mirror of
https://github.com/fluxcd/flagger.git
synced 2026-04-15 06:57:34 +00:00
Merge pull request #763 from fluxcd/ghcr
Publish multi-arch image to GitHub Container Registry
This commit is contained in:
@@ -1,15 +1,10 @@
|
||||
# App Mesh Canary Deployments
|
||||
|
||||
This guide shows you how to use App Mesh and Flagger to automate canary deployments.
|
||||
You'll need an EKS cluster configured with App Mesh,
|
||||
you can find the installion guide [here](https://docs.flagger.app/install/flagger-install-on-eks-appmesh).
|
||||
This guide shows you how to use App Mesh and Flagger to automate canary deployments. You'll need an EKS cluster configured with App Mesh, you can find the installion guide [here](https://docs.flagger.app/install/flagger-install-on-eks-appmesh).
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\),
|
||||
then creates a series of objects \(Kubernetes deployments, ClusterIP services, App Mesh virtual nodes and services\).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
The only App Mesh object you need to create by yourself is the mesh resource.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services, App Mesh virtual nodes and services\). These objects expose the application on the mesh and drive the canary analysis and promotion. The only App Mesh object you need to create by yourself is the mesh resource.
|
||||
|
||||
Create a mesh called `global`:
|
||||
|
||||
@@ -42,7 +37,7 @@ EOF
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
@@ -167,13 +162,9 @@ virtualservice.appmesh.k8s.aws/podinfo
|
||||
virtualservice.appmesh.k8s.aws/podinfo-canary
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to
|
||||
`podinfo.test` will be routed to the primary pods.
|
||||
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
App Mesh blocks all egress traffic by default.
|
||||
If your application needs to call another service, you have to
|
||||
create an App Mesh virtual service for it and add the virtual service name to the backend list.
|
||||
App Mesh blocks all egress traffic by default. If your application needs to call another service, you have to create an App Mesh virtual service for it and add the virtual service name to the backend list.
|
||||
|
||||
```yaml
|
||||
service:
|
||||
@@ -183,7 +174,7 @@ create an App Mesh virtual service for it and add the virtual service name to th
|
||||
- arn:aws:appmesh:eu-west-1:12345678910:mesh/my-mesh/virtualService/backend2
|
||||
```
|
||||
|
||||
## Setup App Mesh Gateway (optional)
|
||||
## Setup App Mesh Gateway \(optional\)
|
||||
|
||||
In order to expose the podinfo app outside the mesh you can use the App Mesh Gateway.
|
||||
|
||||
@@ -277,11 +268,9 @@ When the canary analysis starts, Flagger will call the pre-rollout webhooks befo
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
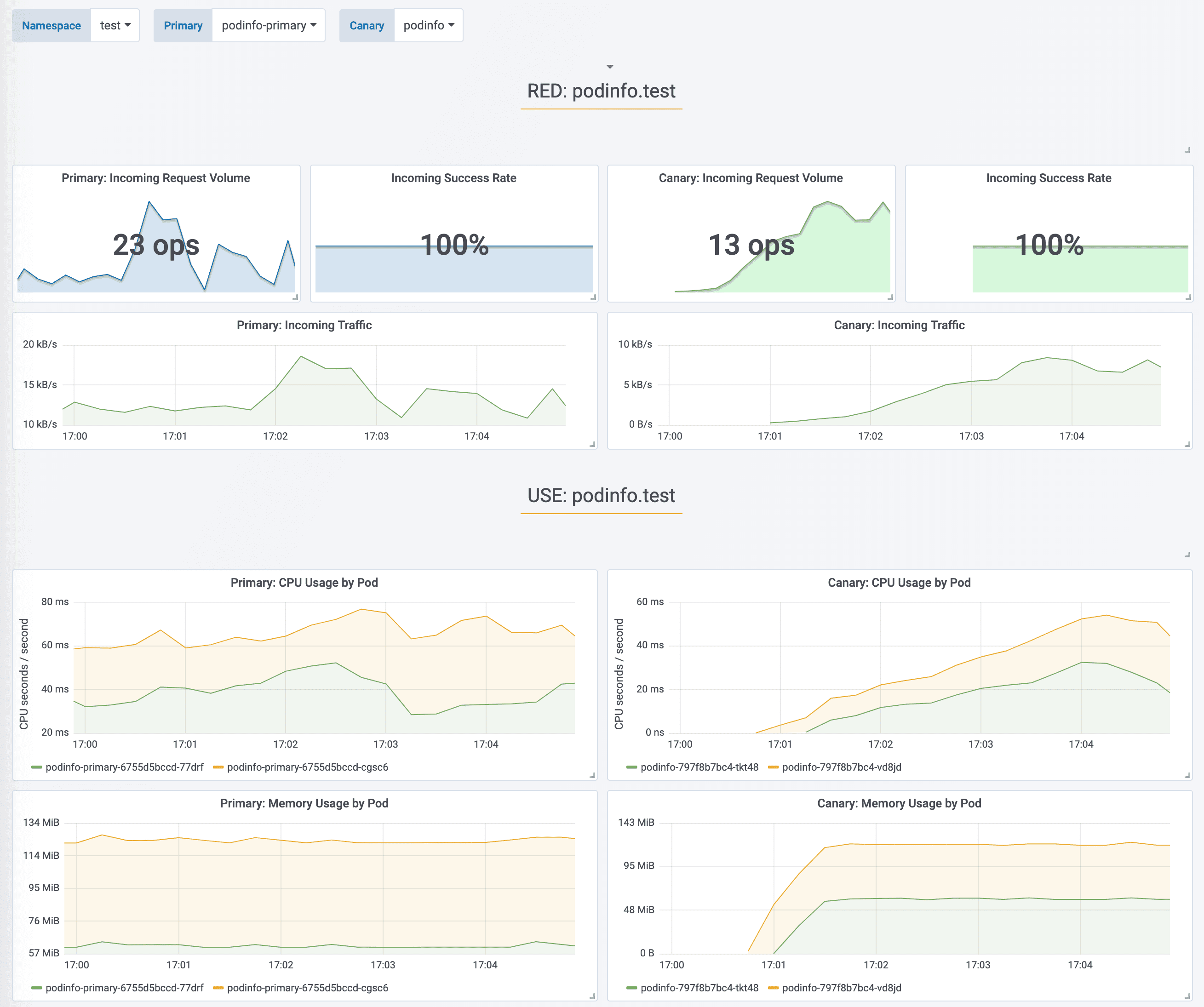
During the analysis the canary’s progress can be monitored with Grafana.
|
||||
The App Mesh dashboard URL is
|
||||
[http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo](http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo).
|
||||
During the analysis the canary’s progress can be monitored with Grafana. The App Mesh dashboard URL is [http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo](http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo).
|
||||
|
||||
|
||||

|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
@@ -296,7 +285,7 @@ prod backend Failed 0
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
@@ -327,8 +316,7 @@ Generate latency:
|
||||
watch -n 1 curl http://podinfo-canary.test:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n appmesh-system logs deploy/flagger -f | jq .msg
|
||||
@@ -347,18 +335,15 @@ Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
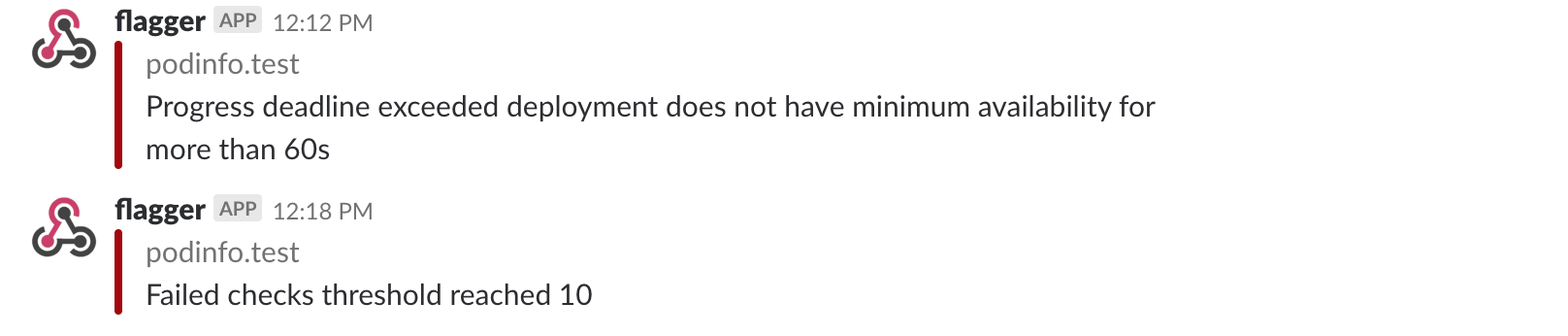
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded, or if the analysis reached the maximum number of failed checks:
|
||||
|
||||
|
||||

|
||||
|
||||
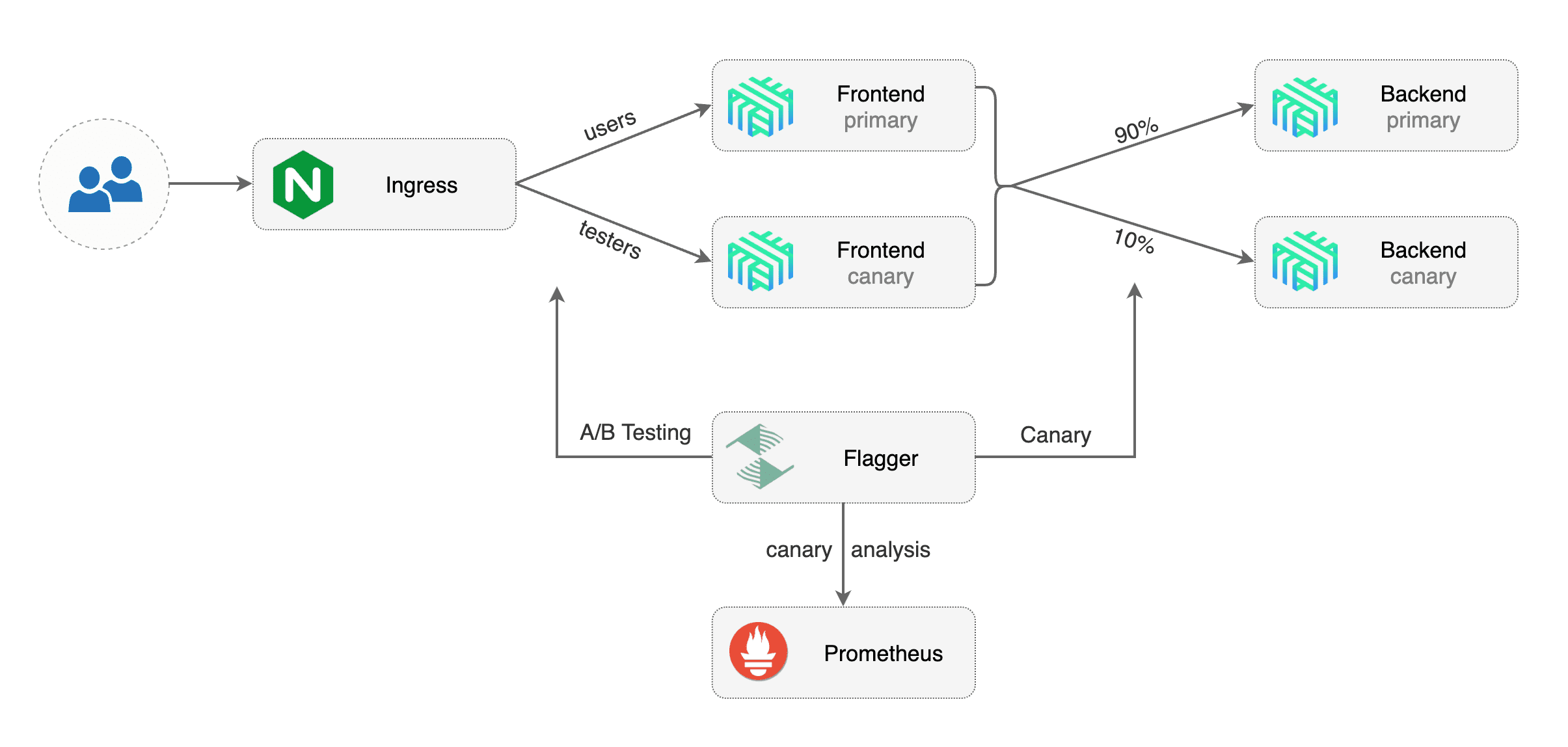
## A/B Testing
|
||||
|
||||
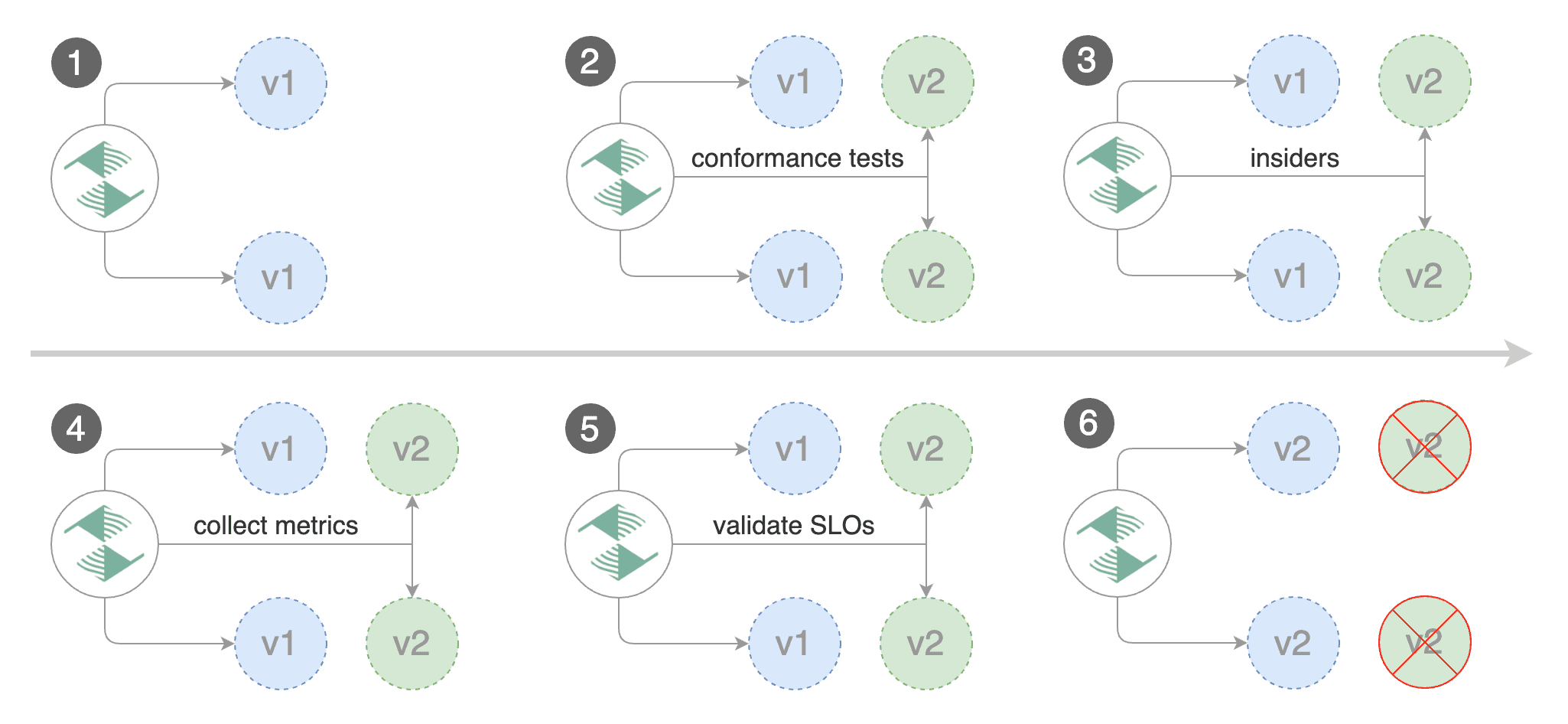
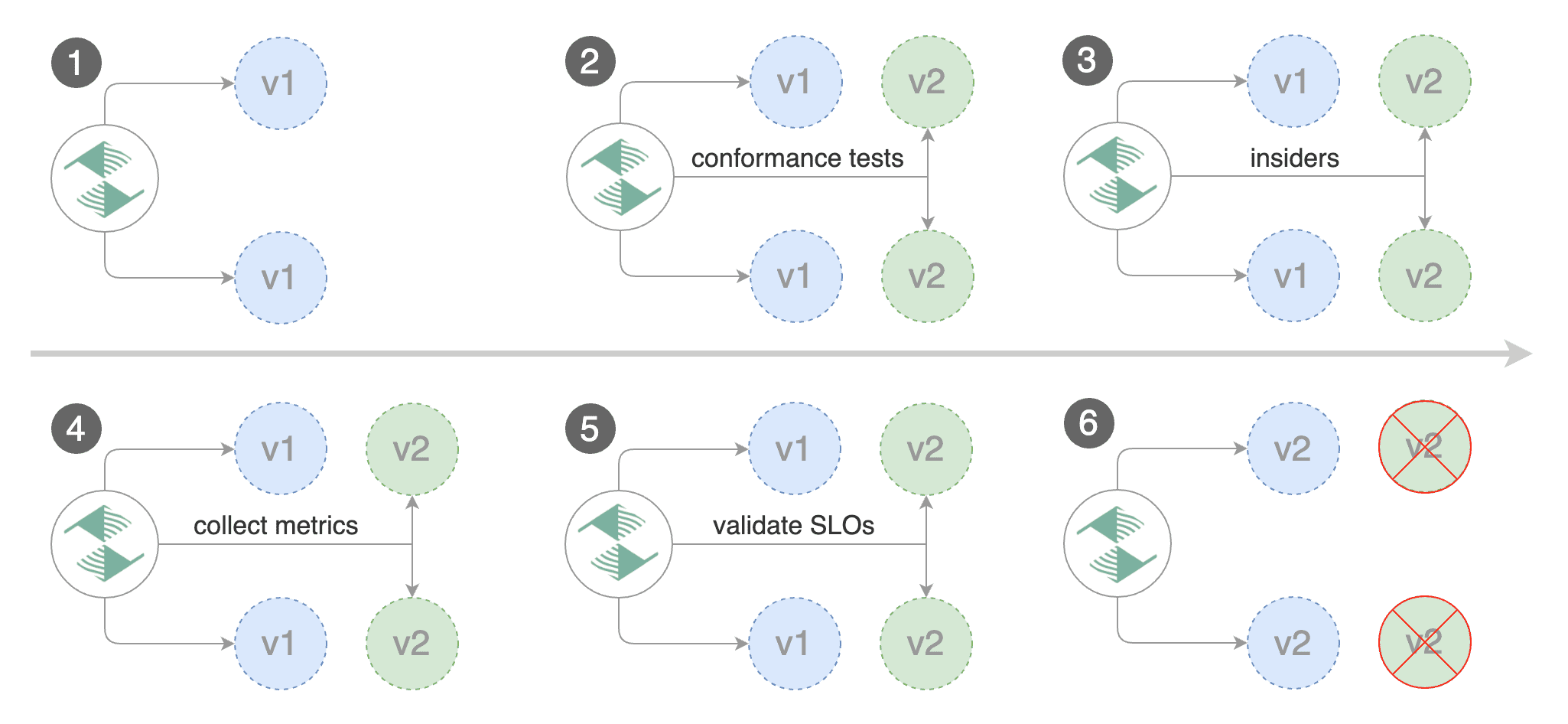
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
|
||||
|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
@@ -424,3 +409,4 @@ Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
||||
@@ -30,7 +30,7 @@ You can find the chart source [here](https://github.com/stefanprodan/flagger/tre
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
```bash
|
||||
export REPO=https://raw.githubusercontent.com/fluxcd/flagger/main
|
||||
export REPO=https://raw.githubusercontent.com/weaveworks/flagger/master
|
||||
|
||||
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
||||
```
|
||||
@@ -77,7 +77,7 @@ When the `frontend-primary` deployment comes online, Flagger will route all traf
|
||||
|
||||
Open your browser and navigate to the frontend URL:
|
||||
|
||||
|
||||

|
||||
|
||||
Now let's install the `backend` release without exposing it outside the mesh:
|
||||
|
||||
@@ -101,7 +101,7 @@ frontend Initialized 0 2019-02-12T17:50:50Z
|
||||
|
||||
Click on the ping button in the `frontend` UI to trigger a HTTP POST request that will reach the `backend` app:
|
||||
|
||||
|
||||

|
||||
|
||||
We'll use the `/echo` endpoint \(same as the one the ping button calls\) to generate load on both apps during a canary deployment.
|
||||
|
||||
@@ -159,7 +159,7 @@ Promotion completed! Scaling down frontend.test
|
||||
|
||||
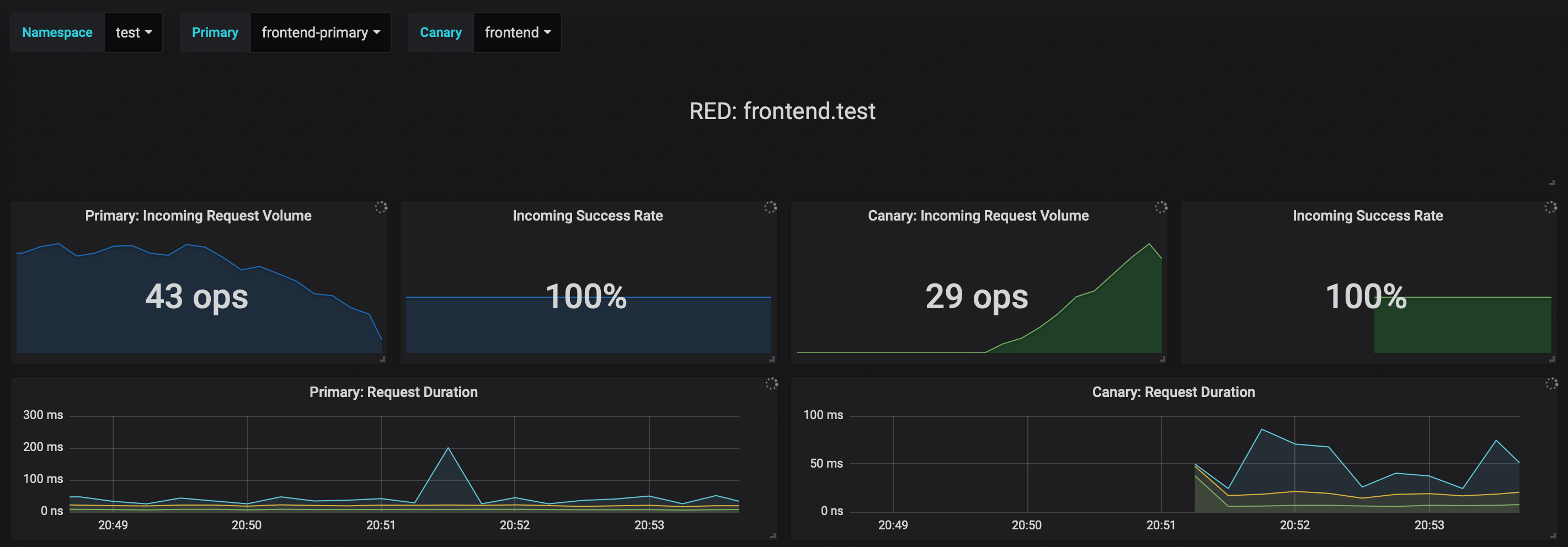
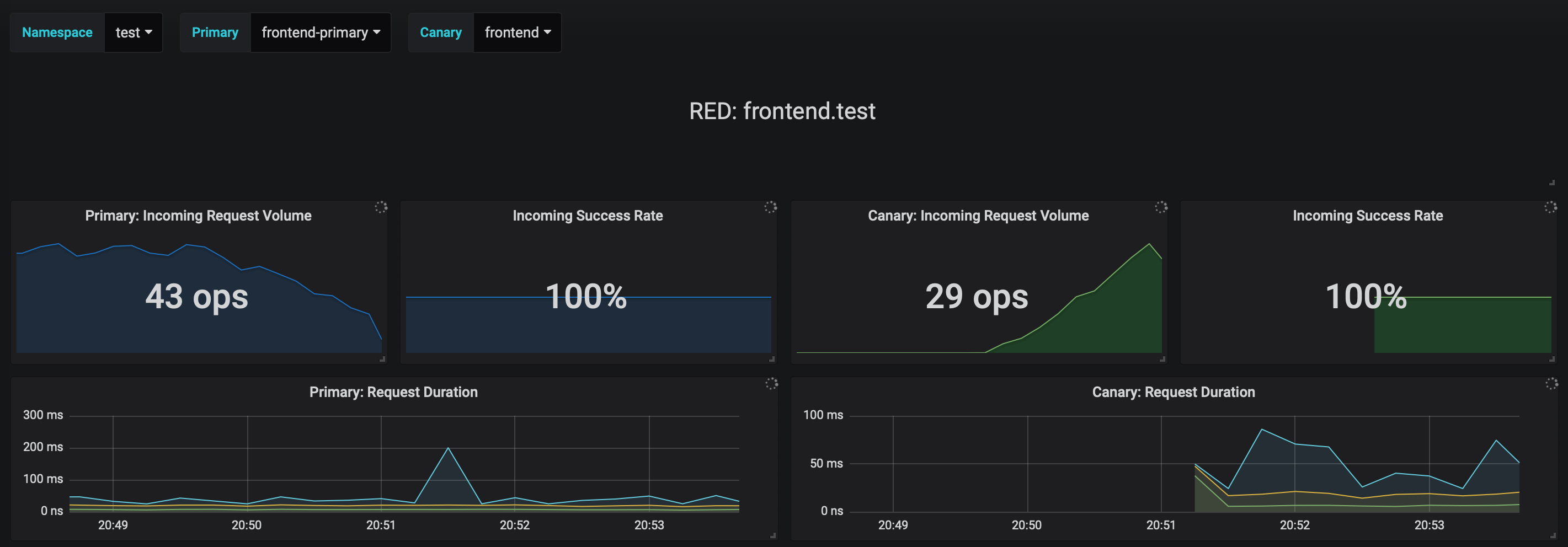
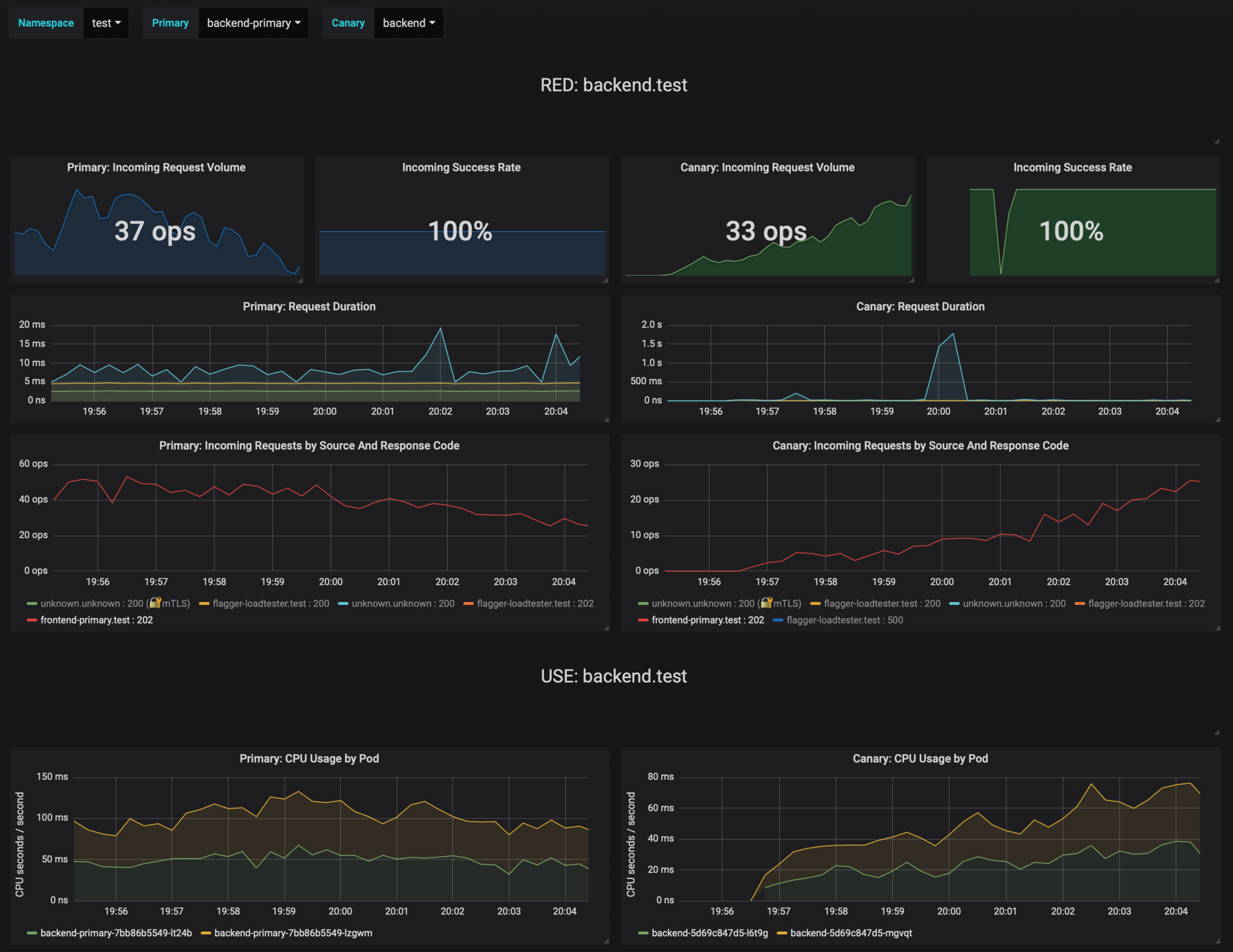
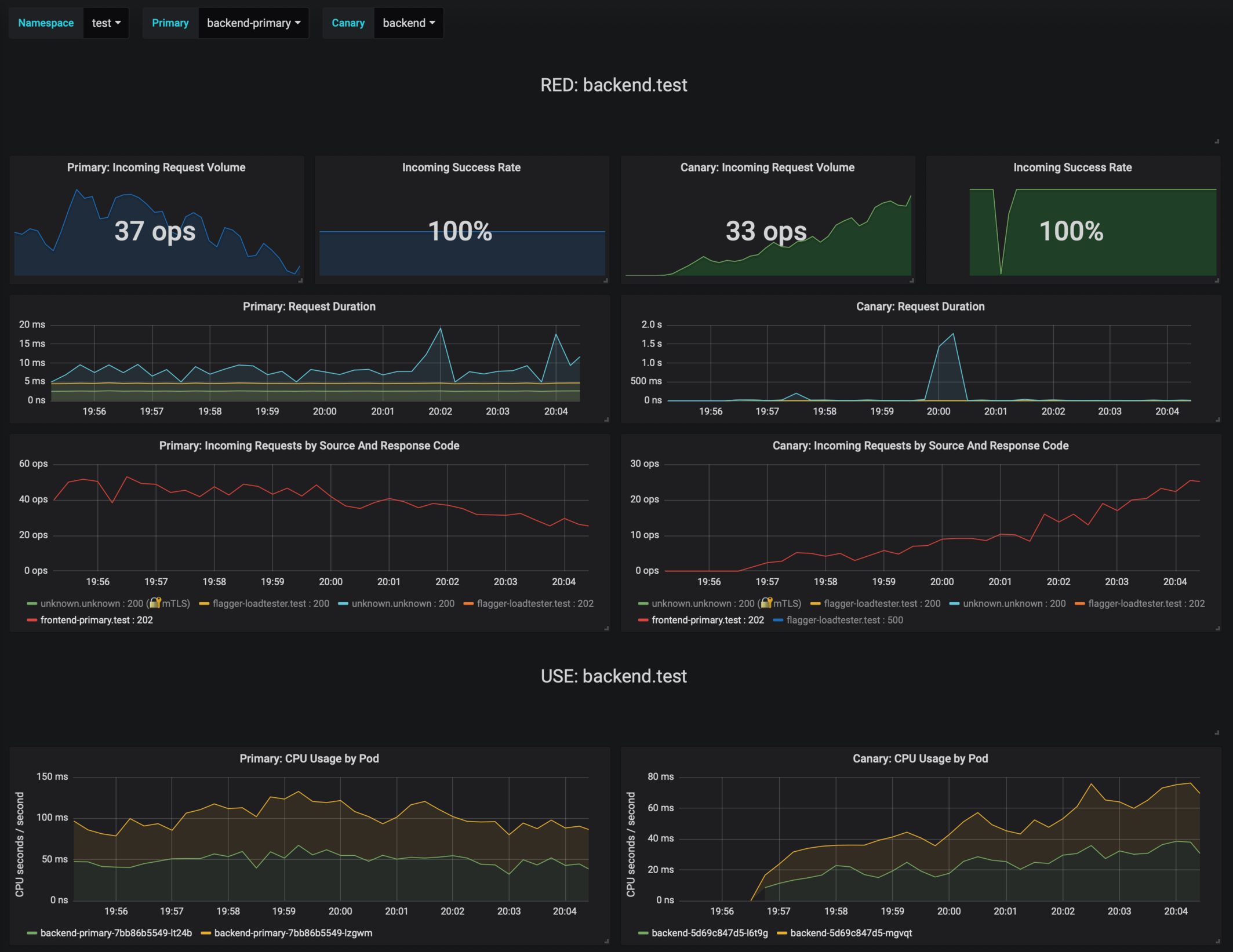
You can monitor the canary deployment with Grafana. Open the Flagger dashboard, select `test` from the namespace dropdown, `frontend-primary` from the primary dropdown and `frontend` from the canary dropdown.
|
||||
|
||||
|
||||
|
||||
|
||||
Now trigger a canary deployment for the `backend` app, but this time you'll change a value in the configmap:
|
||||
|
||||
@@ -217,7 +217,7 @@ Copying backend.test template spec to backend-primary.test
|
||||
Promotion completed! Scaling down backend.test
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
If the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
@@ -235,7 +235,7 @@ If you've enabled the Slack notifications, you'll receive an alert with the reas
|
||||
|
||||
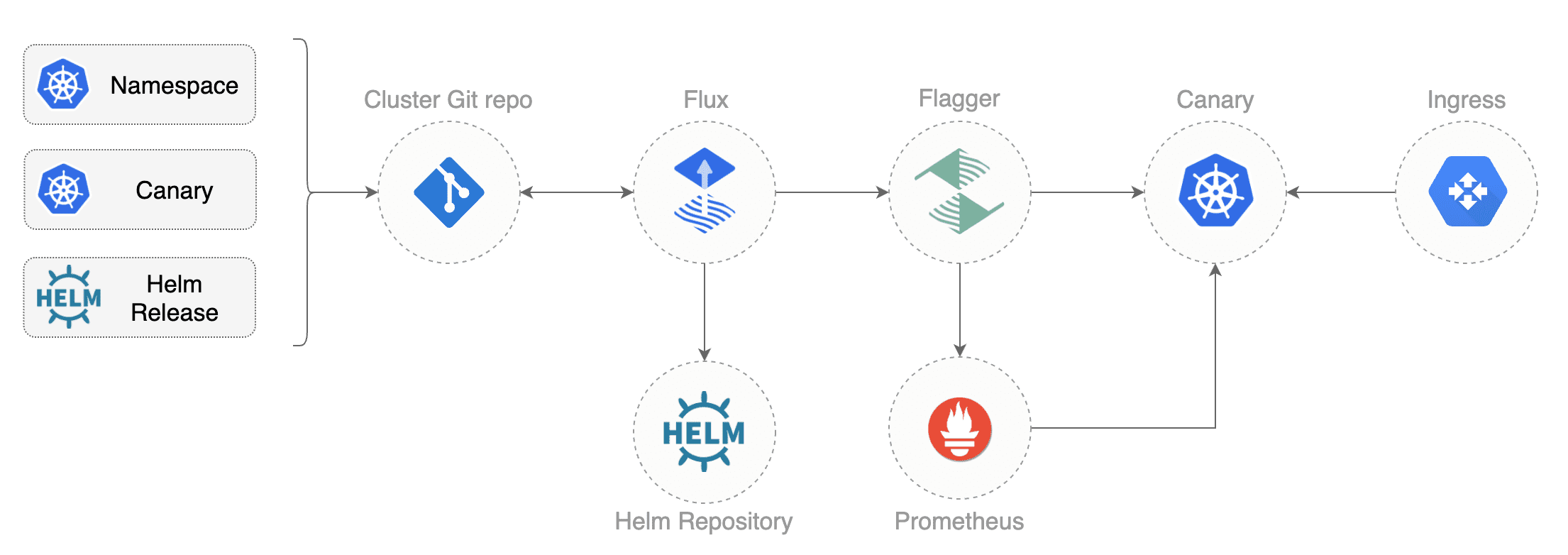
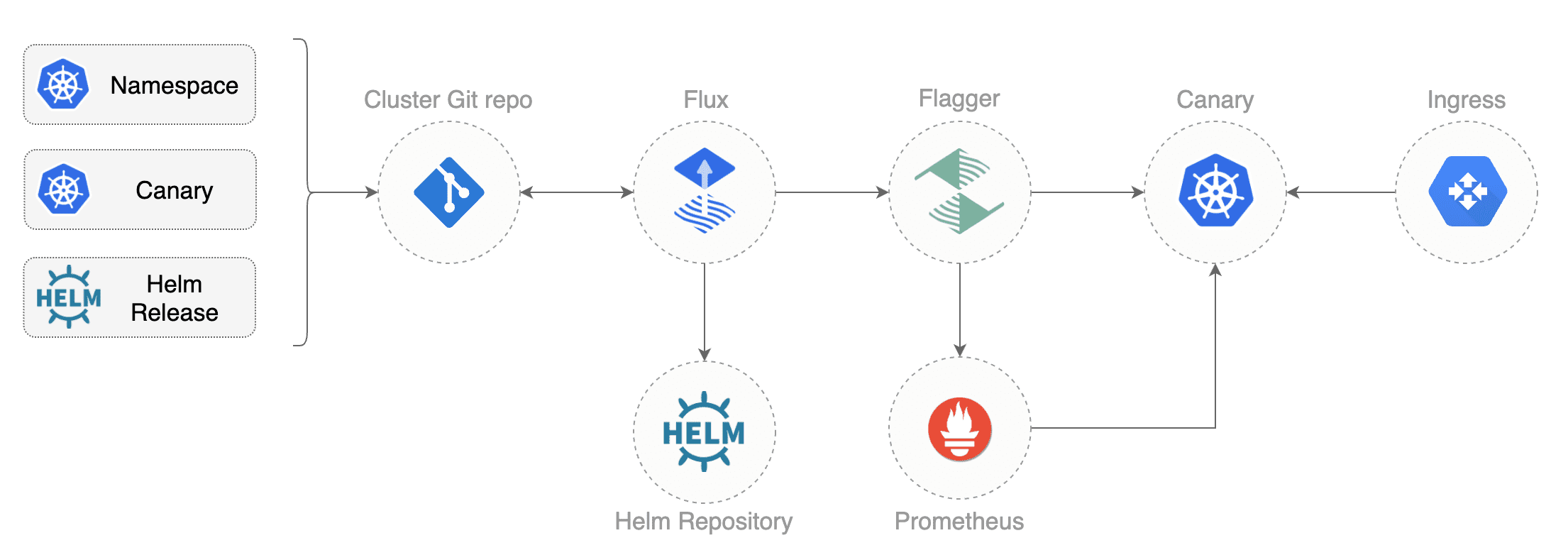
Instead of using Helm CLI from a CI tool to perform the install and upgrade, you could use a Git based approach. GitOps is a way to do Continuous Delivery, it works by using Git as a source of truth for declarative infrastructure and workloads. In the [GitOps model](https://www.weave.works/technologies/gitops/), any change to production must be committed in source control prior to being applied on the cluster. This way rollback and audit logs are provided by Git.
|
||||
|
||||
|
||||
|
||||
|
||||
In order to apply the GitOps pipeline model to Flagger canary deployments you'll need a Git repository with your workloads definitions in YAML format, a container registry where your CI system pushes immutable images and an operator that synchronizes the Git repo with the cluster state.
|
||||
|
||||
@@ -286,15 +286,11 @@ spec:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
In the `chart` section I've defined the release source by specifying the Helm repository (hosted on GitHub Pages),
|
||||
chart name and version. In the `values` section I've overwritten the defaults set in values.yaml.
|
||||
In the `chart` section I've defined the release source by specifying the Helm repository \(hosted on GitHub Pages\), chart name and version. In the `values` section I've overwritten the defaults set in values.yaml.
|
||||
|
||||
With the `fluxcd.io` annotations I instruct Flux to automate this release.
|
||||
When an image tag in the sem ver range of `3.1.0 - 3.1.99` is pushed to Docker Hub,
|
||||
Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
||||
With the `fluxcd.io` annotations I instruct Flux to automate this release. When an image tag in the sem ver range of `3.1.0 - 3.1.99` is pushed to Docker Hub, Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
||||
|
||||
Install [Flux](https://github.com/fluxcd/flux) and its
|
||||
[Helm Operator](https://github.com/fluxcd/helm-operator) by specifying your Git repo URL:
|
||||
Install [Flux](https://github.com/fluxcd/flux) and its [Helm Operator](https://github.com/fluxcd/helm-operator) by specifying your Git repo URL:
|
||||
|
||||
```bash
|
||||
helm repo add fluxcd https://charts.fluxcd.io
|
||||
@@ -315,14 +311,11 @@ At startup Flux generates a SSH key and logs the public key. Find the SSH public
|
||||
kubectl -n fluxcd logs deployment/flux | grep identity.pub | cut -d '"' -f2
|
||||
```
|
||||
|
||||
In order to sync your cluster state with Git you need to copy the public key
|
||||
and create a deploy key with write access on your GitHub repository.
|
||||
In order to sync your cluster state with Git you need to copy the public key and create a deploy key with write access on your GitHub repository.
|
||||
|
||||
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_, check _Allow write access_,
|
||||
paste the Flux public key and click _Add key_.
|
||||
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_, check _Allow write access_, paste the Flux public key and click _Add key_.
|
||||
|
||||
After a couple of seconds Flux will apply the Kubernetes resources from Git and
|
||||
Flagger will launch the `frontend` and `backend` apps.
|
||||
After a couple of seconds Flux will apply the Kubernetes resources from Git and Flagger will launch the `frontend` and `backend` apps.
|
||||
|
||||
A CI/CD pipeline for the `frontend` release could look like this:
|
||||
|
||||
@@ -343,14 +336,12 @@ If the canary fails, fix the bug, do another patch release eg `3.1.2` and the wh
|
||||
A canary deployment can fail due to any of the following reasons:
|
||||
|
||||
* the container image can't be downloaded
|
||||
* the deployment replica set is stuck for more then ten minutes (eg. due to a container crash loop)
|
||||
* the webooks (acceptance tests, helm tests, load tests, etc) are returning a non 2xx response
|
||||
* the HTTP success rate (non 5xx responses) metric drops under the threshold
|
||||
* the deployment replica set is stuck for more then ten minutes \(eg. due to a container crash loop\)
|
||||
* the webooks \(acceptance tests, helm tests, load tests, etc\) are returning a non 2xx response
|
||||
* the HTTP success rate \(non 5xx responses\) metric drops under the threshold
|
||||
* the HTTP average duration metric goes over the threshold
|
||||
* the Istio telemetry service is unable to collect traffic metrics
|
||||
* the metrics server (Prometheus) can't be reached
|
||||
* the metrics server \(Prometheus\) can't be reached
|
||||
|
||||
If you want to find out more about managing Helm releases with Flux here are two in-depth guides:
|
||||
[gitops-helm](https://github.com/stefanprodan/gitops-helm)
|
||||
and [gitops-istio](https://github.com/stefanprodan/gitops-istio).
|
||||
If you want to find out more about managing Helm releases with Flux here are two in-depth guides: [gitops-helm](https://github.com/stefanprodan/gitops-helm) and [gitops-istio](https://github.com/stefanprodan/gitops-istio).
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
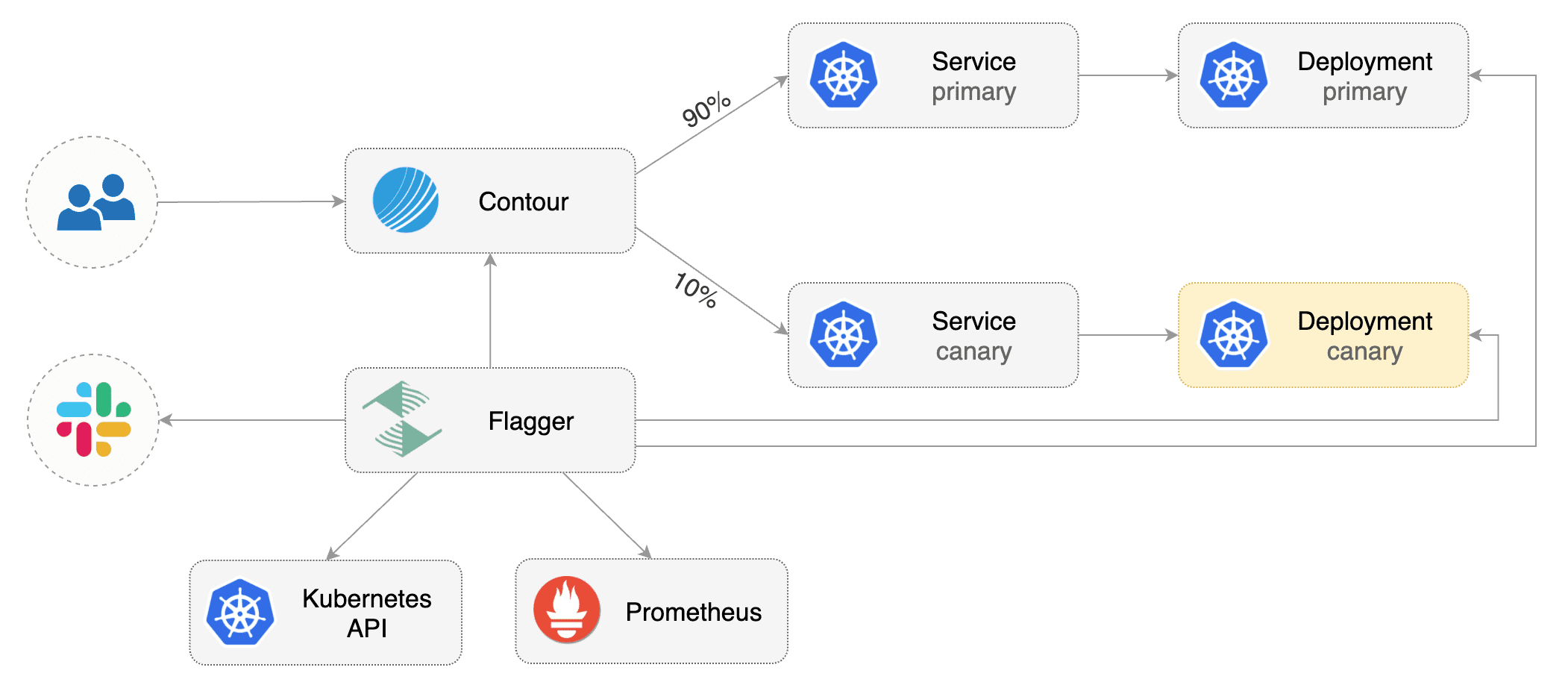
This guide shows you how to use [Contour](https://projectcontour.io/) ingress controller and Flagger to automate canary releases and A/B testing.
|
||||
|
||||
|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -16,10 +16,10 @@ kubectl apply -f https://projectcontour.io/quickstart/contour.yaml
|
||||
|
||||
The above command will deploy Contour and an Envoy daemonset in the `projectcontour` namespace.
|
||||
|
||||
Install Flagger using Kustomize (kubectl 1.14) in the `projectcontour` namespace:
|
||||
Install Flagger using Kustomize \(kubectl 1.14\) in the `projectcontour` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/contour?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/contour
|
||||
```
|
||||
|
||||
The above command will deploy Flagger and Prometheus configured to scrape the Contour's Envoy instances.
|
||||
@@ -36,14 +36,11 @@ helm upgrade -i flagger flagger/flagger \
|
||||
--set prometheus.install=true
|
||||
```
|
||||
|
||||
You can also enable Slack, Discord, Rocket or MS Teams notifications,
|
||||
see the alerting [docs](../usage/alerting.md).
|
||||
You can also enable Slack, Discord, Rocket or MS Teams notifications, see the alerting [docs](../usage/alerting.md).
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Contour HTTPProxy).
|
||||
These objects expose the application in the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and Contour HTTPProxy\). These objects expose the application in the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -54,16 +51,16 @@ kubectl create ns test
|
||||
Install the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -160,9 +157,7 @@ service/podinfo-primary
|
||||
httpproxy.projectcontour.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods.
|
||||
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Expose the app outside the cluster
|
||||
|
||||
@@ -174,11 +169,9 @@ export ADDRESS="$(kubectl -n projectcontour get svc/envoy -ojson \
|
||||
echo $ADDRESS
|
||||
```
|
||||
|
||||
Configure your DNS server with a CNAME record \(AWS\) or A record (GKE/AKS/DOKS)
|
||||
and point a domain e.g. `app.example.com` to the LB address.
|
||||
Configure your DNS server with a CNAME record \(AWS\) or A record \(GKE/AKS/DOKS\) and point a domain e.g. `app.example.com` to the LB address.
|
||||
|
||||
Create a HTTPProxy definition and include the podinfo proxy generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
Create a HTTPProxy definition and include the podinfo proxy generated by Flagger \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: projectcontour.io/v1
|
||||
@@ -214,21 +207,17 @@ podinfo-ingress app.example.com valid
|
||||
|
||||
Now you can access podinfo UI using your domain address.
|
||||
|
||||
Note that you should be using HTTPS when exposing production workloads on internet.
|
||||
You can obtain free TLS certs from Let's Encrypt, read this [guide](https://github.com/stefanprodan/eks-contour-ingress)
|
||||
on how to configure cert-manager to secure Contour with TLS certificates.
|
||||
Note that you should be using HTTPS when exposing production workloads on internet. You can obtain free TLS certs from Let's Encrypt, read this [guide](https://github.com/stefanprodan/eks-contour-ingress) on how to configure cert-manager to secure Contour with TLS certificates.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
|
||||

|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
@@ -282,7 +271,7 @@ test podinfo Progressing 15 2019-12-20T14:05:07Z
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
@@ -313,8 +302,7 @@ Generate latency:
|
||||
watch -n 1 curl http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n projectcontour logs deploy/flagger -f | jq .msg
|
||||
@@ -333,18 +321,15 @@ Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded, or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||

|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||

|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
@@ -439,3 +424,4 @@ match:
|
||||
```
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
||||
@@ -53,15 +53,12 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services, SMI traffic splits).
|
||||
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
||||
There's no SMI object you need to create by yourself.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services, SMI traffic splits\). These objects expose the application on the mesh and drive the canary analysis and promotion. There's no SMI object you need to create by yourself.
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
@@ -210,21 +207,17 @@ service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods. During the canary analysis,
|
||||
the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec (container image, command, ports, env, resources, etc)
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
@@ -285,7 +278,7 @@ kubectl port-forward --namespace test svc/flagger-grafana 3000:80
|
||||
|
||||
The Envoy dashboard URL is [http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo](http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo)
|
||||
|
||||

|
||||

|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
@@ -300,7 +293,7 @@ prod backend Failed 0 2019-10-02T17:05:07Z
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
@@ -331,8 +324,7 @@ Generate latency:
|
||||
watch -n 1 curl -H 'Host: podinfo.test' http://envoy.test:10000/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test logs deploy/flagger -f | jq .msg
|
||||
@@ -351,8 +343,7 @@ Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded, or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
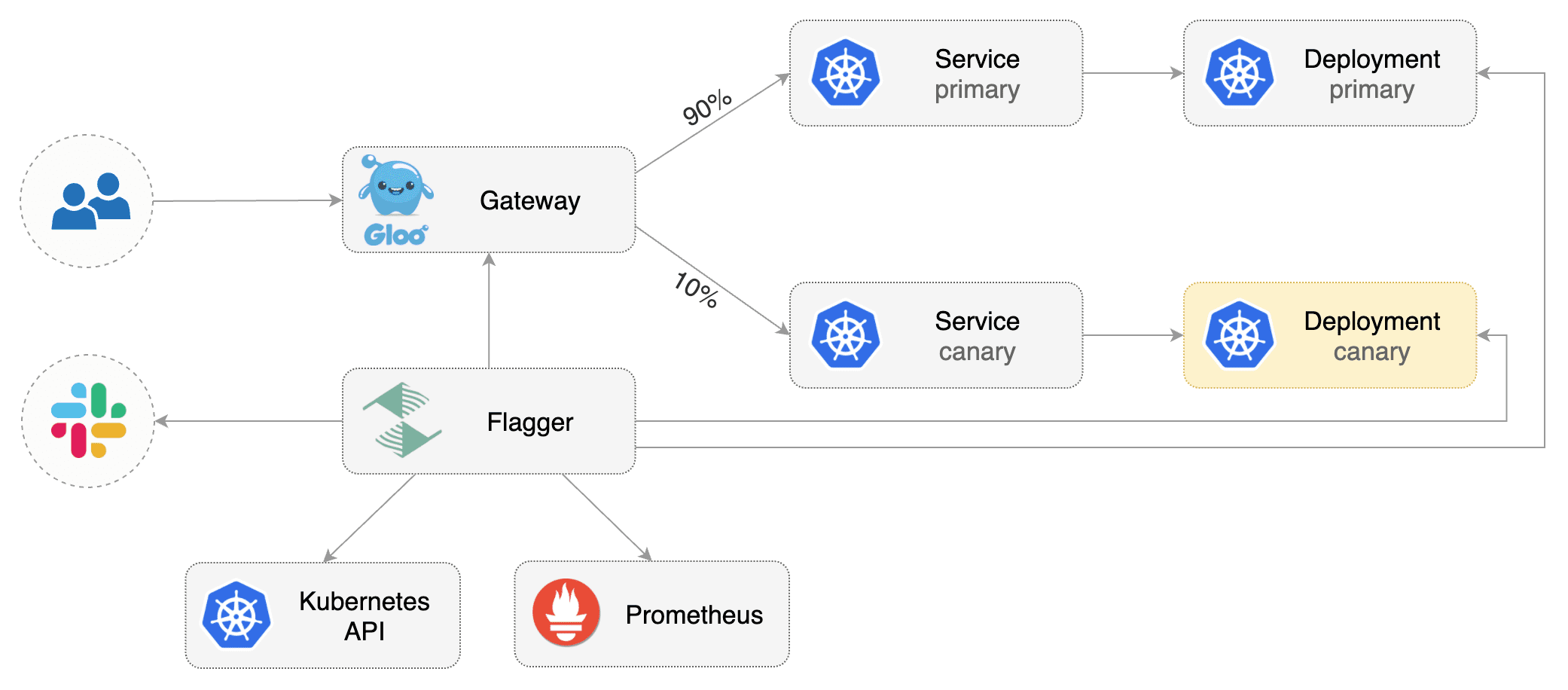
This guide shows you how to use the [Gloo](https://gloo.solo.io/) ingress controller and Flagger to automate canary deployments.
|
||||
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -30,9 +30,7 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Gloo upstream groups).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and Gloo upstream groups\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -43,17 +41,16 @@ kubectl create ns test
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl -n test apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl -n test apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl -n test apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create an virtual service definition that references an upstream group that will be generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
Create an virtual service definition that references an upstream group that will be generated by Flagger \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: gateway.solo.io/v1
|
||||
@@ -80,7 +77,7 @@ Save the above resource as podinfo-virtualservice.yaml and then apply it:
|
||||
kubectl apply -f ./podinfo-virtualservice.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -182,11 +179,9 @@ podinfo Initialized 0 2019-05-17T08:09:51Z
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -261,8 +256,7 @@ Generate high latency:
|
||||
watch curl -H 'Host: app.example.com' http://gateway-proxy-v2.gloo-system/delay/2
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -291,8 +285,7 @@ Events:
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use
|
||||
the HTTP request duration histogram to validate the canary.
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
@@ -340,8 +333,7 @@ Edit the canary analysis and add the following metric:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is
|
||||
below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -374,8 +366,7 @@ Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
If you have [alerting](../usage/alerting.md) configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
||||
@@ -2,11 +2,9 @@
|
||||
|
||||
This guide shows you how to automate A/B testing with Istio and Flagger.
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -23,7 +21,7 @@ kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.8/sampl
|
||||
Install Flagger in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/istio?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/istio
|
||||
```
|
||||
|
||||
Create an ingress gateway to expose the demo app outside of the mesh:
|
||||
@@ -58,16 +56,16 @@ kubectl label namespace test istio-injection=enabled
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace example.com with your own domain):
|
||||
Create a canary custom resource \(replace example.com with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -140,8 +138,7 @@ spec:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: type=insider' http://podinfo.test:9898/"
|
||||
```
|
||||
|
||||
**Note** that when using Istio 1.5 you have to replace the `request-duration`
|
||||
with a [metric template](https://docs.flagger.app/dev/upgrade-guide#istio-telemetry-v2).
|
||||
**Note** that when using Istio 1.5 you have to replace the `request-duration` with a [metric template](https://docs.flagger.app/dev/upgrade-guide#istio-telemetry-v2).
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting Firefox users and those that have an insider cookie.
|
||||
|
||||
@@ -237,8 +234,7 @@ Generate latency:
|
||||
watch curl -b 'type=insider' http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -259,7 +255,5 @@ Events:
|
||||
Warning Synced 1m flagger Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks, [webhooks](../usage/webhooks.md), [manual promotion](../usage/webhooks.md#manual-gating) approval and [Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
This guide shows you how to use Istio and Flagger to automate canary deployments.
|
||||
|
||||

|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -19,7 +19,7 @@ kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.8/sampl
|
||||
Install Flagger in the `istio-system` namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/istio?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/istio
|
||||
```
|
||||
|
||||
Create an ingress gateway to expose the demo app outside of the mesh:
|
||||
@@ -44,10 +44,7 @@ spec:
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services,
|
||||
Istio destination rules and virtual services).
|
||||
These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services, Istio destination rules and virtual services\). These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace with Istio sidecar injection enabled:
|
||||
|
||||
@@ -59,16 +56,16 @@ kubectl label namespace test istio-injection=enabled
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace example.com with your own domain):
|
||||
Create a canary custom resource \(replace example.com with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -151,8 +148,7 @@ spec:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
**Note** that when using Istio 1.4 you have to replace the `request-duration`
|
||||
with a [metric template](https://docs.flagger.app/dev/upgrade-guide#istio-telemetry-v2).
|
||||
**Note** that when using Istio 1.4 you have to replace the `request-duration` with a [metric template](https://docs.flagger.app/dev/upgrade-guide#istio-telemetry-v2).
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
@@ -160,10 +156,9 @@ Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
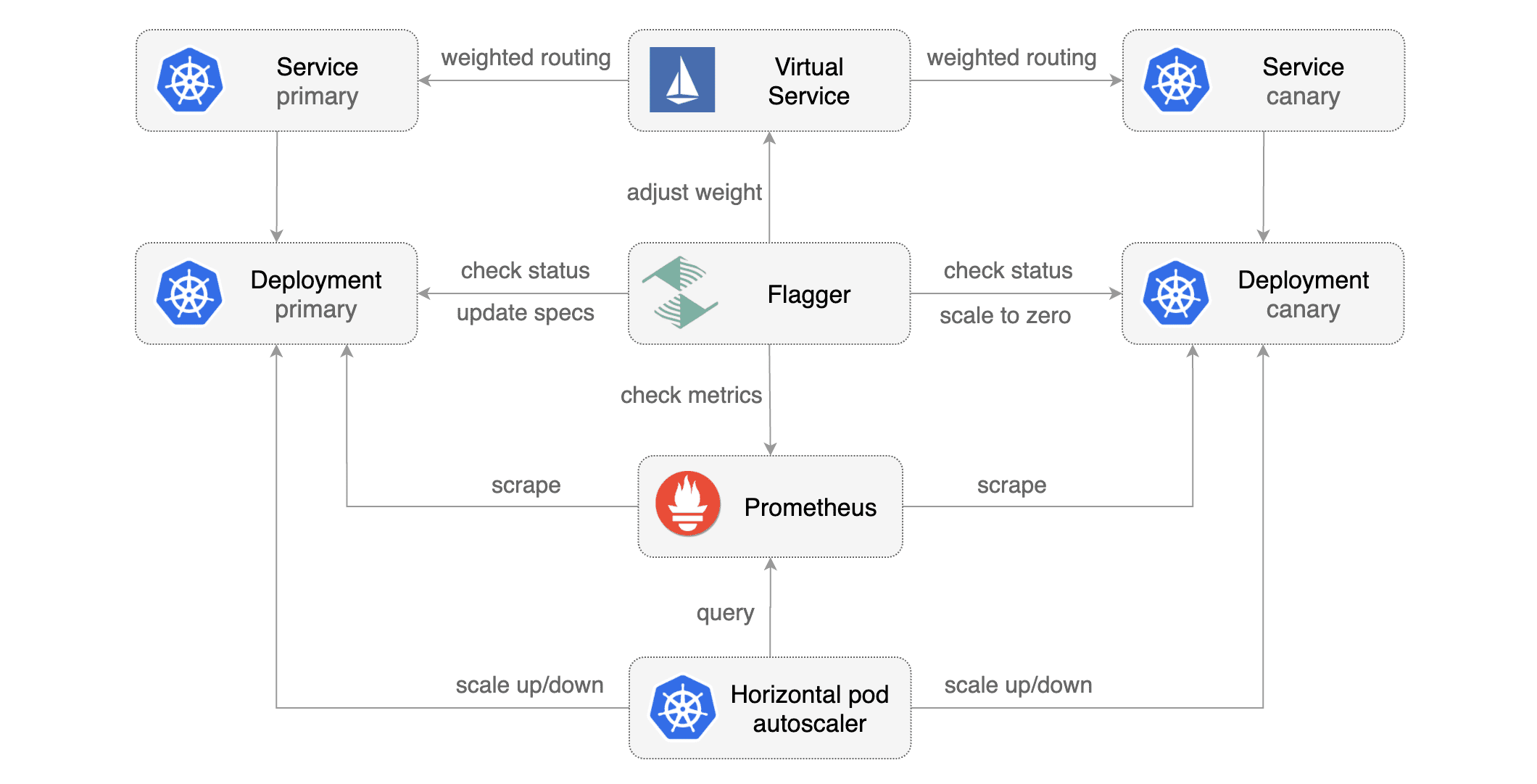
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every minute.
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary. The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every minute.
|
||||
|
||||
|
||||

|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
@@ -271,8 +266,7 @@ Generate latency:
|
||||
watch curl http://podinfo-canary:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -299,14 +293,11 @@ Events:
|
||||
|
||||
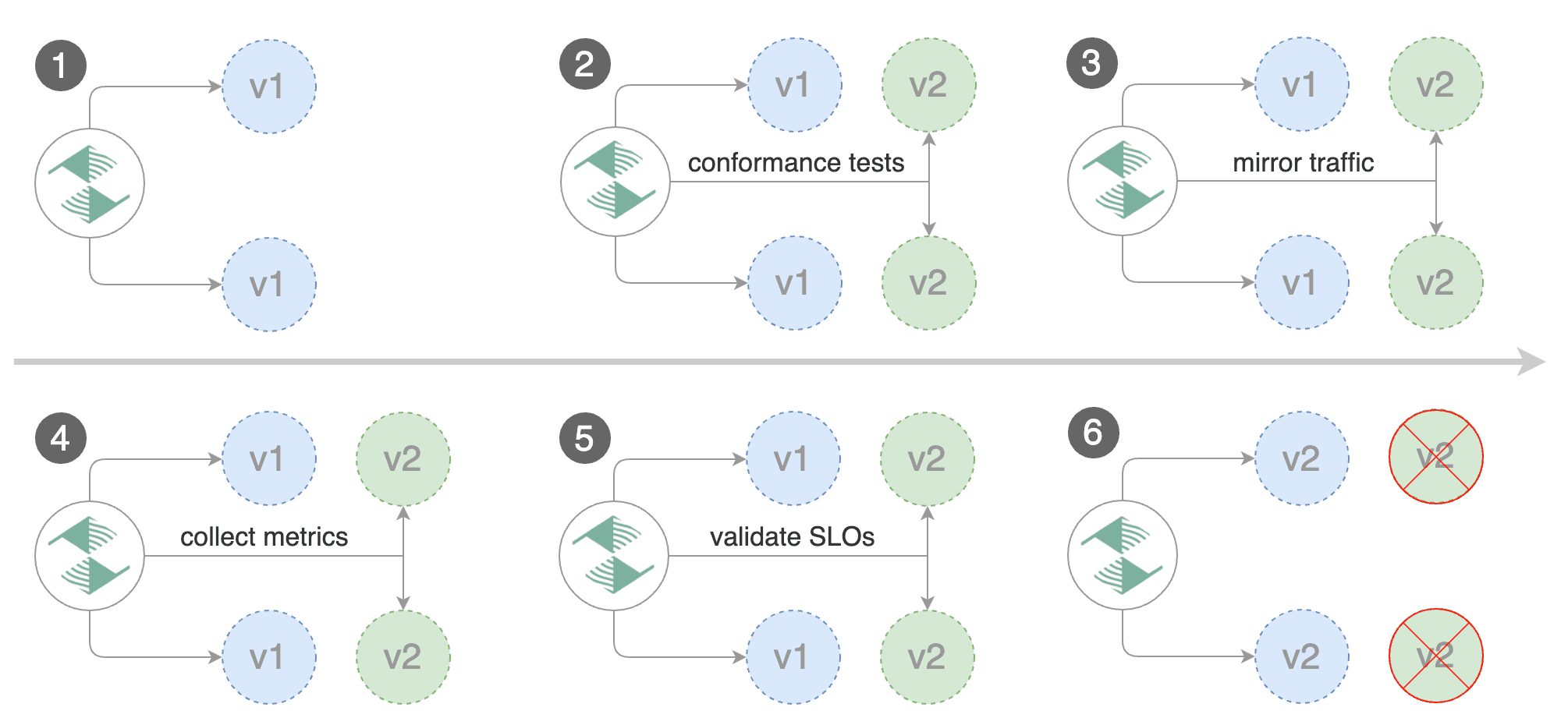
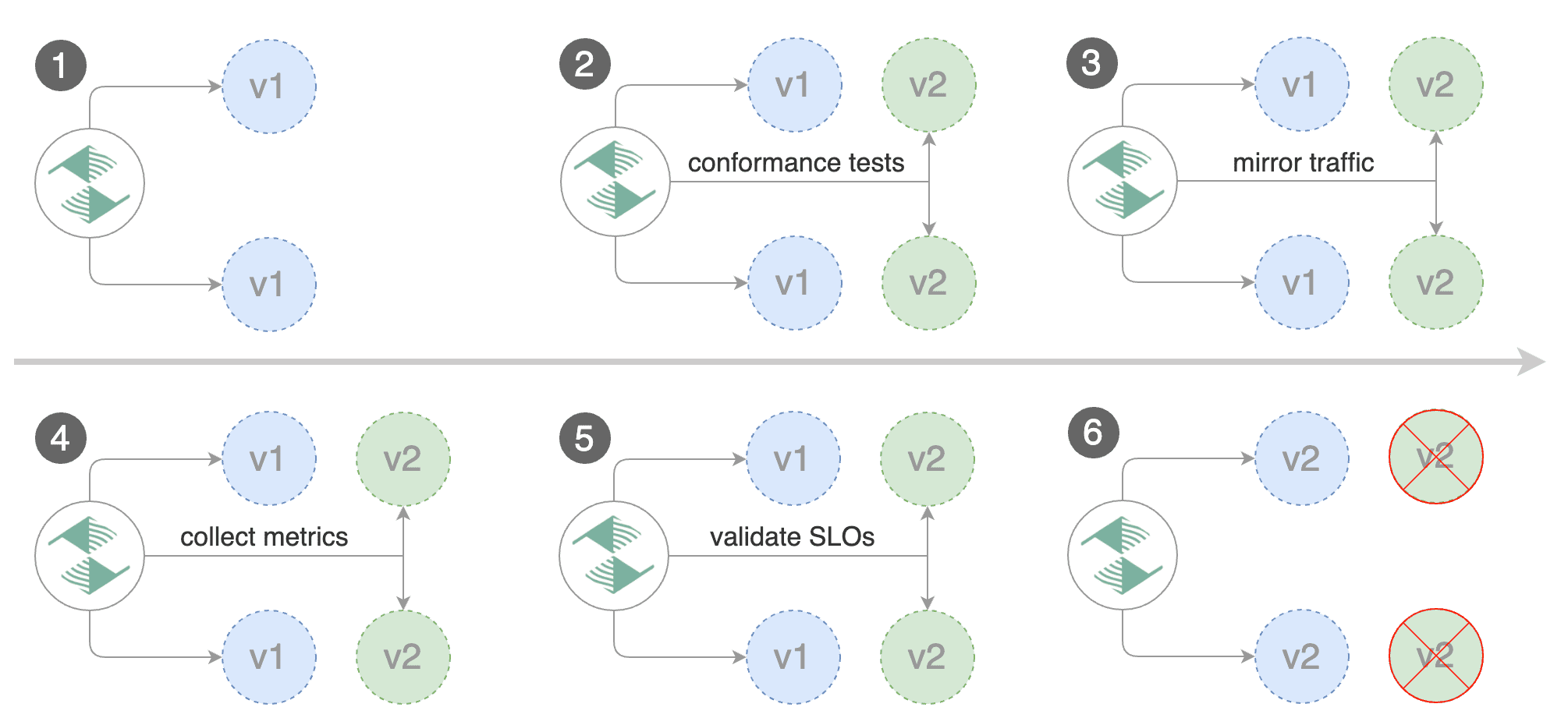
## Traffic mirroring
|
||||
|
||||
|
||||
|
||||
|
||||
For applications that perform read operations, Flagger can be configured to drive canary releases with traffic mirroring.
|
||||
Istio traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service.
|
||||
The response from the primary is sent back to the user and the response from the canary is discarded.
|
||||
Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are within the threshold values.
|
||||
For applications that perform read operations, Flagger can be configured to drive canary releases with traffic mirroring. Istio traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service. The response from the primary is sent back to the user and the response from the canary is discarded. Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are within the threshold values.
|
||||
|
||||
Note that mirroring should be used for requests that are **idempotent** or capable of being processed twice (once by the primary and once by the canary).
|
||||
Note that mirroring should be used for requests that are **idempotent** or capable of being processed twice \(once by the primary and once by the canary\).
|
||||
|
||||
You can enable mirroring by replacing `stepWeight/maxWeight` with `iterations` and by setting `analysis.mirror` to `true`:
|
||||
|
||||
@@ -354,7 +345,7 @@ spec:
|
||||
|
||||
With the above configuration, Flagger will run a canary release with the following steps:
|
||||
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* detect new revision \(deployment spec, secrets or configmaps changes\)
|
||||
* scale from zero the canary deployment
|
||||
* wait for the HPA to set the canary minimum replicas
|
||||
* check canary pods health
|
||||
@@ -366,7 +357,7 @@ With the above configuration, Flagger will run a canary release with the followi
|
||||
* abort the canary release if the metrics check failure threshold is reached
|
||||
* stop traffic mirroring after the number of iterations is reached
|
||||
* route live traffic to the canary pods
|
||||
* promote the canary (update the primary secrets, configmaps and deployment spec)
|
||||
* promote the canary \(update the primary secrets, configmaps and deployment spec\)
|
||||
* wait for the primary deployment rollout to finish
|
||||
* wait for the HPA to set the primary minimum replicas
|
||||
* check primary pods health
|
||||
@@ -374,7 +365,5 @@ With the above configuration, Flagger will run a canary release with the followi
|
||||
* scale to zero the canary
|
||||
* send notification with the canary analysis result
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks, [webhooks](../usage/webhooks.md), [manual promotion](../usage/webhooks.md#manual-gating) approval and [Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
|
||||
@@ -2,11 +2,9 @@
|
||||
|
||||
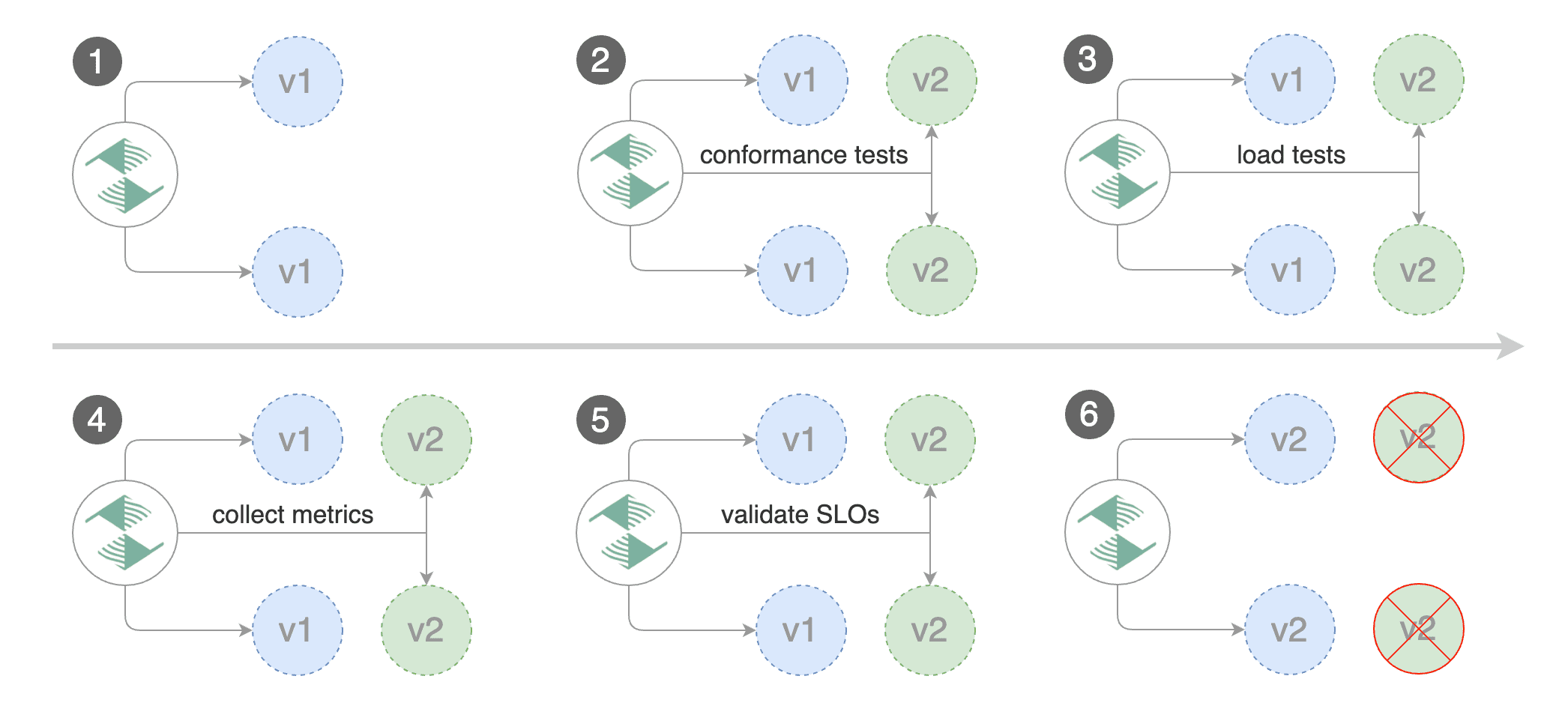
This guide shows you how to automate Blue/Green deployments with Flagger and Kubernetes.
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate Blue/Green style deployments
|
||||
with Kubernetes L4 networking. When using a service mesh blue/green can be used as
|
||||
specified [here](../usage/deployment-strategies.md).
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate Blue/Green style deployments with Kubernetes L4 networking. When using a service mesh blue/green can be used as specified [here](../usage/deployment-strategies.md).
|
||||
|
||||

|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -44,9 +42,7 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployment and ClusterIP services).
|
||||
These objects expose the application inside the cluster and drive the canary analysis and Blue/Green promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployment and ClusterIP services\). These objects expose the application inside the cluster and drive the canary analysis and Blue/Green promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -57,13 +53,13 @@ kubectl create ns test
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
@@ -158,10 +154,14 @@ service/podinfo-primary
|
||||
|
||||
Blue/Green scenario:
|
||||
|
||||
* on bootstrap, Flagger will create three ClusterIP services (`app-primary`,`app-canary`, `app`)
|
||||
and a shadow deployment named `app-primary` that represents the blue version
|
||||
* on bootstrap, Flagger will create three ClusterIP services \(`app-primary`,`app-canary`, `app`\)
|
||||
|
||||
and a shadow deployment named `app-primary` that represents the blue version
|
||||
|
||||
* when a new version is detected, Flagger would scale up the green version and run the conformance tests
|
||||
(the tests should target the `app-canary` ClusterIP service to reach the green version)
|
||||
|
||||
\(the tests should target the `app-canary` ClusterIP service to reach the green version\)
|
||||
|
||||
* if the conformance tests are passing, Flagger would start the load tests and validate them with custom Prometheus queries
|
||||
* if the load test analysis is successful, Flagger will promote the new version to `app-primary` and scale down the green version
|
||||
|
||||
@@ -257,9 +257,7 @@ Events:
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The analysis can be extended with Prometheus queries. The demo app is instrumented with Prometheus so you can
|
||||
create a custom check that will use the HTTP request duration histogram to validate the canary (green version).
|
||||
|
||||
The analysis can be extended with Prometheus queries. The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request duration histogram to validate the canary \(green version\).
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
@@ -307,8 +305,7 @@ Edit the canary analysis and add the following metric:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary (green version) by checking if the HTTP 404 req/sec percentage is
|
||||
below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the rollout is rolled back.
|
||||
The above configuration validates the canary \(green version\) by checking if the HTTP 404 req/sec percentage is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the rollout is rolled back.
|
||||
|
||||
Trigger a deployment by updating the container image:
|
||||
|
||||
@@ -337,8 +334,7 @@ Rolling back podinfo.test failed checks threshold reached 2
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
If you have [alerting](../usage/alerting.md) configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
## Conformance Testing with Helm
|
||||
|
||||
@@ -370,8 +366,7 @@ Add a helm test pre-rollout hook to your chart:
|
||||
cmd: "test {{ .Release.Name }} --cleanup"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks.
|
||||
If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks. If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
This guide shows you how to use Linkerd and Flagger to automate canary deployments.
|
||||
|
||||

|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -11,16 +11,14 @@ Flagger requires a Kubernetes cluster **v1.11** or newer and Linkerd **2.4** or
|
||||
Install Flagger in the linkerd namespace:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/linkerd?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/linkerd
|
||||
```
|
||||
|
||||
Note that you'll need kubectl 1.14 or newer to run the above command.
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and SMI traffic split).
|
||||
These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and SMI traffic split\). These objects expose the application inside the mesh and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace and enable Linkerd proxy injection:
|
||||
|
||||
@@ -32,13 +30,13 @@ kubectl annotate namespace test linkerd.io/inject=enabled
|
||||
Install the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/tester
|
||||
```
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Create a canary custom resource for the podinfo deployment:
|
||||
@@ -115,8 +113,7 @@ Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every half a minute.
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary. The canary analysis will run for five minutes while validating the HTTP metrics and rollout hooks every half a minute.
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
@@ -136,17 +133,13 @@ service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
|
||||
will be routed to the primary pods.
|
||||
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -205,8 +198,7 @@ prod backend Failed 0 2019-06-30T17:05:07Z
|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to
|
||||
test if Flagger pauses and rolls back the faulted version.
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses and rolls back the faulted version.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
@@ -233,8 +225,7 @@ Generate latency:
|
||||
watch -n 1 curl http://podinfo-canary.test:9898/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -293,9 +284,7 @@ Let's a define a check for not found errors. Edit the canary analysis and add th
|
||||
* 100
|
||||
```
|
||||
|
||||
The above configuration validates the canary version by checking if the HTTP 404 req/sec percentage
|
||||
is below three percent of the total traffic.
|
||||
If the 404s rate reaches the 3% threshold, then the analysis is aborted and the canary is marked as failed.
|
||||
The above configuration validates the canary version by checking if the HTTP 404 req/sec percentage is below three percent of the total traffic. If the 404s rate reaches the 3% threshold, then the analysis is aborted and the canary is marked as failed.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -340,8 +329,7 @@ helm upgrade -i nginx-ingress stable/nginx-ingress \
|
||||
--namespace ingress-nginx
|
||||
```
|
||||
|
||||
Create an ingress definition for podinfo that rewrites the incoming header
|
||||
to the internal service name (required by Linkerd):
|
||||
Create an ingress definition for podinfo that rewrites the incoming header to the internal service name \(required by Linkerd\):
|
||||
|
||||
```yaml
|
||||
apiVersion: extensions/v1beta1
|
||||
@@ -367,20 +355,15 @@ spec:
|
||||
servicePort: 9898
|
||||
```
|
||||
|
||||
When using an ingress controller, the Linkerd traffic split does not apply to incoming traffic
|
||||
since NGINX in running outside of the mesh. In order to run a canary analysis for a frontend app,
|
||||
Flagger creates a shadow ingress and sets the NGINX specific annotations.
|
||||
When using an ingress controller, the Linkerd traffic split does not apply to incoming traffic since NGINX in running outside of the mesh. In order to run a canary analysis for a frontend app, Flagger creates a shadow ingress and sets the NGINX specific annotations.
|
||||
|
||||
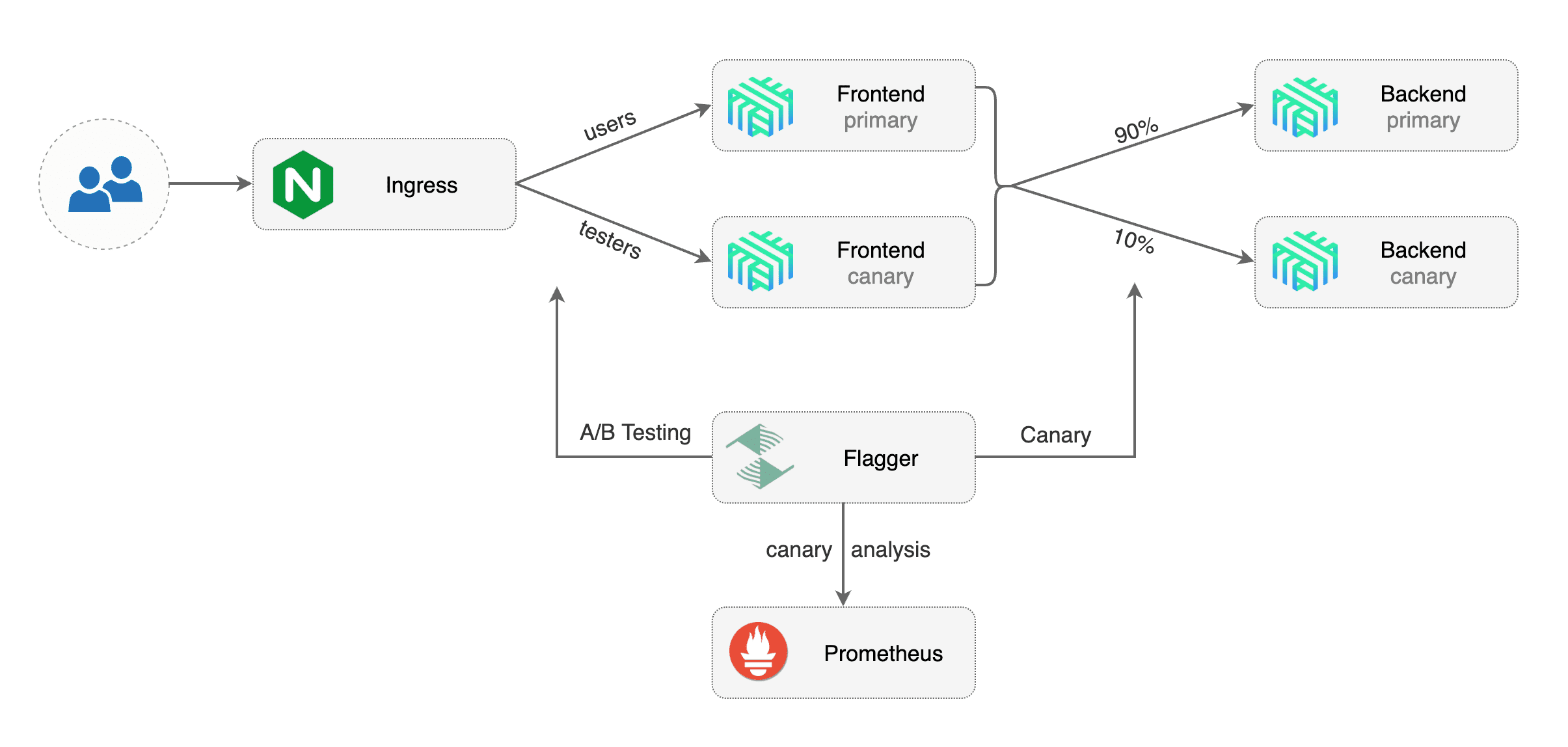
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||
|
||||
|
||||
|
||||
Edit podinfo canary analysis, set the provider to `nginx`, add the ingress reference,
|
||||
remove the max/step weight and add the match conditions and iterations:
|
||||
Edit podinfo canary analysis, set the provider to `nginx`, add the ingress reference, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -444,8 +427,7 @@ spec:
|
||||
cmd: "hey -z 2m -q 10 -c 2 -H 'Cookie: canary=always' http://app.example.com"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have
|
||||
a `canary` cookie set to `always` or those that call the service using the `X-Canary: always` header.
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `canary` cookie set to `always` or those that call the service using the `X-Canary: always` header.
|
||||
|
||||
**Note** that the load test now targets the external address and uses the canary cookie.
|
||||
|
||||
@@ -479,7 +461,5 @@ Events:
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks, [webhooks](../usage/webhooks.md), [manual promotion](../usage/webhooks.md#manual-gating) approval and [Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
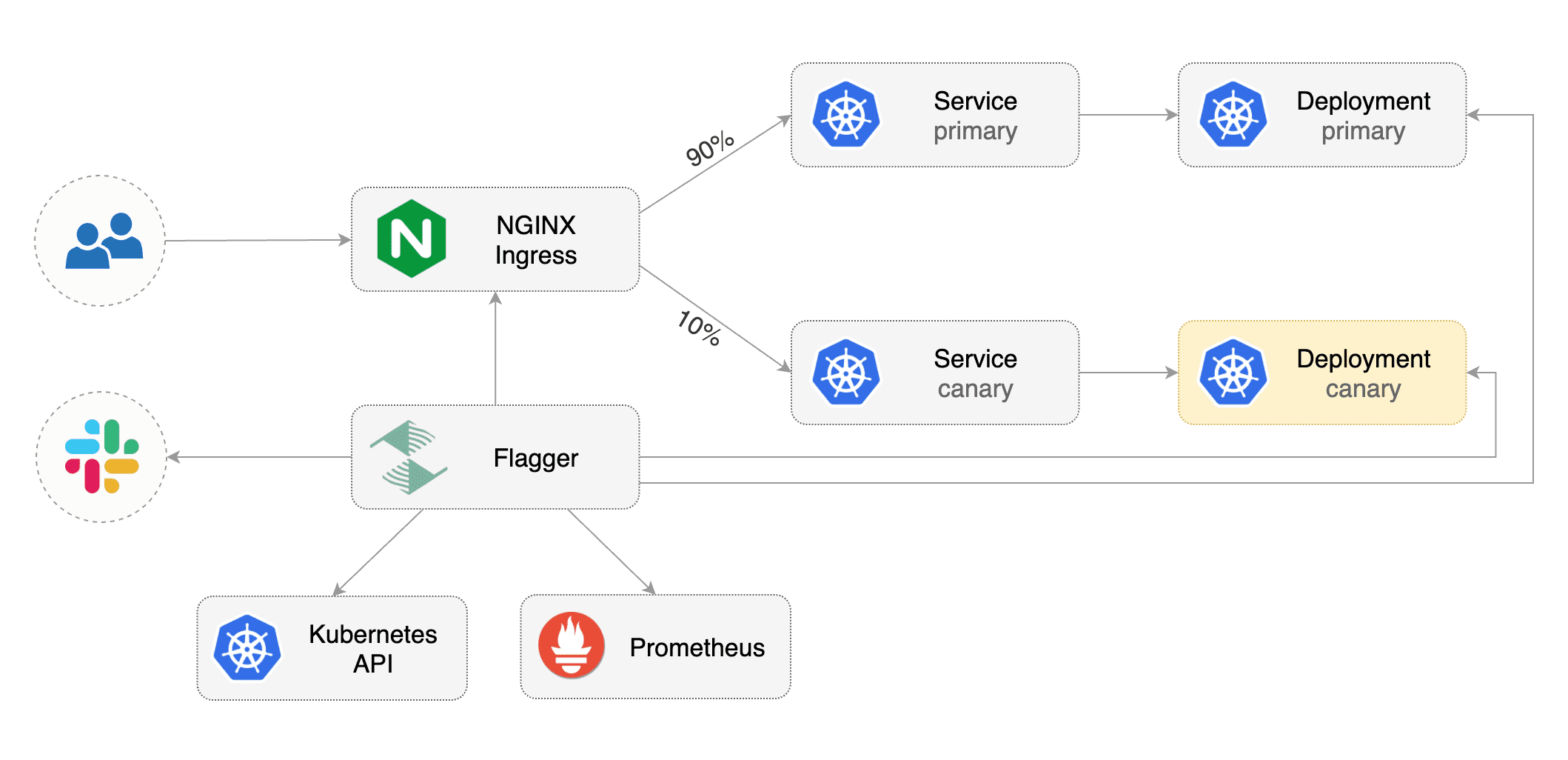
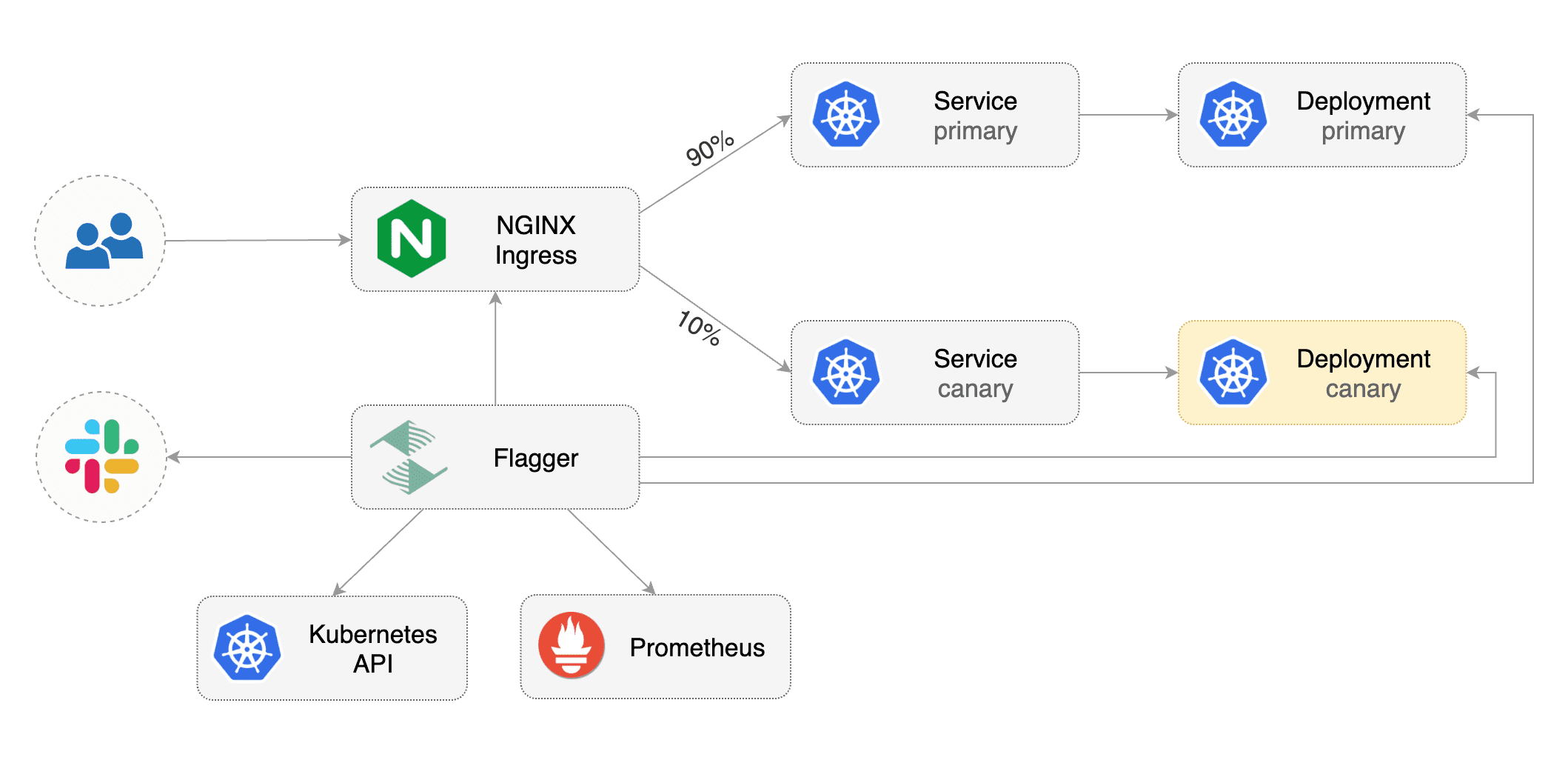
This guide shows you how to use the NGINX ingress controller and Flagger to automate canary deployments and A/B testing.
|
||||
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -43,9 +43,7 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and canary ingress).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and canary ingress\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -56,7 +54,7 @@ kubectl create ns test
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
@@ -188,11 +186,9 @@ ingresses.extensions/podinfo-canary
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
|
||||

|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -261,8 +257,7 @@ Generate HTTP 500 errors:
|
||||
watch curl http://app.example.com/status/500
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
@@ -291,8 +286,7 @@ Events:
|
||||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the
|
||||
HTTP request duration histogram to validate the canary.
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
@@ -332,8 +326,7 @@ Edit the canary analysis and add the latency check:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second
|
||||
then the analysis will fail and the canary will not be promoted.
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second then the analysis will fail and the canary will not be promoted.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -370,11 +363,9 @@ If you have alerting configured, Flagger will send a notification with the reaso
|
||||
|
||||
## A/B Testing
|
||||
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
|
||||
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
|
||||
This is particularly useful for frontend applications that require session affinity.
|
||||
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions. In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users. This is particularly useful for frontend applications that require session affinity.
|
||||
|
||||

|
||||

|
||||
|
||||
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
|
||||
|
||||
@@ -405,8 +396,7 @@ Edit the canary analysis, remove the max/step weight and add the match condition
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: canary=always' http://app.example.com/"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `canary` cookie
|
||||
set to `always` or those that call the service using the `X-Canary: insider` header.
|
||||
The above configuration will run an analysis for ten minutes targeting users that have a `canary` cookie set to `always` or those that call the service using the `X-Canary: insider` header.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -444,7 +434,5 @@ Events:
|
||||
Normal Synced 5s flagger Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks,
|
||||
[webhooks](../usage/webhooks.md),
|
||||
[manual promotion](../usage/webhooks.md#manual-gating) approval and
|
||||
[Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
The above procedure can be extended with [custom metrics](../usage/metrics.md) checks, [webhooks](../usage/webhooks.md), [manual promotion](../usage/webhooks.md#manual-gating) approval and [Slack or MS Teams](../usage/alerting.md) notifications.
|
||||
|
||||
|
||||
@@ -16,8 +16,7 @@ helm upgrade -i prometheus stable/prometheus-operator \
|
||||
--set fullnameOverride=prometheus
|
||||
```
|
||||
|
||||
The `prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false`
|
||||
option allows Prometheus operator to watch serviceMonitors outside of his namespace.
|
||||
The `prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false` option allows Prometheus operator to watch serviceMonitors outside of his namespace.
|
||||
|
||||
Install Flagger by setting the metrics server to Prometheus:
|
||||
|
||||
@@ -85,8 +84,7 @@ spec:
|
||||
app: podinfo-canary
|
||||
```
|
||||
|
||||
We are setting `interval: 5s` to have a more aggressive scraping.
|
||||
If you do not define it, you must to use a longer interval in the Canary object.
|
||||
We are setting `interval: 5s` to have a more aggressive scraping. If you do not define it, you must to use a longer interval in the Canary object.
|
||||
|
||||
## Metric templates
|
||||
|
||||
@@ -191,7 +189,7 @@ spec:
|
||||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test/"
|
||||
```
|
||||
|
||||
Based on the above specification, Flagger creates the primary and canary Kubernetes ClusterIP service.
|
||||
Based on the above specification, Flagger creates the primary and canary Kubernetes ClusterIP service.
|
||||
|
||||
During the canary analysis, Prometheus will scrape the canary service and Flagger will use the HTTP error rate and latency queries to determine if the release should be promoted or rolled back.
|
||||
|
||||
During the canary analysis, Prometheus will scrape the canary service and Flagger will use the HTTP error rate and
|
||||
latency queries to determine if the release should be promoted or rolled back.
|
||||
|
||||
2
docs/gitbook/tutorials/rollout-weights.md
Normal file
2
docs/gitbook/tutorials/rollout-weights.md
Normal file
@@ -0,0 +1,2 @@
|
||||
# Rollout Weights
|
||||
|
||||
@@ -2,7 +2,7 @@
|
||||
|
||||
This guide shows you how to use the [Skipper ingress controller](https://opensource.zalando.com/skipper/kubernetes/ingress-controller/) and Flagger to automate canary deployments.
|
||||
|
||||
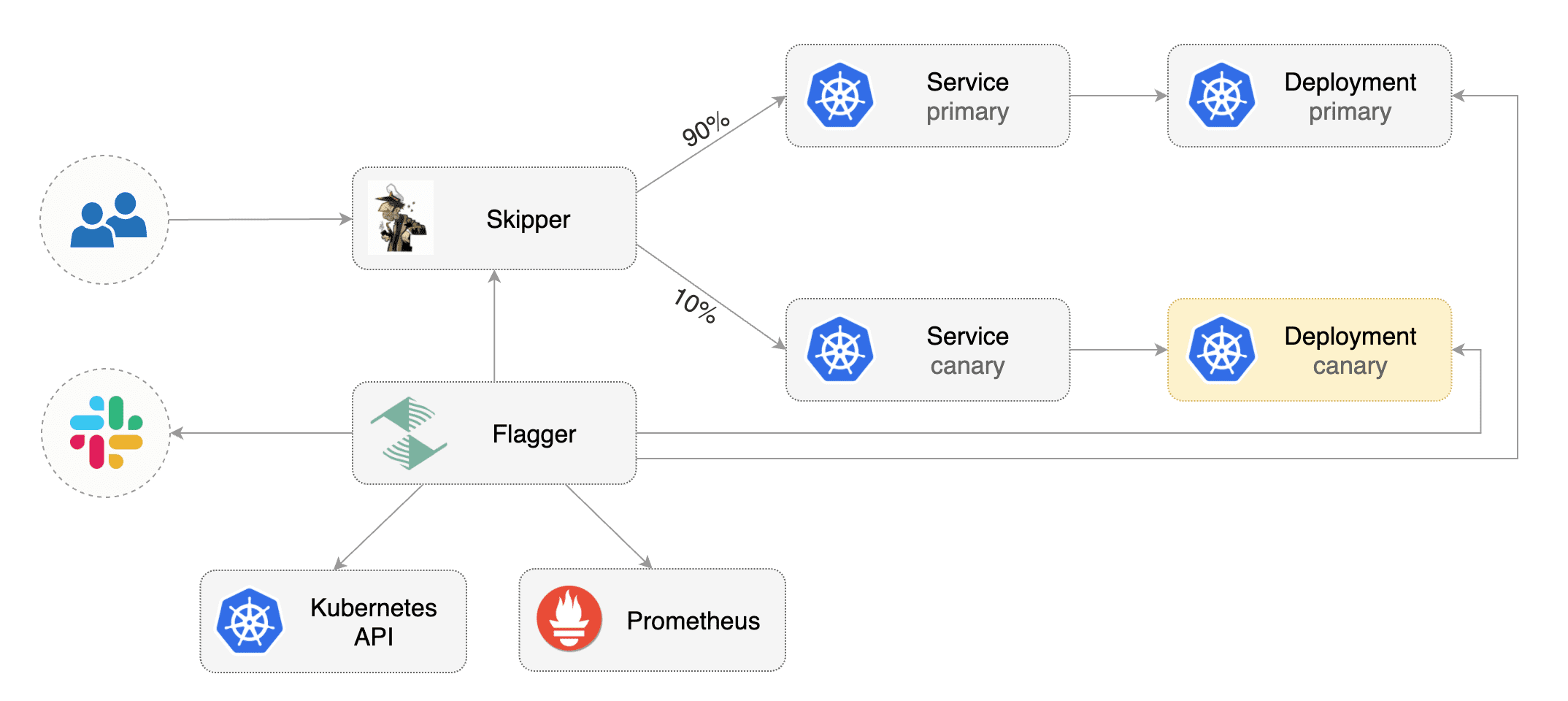
|
||||
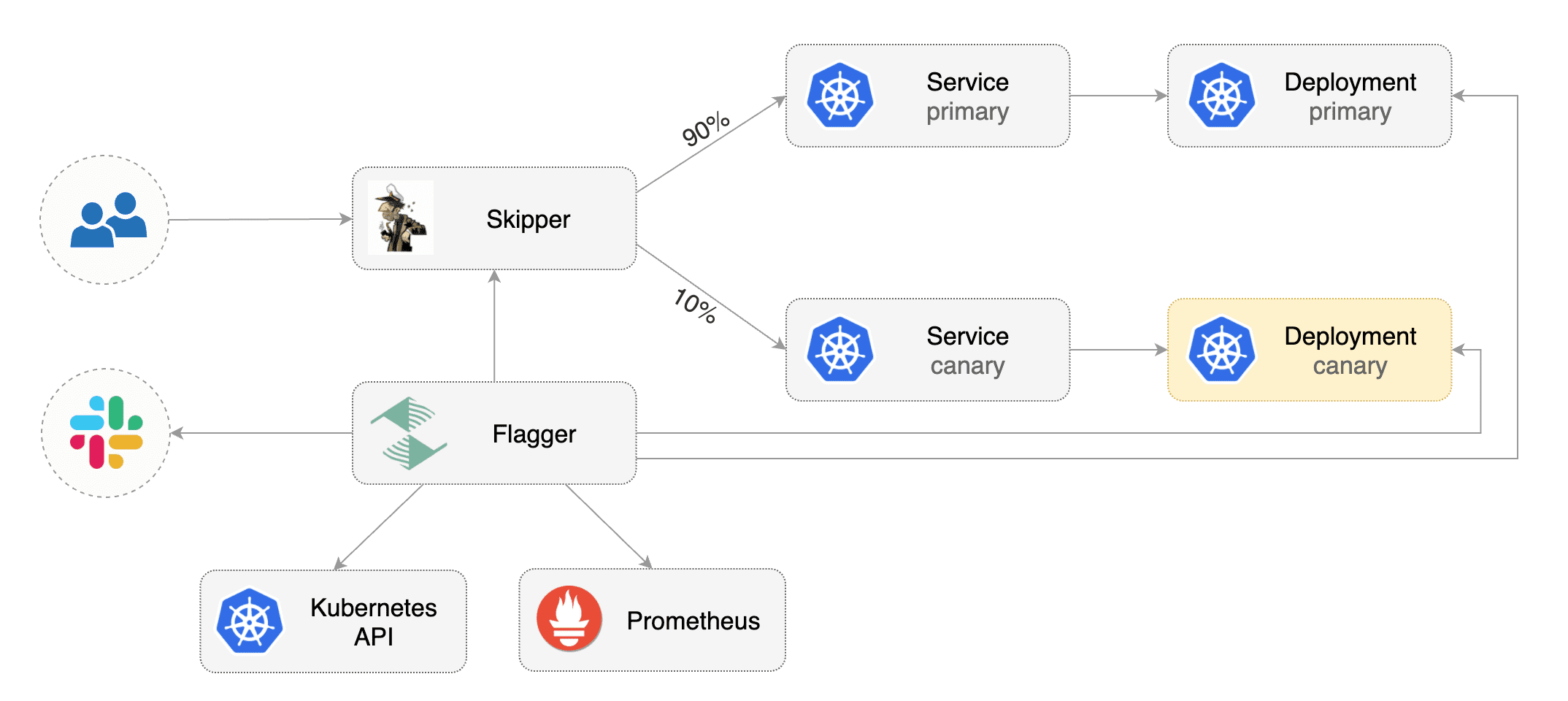
|
||||
|
||||
## Prerequisites
|
||||
|
||||
@@ -31,14 +31,12 @@ Certain arguments are relevant:
|
||||
Install Flagger using kustomize:
|
||||
|
||||
```bash
|
||||
kustomize build https://github.com/fluxcd/flagger/kustomize/kubernetes?ref=main | kubectl apply -f -
|
||||
kustomize build https://github.com/weaveworks/flagger/kustomize/kubernetes | kubectl apply -f -
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and canary ingress).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and canary ingress\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -49,7 +47,7 @@ kubectl create ns test
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
@@ -192,11 +190,9 @@ ingress.networking.k8s.io/podinfo-canary
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
|
||||

|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -275,8 +271,7 @@ Generate latency:
|
||||
watch -n 1 curl http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n flagger-system logs deploy/flagger -f | jq .msg
|
||||
@@ -338,8 +333,7 @@ Edit the canary analysis and add the latency check:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second
|
||||
then the analysis will fail and the canary will not be promoted.
|
||||
The threshold is set to 500ms so if the average request duration in the last minute goes over half a second then the analysis will fail and the canary will not be promoted.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -373,3 +367,4 @@ Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have alerting configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
|
||||
@@ -29,9 +29,7 @@ helm upgrade -i flagger flagger/flagger \
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and TraefikService).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and TraefikService\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
@@ -42,7 +40,7 @@ kubectl create ns test
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
kubectl apply -k github.com/weaveworks/flagger//kustomize/podinfo
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
@@ -52,8 +50,7 @@ helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Create Traefik IngressRoute that references TraefikService generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
Create Traefik IngressRoute that references TraefikService generated by Flagger \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: traefik.containo.us/v1alpha1
|
||||
@@ -79,7 +76,7 @@ Save the above resource as podinfo-ingressroute.yaml and then apply it:
|
||||
kubectl apply -f ./podinfo-ingressroute.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
@@ -175,11 +172,9 @@ traefikservice.traefik.containo.us/podinfo
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
|
||||
|
||||

|
||||

|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -258,8 +253,7 @@ Generate latency:
|
||||
watch -n 1 curl http://app.example.com/delay/1
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n traefik logs deploy/flagger -f | jq .msg
|
||||
@@ -327,8 +321,7 @@ Edit the canary analysis and add the not found error rate check:
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is
|
||||
below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
@@ -361,7 +354,7 @@ Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
If you have [alerting](../usage/alerting.md) configured, Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
||||
Reference in New Issue
Block a user