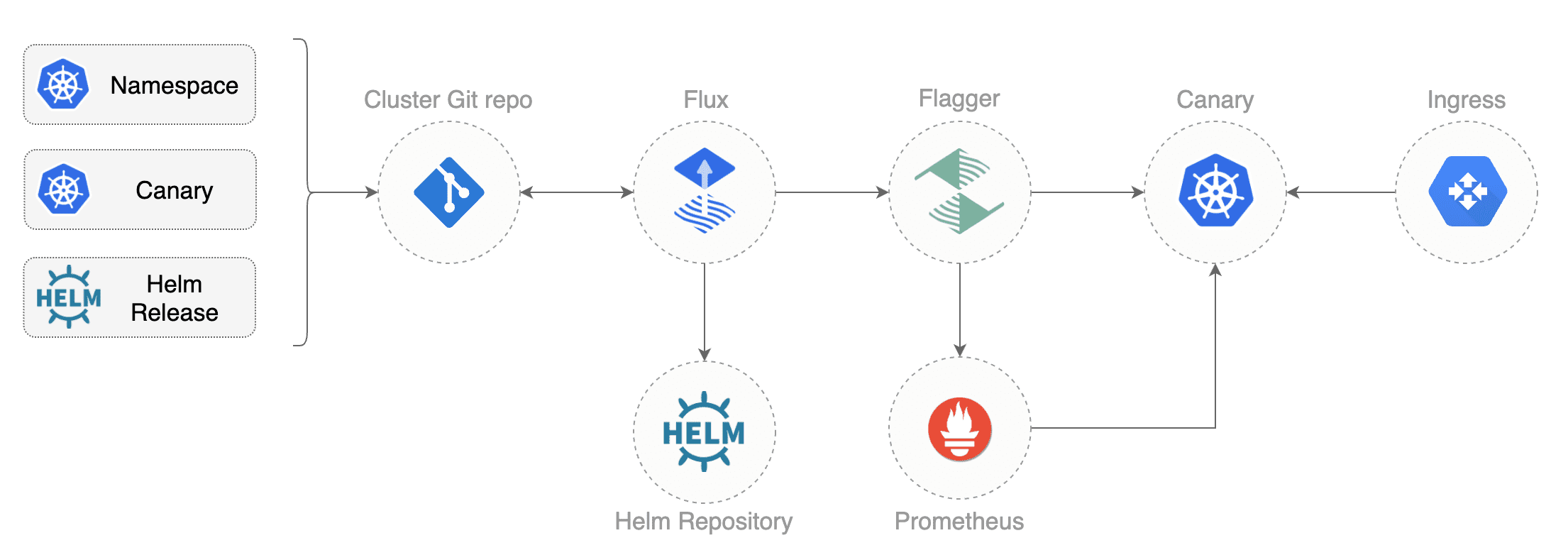
|
||||
|
||||
In order to apply the GitOps pipeline model to Flagger canary deployments you'll need a Git repository with your workloads definitions in YAML format, a container registry where your CI system pushes immutable images and an operator that synchronizes the Git repo with the cluster state.
|
||||
|
||||
Create a git repository with the following content:
|
||||
|
||||
```text
|
||||
├── namespaces
|
||||
│ └── test.yaml
|
||||
└── releases
|
||||
└── test
|
||||
├── backend.yaml
|
||||
├── frontend.yaml
|
||||
├── loadtester.yaml
|
||||
└── helmtester.yaml
|
||||
```
|
||||
|
||||
Define the `frontend` release using Flux `HelmRelease` custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flux.weave.works/v1beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: frontend
|
||||
namespace: test
|
||||
annotations:
|
||||
fluxcd.io/automated: "true"
|
||||
filter.fluxcd.io/chart-image: semver:~3.1
|
||||
spec:
|
||||
releaseName: frontend
|
||||
chart:
|
||||
git: https://github.com/weaveowrks/flagger
|
||||
ref: master
|
||||
path: charts/podinfo
|
||||
values:
|
||||
image:
|
||||
repository: stefanprodan/podinfo
|
||||
tag: 3.1.0
|
||||
backend: http://backend-podinfo:9898/echo
|
||||
canary:
|
||||
enabled: true
|
||||
istioIngress:
|
||||
enabled: true
|
||||
gateway: public-gateway.istio-system.svc.cluster.local
|
||||
host: frontend.istio.example.com
|
||||
loadtest:
|
||||
enabled: true
|
||||
helmtest:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
In the `chart` section I've defined the release source by specifying the Helm repository (hosted on GitHub Pages),
|
||||
chart name and version. In the `values` section I've overwritten the defaults set in values.yaml.
|
||||
|
||||
With the `fluxcd.io` annotations I instruct Flux to automate this release.
|
||||
When an image tag in the sem ver range of `3.1.0 - 3.1.99` is pushed to Docker Hub,
|
||||
Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
||||
|
||||
Install [Flux](https://github.com/fluxcd/flux) and its
|
||||
[Helm Operator](https://github.com/fluxcd/helm-operator) by specifying your Git repo URL:
|
||||
|
||||
```bash
|
||||
helm repo add fluxcd https://charts.fluxcd.io
|
||||
|
||||
helm install --name flux \
|
||||
--set git.url=git@github.com:<USERNAME>/<REPOSITORY> \
|
||||
--namespace fluxcd \
|
||||
fluxcd/flux
|
||||
|
||||
helm upgrade -i helm-operator fluxcd/helm-operator \
|
||||
--namespace fluxcd \
|
||||
--set git.ssh.secretName=flux-git-deploy
|
||||
```
|
||||
|
||||
At startup Flux generates a SSH key and logs the public key. Find the SSH public key with:
|
||||
|
||||
```bash
|
||||
kubectl -n fluxcd logs deployment/flux | grep identity.pub | cut -d '"' -f2
|
||||
```
|
||||
|
||||
In order to sync your cluster state with Git you need to copy the public key
|
||||
and create a deploy key with write access on your GitHub repository.
|
||||
|
||||
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_, check _Allow write access_,
|
||||
paste the Flux public key and click _Add key_.
|
||||
|
||||
After a couple of seconds Flux will apply the Kubernetes resources from Git and
|
||||
Flagger will launch the `frontend` and `backend` apps.
|
||||
|
||||
A CI/CD pipeline for the `frontend` release could look like this:
|
||||
|
||||
* cut a release from the master branch of the podinfo code repo with the git tag `3.1.1`
|
||||
* CI builds the image and pushes the `podinfo:3.1.1` image to the container registry
|
||||
* Flux scans the registry and updates the Helm release `image.tag` to `3.1.1`
|
||||
* Flux commits and push the change to the cluster repo
|
||||
* Flux applies the updated Helm release on the cluster
|
||||
* Flux Helm Operator picks up the change and calls Tiller to upgrade the release
|
||||
* Flagger detects a revision change and scales up the `frontend` deployment
|
||||
* Flagger runs the helm test before routing traffic to the canary service
|
||||
* Flagger starts the load test and runs the canary analysis
|
||||
* Based on the analysis result the canary deployment is promoted to production or rolled back
|
||||
* Flagger sends a Slack or MS Teams notification with the canary result
|
||||
|
||||
If the canary fails, fix the bug, do another patch release eg `3.1.2` and the whole process will run again.
|
||||
|
||||
A canary deployment can fail due to any of the following reasons:
|
||||
|
||||
* the container image can't be downloaded
|
||||
* the deployment replica set is stuck for more then ten minutes (eg. due to a container crash loop)
|
||||
* the webooks (acceptance tests, helm tests, load tests, etc) are returning a non 2xx response
|
||||
* the HTTP success rate (non 5xx responses) metric drops under the threshold
|
||||
* the HTTP average duration metric goes over the threshold
|
||||
* the Istio telemetry service is unable to collect traffic metrics
|
||||
* the metrics server (Prometheus) can't be reached
|
||||
|
||||
If you want to find out more about managing Helm releases with Flux here are two in-depth guides:
|
||||
[gitops-helm](https://github.com/stefanprodan/gitops-helm)
|
||||
and [gitops-istio](https://github.com/stefanprodan/gitops-istio).
|
||||
|
||||
440
docs/tutorials/contour-progressive-delivery.md
Normal file
440
docs/tutorials/contour-progressive-delivery.md
Normal file
@@ -0,0 +1,440 @@
|
||||
# Contour Canary Deployments
|
||||
|
||||
This guide shows you how to use [Contour](https://projectcontour.io/) ingress controller and Flagger to automate canary releases and A/B testing.
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Contour **v1.0** or newer.
|
||||
|
||||
Install Contour on a cluster with LoadBalancer support:
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://projectcontour.io/quickstart/contour.yaml
|
||||
```
|
||||
|
||||
The above command will deploy Contour and an Envoy daemonset in the `projectcontour` namespace.
|
||||
|
||||
Install Flagger using Kustomize (kubectl 1.14) in the `projectcontour` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/contour
|
||||
```
|
||||
|
||||
The above command will deploy Flagger and Prometheus configured to scrape the Contour's Envoy instances.
|
||||
|
||||
Or you can install Flagger using Helm:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace projectcontour \
|
||||
--set meshProvider=contour \
|
||||
--set prometheus.install=true
|
||||
```
|
||||
|
||||
You can also enable Slack, Discord, Rocket or MS Teams notifications,
|
||||
see the alerting [docs](../usage/alerting.md).
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Contour HTTPProxy).
|
||||
These objects expose the application in the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Install the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# HPA reference
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# service port
|
||||
port: 80
|
||||
# container port
|
||||
targetPort: 9898
|
||||
# Contour request timeout
|
||||
timeout: 15s
|
||||
# Contour retry policy
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 5s
|
||||
# define the canary analysis timing and KPIs
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 30s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# Contour Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99 in milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary.test/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
type: rollout
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -host app.example.com http://envoy.projectcontour"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every half a minute.
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
httpproxy.projectcontour.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods.
|
||||
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Expose the app outside the cluster
|
||||
|
||||
Find the external address of Contour's Envoy load balancer:
|
||||
|
||||
```bash
|
||||
export ADDRESS="$(kubectl -n projectcontour get svc/envoy -ojson \
|
||||
| jq -r ".status.loadBalancer.ingress[].hostname")"
|
||||
echo $ADDRESS
|
||||
```
|
||||
|
||||
Configure your DNS server with a CNAME record \(AWS\) or A record (GKE/AKS/DOKS)
|
||||
and point a domain e.g. `app.example.com` to the LB address.
|
||||
|
||||
Create a HTTPProxy definition and include the podinfo proxy generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: projectcontour.io/v1
|
||||
kind: HTTPProxy
|
||||
metadata:
|
||||
name: podinfo-ingress
|
||||
namespace: test
|
||||
spec:
|
||||
virtualhost:
|
||||
fqdn: app.example.com
|
||||
includes:
|
||||
- name: podinfo
|
||||
namespace: test
|
||||
conditions:
|
||||
- prefix: /
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-ingress.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-ingress.yaml
|
||||
```
|
||||
|
||||
Verify that Contour processed the proxy definition with:
|
||||
|
||||
```bash
|
||||
kubectl -n test get httpproxies
|
||||
|
||||
NAME FQDN STATUS
|
||||
podinfo valid
|
||||
podinfo-ingress app.example.com valid
|
||||
```
|
||||
|
||||
Now you can access podinfo UI using your domain address.
|
||||
|
||||
Note that you should be using HTTPS when exposing production workloads on internet.
|
||||
You can obtain free TLS certs from Let's Encrypt, read this [guide](https://github.com/stefanprodan/eks-contour-ingress)
|
||||
on how to configure cert-manager to secure Contour with TLS certificates.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
New revision detected! Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-12-20T14:05:07Z
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors or high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger a canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it deploy/flagger-loadtester bash
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
hey -z 1m -c 5 -q 5 http://app.example.com/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n projectcontour logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Starting canary analysis for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Halt podinfo.test advancement request duration 1.20s > 500ms
|
||||
Halt podinfo.test advancement request duration 1.45s > 500ms
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 5
|
||||
iterations: 10
|
||||
match:
|
||||
- headers:
|
||||
x-canary:
|
||||
exact: "insider"
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 5 -H 'X-Canary: insider' -host app.example.com http://envoy.projectcontour"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `X-Canary: insider` header.
|
||||
|
||||
You can also use a HTTP cookie. To target all users with a cookie set to `insider`, the match condition should be:
|
||||
|
||||
```yaml
|
||||
match:
|
||||
- headers:
|
||||
cookie:
|
||||
suffix: "insider"
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 5 -H 'Cookie: canary=insider' -host app.example.com http://envoy.projectcontour"
|
||||
```
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the A/B test:
|
||||
|
||||
```text
|
||||
kubectl -n projectcontour logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Starting canary analysis for podinfo.test
|
||||
Advance podinfo.test canary iteration 1/10
|
||||
Advance podinfo.test canary iteration 2/10
|
||||
Advance podinfo.test canary iteration 3/10
|
||||
Advance podinfo.test canary iteration 4/10
|
||||
Advance podinfo.test canary iteration 5/10
|
||||
Advance podinfo.test canary iteration 6/10
|
||||
Advance podinfo.test canary iteration 7/10
|
||||
Advance podinfo.test canary iteration 8/10
|
||||
Advance podinfo.test canary iteration 9/10
|
||||
Advance podinfo.test canary iteration 10/10
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The web browser user agent header allows user segmentation based on device or OS.
|
||||
|
||||
For example, if you want to route all mobile users to the canary instance:
|
||||
|
||||
```yaml
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
prefix: "Mobile"
|
||||
```
|
||||
|
||||
Or if you want to target only Android users:
|
||||
|
||||
```yaml
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
prefix: "Android"
|
||||
```
|
||||
|
||||
Or a specific browser version:
|
||||
|
||||
```yaml
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
suffix: "Firefox/71.0"
|
||||
```
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
324
docs/tutorials/crossover-progressive-delivery.md
Normal file
324
docs/tutorials/crossover-progressive-delivery.md
Normal file
@@ -0,0 +1,324 @@
|
||||
# Crossover Canary Deployments
|
||||
|
||||
This guide shows you how to use Envoy, [Crossover](https://github.com/mumoshu/crossover) and Flagger to automate canary deployments.
|
||||
|
||||
Crossover is a minimal Envoy xDS implementation supports [Service Mesh Interface](https://smi-spec.io/).
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Envoy paired with [Crossover](https://github.com/mumoshu/crossover) sidecar.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Install Envoy along with the Crossover sidecar with Helm:
|
||||
|
||||
```bash
|
||||
helm repo add crossover https://mumoshu.github.io/crossover
|
||||
|
||||
helm upgrade --install envoy crossover/envoy \
|
||||
--namespace test \
|
||||
-f <(cat <<EOF
|
||||
smi:
|
||||
apiVersions:
|
||||
trafficSplits: v1alpha1
|
||||
upstreams:
|
||||
podinfo:
|
||||
smi:
|
||||
enabled: true
|
||||
backends:
|
||||
podinfo-primary:
|
||||
port: 9898
|
||||
weight: 100
|
||||
podinfo-canary:
|
||||
port: 9898
|
||||
weight: 0
|
||||
EOF
|
||||
)
|
||||
```
|
||||
|
||||
Install Flagger and the Prometheus add-on in the same namespace as Envoy:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace test \
|
||||
--set prometheus.install=true \
|
||||
--set meshProvider=smi:crossover
|
||||
```
|
||||
|
||||
Optionally you can enable Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace test \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services, SMI traffic splits).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
There's no SMI object you need to create by yourself.
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# specify mesh provider if it isn't the default one
|
||||
# provider: "smi:crossover"
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# ClusterIP port number
|
||||
port: 9898
|
||||
# container port number or name (optional)
|
||||
targetPort: 9898
|
||||
# define the canary analysis timing and KPIs
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# App Mesh Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary.test:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Host: podinfo.test' http://envoy.test:10000/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods. During the canary analysis,
|
||||
the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.5
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
New revision detected! Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
During the analysis the canary’s progress can be monitored with Grafana.
|
||||
|
||||
Flagger comes with a Grafana dashboard made for canary analysis. Install Grafana with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=test \
|
||||
--set url=http://flagger-prometheus:9090
|
||||
```
|
||||
|
||||
Run:
|
||||
|
||||
```bash
|
||||
kubectl port-forward --namespace test svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
The Envoy dashboard URL is [http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo](http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo)
|
||||
|
||||

|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-10-02T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-10-02T16:15:07Z
|
||||
prod backend Failed 0 2019-10-02T17:05:07Z
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors or high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger a canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it deploy/flagger-loadtester bash
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
hey -z 1m -c 5 -q 5 -H 'Host: podinfo.test' http://envoy.test:10000/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl -H 'Host: podinfo.test' http://envoy.test:10000/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! Starting canary analysis for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Halt podinfo.test advancement request duration 1.20s > 0.5s
|
||||
Halt podinfo.test advancement request duration 1.45s > 0.5s
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||
|
||||
295
docs/tutorials/flagger-smi-istio.md
Normal file
295
docs/tutorials/flagger-smi-istio.md
Normal file
@@ -0,0 +1,295 @@
|
||||
# SMI Istio Canary Deployments
|
||||
|
||||
This guide shows you how to use the SMI Istio adapter and Flagger to automate canary deployments.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* Kubernetes > 1.13
|
||||
* Istio > 1.0
|
||||
|
||||
## Install Istio SMI adapter
|
||||
|
||||
Install the SMI adapter:
|
||||
|
||||
```bash
|
||||
kubectl apply -f https://raw.githubusercontent.com/deislabs/smi-adapter-istio/master/deploy/crds/crds.yaml
|
||||
kubectl apply -f https://raw.githubusercontent.com/deislabs/smi-adapter-istio/master/deploy/operator-and-rbac.yaml
|
||||
```
|
||||
|
||||
Create a generic Istio gateway to expose services outside the mesh on HTTP:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
```
|
||||
|
||||
Save the above resource as public-gateway.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./public-gateway.yaml
|
||||
```
|
||||
|
||||
Find the Gateway load balancer IP and add a DNS record for it:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system get svc/istio-ingressgateway -ojson | jq -r .status.loadBalancer.ingress[0].ip
|
||||
```
|
||||
|
||||
## Install Flagger and Grafana
|
||||
|
||||
Add Flagger Helm repository:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
```
|
||||
|
||||
Deploy Flagger in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace=istio-system \
|
||||
--set meshProvider=smi:istio
|
||||
```
|
||||
|
||||
Flagger comes with a Grafana dashboard made for monitoring the canary deployments.
|
||||
|
||||
Deploy Grafana in the _**istio-system**_ namespace:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \
|
||||
--set url=http://prometheus.istio-system:9090
|
||||
```
|
||||
|
||||
You can access Grafana using port forwarding:
|
||||
|
||||
```bash
|
||||
kubectl -n istio-system port-forward svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
## Workloads bootstrap
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
Create a test namespace and enable Linkerd proxy injection:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
kubectl label namespace test istio-injection=enabled
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace example.com with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.example.com
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 10
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# generate traffic during analysis
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=quay.io/stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system logs deployment/flagger -f | jq .msg
|
||||
|
||||
|
||||
New revision detected podinfo.test
|
||||
Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
During the analysis the canary’s progress can be monitored with Grafana. The Istio dashboard URL is [http://localhost:3000/d/flagger-istio/istio-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo](http://localhost:3000/d/flagger-istio/istio-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo)
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-05-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-05-15T16:15:07Z
|
||||
prod backend Failed 0 2019-05-14T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Create a tester pod and exec into it:
|
||||
|
||||
```bash
|
||||
kubectl -n test run tester \
|
||||
--image=quay.io/stefanprodan/podinfo:3.1.2 \
|
||||
-- ./podinfo --port=9898
|
||||
|
||||
kubectl -n test exec -it tester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
381
docs/tutorials/gloo-progressive-delivery.md
Normal file
381
docs/tutorials/gloo-progressive-delivery.md
Normal file
@@ -0,0 +1,381 @@
|
||||
# Gloo Canary Deployments
|
||||
|
||||
This guide shows you how to use the [Gloo](https://gloo.solo.io/) ingress controller and Flagger to automate canary deployments.
|
||||
|
||||
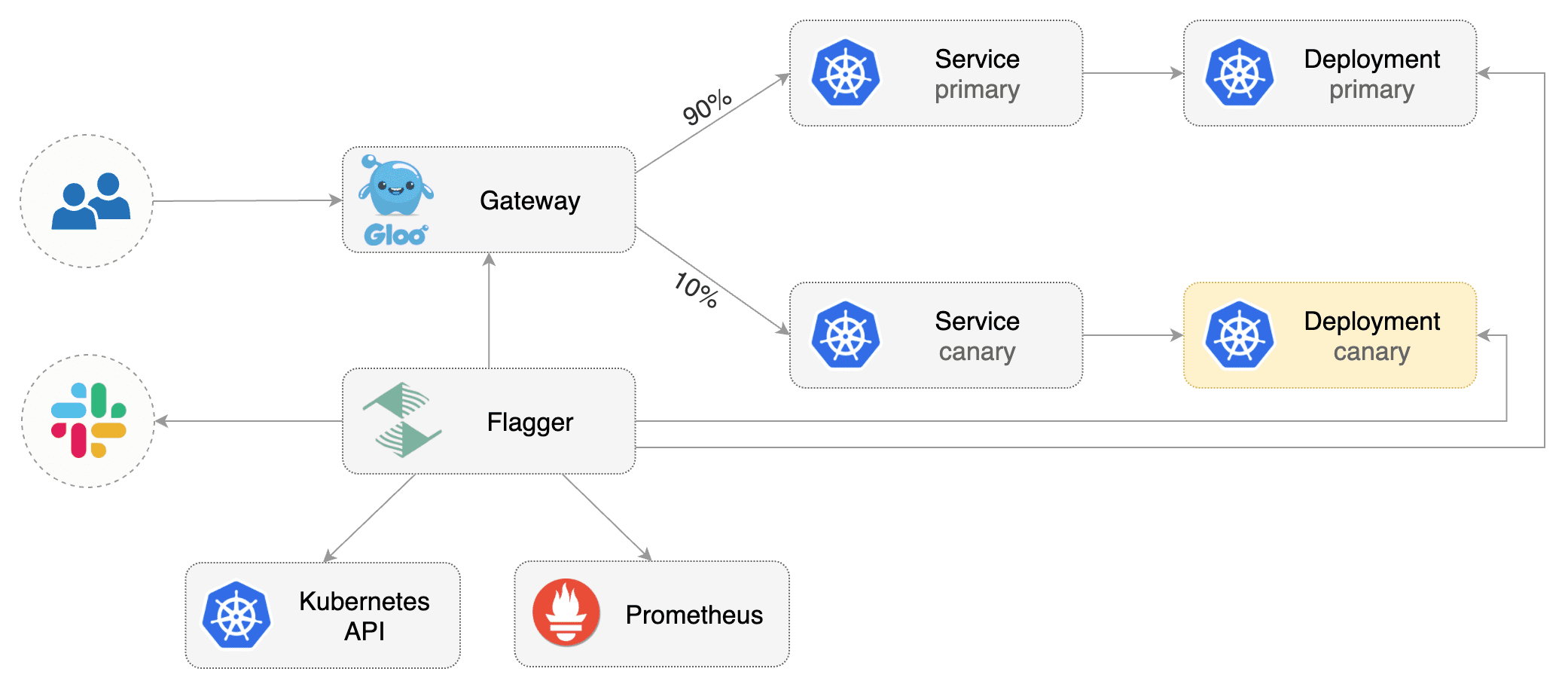
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Gloo ingress **1.3.5** or newer.
|
||||
|
||||
Install Gloo with Helm v3:
|
||||
|
||||
```bash
|
||||
helm repo add gloo https://storage.googleapis.com/solo-public-helm
|
||||
kubectl create ns gloo-system
|
||||
helm upgrade -i gloo gloo/gloo \
|
||||
--namespace gloo-system
|
||||
```
|
||||
|
||||
Install Flagger and the Prometheus add-on in the same namespace as Gloo:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace gloo-system \
|
||||
--set prometheus.install=true \
|
||||
--set meshProvider=gloo
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Gloo upstream groups).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create an virtual service definition that references an upstream group that will be generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: gateway.solo.io/v1
|
||||
kind: VirtualService
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
virtualHost:
|
||||
domains:
|
||||
- 'app.example.com'
|
||||
routes:
|
||||
- matchers:
|
||||
- prefix: /
|
||||
routeAction:
|
||||
upstreamGroup:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-virtualservice.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-virtualservice.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
provider: gloo
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# ClusterIP port number
|
||||
port: 9898
|
||||
# container port number or name (optional)
|
||||
targetPort: 9898
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# Gloo Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 10s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 2m -q 5 -c 2 -host app.example.com http://gateway-proxy.gloo-system"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
virtualservices.gateway.solo.io/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
upstreamgroups.gloo.solo.io/podinfo
|
||||
```
|
||||
|
||||
When the bootstrap finishes Flagger will set the canary status to initialized:
|
||||
|
||||
```bash
|
||||
kubectl -n test get canary podinfo
|
||||
|
||||
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
podinfo Initialized 0 2019-05-17T08:09:51Z
|
||||
```
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-05-17T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-05-17T16:15:07Z
|
||||
prod backend Failed 0 2019-05-17T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses and rolls back the faulted version.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl -H 'Host: app.example.com' http://gateway-proxy-v2.gloo-system/status/500
|
||||
```
|
||||
|
||||
Generate high latency:
|
||||
|
||||
```bash
|
||||
watch curl -H 'Host: app.example.com' http://gateway-proxy-v2.gloo-system/delay/2
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use
|
||||
the HTTP request duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: not-found-percentage
|
||||
namespace: test
|
||||
spec:
|
||||
provider:
|
||||
type: prometheus
|
||||
address: http://flagger-promethues.gloo-system:9090
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
http_request_duration_seconds_count{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
status!="{{ interval }}"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
http_request_duration_seconds_count{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
Edit the canary analysis and add the following metric:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
templateRef:
|
||||
name: not-found-percentage
|
||||
thresholdRange:
|
||||
max: 5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is
|
||||
below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Generate 404s:
|
||||
|
||||
```bash
|
||||
watch curl -H 'Host: app.example.com' http://gateway-proxy.gloo-system/status/400
|
||||
```
|
||||
|
||||
Watch Flagger logs:
|
||||
|
||||
```text
|
||||
kubectl -n gloo-system logs deployment/flagger -f | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement 404s percentage 6.20 > 5
|
||||
Halt podinfo.test advancement 404s percentage 6.45 > 5
|
||||
Halt podinfo.test advancement 404s percentage 7.60 > 5
|
||||
Halt podinfo.test advancement 404s percentage 8.69 > 5
|
||||
Halt podinfo.test advancement 404s percentage 9.70 > 5
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
260
docs/tutorials/istio-ab-testing.md
Normal file
260
docs/tutorials/istio-ab-testing.md
Normal file
@@ -0,0 +1,260 @@
|
||||
# Istio A/B Testing
|
||||
|
||||
This guide shows you how to automate A/B testing with Istio and Flagger.
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Istio **v1.0** or newer.
|
||||
|
||||
Install Istio with telemetry support and Prometheus:
|
||||
|
||||
```bash
|
||||
istioctl manifest apply --set profile=default
|
||||
```
|
||||
|
||||
Install Flagger using Kustomize (kubectl 1.14) in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/istio
|
||||
```
|
||||
|
||||
Create an ingress gateway to expose the demo app outside of the mesh:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
kubectl label namespace test istio-injection=enabled
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace example.com with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.example.com
|
||||
# Istio traffic policy (optional)
|
||||
trafficPolicy:
|
||||
tls:
|
||||
# use ISTIO_MUTUAL when mTLS is enabled
|
||||
mode: DISABLE
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
# canary match condition
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: "^(?!.*Chrome).*Safari.*"
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(type=insider)(;.*)?$"
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# generate traffic during analysis
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: type=insider' http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting Safari users and those that have an insider cookie.
|
||||
|
||||
Save the above resource as podinfo-abtest.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-abtest.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
destinationrule.networking.istio.io/podinfo-canary
|
||||
destinationrule.networking.istio.io/podinfo-primary
|
||||
virtualservice.networking.istio.io/podinfo
|
||||
```
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/abtest
|
||||
|
||||
Status:
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 3/10
|
||||
Normal Synced 2m flagger Advance podinfo.test canary iteration 4/10
|
||||
Normal Synced 2m flagger Advance podinfo.test canary iteration 5/10
|
||||
Normal Synced 1m flagger Advance podinfo.test canary iteration 6/10
|
||||
Normal Synced 1m flagger Advance podinfo.test canary iteration 7/10
|
||||
Normal Synced 55s flagger Advance podinfo.test canary iteration 8/10
|
||||
Normal Synced 45s flagger Advance podinfo.test canary iteration 9/10
|
||||
Normal Synced 35s flagger Advance podinfo.test canary iteration 10/10
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 100 2019-03-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-03-15T16:15:07Z
|
||||
prod backend Failed 0 2019-03-14T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test Flagger's rollback.
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl -b 'type=insider' http://app.example.com/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl -b 'type=insider' http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Failed Checks: 2
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 3/10
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Warning Synced 2m flagger Rolling back podinfo.test failed checks threshold reached 2
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
373
docs/tutorials/istio-progressive-delivery.md
Normal file
373
docs/tutorials/istio-progressive-delivery.md
Normal file
@@ -0,0 +1,373 @@
|
||||
# Istio Canary Deployments
|
||||
|
||||
This guide shows you how to use Istio and Flagger to automate canary deployments.
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Istio **v1.0** or newer.
|
||||
|
||||
Install Istio with telemetry support and Prometheus:
|
||||
|
||||
```bash
|
||||
istioctl manifest apply --set profile=default
|
||||
```
|
||||
|
||||
Install Flagger using Kustomize (kubectl 1.14) in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/istio
|
||||
```
|
||||
|
||||
Create an ingress gateway to expose the demo app outside of the mesh:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
kind: Gateway
|
||||
metadata:
|
||||
name: public-gateway
|
||||
namespace: istio-system
|
||||
spec:
|
||||
selector:
|
||||
istio: ingressgateway
|
||||
servers:
|
||||
- port:
|
||||
number: 80
|
||||
name: http
|
||||
protocol: HTTP
|
||||
hosts:
|
||||
- "*"
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services,
|
||||
Istio destination rules and virtual services).
|
||||
These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
kubectl label namespace test istio-injection=enabled
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace example.com with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# service port number
|
||||
port: 9898
|
||||
# container port number or name (optional)
|
||||
targetPort: 9898
|
||||
# Istio gateways (optional)
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
# Istio virtual service host names (optional)
|
||||
hosts:
|
||||
- app.example.com
|
||||
# Istio traffic policy (optional)
|
||||
trafficPolicy:
|
||||
tls:
|
||||
# use ISTIO_MUTUAL when mTLS is enabled
|
||||
mode: DISABLE
|
||||
# Istio retry policy (optional)
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 1s
|
||||
retryOn: "gateway-error,connect-failure,refused-stream"
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 10
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every minute.
|
||||
|
||||

|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
destinationrule.networking.istio.io/podinfo-canary
|
||||
destinationrule.networking.istio.io/podinfo-primary
|
||||
virtualservice.networking.istio.io/podinfo
|
||||
```
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps mounted as volumes or mapped to environment variables
|
||||
* Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-01-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-01-15T16:15:07Z
|
||||
prod backend Failed 0 2019-01-14T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
## Traffic mirroring
|
||||
|
||||
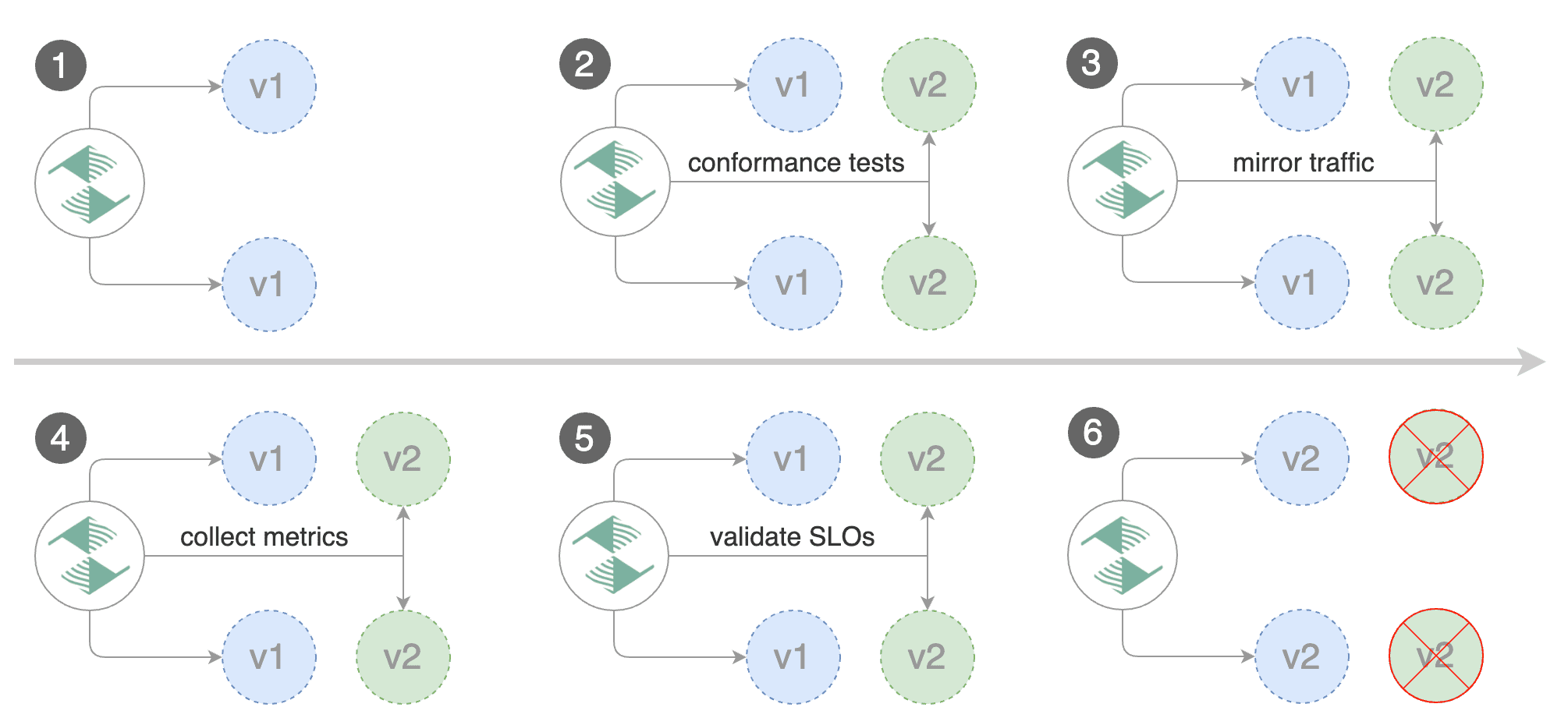
|
||||
|
||||
For applications that perform read operations, Flagger can be configured to drive canary releases with traffic mirroring.
|
||||
Istio traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service.
|
||||
The response from the primary is sent back to the user and the response from the canary is discarded.
|
||||
Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are within the threshold values.
|
||||
|
||||
Note that mirroring should be used for requests that are **idempotent** or capable of being processed twice (once by the primary and once by the canary).
|
||||
|
||||
You can enable mirroring by replacing `stepWeight/maxWeight` with `iterations` and by setting `analysis.mirror` to `true`:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
analysis:
|
||||
# schedule interval
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# enable traffic shadowing
|
||||
mirror: true
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 1m
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
With the above configuration, Flagger will run a canary release with the following steps:
|
||||
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* scale from zero the canary deployment
|
||||
* wait for the HPA to set the canary minimum replicas
|
||||
* check canary pods health
|
||||
* run the acceptance tests
|
||||
* abort the canary release if tests fail
|
||||
* start the load tests
|
||||
* mirror traffic from primary to canary
|
||||
* check request success rate and request duration every minute
|
||||
* abort the canary release if the metrics check failure threshold is reached
|
||||
* stop traffic mirroring after the number of iterations is reached
|
||||
* route live traffic to the canary pods
|
||||
* promote the canary (update the primary secrets, configmaps and deployment spec)
|
||||
* wait for the primary deployment rollout to finish
|
||||
* wait for the HPA to set the primary minimum replicas
|
||||
* check primary pods health
|
||||
* switch live traffic back to primary
|
||||
* scale to zero the canary
|
||||
* send notification with the canary analysis result
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
377
docs/tutorials/kubernetes-blue-green.md
Normal file
377
docs/tutorials/kubernetes-blue-green.md
Normal file
@@ -0,0 +1,377 @@
|
||||
# Blue/Green Deployments
|
||||
|
||||
This guide shows you how to automate Blue/Green deployments with Flagger and Kubernetes.
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate Blue/Green style deployments
|
||||
with Kubernetes L4 networking. When using a service mesh blue/green can be used as
|
||||
specified [here](../usage/deployment-strategies.md).
|
||||
|
||||
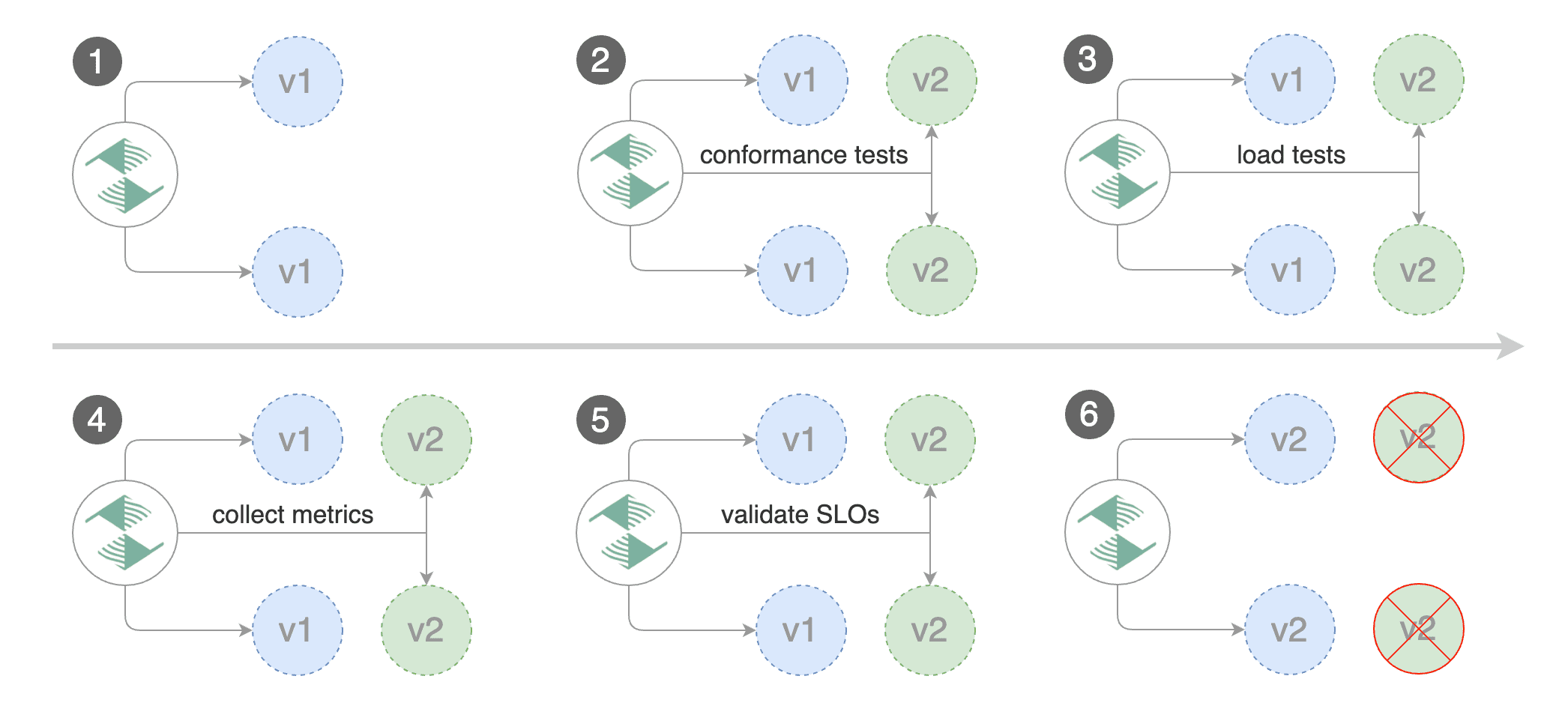
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer.
|
||||
|
||||
Install Flagger and the Prometheus add-on:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace flagger \
|
||||
--set prometheus.install=true \
|
||||
--set meshProvider=kubernetes
|
||||
```
|
||||
|
||||
If you already have a Prometheus instance running in your cluster, you can point Flagger to the ClusterIP service with:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace flagger \
|
||||
--set metricsServer=http://prometheus.monitoring:9090
|
||||
```
|
||||
|
||||
Optionally you can enable Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace flagger \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployment and ClusterIP services).
|
||||
These objects expose the application inside the cluster and drive the canary analysis and Blue/Green promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# service mesh provider can be: kubernetes, istio, appmesh, nginx, gloo
|
||||
provider: kubernetes
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
port: 9898
|
||||
portDiscovery: true
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 30s
|
||||
# max number of failed checks before rollback
|
||||
threshold: 2
|
||||
# number of checks to run before rollback
|
||||
iterations: 10
|
||||
# Prometheus checks based on
|
||||
# http_request_duration_seconds histogram
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# acceptance/load testing hooks
|
||||
webhooks:
|
||||
- name: smoke-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 15s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'anon' http://podinfo-canary.test:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for five minutes.
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
```
|
||||
|
||||
Blue/Green scenario:
|
||||
|
||||
* on bootstrap, Flagger will create three ClusterIP services (`app-primary`,`app-canary`, `app`)
|
||||
and a shadow deployment named `app-primary` that represents the blue version
|
||||
* when a new version is detected, Flagger would scale up the green version and run the conformance tests
|
||||
(the tests should target the `app-canary` ClusterIP service to reach the green version)
|
||||
* if the conformance tests are passing, Flagger would start the load tests and validate them with custom Prometheus queries
|
||||
* if the load test analysis is successful, Flagger will promote the new version to `app-primary` and scale down the green version
|
||||
|
||||
## Automated Blue/Green promotion
|
||||
|
||||
Trigger a deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Events:
|
||||
|
||||
New revision detected podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary iteration 1/10
|
||||
Advance podinfo.test canary iteration 2/10
|
||||
Advance podinfo.test canary iteration 3/10
|
||||
Advance podinfo.test canary iteration 4/10
|
||||
Advance podinfo.test canary iteration 5/10
|
||||
Advance podinfo.test canary iteration 6/10
|
||||
Advance podinfo.test canary iteration 7/10
|
||||
Advance podinfo.test canary iteration 8/10
|
||||
Advance podinfo.test canary iteration 9/10
|
||||
Advance podinfo.test canary iteration 10/10
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 100 2019-06-16T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-06-15T16:15:07Z
|
||||
prod backend Failed 0 2019-06-14T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the analysis you can generate HTTP 500 errors and high latency to test Flagger's rollback.
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary.test:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary.test:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the analysis threshold, the green version is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Failed Checks: 2
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 3/10
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Warning Synced 2m flagger Rolling back podinfo.test failed checks threshold reached 2
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The analysis can be extended with Prometheus queries. The demo app is instrumented with Prometheus so you can
|
||||
create a custom check that will use the HTTP request duration histogram to validate the canary (green version).
|
||||
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: not-found-percentage
|
||||
namespace: test
|
||||
spec:
|
||||
provider:
|
||||
type: prometheus
|
||||
address: http://flagger-promethues.flagger:9090
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
http_request_duration_seconds_count{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
status!="{{ interval }}"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
http_request_duration_seconds_count{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
Edit the canary analysis and add the following metric:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
templateRef:
|
||||
name: not-found-percentage
|
||||
thresholdRange:
|
||||
max: 5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary (green version) by checking if the HTTP 404 req/sec percentage is
|
||||
below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the rollout is rolled back.
|
||||
|
||||
Trigger a deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Generate 404s:
|
||||
|
||||
```bash
|
||||
watch curl http://podinfo-canary.test:9898/status/400
|
||||
```
|
||||
|
||||
Watch Flagger logs:
|
||||
|
||||
```text
|
||||
kubectl -n flagger logs deployment/flagger -f | jq .msg
|
||||
|
||||
New revision detected podinfo.test
|
||||
Scaling up podinfo.test
|
||||
Advance podinfo.test canary iteration 1/10
|
||||
Halt podinfo.test advancement 404s percentage 6.20 > 5
|
||||
Halt podinfo.test advancement 404s percentage 6.45 > 5
|
||||
Rolling back podinfo.test failed checks threshold reached 2
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
## Conformance Testing with Helm
|
||||
|
||||
Flagger comes with a testing service that can run Helm tests when configured as a pre-rollout webhook.
|
||||
|
||||
Deploy the Helm test runner in the `kube-system` namespace using the `tiller` service account:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger-helmtester flagger/loadtester \
|
||||
--namespace=kube-system \
|
||||
--set serviceAccountName=tiller
|
||||
```
|
||||
|
||||
When deployed the Helm tester API will be available at `http://flagger-helmtester.kube-system/`.
|
||||
|
||||
Add a helm test pre-rollout hook to your chart:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "conformance testing"
|
||||
type: pre-rollout
|
||||
url: http://flagger-helmtester.kube-system/
|
||||
timeout: 3m
|
||||
metadata:
|
||||
type: "helm"
|
||||
cmd: "test {{ .Release.Name }} --cleanup"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks.
|
||||
If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
485
docs/tutorials/linkerd-progressive-delivery.md
Normal file
485
docs/tutorials/linkerd-progressive-delivery.md
Normal file
@@ -0,0 +1,485 @@
|
||||
# Linkerd Canary Deployments
|
||||
|
||||
This guide shows you how to use Linkerd and Flagger to automate canary deployments.
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and Linkerd **2.4** or newer.
|
||||
|
||||
Install Flagger in the linkerd namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/linkerd
|
||||
```
|
||||
|
||||
Note that you'll need kubectl 1.14 or newer to run the above command.
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and SMI traffic split).
|
||||
These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace and enable Linkerd proxy injection:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
kubectl annotate namespace test linkerd.io/inject=enabled
|
||||
```
|
||||
|
||||
Install the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Create a canary custom resource for the podinfo deployment:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
service:
|
||||
# ClusterIP port number
|
||||
port: 9898
|
||||
# container port number or name (optional)
|
||||
targetPort: 9898
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 30s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# Linkerd Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary.test:9898/token | grep token"
|
||||
- name: load-test
|
||||
type: rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 2m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every half a minute.
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
ingresses.extensions/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods.
|
||||
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
New revision detected! Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Waiting for podinfo.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps mounted as volumes or mapped to environment variables
|
||||
* Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-06-30T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-06-30T16:15:07Z
|
||||
prod backend Failed 0 2019-06-30T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to
|
||||
test if Flagger pauses and rolls back the faulted version.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xx-xx sh
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl http://podinfo-canary.test:9898/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl http://podinfo-canary.test:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Starting canary analysis for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Halt podinfo.test advancement request duration 1.20s > 0.5s
|
||||
Halt podinfo.test advancement request duration 1.45s > 0.5s
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
Let's a define a check for not found errors. Edit the canary analysis and add the following metric:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
threshold: 3
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
response_total{
|
||||
namespace="test",
|
||||
deployment="podinfo",
|
||||
status_code!="404",
|
||||
direction="inbound"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
response_total{
|
||||
namespace="test",
|
||||
deployment="podinfo",
|
||||
direction="inbound"
|
||||
}[1m]
|
||||
)
|
||||
)
|
||||
* 100
|
||||
```
|
||||
|
||||
The above configuration validates the canary version by checking if the HTTP 404 req/sec percentage
|
||||
is below three percent of the total traffic.
|
||||
If the 404s rate reaches the 3% threshold, then the analysis is aborted and the canary is marked as failed.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Generate 404s:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl http://podinfo-canary:9898/status/404
|
||||
```
|
||||
|
||||
Watch Flagger logs:
|
||||
|
||||
```text
|
||||
kubectl -n linkerd logs deployment/flagger -f | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Halt podinfo.test advancement 404s percentage 6.20 > 3
|
||||
Halt podinfo.test advancement 404s percentage 6.45 > 3
|
||||
Halt podinfo.test advancement 404s percentage 7.22 > 3
|
||||
Halt podinfo.test advancement 404s percentage 6.50 > 3
|
||||
Halt podinfo.test advancement 404s percentage 6.34 > 3
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have Slack configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
## Linkerd Ingress
|
||||
|
||||
There are two ingress controllers that are compatible with both Flagger and Linkerd: NGINX and Gloo.
|
||||
|
||||
Install NGINX:
|
||||
|
||||
```bash
|
||||
helm upgrade -i nginx-ingress stable/nginx-ingress \
|
||||
--namespace ingress-nginx
|
||||
```
|
||||
|
||||
Create an ingress definition for podinfo that rewrites the incoming header
|
||||
to the internal service name (required by Linkerd):
|
||||
|
||||
```yaml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
labels:
|
||||
app: podinfo
|
||||
annotations:
|
||||
kubernetes.io/ingress.class: "nginx"
|
||||
nginx.ingress.kubernetes.io/configuration-snippet: |
|
||||
proxy_set_header l5d-dst-override $service_name.$namespace.svc.cluster.local:9898;
|
||||
proxy_hide_header l5d-remote-ip;
|
||||
proxy_hide_header l5d-server-id;
|
||||
spec:
|
||||
rules:
|
||||
- host: app.example.com
|
||||
http:
|
||||
paths:
|
||||
- backend:
|
||||
serviceName: podinfo
|
||||
servicePort: 9898
|
||||
```
|
||||
|
||||
When using an ingress controller, the Linkerd traffic split does not apply to incoming traffic
|
||||
since NGINX in running outside of the mesh. In order to run a canary analysis for a frontend app,
|
||||
Flagger creates a shadow ingress and sets the NGINX specific annotations.
|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
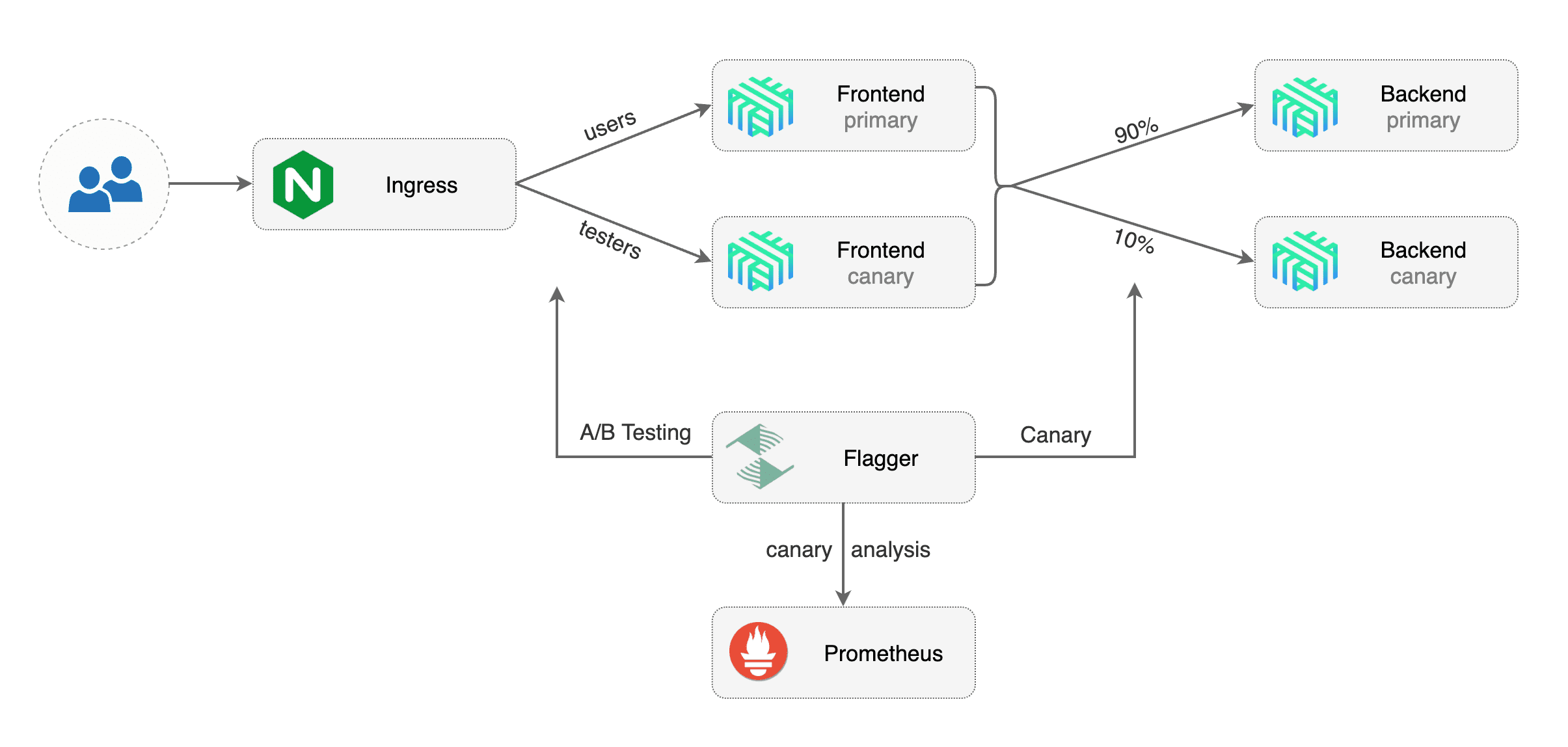
|
||||
|
||||
Edit podinfo canary analysis, set the provider to `nginx`, add the ingress reference,
|
||||
remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
# ingress reference
|
||||
provider: nginx
|
||||
ingressRef:
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
name: podinfo
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
# container port
|
||||
port: 9898
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
iterations: 10
|
||||
match:
|
||||
# curl -H 'X-Canary: always' http://app.example.com
|
||||
- headers:
|
||||
x-canary:
|
||||
exact: "always"
|
||||
# curl -b 'canary=always' http://app.example.com
|
||||
- headers:
|
||||
cookie:
|
||||
exact: "canary"
|
||||
# Linkerd Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 30s
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary:9898/token | grep token"
|
||||
- name: load-test
|
||||
type: rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 2m -q 10 -c 2 -H 'Cookie: canary=always' http://app.example.com"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have
|
||||
a `canary` cookie set to `always` or those that call the service using the `X-Canary: always` header.
|
||||
|
||||
**Note** that the load test now targets the external address and uses the canary cookie.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.4
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the A/B testing:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Events:
|
||||
Starting canary deployment for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary iteration 1/10
|
||||
Advance podinfo.test canary iteration 2/10
|
||||
Advance podinfo.test canary iteration 3/10
|
||||
Advance podinfo.test canary iteration 4/10
|
||||
Advance podinfo.test canary iteration 5/10
|
||||
Advance podinfo.test canary iteration 6/10
|
||||
Advance podinfo.test canary iteration 7/10
|
||||
Advance podinfo.test canary iteration 8/10
|
||||
Advance podinfo.test canary iteration 9/10
|
||||
Advance podinfo.test canary iteration 10/10
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
451
docs/tutorials/nginx-progressive-delivery.md
Normal file
451
docs/tutorials/nginx-progressive-delivery.md
Normal file
@@ -0,0 +1,451 @@
|
||||
# NGINX Canary Deployments
|
||||
|
||||
This guide shows you how to use the NGINX ingress controller and Flagger to automate canary deployments and A/B testing.
|
||||
|
||||
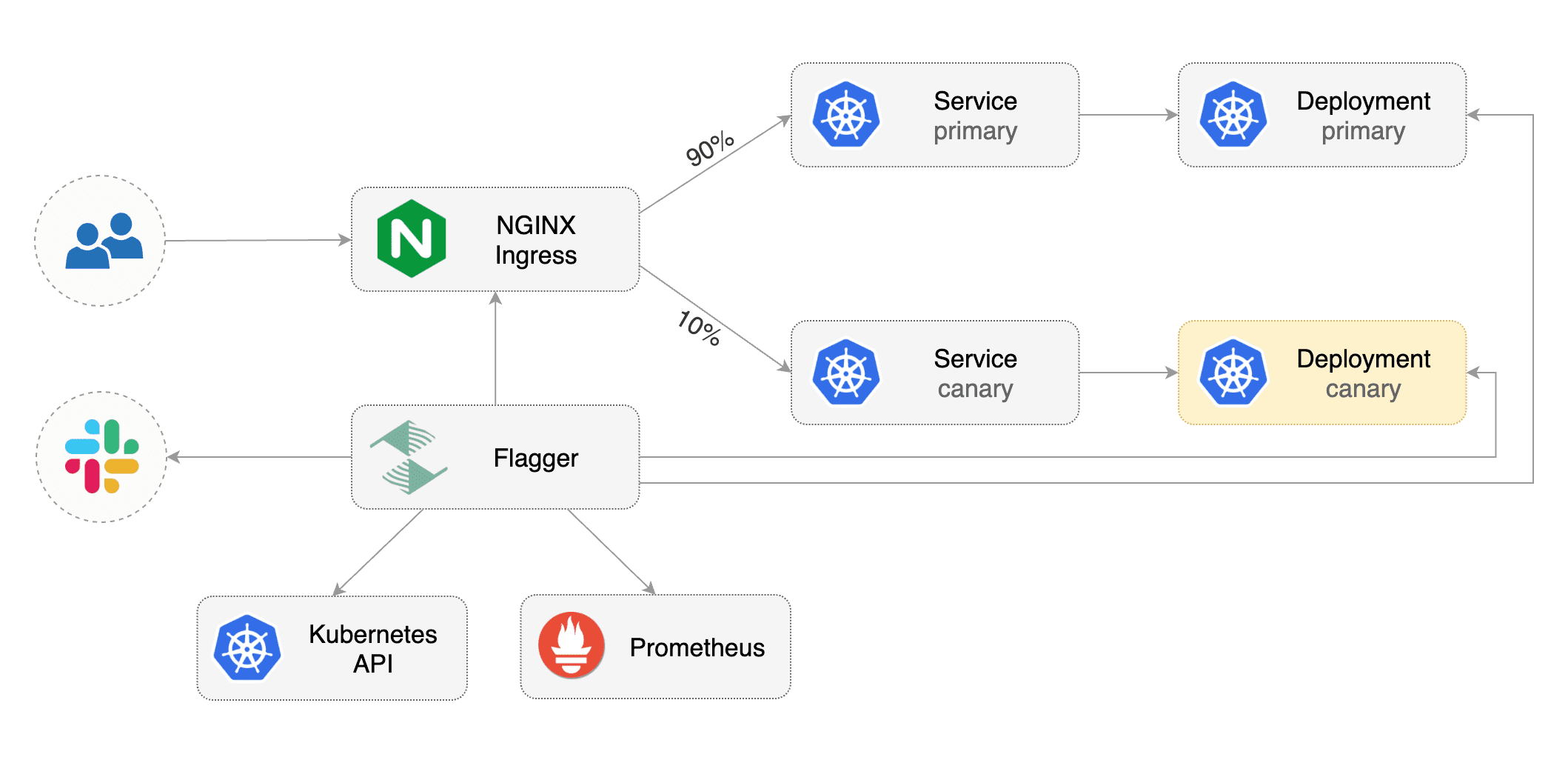
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.11** or newer and NGINX ingress **0.24** or newer.
|
||||
|
||||
Install NGINX with Helm v3:
|
||||
|
||||
```bash
|
||||
kubectl create ns ingress-nginx
|
||||
helm upgrade -i nginx-ingress stable/nginx-ingress \
|
||||
--namespace ingress-nginx \
|
||||
--set controller.stats.enabled=true \
|
||||
--set controller.metrics.enabled=true \
|
||||
--set controller.podAnnotations."prometheus\.io/scrape"=true \
|
||||
--set controller.podAnnotations."prometheus\.io/port"=10254
|
||||
```
|
||||
|
||||
Install Flagger and the Prometheus add-on in the same namespace as NGINX:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace ingress-nginx \
|
||||
--set prometheus.install=true \
|
||||
--set meshProvider=nginx
|
||||
```
|
||||
|
||||
Optionally you can enable Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--reuse-values \
|
||||
--namespace ingress-nginx \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and canary ingress).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Create an ingress definition \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
labels:
|
||||
app: podinfo
|
||||
annotations:
|
||||
kubernetes.io/ingress.class: "nginx"
|
||||
spec:
|
||||
rules:
|
||||
- host: app.example.com
|
||||
http:
|
||||
paths:
|
||||
- backend:
|
||||
serviceName: podinfo
|
||||
servicePort: 80
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-ingress.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-ingress.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
provider: nginx
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
# ingress reference
|
||||
ingressRef:
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
name: podinfo
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
# the maximum time in seconds for the canary deployment
|
||||
# to make progress before it is rollback (default 600s)
|
||||
progressDeadlineSeconds: 60
|
||||
service:
|
||||
# ClusterIP port number
|
||||
port: 80
|
||||
# container port number or name
|
||||
targetPort: 9898
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 10s
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
# NGINX Prometheus checks
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
# testing (optional)
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://app.example.com/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
ingresses.extensions/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
ingresses.extensions/podinfo-canary
|
||||
```
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.1
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 20
|
||||
Normal Synced 2m flagger Advance podinfo.test canary weight 25
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 30
|
||||
Normal Synced 1m flagger Advance podinfo.test canary weight 35
|
||||
Normal Synced 55s flagger Advance podinfo.test canary weight 40
|
||||
Normal Synced 45s flagger Advance podinfo.test canary weight 45
|
||||
Normal Synced 35s flagger Advance podinfo.test canary weight 50
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-05-06T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-05-05T16:15:07Z
|
||||
prod backend Failed 0 2019-05-04T17:05:07Z
|
||||
```
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors to test if Flagger pauses and rolls back the faulted version.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
watch curl http://app.example.com/status/500
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 10
|
||||
Phase: Failed
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger Starting canary deployment for podinfo.test
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 5
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary weight 15
|
||||
Normal Synced 3m flagger Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Normal Synced 2m flagger Halt podinfo.test advancement success rate 47.00% < 99%
|
||||
Normal Synced 2m flagger (combined from similar events): Halt podinfo.test advancement success rate 38.08% < 99%
|
||||
Warning Synced 1m flagger Rolling back podinfo.test failed checks threshold reached 10
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the
|
||||
HTTP request duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: latency
|
||||
namespace: test
|
||||
spec:
|
||||
provider:
|
||||
type: prometheus
|
||||
address: http://flagger-promethues.ingress-nginx:9090
|
||||
query: |
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
rate(
|
||||
http_request_duration_seconds_bucket{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
}[1m]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
Edit the canary analysis and add the latency check:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "latency"
|
||||
templateRef:
|
||||
name: latency
|
||||
thresholdRange:
|
||||
max: 0.5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second
|
||||
then the analysis will fail and the canary will not be promoted.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.3
|
||||
```
|
||||
|
||||
Generate high response latency:
|
||||
|
||||
```bash
|
||||
watch curl http://app.exmaple.com/delay/2
|
||||
```
|
||||
|
||||
Watch Flagger logs:
|
||||
|
||||
```text
|
||||
kubectl -n nginx-ingress logs deployment/flagger -f | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement latency 1.20 > 0.5
|
||||
Halt podinfo.test advancement latency 1.45 > 0.5
|
||||
Halt podinfo.test advancement latency 1.60 > 0.5
|
||||
Halt podinfo.test advancement latency 1.69 > 0.5
|
||||
Halt podinfo.test advancement latency 1.70 > 0.5
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have alerting configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
iterations: 10
|
||||
match:
|
||||
# curl -H 'X-Canary: insider' http://app.example.com
|
||||
- headers:
|
||||
x-canary:
|
||||
exact: "insider"
|
||||
# curl -b 'canary=always' http://app.example.com
|
||||
- headers:
|
||||
cookie:
|
||||
exact: "canary"
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: canary=always' http://app.example.com/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `canary` cookie
|
||||
set to `always` or those that call the service using the `X-Canary: insider` header.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.4
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts the A/B testing:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
Type Reason Age From Message
|
||||
---- ------ ---- ---- -------
|
||||
Normal Synced 3m flagger New revision detected podinfo.test
|
||||
Normal Synced 3m flagger Scaling up podinfo.test
|
||||
Warning Synced 3m flagger Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 1/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 2/10
|
||||
Normal Synced 3m flagger Advance podinfo.test canary iteration 3/10
|
||||
Normal Synced 2m flagger Advance podinfo.test canary iteration 4/10
|
||||
Normal Synced 2m flagger Advance podinfo.test canary iteration 5/10
|
||||
Normal Synced 1m flagger Advance podinfo.test canary iteration 6/10
|
||||
Normal Synced 1m flagger Advance podinfo.test canary iteration 7/10
|
||||
Normal Synced 55s flagger Advance podinfo.test canary iteration 8/10
|
||||
Normal Synced 45s flagger Advance podinfo.test canary iteration 9/10
|
||||
Normal Synced 35s flagger Advance podinfo.test canary iteration 10/10
|
||||
Normal Synced 25s flagger Copying podinfo.test template spec to podinfo-primary.test
|
||||
Warning Synced 15s flagger Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
185
docs/tutorials/zero-downtime-deployments.md
Normal file
185
docs/tutorials/zero-downtime-deployments.md
Normal file
@@ -0,0 +1,185 @@
|
||||
# Zero downtime deployments
|
||||
|
||||
This is a list of things you should consider when dealing with a high traffic production environment if you want to minimise the impact of rolling updates and downscaling.
|
||||
|
||||
## Deployment strategy
|
||||
|
||||
Limit the number of unavailable pods during a rolling update:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
progressDeadlineSeconds: 120
|
||||
strategy:
|
||||
type: RollingUpdate
|
||||
rollingUpdate:
|
||||
maxUnavailable: 0
|
||||
```
|
||||
|
||||
The default progress deadline for a deployment is ten minutes. You should consider adjusting this value to make the deployment process fail faster.
|
||||
|
||||
## Liveness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if your app transitioned to a broken state from which it can't recover and needs to be restarted.
|
||||
|
||||
```yaml
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/healthz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
```
|
||||
|
||||
If you've enabled mTLS, you'll have to use `exec` for liveness and readiness checks since kubelet is not part of the service mesh and doesn't have access to the TLS cert.
|
||||
|
||||
## Readiness health check
|
||||
|
||||
You application should expose a HTTP endpoint that Kubernetes can call to determine if your app is ready to receive traffic.
|
||||
|
||||
```yaml
|
||||
readinessProbe:
|
||||
exec:
|
||||
command:
|
||||
- wget
|
||||
- --quiet
|
||||
- --tries=1
|
||||
- --timeout=4
|
||||
- --spider
|
||||
- http://localhost:8080/readyz
|
||||
timeoutSeconds: 5
|
||||
initialDelaySeconds: 5
|
||||
periodSeconds: 5
|
||||
```
|
||||
|
||||
If your app depends on external services, you should check if those services are available before allowing Kubernetes to route traffic to an app instance. Keep in mind that the Envoy sidecar can have a slower startup than your app. This means that on application start you should retry for at least a couple of seconds any external connection.
|
||||
|
||||
## Graceful shutdown
|
||||
|
||||
Before a pod gets terminated, Kubernetes sends a `SIGTERM` signal to every container and waits for period of time \(30s by default\) for all containers to exit gracefully. If your app doesn't handle the `SIGTERM` signal or if it doesn't exit within the grace period, Kubernetes will kill the container and any inflight requests that your app is processing will fail.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
terminationGracePeriodSeconds: 60
|
||||
containers:
|
||||
- name: app
|
||||
lifecycle:
|
||||
preStop:
|
||||
exec:
|
||||
command:
|
||||
- sleep
|
||||
- "10"
|
||||
```
|
||||
|
||||
Your app container should have a `preStop` hook that delays the container shutdown. This will allow the service mesh to drain the traffic and remove this pod from all other Envoy sidecars before your app becomes unavailable.
|
||||
|
||||
## Delay Envoy shutdown
|
||||
|
||||
Even if your app reacts to `SIGTERM` and tries to complete the inflight requests before shutdown, that doesn't mean that the response will make it back to the caller. If the Envoy sidecar shuts down before your app, then the caller will receive a 503 error.
|
||||
|
||||
To mitigate this issue you can add a `preStop` hook to the Istio proxy and wait for the main app to exist before Envoy exists.
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
set -e
|
||||
if ! pidof envoy &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
if ! pidof pilot-agent &>/dev/null; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
while [ $(netstat -plunt | grep tcp | grep -v envoy | wc -l | xargs) -ne 0 ]; do
|
||||
sleep 1;
|
||||
done
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
You'll have to build your own Envoy docker image with the above script and modify the Istio injection webhook with the `preStop` directive.
|
||||
|
||||
Thanks to Stono for his excellent [tips](https://github.com/istio/istio/issues/12183) on minimising 503s.
|
||||
|
||||
## Resource requests and limits
|
||||
|
||||
Setting CPU and memory requests/limits for all workloads is a mandatory step if you're running a production system. Without limits your nodes could run out of memory or become unresponsive due to CPU exhausting. Without CPU and memory requests, the Kubernetes scheduler will not be able to make decisions about which nodes to place pods on.
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: app
|
||||
resources:
|
||||
limits:
|
||||
cpu: 1000m
|
||||
memory: 1Gi
|
||||
requests:
|
||||
cpu: 100m
|
||||
memory: 128Mi
|
||||
```
|
||||
|
||||
Note that without resource requests the horizontal pod autoscaler can't determine when to scale your app.
|
||||
|
||||
## Autoscaling
|
||||
|
||||
A production environment should be able to handle traffic bursts without impacting the quality of service. This can be achieved with Kubernetes autoscaling capabilities. Autoscaling in Kubernetes has two dimensions: the Cluster Autoscaler that deals with node scaling operations and the Horizontal Pod Autoscaler that automatically scales the number of pods in a deployment.
|
||||
|
||||
```yaml
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
spec:
|
||||
scaleTargetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: app
|
||||
minReplicas: 2
|
||||
maxReplicas: 4
|
||||
metrics:
|
||||
- type: Resource
|
||||
resource:
|
||||
name: cpu
|
||||
targetAverageValue: 900m
|
||||
- type: Resource
|
||||
resource:
|
||||
name: memory
|
||||
targetAverageValue: 768Mi
|
||||
```
|
||||
|
||||
The above HPA ensures your app will be scaled up before the pods reach the CPU or memory limits.
|
||||
|
||||
## Ingress retries
|
||||
|
||||
To minimise the impact of downscaling operations you can make use of Envoy retry capabilities.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
gateways:
|
||||
- public-gateway.istio-system.svc.cluster.local
|
||||
hosts:
|
||||
- app.example.com
|
||||
retries:
|
||||
attempts: 10
|
||||
perTryTimeout: 5s
|
||||
retryOn: "gateway-error,connect-failure,refused-stream"
|
||||
```
|
||||
|
||||
When the HPA scales down your app, your users could run into 503 errors. The above configuration will make Envoy retry the HTTP requests that failed due to gateway errors.
|
||||
|
||||
0
docs/usage/README.md
Normal file
0
docs/usage/README.md
Normal file
128
docs/usage/alerting.md
Normal file
128
docs/usage/alerting.md
Normal file
@@ -0,0 +1,128 @@
|
||||
# Alerting
|
||||
|
||||
Flagger can be configured to send alerts to various chat platforms. You can define a global alert provider at
|
||||
install time or configure alerts on a per canary basis.
|
||||
|
||||
## Global configuration
|
||||
|
||||
Flagger can be configured to send Slack notifications:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--set slack.url=https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK \
|
||||
--set slack.channel=general \
|
||||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Once configured with a Slack incoming **webhook**, Flagger will post messages when a canary deployment
|
||||
has been initialised, when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||

|
||||
|
||||
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis reached the
|
||||
maximum number of failed checks:
|
||||
|
||||

|
||||
|
||||
Flagger can be configured to send notifications to Microsoft Teams:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--set msteams.url=https://outlook.office.com/webhook/YOUR/TEAMS/WEBHOOK
|
||||
```
|
||||
|
||||
Similar to Slack, Flagger alerts on canary analysis events:
|
||||
|
||||
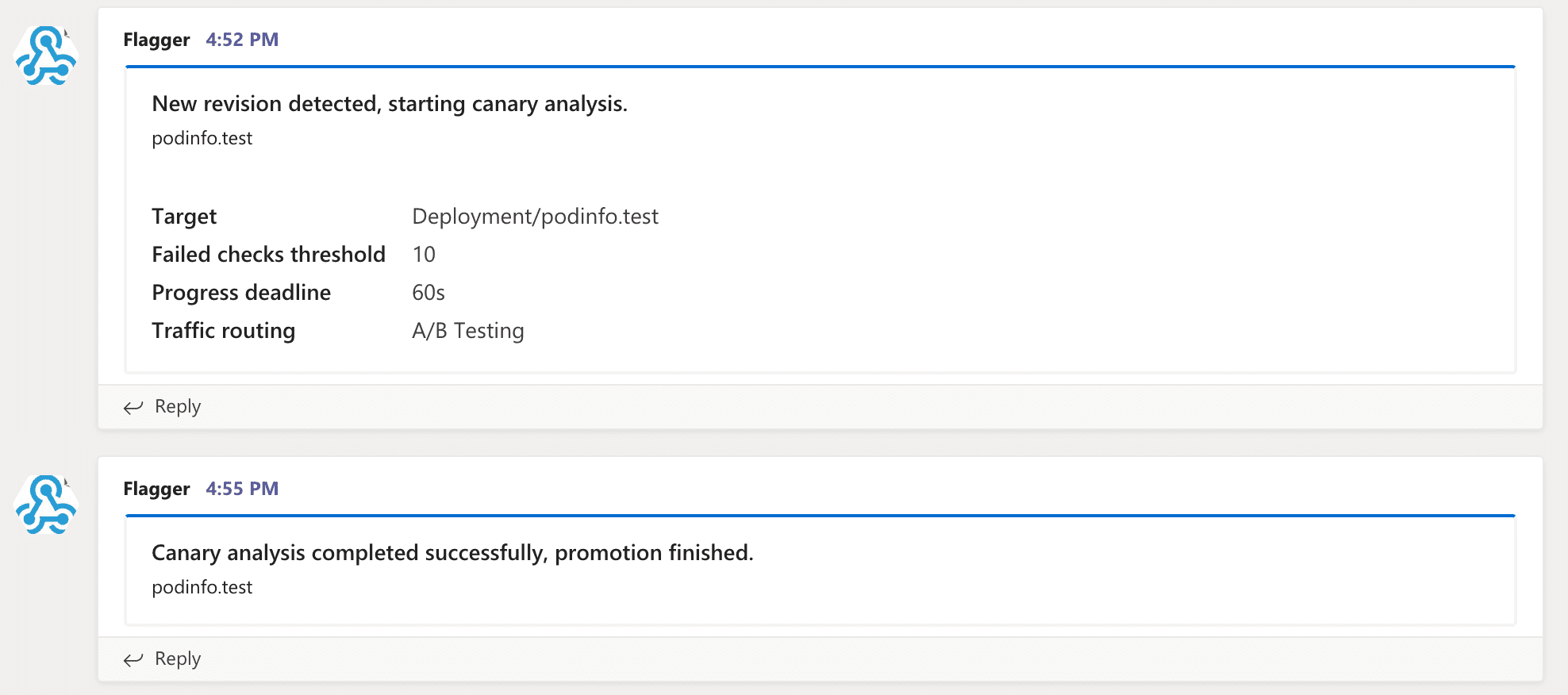
|
||||
|
||||
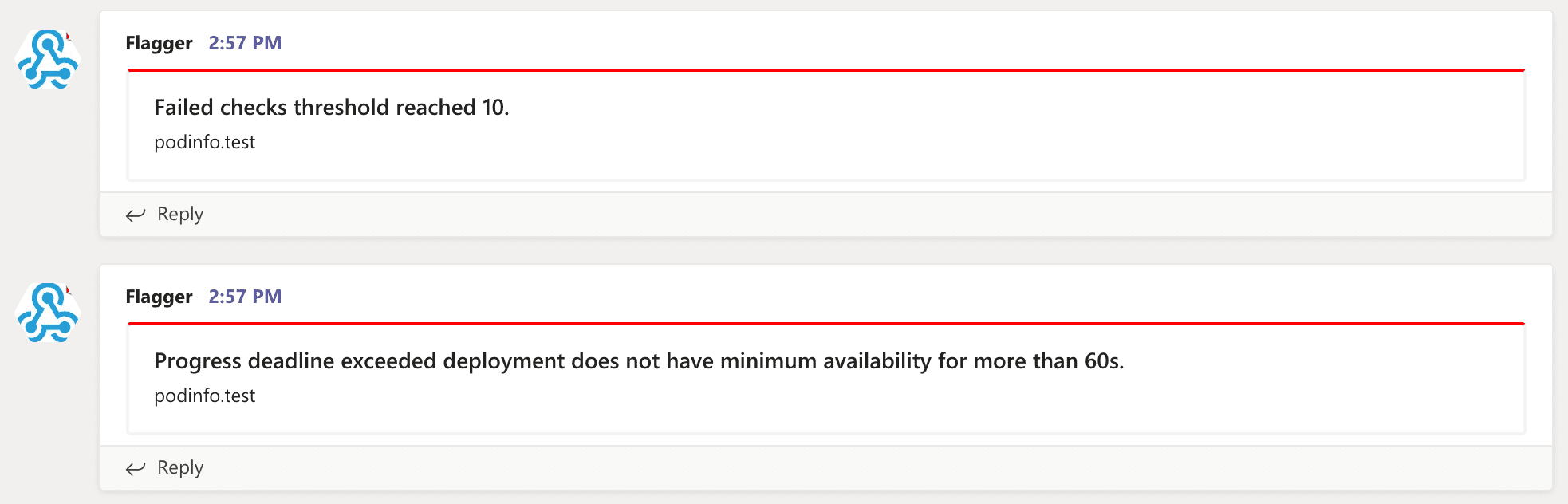
|
||||
|
||||
## Canary configuration
|
||||
|
||||
Configuring alerting globally has several limitations as it's not possible to specify different channels
|
||||
or configure the verbosity on a per canary basis.
|
||||
To make the alerting move flexible, the canary analysis can be extended
|
||||
with a list of alerts that reference an alert provider.
|
||||
For each alert, users can configure the severity level.
|
||||
The alerts section overrides the global setting.
|
||||
|
||||
Slack example:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: AlertProvider
|
||||
metadata:
|
||||
name: on-call
|
||||
namespace: flagger
|
||||
spec:
|
||||
type: slack
|
||||
channel: on-call-alerts
|
||||
username: flagger
|
||||
# webhook address (ignored if secretRef is specified)
|
||||
address: https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK
|
||||
# secret containing the webhook address (optional)
|
||||
secretRef:
|
||||
name: on-call-url
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: on-call-url
|
||||
namespace: flagger
|
||||
data:
|
||||
address: <encoded-url>
|
||||
```
|
||||
|
||||
The alert provider **type** can be: `slack`, `msteams`, `rocket` or `discord`. When set to `discord`,
|
||||
Flagger will use [Slack formatting](https://birdie0.github.io/discord-webhooks-guide/other/slack_formatting.html)
|
||||
and will append `/slack` to the Discord address.
|
||||
|
||||
When not specified, **channel** defaults to `general` and **username** defaults to `flagger`.
|
||||
|
||||
When **secretRef** is specified, the Kubernetes secret must contain a data field named `address`,
|
||||
the address in the secret will take precedence over the **address** field in the provider spec.
|
||||
|
||||
The canary analysis can have a list of alerts, each alert referencing an alert provider:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
alerts:
|
||||
- name: "on-call Slack"
|
||||
severity: error
|
||||
providerRef:
|
||||
name: on-call
|
||||
namespace: flagger
|
||||
- name: "qa Discord"
|
||||
severity: warn
|
||||
providerRef:
|
||||
name: qa-discord
|
||||
- name: "dev MS Teams"
|
||||
severity: info
|
||||
providerRef:
|
||||
name: dev-msteams
|
||||
```
|
||||
|
||||
Alert fields:
|
||||
* **name** (required)
|
||||
* **severity** levels: `info`, `warn`, `error` (default info)
|
||||
* **providerRef.name** alert provider name (required)
|
||||
* **providerRef.namespace** alert provider namespace (defaults to the canary namespace)
|
||||
|
||||
When the severity is set to `warn`, Flagger will alert when waiting on manual confirmation or if the analysis fails.
|
||||
When the severity is set to `error`, Flagger will alert only if the canary analysis fails.
|
||||
|
||||
## Prometheus Alert Manager
|
||||
|
||||
You can use Alertmanager to trigger alerts when a canary deployment failed:
|
||||
|
||||
```yaml
|
||||
- alert: canary_rollback
|
||||
expr: flagger_canary_status > 1
|
||||
for: 1m
|
||||
labels:
|
||||
severity: warning
|
||||
annotations:
|
||||
summary: "Canary failed"
|
||||
description: "Workload {{ $labels.name }} namespace {{ $labels.namespace }}"
|
||||
```
|
||||
|
||||
305
docs/usage/deployment-strategies.md
Normal file
305
docs/usage/deployment-strategies.md
Normal file
@@ -0,0 +1,305 @@
|
||||
# Deployment Strategies
|
||||
|
||||
Flagger can run automated application analysis, promotion and rollback for the following deployment strategies:
|
||||
* **Canary Release** (progressive traffic shifting)
|
||||
* Istio, Linkerd, App Mesh, NGINX, Contour, Gloo
|
||||
* **A/B Testing** (HTTP headers and cookies traffic routing)
|
||||
* Istio, App Mesh, NGINX, Contour
|
||||
* **Blue/Green** (traffic switching)
|
||||
* Kubernetes CNI, Istio, Linkerd, App Mesh, NGINX, Contour, Gloo
|
||||
* **Blue/Green Mirroring** (traffic shadowing)
|
||||
* Istio
|
||||
|
||||
For Canary releases and A/B testing you'll need a Layer 7 traffic management solution like a service mesh or an ingress controller.
|
||||
For Blue/Green deployments no service mesh or ingress controller is required.
|
||||
|
||||
A canary analysis is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* ConfigMaps mounted as volumes or mapped to environment variables
|
||||
* Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
## Canary Release
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance
|
||||
indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
|
||||

|
||||
|
||||
The canary analysis runs periodically until it reaches the maximum traffic weight or the failed checks threshold.
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 10
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 2
|
||||
# deploy straight to production without
|
||||
# the metrics and webhook checks
|
||||
skipAnalysis: false
|
||||
```
|
||||
|
||||
The above analysis, if it succeeds, will run for 25 minutes while validating the HTTP metrics and webhooks every minute.
|
||||
You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
|
||||
|
||||
```
|
||||
interval * (maxWeight / stepWeight)
|
||||
```
|
||||
|
||||
And the time it takes for a canary to be rollback when the metrics or webhook checks are failing:
|
||||
|
||||
```
|
||||
interval * threshold
|
||||
```
|
||||
|
||||
In emergency cases, you may want to skip the analysis phase and ship changes directly to production.
|
||||
At any time you can set the `spec.skipAnalysis: true`.
|
||||
When skip analysis is enabled, Flagger checks if the canary deployment is healthy and
|
||||
promotes it without analysing it. If an analysis is underway, Flagger cancels it and runs the promotion.
|
||||
|
||||
Gated canary promotion stages:
|
||||
|
||||
* scan for canary deployments
|
||||
* check primary and canary deployment status
|
||||
* halt advancement if a rolling update is underway
|
||||
* halt advancement if pods are unhealthy
|
||||
* call confirm-rollout webhooks and check results
|
||||
* halt advancement if any hook returns a non HTTP 2xx result
|
||||
* call pre-rollout webhooks and check results
|
||||
* halt advancement if any hook returns a non HTTP 2xx result
|
||||
* increment the failed checks counter
|
||||
* increase canary traffic weight percentage from 0% to 2% (step weight)
|
||||
* call rollout webhooks and check results
|
||||
* check canary HTTP request success rate and latency
|
||||
* halt advancement if any metric is under the specified threshold
|
||||
* increment the failed checks counter
|
||||
* check if the number of failed checks reached the threshold
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment and mark it as failed
|
||||
* call post-rollout webhooks
|
||||
* post the analysis result to Slack
|
||||
* wait for the canary deployment to be updated and start over
|
||||
* increase canary traffic weight by 2% (step weight) till it reaches 50% (max weight)
|
||||
* halt advancement if any webhook call fails
|
||||
* halt advancement while canary request success rate is under the threshold
|
||||
* halt advancement while canary request duration P99 is over the threshold
|
||||
* halt advancement while any custom metric check fails
|
||||
* halt advancement if the primary or canary deployment becomes unhealthy
|
||||
* halt advancement while canary deployment is being scaled up/down by HPA
|
||||
* call confirm-promotion webhooks and check results
|
||||
* halt advancement if any hook returns a non HTTP 2xx result
|
||||
* promote canary to primary
|
||||
* copy ConfigMaps and Secrets from canary to primary
|
||||
* copy canary deployment spec template over primary
|
||||
* wait for primary rolling update to finish
|
||||
* halt advancement if pods are unhealthy
|
||||
* route all traffic to primary
|
||||
* scale to zero the canary deployment
|
||||
* mark rollout as finished
|
||||
* call post-rollout webhooks
|
||||
* send notification with the canary analysis result
|
||||
* wait for the canary deployment to be updated and start over
|
||||
|
||||
## A/B Testing
|
||||
|
||||
For frontend applications that require session affinity you should use HTTP headers or cookies match conditions
|
||||
to ensure a set of users will stay on the same version for the whole duration of the canary analysis.
|
||||
|
||||

|
||||
|
||||
You can enable A/B testing by specifying the HTTP match conditions and the number of iterations.
|
||||
If Flagger finds a HTTP match condition, it will ignore the `maxWeight` and `stepWeight` settings.
|
||||
|
||||
Istio example:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
# canary match condition
|
||||
match:
|
||||
- headers:
|
||||
x-canary:
|
||||
regex: ".*insider.*"
|
||||
- headers:
|
||||
cookie:
|
||||
regex: "^(.*?;)?(canary=always)(;.*)?$"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting the Safari users and those that have a test cookie.
|
||||
You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
|
||||
|
||||
```
|
||||
interval * iterations
|
||||
```
|
||||
|
||||
And the time it takes for a canary to be rollback when the metrics or webhook checks are failing:
|
||||
|
||||
```
|
||||
interval * threshold
|
||||
```
|
||||
|
||||
App Mesh example:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
iterations: 2
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
regex: ".*Chrome.*"
|
||||
```
|
||||
|
||||
Note that App Mesh supports a single condition.
|
||||
|
||||
Contour example:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
iterations: 2
|
||||
match:
|
||||
- headers:
|
||||
user-agent:
|
||||
prefix: "Chrome"
|
||||
```
|
||||
|
||||
Note that Contour does not support regex, you can use prefix, suffix or exact.
|
||||
|
||||
NGINX example:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
iterations: 2
|
||||
match:
|
||||
- headers:
|
||||
x-canary:
|
||||
exact: "insider"
|
||||
- headers:
|
||||
cookie:
|
||||
exact: "canary"
|
||||
```
|
||||
|
||||
Note that the NGINX ingress controller supports only exact matching for a single header and the cookie value is set to `always`.
|
||||
|
||||
The above configurations will route users with the x-canary header or canary cookie to the canary instance during analysis:
|
||||
|
||||
```bash
|
||||
curl -H 'X-Canary: insider' http://app.example.com
|
||||
curl -b 'canary=always' http://app.example.com
|
||||
```
|
||||
|
||||
## Blue/Green Deployments
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate blue/green style deployments
|
||||
with Kubernetes L4 networking. When using Istio you have the option to mirror traffic between blue and green.
|
||||
|
||||

|
||||
|
||||
You can use the blue/green deployment strategy by replacing `stepWeight/maxWeight` with `iterations` in the `canaryAnalysis` spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
```
|
||||
|
||||
With the above configuration Flagger will run conformance and load tests on the canary pods for ten minutes.
|
||||
If the metrics analysis succeeds, live traffic will be switched from the old version to the new one when the
|
||||
canary is promoted.
|
||||
|
||||
The blue/green deployment strategy is supported for all service mesh providers.
|
||||
|
||||
Blue/Green rollout steps for service mesh:
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* scale up the canary (green)
|
||||
* run conformance tests for the canary pods
|
||||
* run load tests and metric checks for the canary pods every minute
|
||||
* abort the canary release if the failure threshold is reached
|
||||
* route traffic to canary
|
||||
* promote canary spec over primary (blue)
|
||||
* wait for primary rollout
|
||||
* route traffic to primary
|
||||
* scale down canary
|
||||
|
||||
After the analysis finishes, the traffic is routed to the canary (green) before triggering the primary (blue)
|
||||
rolling update, this ensures a smooth transition to the new version avoiding dropping in-flight requests during
|
||||
the Kubernetes deployment rollout.
|
||||
|
||||
## Blue/Green with Traffic Mirroring
|
||||
|
||||
Traffic Mirroring is a pre-stage in a Canary (progressive traffic shifting) or
|
||||
Blue/Green deployment strategy. Traffic mirroring will copy each incoming
|
||||
request, sending one request to the primary and one to the canary service.
|
||||
The response from the primary is sent back to the user. The response from the canary
|
||||
is discarded. Metrics are collected on both requests so that the deployment will
|
||||
only proceed if the canary metrics are healthy.
|
||||
|
||||
Mirroring should be used for requests that are **idempotent** or capable of
|
||||
being processed twice (once by the primary and once by the canary). Reads are
|
||||
idempotent. Before using mirroring on requests that may be writes, you should
|
||||
consider what will happen if a write is duplicated and handled by the primary
|
||||
and canary.
|
||||
|
||||
To use mirroring, set `spec.canaryAnalysis.mirror` to `true`.
|
||||
|
||||
Istio example:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# total number of iterations
|
||||
iterations: 10
|
||||
# max number of failed iterations before rollback
|
||||
threshold: 2
|
||||
# Traffic shadowing (compatible with Istio only)
|
||||
mirror: true
|
||||
```
|
||||
|
||||
Mirroring rollout steps for service mesh:
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* scale from zero the canary deployment
|
||||
* wait for the HPA to set the canary minimum replicas
|
||||
* check canary pods health
|
||||
* run the acceptance tests
|
||||
* abort the canary release if tests fail
|
||||
* start the load tests
|
||||
* mirror traffic from primary to canary
|
||||
* check request success rate and request duration every minute
|
||||
* abort the canary release if the failure threshold is reached
|
||||
* stop traffic mirroring after the number of iterations is reached
|
||||
* route live traffic to the canary pods
|
||||
* promote the canary (update the primary secrets, configmaps and deployment spec)
|
||||
* wait for the primary deployment rollout to finish
|
||||
* wait for the HPA to set the primary minimum replicas
|
||||
* check primary pods health
|
||||
* switch live traffic back to primary
|
||||
* scale to zero the canary
|
||||
* send notification with the canary analysis result
|
||||
|
||||
After the analysis finishes, the traffic is routed to the canary (green) before triggering the primary (blue)
|
||||
rolling update, this ensures a smooth transition to the new version avoiding dropping in-flight requests during
|
||||
the Kubernetes deployment rollout.
|
||||
285
docs/usage/how-it-works.md
Normal file
285
docs/usage/how-it-works.md
Normal file
@@ -0,0 +1,285 @@
|
||||
# How it works
|
||||
|
||||
[Flagger](https://github.com/weaveworks/flagger) can be configured to automate the release process
|
||||
for Kubernetes workloads with a custom resource named canary.
|
||||
|
||||
## Canary resource
|
||||
|
||||
The canary custom resource defines the release process of an application running on Kubernetes
|
||||
and is portable across clusters, service meshes and ingress providers.
|
||||
|
||||
For a deployment named _podinfo_, a canary release with progressive traffic shifting can be defined as:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
spec:
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
service:
|
||||
port: 9898
|
||||
analysis:
|
||||
interval: 1m
|
||||
threshold: 10
|
||||
maxWeight: 50
|
||||
stepWeight: 5
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
thresholdRange:
|
||||
min: 99
|
||||
interval: 1m
|
||||
- name: request-duration
|
||||
thresholdRange:
|
||||
max: 500
|
||||
interval: 1m
|
||||
webhooks:
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
When you deploy a new version of an app, Flagger gradually shifts traffic to the canary,
|
||||
and at the same time, measures the requests success rate as well as the average response duration.
|
||||
You can extend the canary analysis with custom metrics, acceptance and load testing
|
||||
to harden the validation process of your app release process.
|
||||
|
||||
If you are running multiple service meshes or ingress controllers in the same cluster,
|
||||
you can override the global provider for a specific canary with `spec.provider`.
|
||||
|
||||
## Canary target
|
||||
|
||||
A canary resource can target a Kubernetes Deployment or DaemonSet.
|
||||
|
||||
Kubernetes Deployment example:
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
progressDeadlineSeconds: 60
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta1
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
```
|
||||
|
||||
Based on the above configuration, Flagger generates the following Kubernetes objects:
|
||||
|
||||
* `deployment/<targetRef.name>-primary`
|
||||
* `hpa/<autoscalerRef.name>-primary`
|
||||
|
||||
The primary deployment is considered the stable release of your app, by default all traffic is routed to this version
|
||||
and the target deployment is scaled to zero.
|
||||
Flagger will detect changes to the target deployment (including secrets and configmaps) and will perform a
|
||||
canary analysis before promoting the new version as primary.
|
||||
|
||||
If the target deployment uses secrets and/or configmaps, Flagger will create a copy of each object using the `-primary`
|
||||
prefix and will reference these objects in the primary deployment. You can disable the secrets/configmaps tracking
|
||||
with the `-enable-config-tracking=false` command flag in the Flagger deployment manifest under containers args
|
||||
or by setting `--set configTracking.enabled=false` when installing Flagger with Helm.
|
||||
|
||||
**Note** that the target deployment must have a single label selector in the format `app: <DEPLOYMENT-NAME>`:
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: podinfo
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: podinfo
|
||||
```
|
||||
|
||||
Besides `app` Flagger supports `name` and `app.kubernetes.io/name` selectors.
|
||||
If you use a different convention you can specify your label with
|
||||
the `-selector-labels=my-app-label` command flag in the Flagger deployment manifest under containers args
|
||||
or by setting `--set selectorLabels=my-app-label` when installing Flagger with Helm.
|
||||
|
||||
The autoscaler reference is optional, when specified, Flagger will pause the traffic increase while the
|
||||
target and primary deployments are scaled up or down. HPA can help reduce the resource usage during the canary analysis.
|
||||
|
||||
The progress deadline represents the maximum time in seconds for the canary deployment to make progress
|
||||
before it is rolled back, defaults to ten minutes.
|
||||
|
||||
## Canary service
|
||||
|
||||
A canary resource dictates how the target workload is exposed inside the cluster.
|
||||
The canary target should expose a TCP port that will be used by Flagger to create the ClusterIP Services.
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
service:
|
||||
name: podinfo
|
||||
port: 9898
|
||||
portName: http
|
||||
targetPort: 9898
|
||||
portDiscovery: true
|
||||
```
|
||||
|
||||
The container port from the target workload should match the `service.port` or `service.targetPort`.
|
||||
The `service.name` is optional, defaults to `spec.targetRef.name`.
|
||||
The `service.targetPort` can be a container port number or name.
|
||||
The `service.portName` is optional (defaults to `http`), if your workload uses gPRC then set the port name to `grcp`.
|
||||
|
||||
If port discovery is enabled, Flagger scans the target workload and extracts the containers
|
||||
ports excluding the port specified in the canary service and service mesh sidecar ports.
|
||||
These ports will be used when generating the ClusterIP services.
|
||||
|
||||
Based on the canary spec service, Flagger creates the following Kubernetes ClusterIP service:
|
||||
|
||||
* `<service.name>.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>-primary`
|
||||
* `<service.name>-primary.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>-primary`
|
||||
* `<service.name>-canary.<namespace>.svc.cluster.local`
|
||||
selector `app=<name>`
|
||||
|
||||
This ensures that traffic to `podinfo.test:9898` will be routed to the latest stable release of your app.
|
||||
The `podinfo-canary.test:9898` address is available only during the
|
||||
canary analysis and can be used for conformance testing or load testing.
|
||||
|
||||
Besides the port mapping, the service specification can contain URI match and rewrite rules,
|
||||
timeout and retry polices:
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
service:
|
||||
port: 9898
|
||||
match:
|
||||
- uri:
|
||||
prefix: /
|
||||
rewrite:
|
||||
uri: /
|
||||
retries:
|
||||
attempts: 3
|
||||
perTryTimeout: 1s
|
||||
timeout: 5s
|
||||
```
|
||||
|
||||
When using **Istio** as the mesh provider, you can also specify
|
||||
HTTP header operations, CORS and traffic policies, Istio gateways and hosts.
|
||||
The Istio routing configuration can be found [here](../faq.md#istio-routing).
|
||||
|
||||
## Canary status
|
||||
|
||||
You can use kubectl to get the current status of canary deployments cluster wide:
|
||||
|
||||
```bash
|
||||
kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-06-30T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-06-30T16:15:07Z
|
||||
prod backend Failed 0 2019-06-30T17:05:07Z
|
||||
```
|
||||
|
||||
The status condition reflects the last known state of the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test get canary/podinfo -oyaml | awk '/status/,0'
|
||||
```
|
||||
|
||||
A successful rollout status:
|
||||
|
||||
```yaml
|
||||
status:
|
||||
canaryWeight: 0
|
||||
failedChecks: 0
|
||||
iterations: 0
|
||||
lastAppliedSpec: "14788816656920327485"
|
||||
lastPromotedSpec: "14788816656920327485"
|
||||
conditions:
|
||||
- lastTransitionTime: "2019-07-10T08:23:18Z"
|
||||
lastUpdateTime: "2019-07-10T08:23:18Z"
|
||||
message: Canary analysis completed successfully, promotion finished.
|
||||
reason: Succeeded
|
||||
status: "True"
|
||||
type: Promoted
|
||||
```
|
||||
|
||||
The `Promoted` status condition can have one of the following reasons:
|
||||
Initialized, Waiting, Progressing, Promoting, Finalising, Succeeded or Failed.
|
||||
A failed canary will have the promoted status set to `false`,
|
||||
the reason to `failed` and the last applied spec will be different to the last promoted one.
|
||||
|
||||
Wait for a successful rollout:
|
||||
|
||||
```bash
|
||||
kubectl wait canary/podinfo --for=condition=promoted
|
||||
```
|
||||
|
||||
CI example:
|
||||
|
||||
```bash
|
||||
# update the container image
|
||||
kubectl set image deployment/podinfo podinfod=stefanprodan/podinfo:3.0.1
|
||||
|
||||
# wait for Flagger to detect the change
|
||||
ok=false
|
||||
until ${ok}; do
|
||||
kubectl get canary/podinfo | grep 'Progressing' && ok=true || ok=false
|
||||
sleep 5
|
||||
done
|
||||
|
||||
# wait for the canary analysis to finish
|
||||
kubectl wait canary/podinfo --for=condition=promoted --timeout=5m
|
||||
|
||||
# check if the deployment was successful
|
||||
kubectl get canary/podinfo | grep Succeeded
|
||||
```
|
||||
|
||||
## Canary analysis
|
||||
|
||||
The canary analysis defines:
|
||||
* the type of [deployment strategy](deployment-strategies.md)
|
||||
* the [metrics](metrics.md) used to validate the canary version
|
||||
* the [webhooks](webhooks.md) used for conformance testing, load testing and manual gating
|
||||
* the [alerting settings](alerting.md)
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval:
|
||||
# max number of failed metric checks before rollback
|
||||
threshold:
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight:
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight:
|
||||
# total number of iterations
|
||||
# used for A/B Testing and Blue/Green
|
||||
iterations:
|
||||
# canary match conditions
|
||||
# used for A/B Testing
|
||||
match:
|
||||
- # HTTP header
|
||||
# key performance indicators
|
||||
metrics:
|
||||
- # metric check
|
||||
# alerting
|
||||
alerts:
|
||||
- # alert provider
|
||||
# external checks
|
||||
webhooks:
|
||||
- # hook
|
||||
```
|
||||
|
||||
The canary analysis runs periodically until it reaches the maximum traffic weight or the number of iterations.
|
||||
On each run, Flagger calls the webhooks, checks the metrics and if the failed checks threshold is reached, stops the
|
||||
analysis and rolls back the canary. If alerting is configured, Flagger will post the analysis result using the alert providers.
|
||||
316
docs/usage/metrics.md
Normal file
316
docs/usage/metrics.md
Normal file
@@ -0,0 +1,316 @@
|
||||
# Metrics Analysis
|
||||
|
||||
As part of the analysis process, Flagger can validate service level objectives (SLOs) like
|
||||
availability, error rate percentage, average response time and any other objective based on app specific metrics.
|
||||
If a drop in performance is noticed during the SLOs analysis,
|
||||
the release will be automatically rolled back with minimum impact to end-users.
|
||||
|
||||
## Builtin metrics
|
||||
|
||||
Flagger comes with two builtin metric checks: HTTP request success rate and duration.
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: request-success-rate
|
||||
interval: 1m
|
||||
# minimum req success rate (non 5xx responses)
|
||||
# percentage (0-100)
|
||||
thresholdRange:
|
||||
min: 99
|
||||
- name: request-duration
|
||||
interval: 1m
|
||||
# maximum req duration P99
|
||||
# milliseconds
|
||||
thresholdRange:
|
||||
max: 500
|
||||
```
|
||||
|
||||
For each metric you can specify a range of accepted values with `thresholdRange`
|
||||
and the window size or the time series with `interval`.
|
||||
The builtin checks are available for every service mesh / ingress controller
|
||||
and are implemented with [Prometheus queries](../faq.md#metrics).
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The canary analysis can be extended with custom metric checks. Using a `MetricTemplate` custom resource, you
|
||||
configure Flagger to connect to a metric provider and run a query that returns a `float64` value.
|
||||
The query result is used to validate the canary based on the specified threshold range.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: my-metric
|
||||
spec:
|
||||
provider:
|
||||
type: # can be prometheus or datadog
|
||||
address: # API URL
|
||||
secretRef:
|
||||
name: # name of the secret containing the API credentials
|
||||
query: # metric query
|
||||
```
|
||||
|
||||
The following variables are available in query templates:
|
||||
|
||||
- `name` (canary.metadata.name)
|
||||
- `namespace` (canary.metadata.namespace)
|
||||
- `target` (canary.spec.targetRef.name)
|
||||
- `service` (canary.spec.service.name)
|
||||
- `ingress` (canary.spec.ingresRef.name)
|
||||
- `interval` (canary.spec.canaryAnalysis.metrics[].interval)
|
||||
|
||||
A canary analysis metric can reference a template with `templateRef`:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "my metric"
|
||||
templateRef:
|
||||
name: my-metric
|
||||
# namespace is optional
|
||||
# when not specified, the canary namespace will be used
|
||||
namespace: flagger
|
||||
# accepted values
|
||||
thresholdRange:
|
||||
min: 10
|
||||
max: 1000
|
||||
# metric query time window
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
## Prometheus
|
||||
|
||||
You can create custom metric checks targeting a Prometheus server
|
||||
by setting the provider type to `prometheus` and writing the query in PromQL.
|
||||
|
||||
Prometheus template example:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: not-found-percentage
|
||||
namespace: istio-system
|
||||
spec:
|
||||
provider:
|
||||
type: prometheus
|
||||
address: http://promethues.istio-system:9090
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="{{ namespace }}",
|
||||
destination_workload="{{ target }}",
|
||||
response_code!="404"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
istio_requests_total{
|
||||
reporter="destination",
|
||||
destination_workload_namespace="{{ namespace }}",
|
||||
destination_workload="{{ target }}"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
Reference the template in the canary analysis:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
templateRef:
|
||||
name: not-found-percentage
|
||||
namespace: istio-system
|
||||
thresholdRange:
|
||||
max: 5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking
|
||||
if the HTTP 404 req/sec percentage is below 5 percent of the total traffic.
|
||||
If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Prometheus gRPC error rate example:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: grpc-error-rate-percentage
|
||||
namespace: flagger
|
||||
spec:
|
||||
provider:
|
||||
type: prometheus
|
||||
address: http://flagger-promethues.flagger-system:9090
|
||||
query: |
|
||||
100 - sum(
|
||||
rate(
|
||||
grpc_server_handled_total{
|
||||
grpc_code!="OK",
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
)
|
||||
/
|
||||
sum(
|
||||
rate(
|
||||
grpc_server_started_total{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
kubernetes_pod_name=~"{{ target }}-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
) * 100
|
||||
```
|
||||
|
||||
The above template is for gPRC services instrumented with [go-grpc-prometheus](https://github.com/grpc-ecosystem/go-grpc-prometheus).
|
||||
|
||||
## Datadog
|
||||
|
||||
You can create custom metric checks using the Datadog provider.
|
||||
|
||||
Create a secret with your Datadog API credentials:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Secret
|
||||
metadata:
|
||||
name: datadog
|
||||
namespace: istio-system
|
||||
data:
|
||||
datadog_api_key: your-datadog-api-key
|
||||
datadog_application_key: your-datadog-application-key
|
||||
```
|
||||
|
||||
Datadog template example:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: not-found-percentage
|
||||
namespace: istio-system
|
||||
spec:
|
||||
provider:
|
||||
type: datadog
|
||||
address: https://api.datadoghq.com
|
||||
secretRef:
|
||||
name: datadog
|
||||
query: |
|
||||
100 - (
|
||||
sum:istio.mesh.request.count{
|
||||
reporter:destination,
|
||||
destination_workload_namespace:{{ namespace }},
|
||||
destination_workload:{{ target }},
|
||||
!response_code:404
|
||||
}.as_count()
|
||||
/
|
||||
sum:istio.mesh.request.count{
|
||||
reporter:destination,
|
||||
destination_workload_namespace:{{ namespace }},
|
||||
destination_workload:{{ target }}
|
||||
}.as_count()
|
||||
) * 100
|
||||
```
|
||||
|
||||
Reference the template in the canary analysis:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "404s percentage"
|
||||
templateRef:
|
||||
name: not-found-percentage
|
||||
namespace: istio-system
|
||||
thresholdRange:
|
||||
max: 5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
|
||||
## Amazon CloudWatch
|
||||
|
||||
You can create custom metric checks using the CloudWatch metrics provider.
|
||||
|
||||
CloudWatch template example:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1alpha1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: cloudwatch-error-rate
|
||||
spec:
|
||||
provider:
|
||||
type: cloudwatch
|
||||
region: ap-northeast-1 # specify the region of your metrics
|
||||
query: |
|
||||
[
|
||||
{
|
||||
"Id": "e1",
|
||||
"Expression": "m1 / m2",
|
||||
"Label": "ErrorRate"
|
||||
},
|
||||
{
|
||||
"Id": "m1",
|
||||
"MetricStat": {
|
||||
"Metric": {
|
||||
"Namespace": "MyKubernetesCluster",
|
||||
"MetricName": "ErrorCount",
|
||||
"Dimensions": [
|
||||
{
|
||||
"Name": "appName",
|
||||
"Value": "{{ name }}.{{ namespace }}"
|
||||
}
|
||||
]
|
||||
},
|
||||
"Period": 60,
|
||||
"Stat": "Sum",
|
||||
"Unit": "Count"
|
||||
},
|
||||
"ReturnData": false
|
||||
},
|
||||
{
|
||||
"Id": "m2",
|
||||
"MetricStat": {
|
||||
"Metric": {
|
||||
"Namespace": "MyKubernetesCluster",
|
||||
"MetricName": "RequestCount",
|
||||
"Dimensions": [
|
||||
{
|
||||
"Name": "appName",
|
||||
"Value": "{{ name }}.{{ namespace }}"
|
||||
}
|
||||
]
|
||||
},
|
||||
"Period": 60,
|
||||
"Stat": "Sum",
|
||||
"Unit": "Count"
|
||||
},
|
||||
"ReturnData": false
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
The query format documentation can be found [here](https://aws.amazon.com/premiumsupport/knowledge-center/cloudwatch-getmetricdata-api/).
|
||||
|
||||
Reference the template in the canary analysis:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
metrics:
|
||||
- name: "app error rate"
|
||||
templateRef:
|
||||
name: cloudwatch-error-rate
|
||||
thresholdRange:
|
||||
max: 0.1
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
**Note** that Flagger need AWS IAM permission to perform `cloudwatch:GetMetricData` to use this provider.
|
||||
119
docs/usage/monitoring.md
Normal file
119
docs/usage/monitoring.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# Monitoring
|
||||
|
||||
## Grafana
|
||||
|
||||
Flagger comes with a Grafana dashboard made for canary analysis. Install Grafana with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \ # or appmesh-system
|
||||
--set url=http://prometheus:9090
|
||||
```
|
||||
|
||||
The dashboard shows the RED and USE metrics for the primary and canary workloads:
|
||||
|
||||
|
||||
|
||||
## Logging
|
||||
|
||||
The canary errors and latency spikes have been recorded as Kubernetes events and logged by Flagger in json format:
|
||||
|
||||
```text
|
||||
kubectl -n istio-system logs deployment/flagger --tail=100 | jq .msg
|
||||
|
||||
Starting canary deployment for podinfo.test
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Halt podinfo.test advancement success rate 98.69% < 99%
|
||||
Advance podinfo.test canary weight 40
|
||||
Halt podinfo.test advancement request duration 1.515s > 500ms
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Halt podinfo-primary.test advancement waiting for rollout to finish: 1 old replicas are pending termination
|
||||
Scaling down podinfo.test
|
||||
Promotion completed! podinfo.test
|
||||
```
|
||||
|
||||
## Event Webhook
|
||||
|
||||
Flagger can be configured to send event payloads to a specified webhook:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--set eventWebhook=https://example.com/flagger-canary-event-webhook
|
||||
```
|
||||
|
||||
The environment variable _EVENT\_WEBHOOK\_URL_ can be used for activating the event-webhook, too. This is handy for using a secret to store a sensible value that could contain api keys for example.
|
||||
|
||||
When configured, every action that Flagger takes during a canary deployment will be sent as JSON via an HTTP POST request. The JSON payload has the following schema:
|
||||
|
||||
```javascript
|
||||
{
|
||||
"name": "string (canary name)",
|
||||
"namespace": "string (canary namespace)",
|
||||
"phase": "string (canary phase)",
|
||||
"metadata": {
|
||||
"eventMessage": "string (canary event message)",
|
||||
"eventType": "string (canary event type)",
|
||||
"timestamp": "string (unix timestamp ms)"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```javascript
|
||||
{
|
||||
"name": "podinfo",
|
||||
"namespace": "default",
|
||||
"phase": "Progressing",
|
||||
"metadata": {
|
||||
"eventMessage": "New revision detected! Scaling up podinfo.default",
|
||||
"eventType": "Normal",
|
||||
"timestamp": "1578607635167"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The event webhook can be overwritten at canary level with:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "send to Slack"
|
||||
type: event
|
||||
url: http://event-recevier.notifications/slack
|
||||
```
|
||||
|
||||
## Metrics
|
||||
|
||||
Flagger exposes Prometheus metrics that can be used to determine the canary analysis status and the destination weight values:
|
||||
|
||||
```bash
|
||||
# Flagger version and mesh provider gauge
|
||||
flagger_info{version="0.10.0", mesh_provider="istio"} 1
|
||||
|
||||
# Canaries total gauge
|
||||
flagger_canary_total{namespace="test"} 1
|
||||
|
||||
# Canary promotion last known status gauge
|
||||
# 0 - running, 1 - successful, 2 - failed
|
||||
flagger_canary_status{name="podinfo" namespace="test"} 1
|
||||
|
||||
# Canary traffic weight gauge
|
||||
flagger_canary_weight{workload="podinfo-primary" namespace="test"} 95
|
||||
flagger_canary_weight{workload="podinfo" namespace="test"} 5
|
||||
|
||||
# Seconds spent performing canary analysis histogram
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="10"} 6
|
||||
flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="+Inf"} 6
|
||||
flagger_canary_duration_seconds_sum{name="podinfo",namespace="test"} 17.3561329
|
||||
flagger_canary_duration_seconds_count{name="podinfo",namespace="test"} 6
|
||||
```
|
||||
|
||||
398
docs/usage/webhooks.md
Normal file
398
docs/usage/webhooks.md
Normal file
@@ -0,0 +1,398 @@
|
||||
# Webhooks
|
||||
|
||||
The canary analysis can be extended with webhooks. Flagger will call each webhook URL and
|
||||
determine from the response status code (HTTP 2xx) if the canary is failing or not.
|
||||
|
||||
There are several types of hooks:
|
||||
* **confirm-rollout** hooks are executed before scaling up the canary deployment and can be used for manual approval.
|
||||
The rollout is paused until the hook returns a successful HTTP status code.
|
||||
* **pre-rollout** hooks are executed before routing traffic to canary.
|
||||
The canary advancement is paused if a pre-rollout hook fails and if the number of failures reach the
|
||||
threshold the canary will be rollback.
|
||||
* **rollout** hooks are executed during the analysis on each iteration before the metric checks.
|
||||
If a rollout hook call fails the canary advancement is paused and eventfully rolled back.
|
||||
* **confirm-promotion** hooks are executed before the promotion step.
|
||||
The canary promotion is paused until the hooks return HTTP 200.
|
||||
While the promotion is paused, Flagger will continue to run the metrics checks and rollout hooks.
|
||||
* **post-rollout** hooks are executed after the canary has been promoted or rolled back.
|
||||
If a post rollout hook fails the error is logged.
|
||||
* **rollback** hooks are executed while a canary deployment is in either Progressing or Waiting status.
|
||||
This provides the ability to rollback during analysis or while waiting for a confirmation. If a rollback hook
|
||||
returns a successful HTTP status code, Flagger will stop the analysis and mark the canary release as failed.
|
||||
* **event** hooks are executed every time Flagger emits a Kubernetes event. When configured,
|
||||
every action that Flagger takes during a canary deployment will be sent as JSON via an HTTP POST request.
|
||||
|
||||
Spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "start gate"
|
||||
type: confirm-rollout
|
||||
url: http://flagger-loadtester.test/gate/approve
|
||||
- name: "helm test"
|
||||
type: pre-rollout
|
||||
url: http://flagger-helmtester.flagger/
|
||||
timeout: 3m
|
||||
metadata:
|
||||
type: "helmv3"
|
||||
cmd: "test podinfo -n test"
|
||||
- name: "load test"
|
||||
type: rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 15s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 5 -c 2 http://podinfo-canary.test:9898/"
|
||||
- name: "promotion gate"
|
||||
type: confirm-promotion
|
||||
url: http://flagger-loadtester.test/gate/approve
|
||||
- name: "notify"
|
||||
type: post-rollout
|
||||
url: http://telegram.bot:8080/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
some: "message"
|
||||
- name: "rollback gate"
|
||||
type: rollback
|
||||
url: http://flagger-loadtester.test/rollback/check
|
||||
- name: "send to Slack"
|
||||
type: event
|
||||
url: http://event-recevier.notifications/slack
|
||||
```
|
||||
|
||||
> **Note** that the sum of all rollout webhooks timeouts should be lower than the analysis interval.
|
||||
|
||||
Webhook payload (HTTP POST):
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "podinfo",
|
||||
"namespace": "test",
|
||||
"phase": "Progressing",
|
||||
"metadata": {
|
||||
"test": "all",
|
||||
"token": "16688eb5e9f289f1991c"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Response status codes:
|
||||
|
||||
* 200-202 - advance canary by increasing the traffic weight
|
||||
* timeout or non-2xx - halt advancement and increment failed checks
|
||||
|
||||
On a non-2xx response Flagger will include the response body (if any) in the failed checks log and Kubernetes events.
|
||||
|
||||
Event payload (HTTP POST):
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "string (canary name)",
|
||||
"namespace": "string (canary namespace)",
|
||||
"phase": "string (canary phase)",
|
||||
"metadata": {
|
||||
"eventMessage": "string (canary event message)",
|
||||
"eventType": "string (canary event type)",
|
||||
"timestamp": "string (unix timestamp ms)"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The event receiver can create alerts based on the received phase
|
||||
(possible values: ` Initialized`, `Waiting`, `Progressing`, `Promoting`, `Finalising`, `Succeeded` or `Failed`).
|
||||
|
||||
## Load Testing
|
||||
|
||||
For workloads that are not receiving constant traffic Flagger can be configured with a webhook,
|
||||
that when called, will start a load test for the target workload.
|
||||
If the target workload doesn't receive any traffic during the canary analysis,
|
||||
Flagger metric checks will fail with "no values found for metric request-success-rate".
|
||||
|
||||
Flagger comes with a load testing service based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
that generates traffic during analysis when configured as a webhook.
|
||||
|
||||
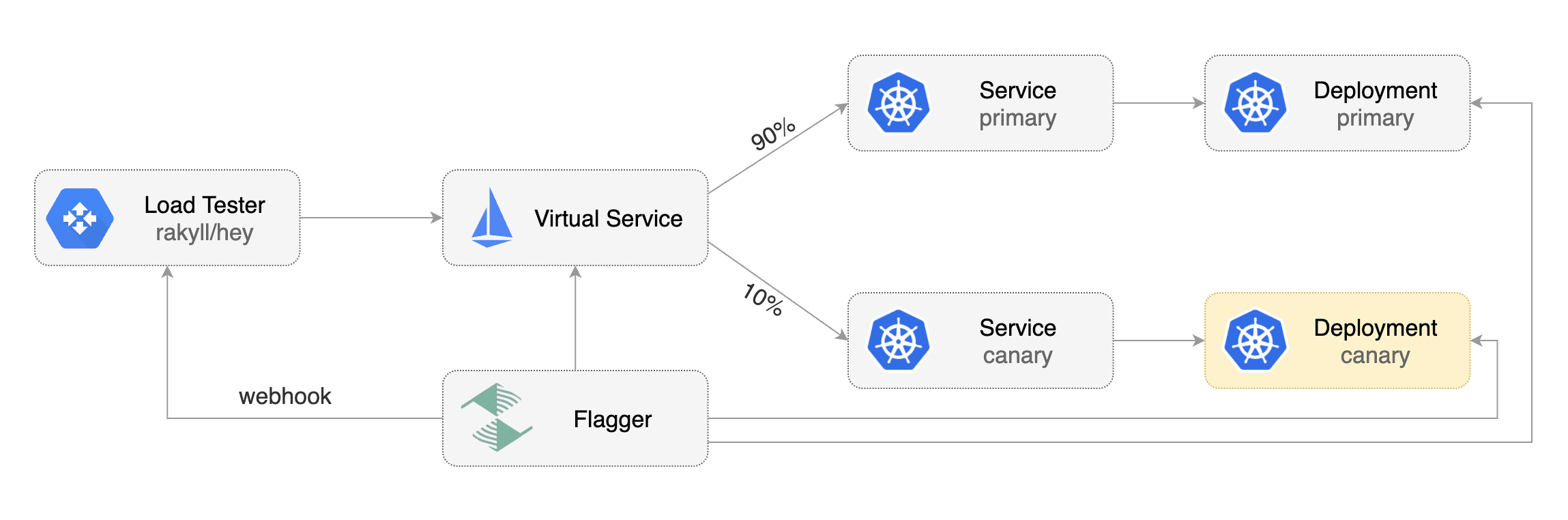
|
||||
|
||||
First you need to deploy the load test runner in a namespace with sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Or by using Helm:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test \
|
||||
--set cmd.timeout=1h
|
||||
```
|
||||
|
||||
When deployed the load tester API will be available at `http://flagger-loadtester.test/`.
|
||||
|
||||
Now you can add webhooks to the canary analysis spec:
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
- name: load-test-post
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 -m POST -d '{test: 2}' http://podinfo-canary.test:9898/echo"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the webhooks and the load tester will run the `hey` commands
|
||||
in the background, if they are not already running. This will ensure that during the
|
||||
analysis, the `podinfo-canary.test` service will receive a steady stream of GET and POST requests.
|
||||
|
||||
If your workload is exposed outside the mesh you can point `hey` to the
|
||||
public URL and use HTTP2.
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-get
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "hey -z 1m -q 10 -c 2 -h2 https://podinfo.example.com/"
|
||||
```
|
||||
|
||||
For gRPC services you can use [bojand/ghz](https://github.com/bojand/ghz) which is a similar tool to Hey but for gPRC:
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: grpc-load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "ghz -z 1m -q 10 -c 2 --insecure podinfo.test:9898"
|
||||
```
|
||||
|
||||
`ghz` uses reflection to identify which gRPC method to call. If you do not wish to enable reflection for your gRPC service you can implement a standardized health check from the [grpc-proto](https://github.com/grpc/grpc-proto) library. To use this [health check schema](https://github.com/grpc/grpc-proto/blob/master/grpc/health/v1/health.proto) without reflection you can pass a parameter to `ghz` like this
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: grpc-load-test-no-reflection
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
type: cmd
|
||||
cmd: "ghz --insecure --proto=/tmp/ghz/health.proto --call=grpc.health.v1.Health/Check podinfo.test:9898"
|
||||
```
|
||||
|
||||
The load tester can run arbitrary commands as long as the binary is present in the container image.
|
||||
For example if you you want to replace `hey` with another CLI, you can create your own Docker image:
|
||||
|
||||
```dockerfile
|
||||
FROM weaveworks/flagger-loadtester:<VER>
|
||||
|
||||
RUN curl -Lo /usr/local/bin/my-cli https://github.com/user/repo/releases/download/ver/my-cli \
|
||||
&& chmod +x /usr/local/bin/my-cli
|
||||
```
|
||||
|
||||
## Load Testing Delegation
|
||||
|
||||
The load tester can also forward testing tasks to external tools, by now [nGrinder](https://github.com/naver/ngrinder)
|
||||
is supported.
|
||||
|
||||
To use this feature, add a load test task of type 'ngrinder' to the canary analysis spec:
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
- name: load-test-post
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
# type of this load test task, cmd or ngrinder
|
||||
type: ngrinder
|
||||
# base url of your nGrinder controller server
|
||||
server: http://ngrinder-server:port
|
||||
# id of the test to clone from, the test must have been defined.
|
||||
clone: 100
|
||||
# user name and base64 encoded password to authenticate against the nGrinder server
|
||||
username: admin
|
||||
passwd: YWRtaW4=
|
||||
# the interval between between nGrinder test status polling, default to 1s
|
||||
pollInterval: 5s
|
||||
```
|
||||
When the canary analysis starts, the load tester will initiate a [clone_and_start request](https://github.com/naver/ngrinder/wiki/REST-API-PerfTest)
|
||||
to the nGrinder server and start a new performance test. the load tester will periodically poll the nGrinder server
|
||||
for the status of the test, and prevent duplicate requests from being sent in subsequent analysis loops.
|
||||
|
||||
## Integration Testing
|
||||
|
||||
Flagger comes with a testing service that can run Helm tests or Bats tests when configured as a webhook.
|
||||
|
||||
Deploy the Helm test runner in the `kube-system` namespace using the `tiller` service account:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger-helmtester flagger/loadtester \
|
||||
--namespace=kube-system \
|
||||
--set serviceAccountName=tiller
|
||||
```
|
||||
|
||||
When deployed the Helm tester API will be available at `http://flagger-helmtester.kube-system/`.
|
||||
|
||||
Now you can add pre-rollout webhooks to the canary analysis spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "smoke test"
|
||||
type: pre-rollout
|
||||
url: http://flagger-helmtester.kube-system/
|
||||
timeout: 3m
|
||||
metadata:
|
||||
type: "helm"
|
||||
cmd: "test {{ .Release.Name }} --cleanup"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
|
||||
If you are using Helm v3, you'll have to create a dedicated service account and add the release namespace to the test command:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "smoke test"
|
||||
type: pre-rollout
|
||||
url: http://flagger-helmtester.kube-system/
|
||||
timeout: 3m
|
||||
metadata:
|
||||
type: "helmv3"
|
||||
cmd: "test {{ .Release.Name }} --timeout 3m -n {{ .Release.Namespace }}"
|
||||
```
|
||||
|
||||
As an alternative to Helm you can use the [Bash Automated Testing System](https://github.com/bats-core/bats-core) to run your tests.
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "acceptance tests"
|
||||
type: pre-rollout
|
||||
url: http://flagger-batstester.default/
|
||||
timeout: 5m
|
||||
metadata:
|
||||
type: "bash"
|
||||
cmd: "bats /tests/acceptance.bats"
|
||||
```
|
||||
|
||||
Note that you should create a ConfigMap with your Bats tests and mount it inside the tester container.
|
||||
|
||||
## Manual Gating
|
||||
|
||||
For manual approval of a canary deployment you can use the `confirm-rollout` and `confirm-promotion` webhooks.
|
||||
The confirmation rollout hooks are executed before the pre-rollout hooks.
|
||||
Flagger will halt the canary traffic shifting and analysis until the confirm webhook returns HTTP status 200.
|
||||
|
||||
For manual rollback of a canary deployment you can use the `rollback` webhook. The rollback hook will be called
|
||||
during the analysis and confirmation states. If a rollback webhook returns a successful HTTP status code, Flagger
|
||||
will shift all traffic back to the primary instance and fail the canary.
|
||||
|
||||
Manual gating with Flagger's tester:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "gate"
|
||||
type: confirm-rollout
|
||||
url: http://flagger-loadtester.test/gate/halt
|
||||
```
|
||||
|
||||
The `/gate/halt` returns HTTP 403 thus blocking the rollout.
|
||||
|
||||
If you have notifications enabled, Flagger will post a message to Slack or MS Teams if a canary rollout is waiting for approval.
|
||||
|
||||
Change the URL to `/gate/approve` to start the canary analysis:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "gate"
|
||||
type: confirm-rollout
|
||||
url: http://flagger-loadtester.test/gate/approve
|
||||
```
|
||||
|
||||
Manual gating can be driven with Flagger's tester API. Set the confirmation URL to `/gate/check`:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "ask for confirmation"
|
||||
type: confirm-rollout
|
||||
url: http://flagger-loadtester.test/gate/check
|
||||
```
|
||||
|
||||
By default the gate is closed, you can start or resume the canary rollout with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxxx-xxxx sh
|
||||
|
||||
curl -d '{"name": "podinfo","namespace":"test"}' http://localhost:8080/gate/open
|
||||
```
|
||||
|
||||
You can pause the rollout at any time with:
|
||||
|
||||
```bash
|
||||
curl -d '{"name": "podinfo","namespace":"test"}' http://localhost:8080/gate/close
|
||||
```
|
||||
|
||||
If a canary analysis is paused the status will change to waiting:
|
||||
|
||||
```bash
|
||||
kubectl get canary/podinfo
|
||||
|
||||
NAME STATUS WEIGHT
|
||||
podinfo Waiting 0
|
||||
```
|
||||
|
||||
The `confirm-promotion` hook type can be used to manually approve the canary promotion.
|
||||
While the promotion is paused, Flagger will continue to run the metrics checks and load tests.
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "promotion gate"
|
||||
type: confirm-promotion
|
||||
url: http://flagger-loadtester.test/gate/halt
|
||||
```
|
||||
|
||||
The `rollback` hook type can be used to manually rollback the canary promotion. As with gating, rollbacks can be driven
|
||||
with Flagger's tester API by setting the rollback URL to `/rollback/check`
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
webhooks:
|
||||
- name: "rollback"
|
||||
type: rollback
|
||||
url: http://flagger-loadtester.test/rollback/check
|
||||
```
|
||||
|
||||
By default rollback is closed, you can rollback a canary rollout with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxxx-xxxx sh
|
||||
|
||||
curl -d '{"name": "podinfo","namespace":"test"}' http://localhost:8080/rollback/open
|
||||
```
|
||||
|
||||
You can close the rollback with:
|
||||
|
||||
```bash
|
||||
curl -d '{"name": "podinfo","namespace":"test"}' http://localhost:8080/rollback/close
|
||||
```
|
||||
|
||||
If you have notifications enabled, Flagger will post a message to Slack or MS Teams if a canary has been rolled back.
|
||||
Reference in New Issue
Block a user